Автор: Денис Аветисян
Исследователи предлагают инновационный метод символьной регрессии, позволяющий находить физически обоснованные уравнения, избегая ложных корреляций.

В статье представлена платформа PG-SR, использующая априорные ограничения и новый механизм оценки для решения проблемы ‘ловушки псевдоуравнения’ и достижения научной согласованности в процессе открытия уравнений.
Несмотря на потенциал символьной регрессии в открытии фундаментальных закономерностей, существующие подходы часто сталкиваются с проблемой так называемой «ловушки псевдоуравнений». В работе, озаглавленной ‘Prior-Guided Symbolic Regression: Towards Scientific Consistency in Equation Discovery’, предложен новый фреймворк PG-SR, который явно учитывает априорные знания и использует механизм Prior Annealing Constrained Evaluation (PACE) для направления поиска к научно обоснованным решениям. Данный подход позволяет снизить сложность пространства гипотез и гарантировать получение уравнений, соответствующих фундаментальным научным принципам. Сможет ли PG-SR стать основой для создания систем автоматического научного открытия, способных выявлять истинные закономерности в данных?
Ловушка псевдо-уравнений: Цена слепой оптимизации
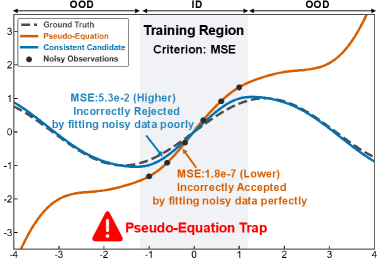
Традиционная символическая регрессия (СР) направлена на выявление уравнений, описывающих данные, однако часто в значительной степени полагается на минимизацию эмпирического риска. Этот подход, по сути, стремится найти уравнение, которое наилучшим образом соответствует наблюдаемым данным, не уделяя особого внимания физической правдоподобности или возможности обобщения полученной модели. В процессе минимизации эмпирического риска алгоритм СР оптимизируется для уменьшения расхождения между предсказанными значениями и фактическими данными в обучающем наборе. Хотя это и обеспечивает высокую точность аппроксимации, такой подход не гарантирует, что полученное уравнение отражает реальные причинно-следственные связи или фундаментальные законы природы. По сути, алгоритм может найти математически корректное, но физически бессмысленное выражение, идеально подходящее под конкретный набор данных, но бесполезное для прогнозирования или понимания явлений за его пределами. R^2 — показатель, часто используемый для оценки качества соответствия модели данным, но он не учитывает научную обоснованность полученных уравнений.
Стремление к идеальному соответствию данным, хотя и кажется привлекательным, часто приводит к так называемой «ловушке псевдо-уравнения». В этом случае, алгоритмы, оптимизирующие соответствие наблюдаемым данным, могут генерировать математические выражения, которые, несмотря на безупречную точность в рамках имеющегося набора данных, лишены научной обоснованности и не способны к предсказанию в новых, незнакомых условиях. Такие уравнения, хотя и кажутся закономерностями, на самом деле представляют собой лишь отражение статистических случайностей или скрытых корреляций, не имеющих физического смысла. R^2 показатель, будучи высоким, не гарантирует истинности полученной модели, а лишь подтверждает ее способность к интерполяции, но не к экстраполяции и обобщению. В результате, возникает опасность построения математических конструкций, которые выглядят убедительно, но не отражают фундаментальные принципы изучаемого явления.
Без учета априорных знаний, методы символьной регрессии способны выявлять ложные корреляции, которые ошибочно принимаются за фундаментальные законы природы. Алгоритмы, ориентированные исключительно на минимизацию эмпирического риска, могут находить математические зависимости, идеально описывающие имеющиеся данные, но лишенные физического смысла или способности к обобщению на новые ситуации. Например, уравнение, связывающее количество чашек выпитого кофе с успехом в игре в шахматы, может демонстрировать высокую точность на обучающей выборке, однако не отражает никакой причинно-следственной связи и не предсказывает результаты в других контекстах. Таким образом, слепое доверие к статистическим закономерностям, выявленным без учета существующих научных теорий и физических принципов, может привести к ошибочным выводам и неверным прогнозам, подменяя истинное понимание мира мнимыми закономерностями.
