Автор: Денис Аветисян
Исследователи представили сложный тест, демонстрирующий, как хорошо большие языковые модели способны планировать и использовать реальные знания для решения задач, требующих долгосрочной стратегии.
LLM-WikiRace: бенчмарк для оценки долгосрочного планирования и рассуждений на основе графов знаний.
Несмотря на впечатляющий прогресс в области больших языковых моделей (LLM), их способность к долгосрочному планированию и использованию знаний реального мира остается ограниченной. В работе ‘LLM-WikiRace: Benchmarking Long-term Planning and Reasoning over Real-World Knowledge Graphs’ представлен новый бенчмарк, LLM-WikiRace, оценивающий способность моделей последовательно перемещаться по гиперссылкам Википедии для достижения целевой страницы. Результаты показывают, что хотя модели демонстрируют сверхчеловеческую производительность на простых задачах, их эффективность резко снижается при повышении сложности, подчеркивая необходимость улучшения навыков адаптивного перепланирования. Какие новые подходы к обучению и архитектуре позволят LLM эффективно решать задачи, требующие глубокого понимания мира и стратегического планирования на больших горизонтах?
Вызов многоступенчатого рассуждения в больших языковых моделях
Несмотря на впечатляющие возможности, большие языковые модели зачастую испытывают трудности при решении сложных, многоступенчатых задач, требующих последовательного применения логических выводов. Это проявляется не в отсутствии знаний, а в неспособности эффективно организовать и применить имеющуюся информацию для достижения конкретной цели. Модели могут успешно оперировать отдельными фактами, но сталкиваются с проблемами при построении целостной картины и планировании действий на несколько шагов вперед. Данная сложность обусловлена архитектурными ограничениями и недостаточной способностью к абстрактному мышлению, что препятствует эффективному решению задач, требующих не просто извлечения информации, а её синтеза и творческого применения.
Несмотря на обширные знания о мире, которыми обладают большие языковые модели, часто наблюдается неэффективность в применении этих знаний для решения сложных задач. Модели могут хранить огромное количество фактов и связей, однако испытывают трудности с их логической организацией и последовательным использованием для достижения конкретной цели. Это проявляется в неспособности эффективно выстраивать цепочку рассуждений, что приводит к ошибкам даже в задачах, требующих лишь базового логического вывода. Проблема заключается не в отсутствии информации, а в сложностях с ее обработкой и применением в контексте многоступенчатых проблем, требующих планирования и адаптации к меняющимся обстоятельствам. Таким образом, хотя модели и демонстрируют впечатляющий объем знаний, их способность к эффективному применению этих знаний для решения комплексных задач остается существенным ограничением.
Особая сложность для больших языковых моделей представляет собой построение последовательных, долгосрочных планов. Исследования показывают, что, обладая огромным объемом знаний о мире, модели испытывают трудности в их эффективном применении для решения задач, требующих нескольких шагов и прогнозирования последствий на отдалённое будущее. Неспособность поддерживать когерентную логическую цепочку при планировании, особенно когда необходимо учитывать множество переменных и их взаимосвязь, приводит к ошибкам и неоптимальным решениям. В отличие от людей, способных к абстрактному мышлению и моделированию будущих событий, модели зачастую застревают на текущем этапе, не предвидя возможных препятствий или альтернативных путей достижения цели. Данное ограничение критически важно для задач, требующих стратегического планирования и адаптации к меняющимся обстоятельствам.
