Автор: Денис Аветисян
Новый подход к семантическому поиску в интернет-магазинах позволяет понимать сложные запросы пользователей, сформулированные естественным языком.
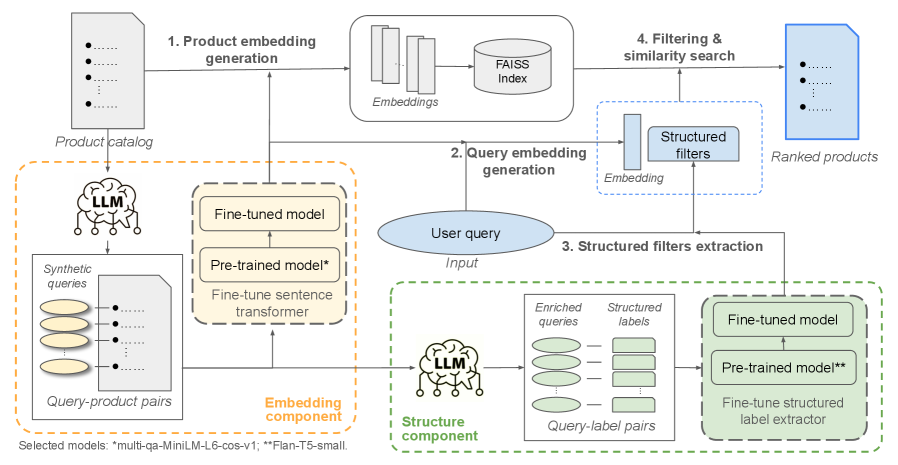
В статье рассматривается LLM-основанный фреймворк, использующий синтетические данные для повышения релевантности результатов поиска в электронной коммерции.
Традиционные поисковые системы электронной коммерции испытывают затруднения при обработке сложных запросов, сформулированных в форме естественного диалога. В статье ‘LLM-based Semantic Search for Conversational Queries in E-commerce’ предложен новый подход к семантическому поиску, основанный на использовании больших языковых моделей (LLM) для более точного понимания намерений пользователя. Разработанная система эффективно сочетает семантическое представление продуктов с фильтрацией по структурированным атрибутам, используя синтетические данные для обучения моделей. Способна ли эта архитектура значительно повысить релевантность результатов поиска и улучшить пользовательский опыт в сфере онлайн-торговли?
За пределами Ключевых Слов: Эволюция Семантического Поиска в Электронной Коммерции
Традиционные системы поиска в электронной коммерции долгое время опирались на сопоставление ключевых слов, что зачастую приводило к неточным результатам и разочарованию пользователей. Вместо того чтобы понимать, что именно ищет покупатель, система просто идентифицировала товары, содержащие заданные слова. Например, запрос “красные кроссовки для бега” мог выдать как красные кроссовки, так и красные туфли, или даже товары, содержащие слово “красный” в описании, но не являющиеся обувью. Такая зависимость от буквального соответствия слов игнорировала контекст и намерение пользователя, приводя к нерелевантным предложениям и снижению конверсии. В результате, покупатели тратили больше времени на поиск нужного товара, а продавцы теряли потенциальных клиентов из-за неэффективности поисковой системы.
Современные покупатели ожидают от интернет-магазинов взаимодействия, имитирующего естественный диалог, и простого ввода ключевых слов уже недостаточно для успешного поиска. Вместо сопоставления слов, эффективная электронная коммерция требует понимания смысла, который пользователь вкладывает в свой запрос. Это означает, что системы поиска должны анализировать контекст, учитывать синонимы и даже предвидеть потребности покупателя, чтобы предлагать действительно релевантные товары. Такой подход позволяет выйти за рамки буквального поиска и обеспечить более персонализированный и удобный опыт, значительно повышая вероятность совершения покупки.
Семантический поиск представляет собой принципиально новый подход к поиску в интернет-магазинах, смещая акцент с простого сопоставления ключевых слов на понимание истинных намерений пользователя. Вместо того чтобы искать товары, буквально соответствующие введенным словам, система анализирует контекст запроса, включая смысл, взаимосвязи между понятиями и даже предыдущие действия пользователя. Это позволяет выдавать гораздо более релевантные результаты, даже если запрос сформулирован неточно или содержит синонимы. Например, запрос «удобные кроссовки для бега по пересеченной местности» будет обработан с учетом не только слов, но и подразумеваемой потребности в амортизации, прочности и специфическом типе подошвы. В итоге, семантический поиск не просто находит товары, но и предлагает решения, удовлетворяющие потребности покупателя, значительно повышая вероятность совершения покупки и формируя положительный пользовательский опыт.