PG-SR: Руководство к истинным уравнениям
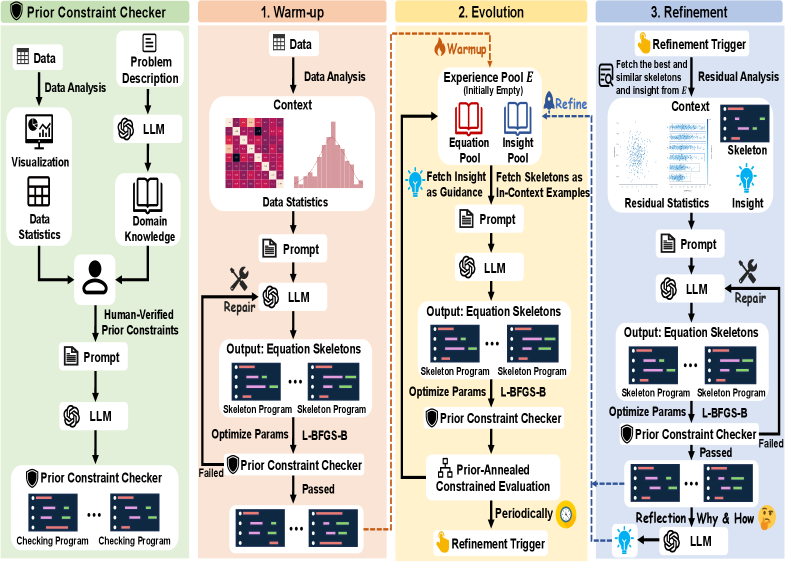
Метод символьной регрессии с предварительным руководством (PG-SR) решает проблему ложных уравнений (Pseudo-Equation Trap) путем явного включения априорных ограничений, основанных на предметных знаниях. Эти ограничения функционируют как направляющие принципы, обеспечивая соответствие обнаруженных уравнений установленным научным принципам и физическим законам. В отличие от стандартной символьной регрессии, PG-SR не полагается исключительно на случайный поиск в пространстве возможных уравнений, а использует предварительные знания для сужения этого пространства и повышения вероятности обнаружения корректных и интерпретируемых моделей. Априорные ограничения могут включать в себя известные физические константы, ожидаемые функциональные зависимости между переменными, или требования к размерности полученных уравнений.
В рамках подхода PG-SR, априорные ограничения выступают в качестве руководящих принципов, обеспечивающих соответствие обнаруженных уравнений установленным научным принципам. Эти ограничения, сформулированные на основе экспертных знаний о предметной области, позволяют существенно сократить пространство поиска возможных решений и избежать получения физически или химически нереалистичных формул. Ограничения могут включать в себя требования к размерности, типу используемых функций, диапазону допустимых значений параметров, а также соответствие известным законам сохранения, таким как закон сохранения массы или энергии. Например, при моделировании физических процессов, ограничения могут предписывать, что уравнение должно быть однородным по определенным переменным или содержать определенные физические константы. Применение априорных ограничений повышает достоверность и интерпретируемость полученных уравнений, облегчая их валидацию и применение в практических задачах.
Начальный этап, известный как «Разогрев», использует возможности больших языковых моделей (LLM) для генерации первоначальных вариантов структуры уравнений и соответствующих ограничений. LLM анализируют доступные данные и существующие знания предметной области для предложения базовых математических выражений и условий, которым должны удовлетворять искомые уравнения. Этот процесс позволяет значительно сократить пространство поиска и направить алгоритм символьной регрессии в наиболее перспективные области, избегая бесполезных вычислений и ускоряя процесс обнаружения уравнений. Предложенные LLM структуры уравнений и ограничения служат отправной точкой для последующей итеративной доработки и уточнения в рамках алгоритма PG-SR.
База опытных решений (Experience Pool) представляет собой ключевой компонент подхода PG-SR, предназначенный для хранения и систематизации промежуточных и конечных вариантов уравнений, полученных в процессе символьной регрессии. Эта база данных позволяет накапливать знания о различных функциональных зависимостях и их параметрах, а также о результатах оценки этих уравнений. Сохранение как успешных, так и неудачных кандидатов обеспечивает возможность итеративного улучшения процесса поиска, позволяя повторно использовать и модифицировать существующие уравнения вместо полного перебора вариантов. Накопленные данные в базе используются для направленной оптимизации, что существенно повышает эффективность поиска оптимальных уравнений, описывающих заданную систему, и предотвращает повторение ошибок.