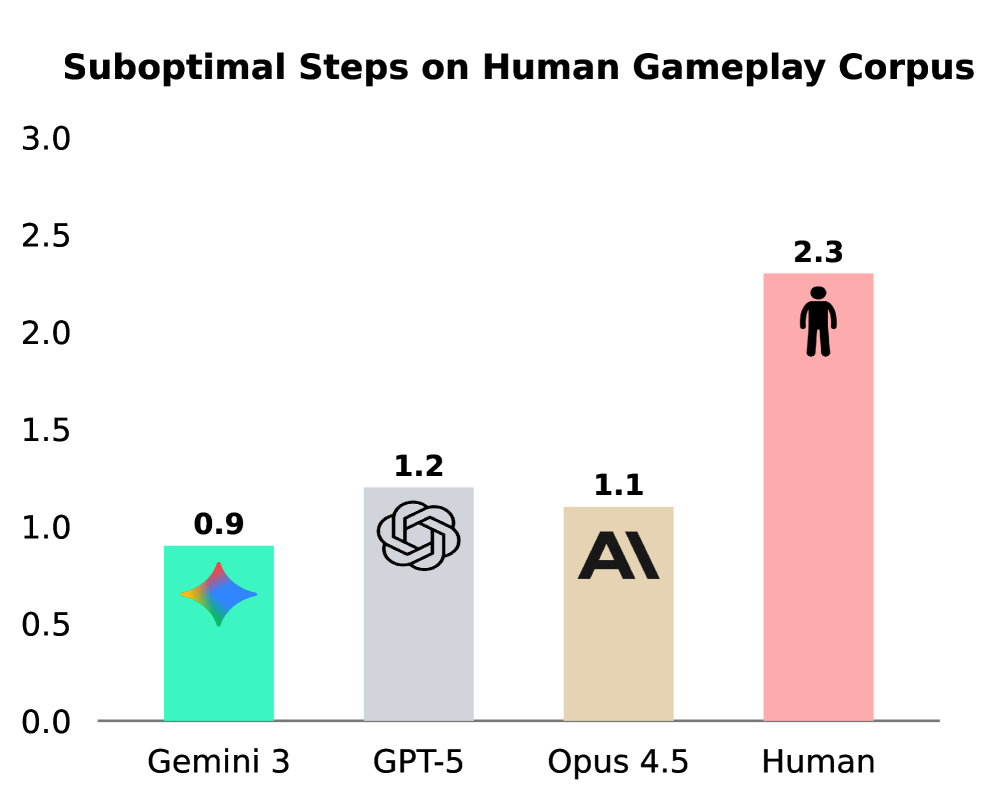
Несмотря на впечатляющие результаты в решении задач, представленных в Human Gameplay Corpus, где современные языковые модели превосходят человеческие показатели (достигая 100% успеха против 98,5%), их возможности в адаптивном рассуждении остаются ограниченными. Данный феномен указывает на существенный пробел в способности моделей к эффективному планированию и решению более сложных, многоступенчатых проблем, требующих гибкого подхода и учета меняющихся обстоятельств. Достижение совершенства в узкоспециализированных наборах данных не гарантирует универсальную способность к рассуждению, а подчеркивает необходимость разработки новых подходов, позволяющих моделям переносить навыки решения задач на более широкую и сложную палитру ситуаций.
LLM-WikiRace: Бенчмарк для оценки планирования и навигации
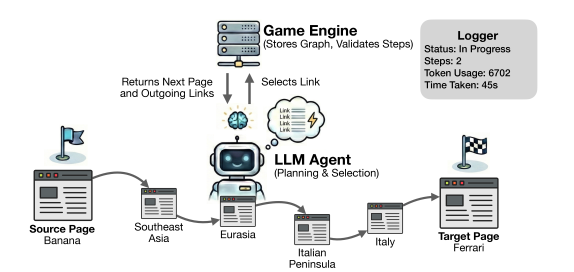
LLM-WikiRace использует граф гиперссылок Википедии в качестве сложной среды для оценки возможностей многошагового рассуждения. Этот граф представляет собой обширную сеть взаимосвязанных статей, что требует от моделей не только извлечения информации, но и планирования последовательности действий для достижения поставленной цели. Сложность заключается в огромном размере графа, неструктурированности информации и необходимости выбора оптимального пути среди множества возможных переходов по ссылкам. Использование Википедии в качестве тестовой среды позволяет оценить способность моделей к обобщению знаний и адаптации к новым, непредсказуемым ситуациям, что делает LLM-WikiRace эффективным инструментом для анализа и улучшения алгоритмов многошагового рассуждения.
