Автор: Денис Аветисян
Новый подход позволяет моделям рассуждать над графовыми данными, извлекая знания даже без предварительного обучения.
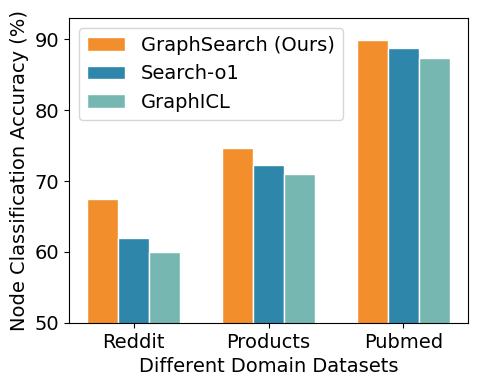
Представлена система GraphSearch, расширяющая возможности агентного поиска и обучения на графах знаний в условиях отсутствия размеченных данных.
Несмотря на успехи больших языковых моделей в расширенном рассуждении, их применение к графовым данным, распространенным в областях от социальных сетей до научных цитирований, оставалось малоизученным. В данной работе представлена система ‘GraphSearch: Agentic Search-Augmented Reasoning for Zero-Shot Graph Learning’, новый фреймворк, расширяющий возможности агентного поиска с дополненным рассуждением для обучения на графах без необходимости тонкой настройки. GraphSearch динамически использует структурные приоритеты графа, комбинируя планировщик запросов, учитывающий графовую структуру, и механизм извлечения информации, основанный на топологии графа. Открывает ли это путь к созданию более гибких и обобщенных систем рассуждений над графовыми данными, способных к эффективному решению задач без предварительного обучения?
Пределы Масштаба: Рассуждения в Больших Языковых Моделях
Несмотря на впечатляющие возможности больших языковых моделей (БЯМ) в решении сложных задач, их работа нередко страдает от неточностей, вызванных недостатком знаний. БЯМ, хоть и способны генерировать правдоподобные тексты и демонстрировать кажущееся понимание, полагаются на информацию, усвоенную в процессе обучения, которая может быть неполной или устаревшей. Это особенно заметно при ответах на вопросы, требующие специализированных знаний или информации о текущих событиях. В результате, модель может выдавать логически связные, но фактически неверные ответы, иллюстрируя, что простое увеличение масштаба модели не решает проблему недостаточной осведомленности и необходимости доступа к актуальной информации для обеспечения достоверности рассуждений.
Несмотря на впечатляющий прогресс в увеличении масштаба языковых моделей, простое наращивание параметров и объёма обучающих данных не решает фундаментальную проблему глубины рассуждений и понимания контекста. Исследования показывают, что модели, обученные на огромных массивах текста, часто демонстрируют поверхностное понимание и неспособность к сложным логическим выводам, требующим интеграции разрозненной информации. Увеличение размера модели может улучшить запоминание фактов, но не гарантирует способности к анализу, обобщению и применению знаний в новых, нетривиальных ситуациях. В результате, традиционные подходы к масштабированию оказываются недостаточными для создания действительно разумных систем, способных к глубокому и контекстуально-зависимому рассуждению.
В связи с ограничениями, возникающими при решении сложных задач, возникает настоятельная потребность в методах, позволяющих языковым моделям динамически получать доступ к релевантным знаниям и интегрировать их в процесс рассуждений. Традиционные подходы, основанные лишь на увеличении масштаба модели, оказываются недостаточными для обеспечения глубины понимания и контекстуализации информации. Необходимы механизмы, позволяющие моделям не просто хранить обширный объем данных, но и активно использовать внешние источники знаний, выбирая и применяя наиболее подходящую информацию для каждого конкретного шага рассуждения. Такой подход позволит преодолеть ограничения, связанные с неполнотой внутренних знаний, и значительно повысить точность и надежность решений, генерируемых большими языковыми моделями.