Механизмы научной согласованности в PG-SR
Проверка на соответствие априорным ограничениям (Prior Constraint Checker) представляет собой ключевой механизм, обеспечивающий научную корректность генерируемых уравнений в PG-SR. Данный компонент осуществляет строгую верификацию каждого предлагаемого уравнения на соответствие заранее определенным принципам и ограничениям, заданным экспертами в соответствующей области. Уравнения, не удовлетворяющие этим критериям — например, нарушающие законы сохранения энергии или импульса, или содержащие физически невозможные параметры — немедленно отбрасываются на ранних этапах процесса поиска. Этот процесс гарантирует, что дальнейший анализ и оптимизация сосредоточены исключительно на научно обоснованных кандидатах, существенно снижая вероятность генерации псевдо-уравнений и повышая надежность полученных результатов.
Механизм PACE (Progressive Adaptive Constraint Enforcement) осуществляет динамическую регулировку строгости применяемых ограничений в процессе поиска уравнений. В начале работы, ограничения применяются с умеренной строгостью, позволяя алгоритму исследовать широкое пространство возможных решений. По мере продвижения поиска и получения предварительных результатов, PACE постепенно усиливает контроль над соблюдением ограничений, направляя процесс в области, соответствующие установленным научным принципам. Это достигается путем адаптивного изменения весовых коэффициентов, определяющих влияние каждого ограничения на функцию оценки. Таким образом, PACE способствует более эффективному и целенаправленному поиску, минимизируя вероятность генерации псевдо-уравнений и обеспечивая соответствие полученных результатов научным требованиям.
Механизм PG-SR снижает риск генерации псевдо-уравнений (Pseudo-Equations) благодаря комбинации двух ключевых подходов. Строгая проверка кандидатов на соответствие априорным ограничениям (Prior Constraints) отсеивает уравнения, нарушающие установленные научные принципы. Одновременно, адаптивное управление (PACE Mechanism) динамически регулирует строгость применения этих ограничений, постепенно направляя поиск в область научно обоснованных решений. Такое сочетание обеспечивает эффективную фильтрацию недопустимых уравнений и способствует более быстрому обнаружению валидных моделей, минимизируя вероятность получения ложных корреляций или нефизических результатов.
Радиусная сложность (Rademacher Complexity) служит теоретической основой для оценки обобщающей способности PG-SR, определяя верхнюю границу ошибки модели на невидимых данных. Наш анализ показывает, что применение механизмов, описанных в PG-SR, приводит к снижению радиусной сложности по сравнению со стандартными подходами. Уменьшение радиусной сложности RC(\mathcal{H}, S) указывает на то, что модель менее склонна к переобучению и обладает улучшенной способностью к обобщению на новые данные, где \mathcal{H} — пространство гипотез, а S — выборка данных. Полученные результаты подтверждают, что PG-SR обеспечивает более надежные и точные прогнозы за счет контроля за сложностью модели и предотвращения переобучения.
За пределами ограничений: Влияние и перспективы
Метод PG-SR представляет собой принципиально новый подход к символической регрессии, позволяющий преодолеть ограничения, присущие традиционным методам и техникам, основанным на трансформерах. В областях, где априорные знания играют важную роль, PG-SR демонстрирует повышенную эффективность за счет интеграции предварительной информации в процесс поиска уравнений. В отличие от методов, полагающихся исключительно на анализ данных, PG-SR использует знания экспертов и существующие научные принципы, что позволяет находить не только точные, но и интерпретируемые, физически обоснованные модели. Такой подход особенно ценен в сложных областях, где количество данных ограничено или где требуется понимание лежащих в основе процессов, а не просто предсказание результатов. Благодаря этому, PG-SR открывает новые возможности для научных открытий и инженерных разработок.