Бенчмарк LLM-WikiRace предполагает, что модели должны перемещаться между страницами Википедии, используя гиперссылки, для достижения заданной цели. Этот процесс требует от модели не просто извлечения информации, но и построения последовательного плана действий, адаптирующегося к структуре графа гиперссылок. Успешное выполнение задачи подразумевает определение релевантных ссылок на каждом шаге и их последовательное использование для приближения к целевой странице, что делает акцент на способности модели к долгосрочному планированию и принятию решений в динамической среде. Отсутствие четкого плана приводит к неэффективному использованию ресурсов и увеличению количества шагов, необходимых для достижения цели.
Оценка в LLM-WikiRace основывается на количественных показателях, таких как количество неоптимальных шагов (Suboptimal Steps) и эффективность достижения целевой страницы. Количество неоптимальных шагов измеряет, насколько отклоняется путь модели от кратчайшего пути к цели, в то время как эффективность отражает общую длину маршрута. Эти метрики позволяют объективно оценить способность модели к планированию и поиску оптимальных решений в графе гиперссылок Википедии, предоставляя измеримый показатель навыков планирования и эффективности навигации.
Для успешной навигации в задачах, требующих многошагового планирования, недостаточно обладания знаниями; критически важна способность избегать зацикливания и находить кратчайший путь. Текущие языковые модели демонстрируют зацикливание в 66%-92% случаев при решении сложных задач, что указывает на недостаточную эффективность алгоритмов планирования и поиска оптимального маршрута в графе гиперссылок. Наблюдаемое зацикливание свидетельствует о неспособности моделей эффективно оценивать уже пройденные пути и избегать повторного посещения одних и тех же страниц, что существенно влияет на общую эффективность и скорость достижения целевой страницы.
Выявление недостатков планирования посредством анализа траекторий
Анализ траекторий моделей, протестированных на LLM-WikiRace, последовательно выявляет наличие «Пробела в планировании» — несоответствия между объемом имеющихся у модели мировых знаний и способностью эффективно использовать эти знания для построения последовательности действий, ведущих к цели. Данный пробел проявляется в том, что модели демонстрируют наличие необходимой информации для решения задачи, но при этом не способны оптимально спланировать маршрут к целевой статье, что указывает на дефицит механизмов, обеспечивающих эффективное применение знаний в процессе планирования.
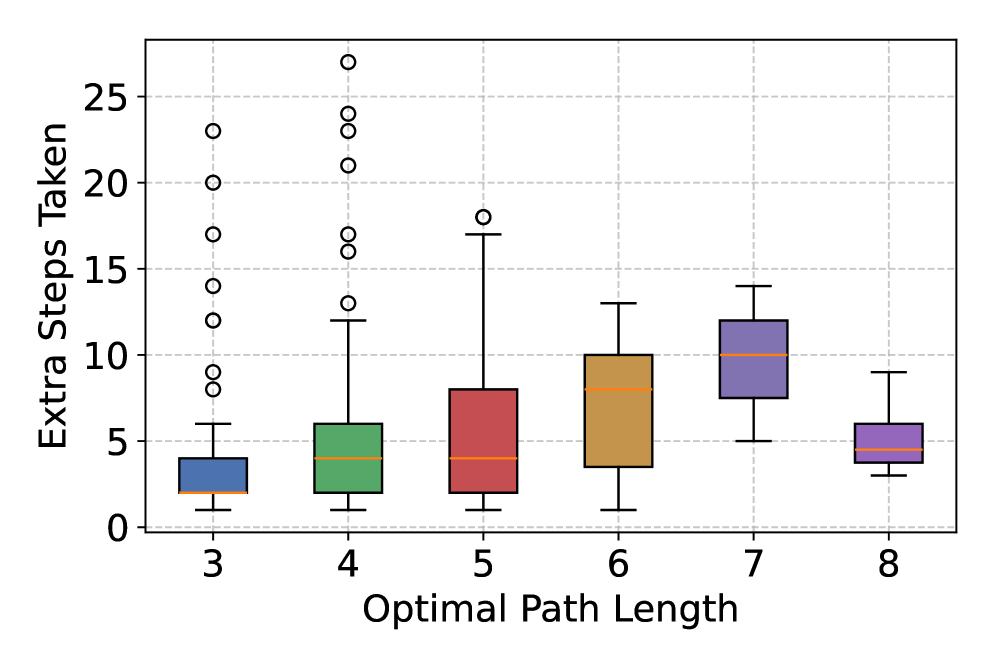
Анализ траекторий моделей на LLM-WikiRace демонстрирует, что для достижения целевого состояния им требуется значительно больше шагов, чем оптимальное количество. Данный факт указывает на неспособность эффективно планировать последовательность действий и выстраивать кратчайший путь к решению задачи. Наблюдаемое увеличение числа шагов свидетельствует о неэффективном использовании имеющихся знаний о мире и неспособности модели предвидеть последствия каждого действия, что приводит к избыточным и ненужным операциям для достижения цели.