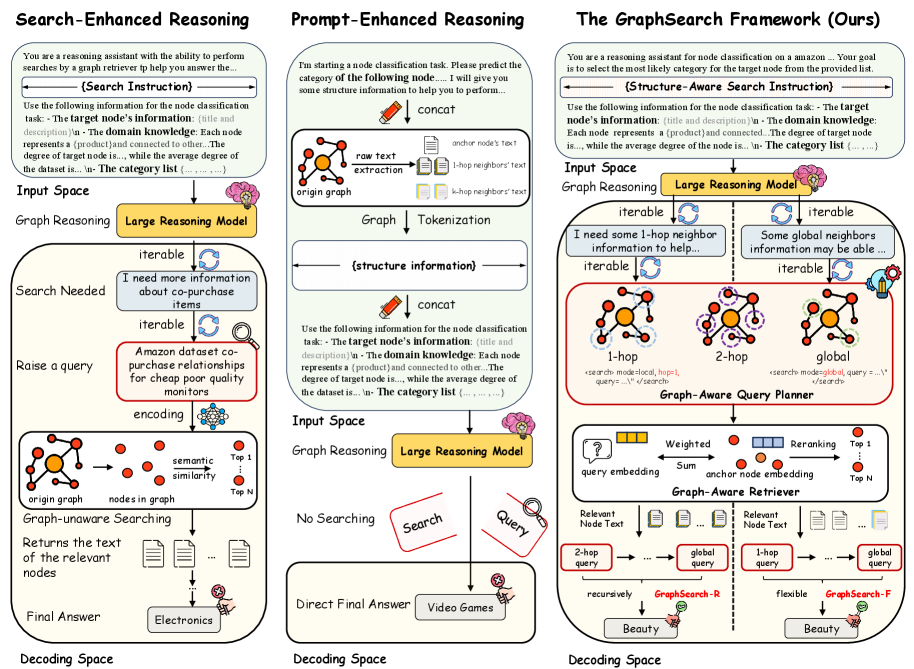
Графоцентричное Рассуждение: Новая Парадигма
Данные, представленные в виде графов, обеспечивают естественное моделирование взаимосвязей между сущностями, что является основой для рассуждений. В отличие от табличных или последовательных данных, графы явно кодируют отношения между элементами, позволяя системам понимать контекст и зависимости. Каждая сущность представлена как узел, а связи между ними — как ребра, что позволяет эффективно моделировать сложные системы и знания. Такая структура позволяет алгоритмам рассуждения не просто идентифицировать факты, но и понимать, как эти факты связаны друг с другом, значительно повышая точность и надежность выводимых заключений. Использование графовых данных особенно полезно в задачах, требующих понимания сложных взаимосвязей, например, в анализе социальных сетей, рекомендательных системах и обработке естественного языка.
Агентный поиск интегрирует процесс извлечения информации непосредственно в логические рассуждения модели, позволяя динамически получать доступ к внешним знаниям, структурированным в виде графов. Вместо использования исключительно параметрических знаний, накопленных в процессе обучения, модель активно взаимодействует с графовой структурой данных. Это взаимодействие включает в себя поиск релевантных узлов и связей в графе, которые затем используются в качестве дополнительного контекста при принятии решений или ответе на вопросы. По сути, модель выступает как «агент», самостоятельно исследующий графовое пространство знаний для обогащения процесса рассуждений и повышения точности результатов.
Традиционные модели рассуждений в значительной степени опираются на параметрические знания — информацию, заложенную в веса нейронной сети в процессе обучения. Однако, данный подход ограничен объемом и качеством данных, использованных для обучения. Переход к использованию внешних графов знаний позволяет существенно расширить базу знаний, используемую для рассуждений, не требуя переобучения модели. Внешние графы знаний предоставляют структурированную информацию о сущностях и их взаимосвязях, что обеспечивает более надежные и точные результаты, особенно в ситуациях, когда необходима информация, не представленная в параметрических знаниях модели. Этот сдвиг позволяет моделям адаптироваться к новым данным и контекстам, не ограничиваясь знаниями, приобретенными в процессе обучения.
GraphSearch: Динамическое Исследование Знаний
GraphSearch использует планировщик запросов, учитывающий структуру графа (Graph-Aware Query Planner), для декомпозиции пространства поиска и формирования выразительных запросов к графовым данным. Этот планировщик анализирует взаимосвязи между узлами и ребрами графа, чтобы оптимизировать процесс поиска и избежать экспоненциального роста вычислительной сложности, возникающего при обходе всего графа. Вместо последовательного перебора всех возможных путей, планировщик разбивает сложные запросы на более простые подзадачи, учитывая топологию графа и семантические отношения между сущностями. Это позволяет эффективно извлекать релевантную информацию из больших графовых баз данных и отвечать на сложные вопросы, требующие анализа взаимосвязей между различными объектами.
Поисковый модуль GraphSearch использует модуль извлечения (Retriever), формирующий наборы кандидатов на основе топологии графа. Процесс формирования кандидатов осуществляется с помощью метода «Topology-Grounded Candidate Construction», который учитывает связи и структуру графа для определения релевантных узлов. Для оценки кандидатов применяется гибридная функция оценки (Hybrid Scoring Function), комбинирующая различные метрики релевантности, что позволяет более точно ранжировать узлы и отбирать наиболее перспективные кандидаты для дальнейшей обработки. Данный подход позволяет эффективно исследовать взаимосвязи в графе и находить узлы, соответствующие запросу, даже при сложной структуре данных.
