Автор: Денис Аветисян
Новая разработка позволяет автоматически формировать правила доступа и контролировать исполнение, снижая риски, связанные с вредоносными запросами и непредсказуемостью больших языковых моделей.
Представлен AgentGuardian — фреймворк для автоматического формирования политик контроля доступа и обеспечения целостности потока выполнения ИИ-агентов, использующий атрибутный контроль доступа и снижающий влияние галлюцинаций.
По мере расширения сфер применения ИИ-агентов возрастает и потребность в надежной системе их защиты. В данной работе представлена система AgentGuardian: Learning Access Control Policies to Govern AI Agent Behavior, предназначенная для автоматического формирования политик контроля доступа и обеспечения целостности выполнения задач. Предлагаемый фреймворк динамически адаптируется к поведению агента, предотвращая несанкционированные действия и минимизируя риски, связанные с некорректными входными данными и галлюцинациями больших языковых моделей. Способна ли такая система обеспечить надежную и гибкую защиту ИИ-агентов в условиях постоянно меняющихся угроз и требований?
Пророчество о Неизбежном: Рождение Уязвимостей AI-Агентов
Быстрое распространение AI-агентов в сфере генеративного искусственного интеллекта порождает новые, ранее не встречавшиеся проблемы безопасности. В отличие от традиционных систем, ориентированных на защиту от прямых действий пользователя, взаимодействие с автономными агентами требует принципиально иного подхода. Способность этих агентов к использованию инструментов и сотрудничеству друг с другом создает сложные сценарии, в которых стандартные меры защиты оказываются неэффективными. Уязвимости в алгоритмах и процессах принятия решений могут быть использованы злоумышленниками для манипулирования агентами, что потенциально ведет к непредсказуемым и опасным последствиям, требуя разработки новых методов оценки и укрепления безопасности систем на основе AI.
Традиционные парадигмы безопасности, ориентированные на непосредственный ввод данных пользователем, оказываются недостаточными для защиты от сложных взаимодействий автономных агентов. Вместо анализа отдельных запросов, современные системы безопасности должны учитывать способность агентов к самообучению, использованию инструментов и сотрудничеству друг с другом. Это требует перехода к более комплексному подходу, учитывающему не только входные данные, но и внутреннюю логику агента, его цели и потенциальные векторы атак, возникающие в процессе взаимодействия с другими системами и агентами. Неспособность адаптироваться к этой новой реальности создает значительные уязвимости и повышает риск непредсказуемого или даже вредоносного поведения автономных систем.
Возможности современных ИИ-агентов, включающие использование различных инструментов и взаимодействие друг с другом, требуют кардинального пересмотра подходов к обеспечению безопасности. Традиционные методы, ориентированные на защиту от прямого вмешательства пользователя, оказываются недостаточными для оценки рисков, связанных с автономными агентами, способными к сложным действиям и самообучению. Необходим переход к целостным, системным оценкам безопасности, учитывающим не только отдельные компоненты, но и все взаимодействия внутри системы, а также потенциальные точки уязвимости, возникающие при совместной работе агентов. Такой подход позволит выявить и нейтрализовать угрозы, которые не могут быть обнаружены при использовании устаревших методов, и обеспечить надежную защиту от непредсказуемого или вредоносного поведения ИИ.
Отсутствие надежных механизмов защиты делает искусственные агенты уязвимыми к эксплуатации, что может приводить к непредсказуемому и даже опасному поведению. Исследования показывают, что злоумышленники способны манипулировать целями и действиями агентов, используя лазейки в их алгоритмах или вводя искаженные данные. Это может выражаться в несанкционированном доступе к информации, совершении финансовых операций от имени пользователя или даже в физическом воздействии на окружающую среду, если агент взаимодействует с реальным миром. Особенно тревожным является тот факт, что из-за автономности и способности к самообучению агенты могут действовать вне контроля разработчиков, усиливая потенциальный ущерб. Поэтому разработка эффективных систем защиты и постоянный мониторинг поведения агентов являются критически важными задачами для обеспечения безопасности в эпоху повсеместного распространения искусственного интеллекта.