Анализ траекторий выполнения задач на LLM-WikiRace демонстрирует склонность моделей к циклическим повторениям одних и тех же действий, что указывает на недостаток адаптивного управления и неэффективные механизмы перепланирования. Статистический анализ выявил сильную отрицательную корреляцию между частотой возникновения циклического поведения и успешностью выполнения задачи: коэффициент регрессии составил -1.02 (95% ДИ: от -1.13 до -0.91). Это означает, что увеличение частоты циклов существенно снижает вероятность достижения целевого состояния, подчеркивая необходимость разработки более надежных алгоритмов перепланирования, способных оперативно корректировать стратегию действий при возникновении тупиковых ситуаций.
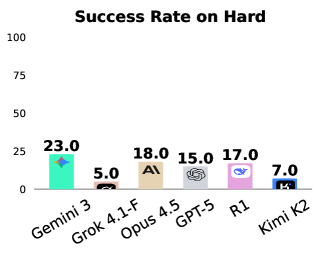
Анализ производительности моделей на LLM-WikiRace демонстрирует значительное снижение эффективности при усложнении задач. В то время как на простых экземплярах моделей достигается более 90% успешных завершений, на наиболее сложных экземплярах процент успешности опускается ниже 25%. Данный факт указывает на существенные ограничения в масштабируемости способностей к планированию, что свидетельствует о неспособности моделей эффективно применять имеющиеся знания для решения комплексных проблем, требующих многоэтапного планирования и адаптации к изменяющимся условиям.
Улучшение планирования с помощью продвинутых стратегий тонкой настройки
Методы, такие как DAPO (Decoupled clip и Dynamic sAmpling Policy Optimization), показывают перспективные результаты в улучшении производительности при решении задач планирования на платформе LLM-WikiRace. DAPO использует раздельное обучение CLIP и динамическую выборку стратегий оптимизации политики, что позволяет модели более эффективно исследовать пространство возможных действий и находить оптимальные решения. Эксперименты на LLM-WikiRace демонстрируют, что применение DAPO позволяет значительно сократить количество шагов, необходимых для достижения цели, и повысить общую эффективность планирования по сравнению со стандартными подходами.
В ходе исследований, посвященных применению методов тонкой настройки, таких как DAPO, было зафиксировано повышение эффективности и снижение количества Субоптимальных Шагов при решении задач для моделей Claude Opus 4.5, Gemini 3 и GPT-5. В частности, наблюдалось уменьшение числа итераций, необходимых для достижения оптимального решения в задачах, требующих планирования, что свидетельствует об улучшении способности моделей к последовательному и логически обоснованному принятию решений. Данные результаты подтверждают, что целенаправленная тонкая настройка является эффективным способом повышения производительности больших языковых моделей в задачах, связанных с планированием и рассуждениями.