Кодирование Смысла: Предложения-Трансформеры и Эффективное Сравнение
Преобразователи предложений (Sentence Transformers) преобразуют текстовые данные в плотные векторные представления фиксированной длины, кодируя семантическое значение текста. В отличие от традиционных методов, таких как TF-IDF или Word2Vec, эти векторы отражают общее значение предложения, а не просто частоту или сочетание слов. Это позволяет проводить эффективные сравнения семантической близости между различными текстами, вычисляя косинусное расстояние или другие метрики сходства между их векторными представлениями. Чем меньше расстояние, тем более семантически близки предложения, что делает данный подход особенно полезным для задач поиска, кластеризации и анализа текстовых данных.
Использование предварительно обученной модели, такой как Multi-QA-MiniLM-L6-COS-V1, обеспечивает надежную отправную точку для задач семантического поиска. Данная модель представляет собой компромисс между точностью и вычислительной эффективностью, позволяя добиться приемлемых результатов при ограниченных ресурсах. Multi-QA-MiniLM-L6-COS-V1, разработанная на основе архитектуры Transformer, обучена на большом объеме данных, что позволяет ей эффективно кодировать семантическое значение текста в компактные векторные представления. Оптимизация модели включает в себя использование косинусного сходства (COS) для повышения скорости вычислений и уменьшения размера векторов, что особенно важно при работе с большими объемами данных и ограниченными вычислительными мощностями.
Для работы с большими каталогами товаров критически важен эффективный поиск по семантической схожести. Библиотека FAISS (Facebook AI Similarity Search) используется для быстрого поиска наиболее релевантных товаров, основываясь на векторных представлениях, полученных с помощью Sentence Transformers. FAISS реализует оптимизированные алгоритмы индексирования и поиска ближайших соседей в многомерном пространстве, позволяя значительно сократить время отклика при поиске в каталогах, содержащих миллионы или миллиарды элементов. Это достигается за счет использования квантования векторов и других техник приближенного ближайшего соседа (Approximate Nearest Neighbor, ANN), что позволяет находить близкие векторы с высокой скоростью, жертвуя незначительной точностью.
Расшифровка Намерений: Извлечение Структурированных Фильтров из Запросов
Определение намерения пользователя является критически важным этапом для повышения релевантности результатов поиска, позволяя применять структурированные фильтры. Анализ запроса с целью выявления потребностей пользователя позволяет автоматически извлекать такие параметры, как ценовой диапазон, цвет, размер или другие характеристики, определяющие искомый товар или услугу. Применение этих фильтров сужает область поиска, отсеивая нерелевантные результаты и предоставляя пользователю более точные и соответствующие его запросу данные. Эффективное определение намерения пользователя значительно повышает точность и полноту поиска, улучшая пользовательский опыт и сокращая время, необходимое для нахождения необходимой информации.
Модель Flan-T5-small, относящаяся к классу sequence-to-sequence, демонстрирует высокую эффективность в автоматизированном извлечении структурированных фильтров из поисковых запросов пользователей. Данная модель, основанная на архитектуре Transformer, способна преобразовывать текстовый запрос в набор структурированных данных, определяющих необходимые фильтры, такие как ценовой диапазон, цвет или размер. Процесс извлечения фильтров осуществляется путем обучения модели на большом корпусе данных, содержащем примеры запросов и соответствующих им структурированных фильтров. В результате, Flan-T5-small позволяет автоматически определять и применять релевантные фильтры к поисковым запросам, повышая точность и полноту выдаваемых результатов.
Автоматизированное извлечение структурированных фильтров из поисковых запросов демонстрирует значительное улучшение показателей точности (precision) и полноты (recall) по сравнению с базовыми методами. Экспериментальные данные показывают, что система, использующая Flan-T5-small, обеспечивает более релевантные результаты поиска за счет автоматического определения и применения фильтров, таких как ценовой диапазон или цвет, непосредственно из запроса пользователя. Это позволяет уменьшить количество нерелевантных результатов и повысить вероятность нахождения искомой информации, что особенно важно для больших объемов данных и сложных поисковых запросов.
Основанный на Данных Валидация и Увеличение
Тщательная оценка эффективности семантического поиска осуществлялась на основе общедоступных наборов данных, таких как ESCI Dataset и Amazon Reviews Dataset. ESCI Dataset, специально разработанный для оценки систем поиска, содержит сложные запросы и релевантные документы, требующие глубокого понимания смысла. Amazon Reviews Dataset, в свою очередь, представляет собой обширный источник пользовательских отзывов, позволяющий оценить способность системы находить релевантную информацию в неструктурированном текстовом формате. Использование этих разнообразных наборов данных гарантирует всестороннюю проверку возможностей системы и позволяет выявить ее сильные и слабые стороны в различных сценариях поиска.
Для преодоления проблем, связанных с недостатком данных или их предвзятостью, применялась методика генерации синтетических данных с использованием больших языковых моделей (LLM). Этот подход позволил значительно расширить обучающую выборку, создавая реалистичные примеры, которые дополняют существующие данные. Использование LLM для синтеза данных позволило не только увеличить объем обучающей выборки, но и снизить вероятность переобучения модели на ограниченном наборе реальных данных, что, в свою очередь, способствует повышению ее обобщающей способности и устойчивости к новым, ранее не встречавшимся запросам.