Первый Рубеж: Защита на Уровне Запросов
Текстовые фильтры, известные как Prompt-Level Guardrails, представляют собой первую линию защиты, анализируя как входные запросы, отправляемые к базовой языковой модели (LLM), так и выходные данные, генерируемые ею. Этот подход предполагает проверку текста на наличие потенциально вредоносного или нежелательного контента, такого как оскорбления, разжигание ненависти, конфиденциальная информация или запросы, направленные на обход ограничений модели. Анализ осуществляется на текстовом уровне, до того, как запрос или ответ будет обработан другими компонентами системы, что позволяет оперативно блокировать или изменять небезопасные данные. Реализация таких фильтров обычно включает в себя использование списков запрещенных слов, регулярных выражений и, в более продвинутых случаях, моделей машинного обучения, обученных на выявлении нежелательного контента.
Существующие решения, такие как Llama Guard, Llama Firewall и Amazon Bedrock Guardrails, подтверждают принципиальную возможность применения защиты на уровне запросов. Llama Guard фокусируется на фильтрации небезопасного контента в ответах LLM, используя предварительно заданные критерии. Llama Firewall, в свою очередь, предоставляет более широкие возможности по контролю входящих и исходящих запросов, позволяя блокировать потенциально вредоносные взаимодействия. Amazon Bedrock Guardrails предлагает инструменты для определения и применения политик безопасности, включая ограничения на типы генерируемого контента и доступ к определенным функциям. Все эти системы демонстрируют, что анализ и фильтрация текстовых данных, обмениваемых с языковой моделью, является эффективным способом снижения рисков, связанных с генерацией нежелательного или опасного контента.
Существующие механизмы защиты на уровне запросов, такие как Llama Guard, Llama Firewall и Amazon Bedrock Guardrails, ограничиваются анализом непосредственного текстового взаимодействия с языковой моделью. Они не учитывают более широкий контекст работы агента, включая последовательность действий, используемые инструменты и внешние источники данных. В результате, эти решения не способны предотвратить злоупотребление инструментами или учитывать сложные рабочие процессы, что оставляет значительные уязвимости в системе без должной защиты. Анализ ограничивается только текущим запросом и ответом, игнорируя всю историю взаимодействия и потенциальные последствия действий агента.
Защита на уровне запросов не способна предотвратить злонамеренное использование инструментов, к которым имеет доступ агент, и не учитывает сложность многошаговых рабочих процессов. Это означает, что даже если входящий запрос и ответ кажутся безопасными, агент может быть использован для выполнения вредоносных действий посредством взаимодействия с внешними сервисами или выполнения команд, не связанных с обработкой текста. Отсутствие контекстного анализа, учитывающего последовательность действий агента и назначение используемых инструментов, создает значительные уязвимости, которые не могут быть устранены простыми фильтрами ввода-вывода.

AgentGuardian: Системный Контроль Потока Выполнения
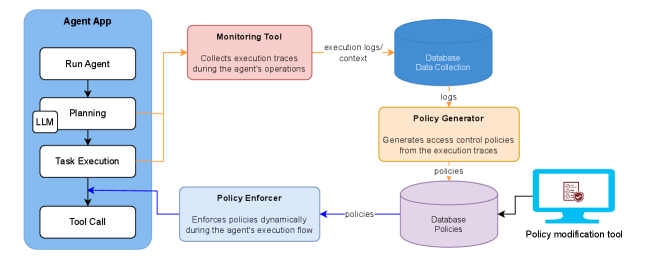
Система AgentGuardian представляет собой новый подход к обеспечению безопасности AI-агентов, объединяющий политики контроля доступа с валидацией целостности потока выполнения. В отличие от традиционных методов, фокусирующихся на отдельных запросах, AgentGuardian отслеживает и проверяет последовательность всех действий, предпринимаемых агентом. Это достигается путем определения разрешенных операций и ресурсов, к которым агент имеет доступ, и последующей проверки соответствия фактического потока выполнения этим политикам. Такой подход позволяет обнаруживать и предотвращать несанкционированные действия, даже если они возникают в результате уязвимостей в логике агента или манипуляций с входными данными.
В отличие от традиционных методов безопасности, ориентированных на проверку отдельных запросов (prompts), AgentGuardian обеспечивает защиту на уровне всей последовательности действий, выполняемых агентом. Этот подход позволяет отслеживать и контролировать не только начальный запрос, но и все последующие операции, включая вызовы API, доступ к данным и взаимодействие с другими системами. Такой мониторинг всей цепочки действий критически важен для выявления и предотвращения атак, которые могут быть замаскированы в рамках легитимного запроса, но приводят к несанкционированным или вредоносным результатам в процессе выполнения.