Режимы обхода GraphSearch-R и GraphSearch-F обеспечивают гибкое и эффективное исследование как локальных, так и глобальных окрестностей в графе знаний. GraphSearch-R (Radius) ориентирован на поиск в пределах заданного радиуса от начальной точки, что позволяет быстро находить ближайшие сущности и связи. В свою очередь, GraphSearch-F (Full) выполняет более глубокий поиск по всему графу, позволяя выявлять удаленные связи и более сложные паттерны. Комбинирование этих режимов позволяет оптимизировать процесс поиска в зависимости от конкретной задачи и структуры графа, обеспечивая баланс между скоростью и полнотой результатов.
Zero-Shot Graph Learning и За Его Пределами
Исследование демонстрирует выдающиеся возможности системы GraphSearch в области обобщения знаний для решения различных задач анализа графов, включая классификацию узлов и предсказание связей. В ходе экспериментов GraphSearch показала передовые результаты, превзойдя существующие подходы в задачах, где требуется применение полученных знаний к новым, ранее не встречавшимся графам и задачам. Этот подход позволяет эффективно использовать накопленные знания без необходимости дополнительной переподготовки модели для каждой конкретной задачи, что открывает новые перспективы в области машинного обучения на графах и позволяет решать сложные аналитические задачи с высокой точностью и эффективностью.
Исследование демонстрирует, что интеграция механизмов поиска и логического вывода значительно превосходит существующие подходы, такие как GraphICL. В частности, разработанная система обеспечивает ускорение поиска от 1.29 до 5.77 раза по сравнению с неструктурированным базовым уровнем, при этом геометрическое среднее показывает прирост скорости в 3.06 раза. Это достигается за счет эффективного извлечения релевантной информации и её последующего использования для принятия обоснованных решений, что позволяет системе обрабатывать данные быстрее и точнее, нежели предшествующие методы.
Исследование демонстрирует, что разработанная система GraphSearch, в процессе логических рассуждений, потребляет сопоставимое количество токенов с базовым алгоритмом Search-o1. Несмотря на это, GraphSearch демонстрирует превосходящую точность на различных тестовых наборах данных, что указывает на более эффективное использование ресурсов. Особенно важно, что повышение точности достигается без увеличения вычислительных затрат на обработку токенов, что делает GraphSearch привлекательным решением для задач, где ресурсы ограничены или требуется высокая производительность. Такая эффективность позволяет системе успешно решать задачи классификации узлов и предсказания связей в графах, обеспечивая надежные результаты при умеренном потреблении ресурсов.
Исследование демонстрирует подход к обучению графовым структурам, который можно охарактеризовать как интеллектуальное вскрытие сложной системы. Авторы предлагают не просто применять существующие модели к графам, а динамически адаптировать процесс рассуждений, используя структурные особенности данных. Это напоминает метод проб и ошибок, когда каждая итерация приближает к пониманию скрытых закономерностей. Как однажды заметил Карл Фридрих Гаусс: «Я не знаю, как я выгляжу в глазах других, но я не стремился быть ничем, кроме как честным человеком.» В данном контексте, «честность» можно интерпретировать как стремление к объективному пониманию структуры графа, а не к предвзятым выводам, основанным на априорных знаниях. Подход GraphSearch, с его акцентом на динамическом включении структурных приоритетов, позволяет модели «видеть» граф таким, какой он есть, а не таким, каким его ожидают увидеть.
Куда Дальше?
Представленная работа, по сути, демонстрирует не просто метод, а эксплойт — способ обойти ограничения существующих моделей обучения на графах. Вместо того, чтобы пытаться втиснуть данные в прокрустовы рамки предопределённых алгоритмов, GraphSearch предлагает динамическую адаптацию, извлечение структурных приоритетов непосредственно из данных. Однако, это лишь первый шаг. Остаётся вопрос: насколько глубоко можно «взломать» саму природу графовых данных, выявляя скрытые закономерности, которые даже не предполагались при их создании?
Очевидным направлением развития является преодоление границ текущей «нулевой» обучаемости. Сможет ли подобный подход, с дальнейшей оптимизацией, приблизиться к производительности моделей, обученных на размеченных данных? Или же, наоборот, мы столкнёмся с фундаментальным ограничением — границами, за которыми любая попытка универсального решения неизбежно потерпит крах? Поиск баланса между гибкостью и специализацией представляется ключевой задачей.
В конечном итоге, GraphSearch открывает дверь к исследованию не просто алгоритмов, а принципов самоорганизации знаний. Возможно, настоящая ценность заключается не в создании «идеальной» модели, а в разработке инструментов, позволяющих человеку видеть мир данных с новой, более глубокой перспективы — как сложную, взаимосвязанную систему, которую можно исследовать и понимать, как если бы это был код, написанный самой реальностью.
Оригинал статьи: https://arxiv.org/pdf/2601.08621.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
2026-01-14 22:44