Данный подход позволяет не просто получать точные математические модели, но и выявлять уравнения, обладающие высокой интерпретируемостью и соответствующими фундаментальным научным принципам. В отличие от «черных ящиков», где точность достигается за счет потери понимания внутренней логики, полученные модели представляют собой прозрачные зависимости, которые можно проанализировать и использовать для углубленного изучения исследуемого явления. Это особенно важно в областях, где не только предсказательная сила, но и физический смысл полученных результатов имеет решающее значение, например, при моделировании сложных физических процессов или в биомедицинских исследованиях. Благодаря этому, y = ax^2 + bx + c или другие полученные уравнения не просто описывают данные, но и позволяют выдвигать новые гипотезы и расширять научные знания.
Интеграция символической регрессии на основе больших языковых моделей (LLM) с подходом PG-SR открывает новые возможности для научного открытия, сочетая в себе сильные стороны как анализа данных, так и экспертных знаний. В то время как LLM способны выявлять закономерности в данных, PG-SR обеспечивает структурированный способ включения априорных знаний и физических ограничений в процесс регрессии. Такое сочетание позволяет не только находить точные математические выражения, описывающие наблюдаемые явления, но и гарантировать их интерпретируемость и соответствие научным принципам. В результате, формируется система, способная генерировать не просто статистически значимые уравнения, а осмысленные и научно обоснованные модели, представляющие ценность для исследователей в различных областях, например, для поиска новых f(x) функций или проверки гипотез.
Экспериментальные исследования демонстрируют, что предложенный метод PG-SR превосходит существующие подходы к символьной регрессии в различных областях знаний. Анализ результатов, представленный в Таблице 1, показывает, что PG-SR обеспечивает более высокую точность и надежность обнаружения уравнений, описывающих исследуемые процессы. Преимущества PG-SR особенно заметны в задачах, где априорные знания играют важную роль, поскольку метод эффективно интегрирует их в процесс символического поиска. Полученные данные свидетельствуют о том, что PG-SR представляет собой перспективный инструмент для автоматизированного научного открытия и может быть успешно применен для решения сложных задач в различных областях науки и техники.
Представленная работа стремится к лаконичности и ясности в процессе обнаружения уравнений. Этот подход находит отклик в философии Пола Эрдеша, который однажды заметил: «Математика — это искусство находить закономерности, которые никто не замечал». PG-SR, вводя ограничения на основе априорных знаний, как бы «убирает лишнее», фокусируясь на тех решениях, которые не только формально соответствуют данным, но и согласуются с существующим научным пониманием. Преодоление так называемой «ловушки псевдоуравнений» демонстрирует стремление к компрессии без потерь — к нахождению наиболее элегантного и точного описания явления, избегая избыточных и бессмысленных конструкций. Это — архитектура, где каждая деталь служит цели, а сложность минимизирована.
Куда Далее?
Представленный подход, хоть и смягчает ловушку псевдо-уравнений, не устраняет её полностью. Сложность, как всегда, таится в природе самой задачи — поиск истины в шумных данных требует не только вычислительной мощи, но и философской скромности. Следующим шагом представляется не усложнение алгоритмов, а более глубокое понимание границ применимости символьной регрессии вообще. Когда же мы признаем, что не всякая зависимость требует уравнения?
Особое внимание следует уделить разработке более эффективных способов кодирования априорных знаний. Простое наложение ограничений — это лишь первый шаг. Необходимо исследовать методы, позволяющие алгоритму учиться у экспертов, а не просто следовать их указаниям. И, что более важно, необходимо научиться отличать истинное знание от предрассудков, иначе мы рискуем лишь автоматизировать собственную некомпетентность.
В конечном счете, успех этой области будет определяться не количеством найденных уравнений, а их способностью предсказывать и объяснять явления, выходящие за рамки обучающей выборки. Поиск элегантности — это не самоцель, а средство достижения ясности. Пусть же будущие исследователи помнят: лучшая модель — это та, которую можно выбросить, не потеряв ничего существенного.
Оригинал статьи: https://arxiv.org/pdf/2602.13021.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Квантовые Завихрения и Пятилетние Планы: Взгляд изнутри
- Сборка с подсказками: Искусственный интеллект и дополненная реальность на службе у мастера
- Физика под контролем: Как «научить» модели понимать мир
- Грань между Творчеством и Риском: Искусственный Интеллект и Эротический Контент
- Обучение представлений для динамических систем: новый взгляд
2026-02-16 22:05