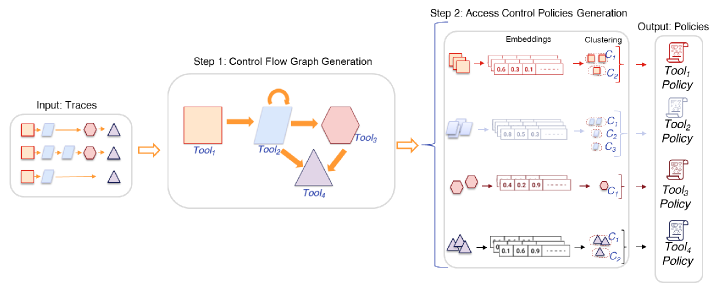
В системе AgentGuardian генерация политик доступа осуществляется автоматически на основе анализа образцов безопасного ввода с использованием регулярных выражений (Regex Patterns). Этот подход позволяет выводить правила доступа, определяющие допустимые действия агента, без необходимости ручной настройки и конфигурирования. Анализ образцов безопасного поведения позволяет системе выявить шаблоны допустимых операций, которые затем кодируются в виде политик. Автоматизация процесса генерации политик существенно снижает административную нагрузку и упрощает развертывание системы безопасности для AI-агентов, обеспечивая динамическую адаптацию к изменяющимся условиям эксплуатации.
В ходе тестирования, система AgentGuardian продемонстрировала эффективность обнаружения вредоносного поведения, достигнув частоты ложноположительных срабатываний в 10% и частоты ложноотрицательных срабатываний в 15%. В частности, из 20 смоделированных сценариев нарушения политик безопасности, AgentGuardian успешно обнаружил 18 случаев, что подтверждает её способность к точному выявлению отклонений от заданных правил и защите от потенциальных угроз. Данные показатели отражают практическую применимость системы в качестве инструмента для обеспечения безопасности AI-агентов.
В ходе тестирования AgentGuardian продемонстрировал способность снижать влияние галлюцинаций больших языковых моделей (LLM) на выполнение задач. Показатель частоты ложных отказов при выполнении безопасных операций (Benign Execution Failure Rate, BEFR) составил всего 7.5%. Это указывает на то, что система эффективно предотвращает ошибочную блокировку легитимных действий агента, вызванную неверной интерпретацией или генерацией данных LLM. Низкий показатель BEFR свидетельствует о высокой степени надежности и стабильности работы AgentGuardian в реальных сценариях использования.
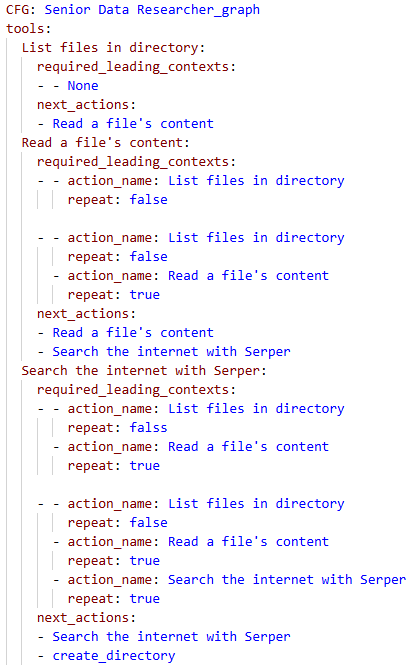
![Политика контроля доступа для агента Senior Data Researcher ограничивает чтение файлов инструментом Read File только текстовыми файлами ([.txt]) в папках Cars и AI, причем в папке AI разрешены только файлы, начинающиеся с 'ai' и заканчивающиеся на '-2025', в рабочее время с 07:33 до 20:25.](https://arxiv.org/html/2601.10440v1/Figures/rule_yaml.png)
Укрепление Системного Контроля: Взгляд в Будущее
Системное управление потоком выполнения, включающее в себя такие методы, как IsolateGPT и RTBAS, представляет собой ключевой подход к повышению безопасности агентов искусственного интеллекта. Эти технологии обеспечивают строгий контроль доступа к ресурсам и внимательный мониторинг зависимостей, существенно ограничивая потенциальный ущерб от вредоносных действий или ошибок. IsolateGPT, например, создает изолированную среду выполнения, предотвращая несанкционированный доступ к конфиденциальным данным и системным функциям. RTBAS (Runtime Behavior Analysis) непрерывно отслеживает поведение агента, выявляя аномалии и потенциальные угрозы в реальном времени. Совместное применение этих методов позволяет значительно снизить риски, связанные с эксплуатацией уязвимостей и обеспечить более надежную и предсказуемую работу агента в сложных и динамичных средах.