Наблюдаемые улучшения в производительности больших языковых моделей (LLM) благодаря целенаправленному тонкому дообучению позволяют эффективно нивелировать так называемый «разрыв планирования» (Planning Gap). Этот разрыв проявляется в неспособности моделей последовательно и эффективно решать сложные задачи, требующие многоэтапного планирования. Тонкое дообучение, ориентированное на оптимизацию стратегий планирования, позволяет моделям, таким как Claude Opus 4.5, Gemini 3 и GPT-5, демонстрировать более надежные навыки рассуждения и повышать эффективность решения задач, требующих последовательных логических шагов. По сути, это позволяет LLM переходить от простого воспроизведения паттернов к более глубокому пониманию и эффективному применению стратегий для достижения поставленных целей.
Дальнейшее исследование методов расширенного тонкого дообучения, таких как DAPO, критически важно для развития более интеллектуальных и адаптируемых больших языковых моделей. Непрерывное совершенствование этих техник позволит не только улучшить эффективность планирования и снизить количество неоптимальных шагов в задачах вроде LLM-WikiRace, но и повысить общую способность моделей к рассуждению и решению сложных проблем. Продолжение исследований в этой области необходимо для преодоления разрыва в планировании и создания систем искусственного интеллекта, способных к гибкому и надежному выполнению широкого спектра задач в различных условиях.
Исследование, представленное в статье, демонстрирует, что современные большие языковые модели, обладая обширными знаниями о мире, испытывают трудности с долгосрочным планированием и адаптацией к меняющимся условиям. Это подтверждает идею о том, что структура определяет поведение системы. Как отмечал Роберт Тарьян: «Хороший алгоритм — это элегантное решение сложной задачи, а не просто набор инструкций». Подобно тому, как тщательно спроектированный алгоритм требует четкой структуры для эффективной работы, так и успешное долгосрочное планирование требует от модели способности не только хранить информацию, но и динамически перестраивать свои планы в ответ на новые данные и неожиданные препятствия. Неспособность к адаптивному перепланированию, выявленная в LLM-WikiRace, подчеркивает необходимость разработки более гибких и интеллектуальных систем планирования.
Куда двигаться дальше?
Представленная работа выявляет закономерную дихотомию: языковые модели обладают обширными знаниями о мире, но их способность к адаптивному перепланированию, к построению последовательных стратегий на больших временных горизонтах, остаётся проблематичной. Это напоминает о важности не только объёма информации, но и о структуре её организации, о механизмах, позволяющих эффективно использовать знания в динамично меняющейся среде. Каждое упрощение в архитектуре модели, каждое стремление к элегантности, имеет свою цену — потерю гибкости, снижение способности к адаптации.
Очевидным направлением дальнейших исследований представляется разработка более надёжных методов оценки и стимулирования долгосрочного планирования. Текущие метрики, как показывает опыт, не всегда отражают истинную способность модели к последовательному решению задач. Необходимо сосредоточиться на создании бенчмарков, которые требуют не просто извлечения фактов, а активного использования знаний для достижения конкретной цели, с учётом непредсказуемости реального мира.
В конечном счёте, успех в этой области будет зависеть от способности найти баланс между объёмом знаний, эффективностью алгоритмов планирования и способностью к адаптации. Стремление к изяществу должно быть подкреплено пониманием того, что сложная система требует сложного подхода, и что каждое решение является частью сети компромиссов. Иначе, даже самая обширная база знаний останется лишь пассивным грузом.
Оригинал статьи: https://arxiv.org/pdf/2602.16902.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Предел возможностей: где большие языковые модели теряют разум?
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Моделирование спектроскопии электронного пучка: новый подход
- Квантовое программирование: Карта развивающегося мира
- За пределами стандартной точности: новая структура эффективной теории
- Сердце музыки: открытые модели для создания композиций
- Тандем топ-кварков и бозона Хиггса: новые горизонты точности
- Квантовый скачок: от лаборатории к рынку
- Квантовый шум: за пределами стандартных моделей
2026-02-22 04:09