Увеличение объема обучающей выборки за счет сгенерированных данных существенно повышает устойчивость и обобщающую способность системы семантического поиска. Результаты тестирования демонстрируют превосходство разработанного подхода над базовыми методами: достигнута точность Precision@k=1 на уровне 0.32, Precision@k=5 — 0.20, а также полнота Recall@k=5, равная 0.44. Эти показатели свидетельствуют о способности системы эффективно находить релевантные результаты даже при неполных или зашумленных запросах, что делает её более надежной и полезной для пользователей.
Практические Соображения: Защита Устройств в Электронной Коммерции
В настоящее время электронная коммерция все чаще осуществляется с использованием мобильных устройств, что закономерно вызывает вопросы о надежности и устойчивости этих устройств к различным внешним воздействиям. Повышенная мобильность, использование гаджетов в различных условиях — от повседневной суеты до активного отдыха — значительно увеличивает риск повреждений, связанных с ударами, падениями и воздействием влаги. Поэтому, обеспечение долговременной работоспособности смартфона или планшета становится ключевым фактором для комфортного и бесперебойного онлайн-шопинга, ведь поломка устройства может не только прервать процесс покупки, но и привести к потере ценной информации и финансовых средств.
Водонепроницаемые чехлы, соответствующие стандартам, таким как IP68, представляют собой важный элемент защиты для мобильных устройств, используемых в самых разных условиях. Данный стандарт гарантирует полную защиту от пыли и возможность длительного пребывания под водой, что особенно актуально для пользователей, ведущих активный образ жизни или работающих в сложных средах. В отличие от водоотталкивающих покрытий, чехлы IP68 обеспечивают герметичную защиту, предотвращая попадание влаги и повреждение внутренних компонентов устройства. Благодаря этому, потребители могут быть уверены в надежности и долговечности своих гаджетов, даже при случайном попадании в воду или использовании в условиях повышенной влажности, что значительно повышает ценность приобретаемого товара.
Интеграция заботы о защите устройств непосредственно в платформы электронной коммерции значительно улучшает пользовательский опыт и демонстрирует практичный подход к потребностям клиентов. Включение информации о водонепроницаемых чехлах, ударопрочных материалах или рекомендаций по страхованию от повреждений не только повышает ценность предложения, но и формирует доверие к продавцу, заботящемуся о долговечности приобретенного товара. Такой подход выходит за рамки простой продажи, подчеркивая готовность компании предусмотреть потенциальные риски и предложить решения, что особенно актуально для мобильных устройств, используемых в разнообразных условиях повседневной жизни. В конечном итоге, учет защиты устройств становится конкурентным преимуществом, укрепляющим лояльность клиентов и способствующим положительной репутации бренда.
Представленное исследование демонстрирует стремление к редукции сложности в области электронной коммерции. Авторы предлагают систему, использующую большие языковые модели для улучшения семантического поиска, фокусируясь на синтетических данных для повышения релевантности результатов. Это соответствует принципу упрощения: вместо добавления новых параметров, система очищается от избыточности, чтобы более точно соответствовать запросу пользователя. Как однажды заметил Джон Маккарти: «Наилучшая вещь о предсказании будущего — это то, что оно никогда не наступает». Эта фраза, хоть и не напрямую связана с семантическим поиском, отражает стремление к ясности и точности, исключая ненужные сложности в прогнозировании и, соответственно, в предоставлении релевантных результатов поиска.
Куда же дальше?
Представленная работа, как и большинство, лишь обнажает сложность кажущегося простого вопроса. Улучшение семантического поиска в электронной коммерции посредством больших языковых моделей и синтетических данных — шаг, несомненно, полезный, но лишь отодвигающий истинную проблему. Недостаточно лишь “понимать” запрос; необходимо понимать, зачем он задан. Глубинная мотивация пользователя, скрытая за словами, остаётся областью, требующей куда более изысканных методов, чем простое сопоставление векторных представлений.
Упор на синтетические данные, хотя и оправдан в условиях ограниченности размеченных примеров, таит в себе опасность самообмана. Чем искусственнее данные, тем тоньше грань между “пониманием” и “имитацией”. Следующим этапом представляется не увеличение объёма синтетики, а разработка методов, позволяющих моделям самостоятельно извлекать знания из неструктурированных источников — отзывов, обсуждений, социальных сетей — и верифицировать их достоверность.
В конечном итоге, задача заключается не в создании “умного” поиска, а в создании системы, способной к интеллектуальной скромности. Система должна признавать границы своего знания, предлагать альтернативные варианты и, главное, не заменять собой человеческое любопытство и критическое мышление. Иначе, все эти языковые модели превратятся лишь в изощрённые инструменты для манипуляции.
Оригинал статьи: https://arxiv.org/pdf/2601.16492.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-27 05:34