Система FIDES/IFC значительно усиливает защиту, предоставляя возможность планирования с учетом информационных меток. Этот подход позволяет агентам не просто выполнять задачи, но и осознанно обрабатывать конфиденциальные данные в соответствии с установленными политиками безопасности. Вместо слепого следования инструкциям, агент способен оценивать уровень доступа к информации и корректировать свои действия, чтобы избежать несанкционированного раскрытия или использования чувствительных данных. Такая «чувствительность» к меткам позволяет создавать более надежные и безопасные системы, где обработка информации происходит в строгом соответствии с требованиями конфиденциальности и целостности.
Сочетание передовых методов контроля системного уровня, таких как IsolateGPT и RTBAS, с AgentGuardian формирует эшелонированную систему защиты от разнообразных угроз. AgentGuardian выступает в роли централизованного координатора, интегрируя механизмы изоляции, мониторинга зависимостей и контроля доступа, обеспечиваемые другими компонентами. Такой подход позволяет не только предотвратить несанкционированный доступ к конфиденциальным данным и ресурсам, но и эффективно обнаруживать и нейтрализовывать потенциальные атаки на различных этапах работы агента. В результате формируется устойчивая архитектура, способная противостоять как внешним угрозам, так и внутренним уязвимостям, обеспечивая надежную и безопасную работу интеллектуальных систем.
Неизбежный риск галлюцинаций, присущий большим языковым моделям (LLM), требует непрерывного мониторинга и валидации на протяжении всего процесса выполнения агента. Это связано с тем, что LLM могут генерировать неточные или вводящие в заблуждение ответы, даже если они кажутся правдоподобными. Для смягчения этой проблемы необходима постоянная проверка сгенерированного контента на соответствие фактическим данным и заданным ограничениям. Механизмы валидации могут включать в себя сверку с внешними источниками информации, использование экспертных систем для оценки достоверности, а также применение статистических методов для выявления аномалий. Постоянный мониторинг позволяет оперативно обнаруживать и корректировать любые отклонения от ожидаемого поведения, обеспечивая надежность и безопасность работы агента, основанного на LLM.
Исследование, представленное в данной работе, демонстрирует закономерную сложность систем, управляющих агентами искусственного интеллекта. Авторы стремятся не просто создать инструменты контроля, но и сформировать экосистему, способную адаптироваться к непредсказуемым проявлениям больших языковых моделей. Как точно подметил Джон фон Нейман: «В науке не бывает готовых ответов, только более или менее обоснованные предположения». AgentGuardian, автоматизируя генерацию политик доступа и обеспечивая целостность потока выполнения, пытается предвидеть и смягчить последствия потенциальных сбоев, вызванных как злонамеренными входными данными, так и «галлюцинациями» моделей. Каждый новый деплой — это маленькое подтверждение этого принципа, проверка архитектурного пророчества на прочность.
Куда Ведет Эта Тропа?
Представленная работа, словно опытный садовник, пытается привить порядок в хаотичном саду автономных агентов. Вместо того чтобы строить непроницаемые стены, она предлагает выращивать политику доступа, адаптирующуюся к меняющимся условиям. Однако, стоит признать, что даже самый заботливый садовник не может предвидеть все капризы погоды. Проблема галлюцинаций больших языковых моделей, хоть и смягчается, остаётся тенью, напоминающей о том, что доверие к агентам — это всегда выверенный риск.
Будущее исследований, вероятно, лежит не в создании идеальных политик, а в разработке систем, способных прощать ошибки. Устойчивость не в изоляции компонентов, а в их способности смягчать последствия сбоев друг друга. Необходимо сместить фокус с предотвращения атак на быстрое восстановление после них, создавая самовосстанавливающиеся системы, способные адаптироваться к непредвиденным обстоятельствам.
Система — это не машина, это сад; если её не поливать, вырастет техдолг. Следующим шагом представляется разработка механизмов автоматической эволюции политик доступа, способных обучаться на опыте, предвидеть потенциальные угрозы и адаптироваться к новым вызовам. Задача не в том, чтобы создать идеальный замок, а в том, чтобы вырастить гибкий и живучий сад.
Оригинал статьи: https://arxiv.org/pdf/2601.10440.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2026-01-16 20:15