Автор: Денис Аветисян
Новый подход к обучению ИИ позволяет ему надежнее искать информацию и честно говорить, когда ответа у него нет.
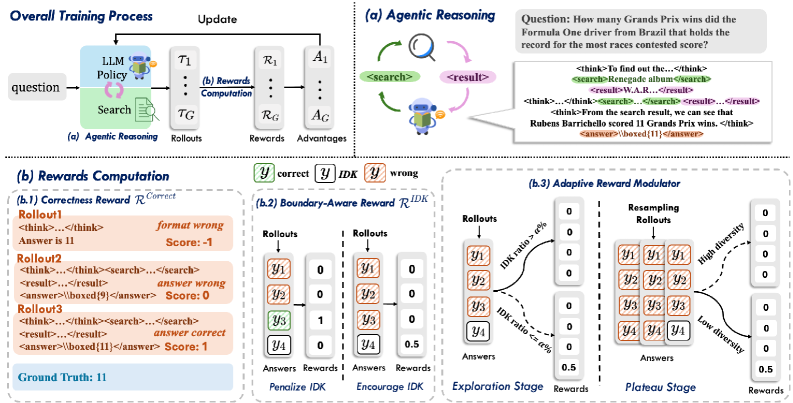
Предложена методика BAPO, оптимизирующая обучение с подкреплением для повышения надежности агентного поиска и распознавания неопределенности.
Несмотря на значительные успехи в обучении агентов на основе обучения с подкреплением для поиска информации, существующие системы часто демонстрируют неуверенность в оценке границ своей компетентности. В данной работе, ‘BAPO: Boundary-Aware Policy Optimization for Reliable Agentic Search’, предлагается новый подход к повышению надежности агентов, способных к поиску, путем развития у них способности признавать собственные ограничения и отвечать «Я НЕ ЗНАЮ», когда это необходимо. Предложенный фреймворк BAPO использует специально разработанную функцию вознаграждения и адаптивный модулятор для стимулирования осознания границ без ущерба для точности. Сможет ли BAPO обеспечить более надежные и заслуживающие доверия системы агентов для решения сложных задач?
Пределы Масштабируемости: Разум и Логика в Больших Языковых Моделях
Несмотря на впечатляющую способность больших языковых моделей распознавать закономерности в данных, сложные задачи, требующие логического мышления и глубокого понимания, часто оказываются им не под силу. Эти модели, по сути, оперируют статистическими связями, а не реальным смыслом, что приводит к ошибкам в ситуациях, требующих абстрактного мышления или знания контекста. Они могут успешно имитировать разумный ответ, но зачастую не способны объяснить почему этот ответ верен или применим, демонстрируя отсутствие истинного понимания лежащих в основе принципов. Это ограничивает их применимость в критически важных областях, где надежность и обоснованность решения имеют первостепенное значение.
Современные подходы к развитию больших языковых моделей зачастую делают ставку на увеличение их размера, что требует колоссальных вычислительных ресурсов и энергозатрат. Однако, простое увеличение числа параметров не гарантирует повышения надежности или достоверности генерируемых ответов. Исследования показывают, что модели, несмотря на впечатляющие объемы данных, на которых они обучаются, могут допускать логические ошибки, демонстрировать предвзятость или генерировать бессмысленные утверждения. Таким образом, стратегия масштабирования, хотя и позволила достичь определенных успехов в области обработки естественного языка, сталкивается с ограничениями и требует поиска альтернативных методов, направленных на повышение не только производительности, но и надежности и доверия к результатам работы моделей.
Осознание Границ: Знание того, Чего Ты Не Знаешь
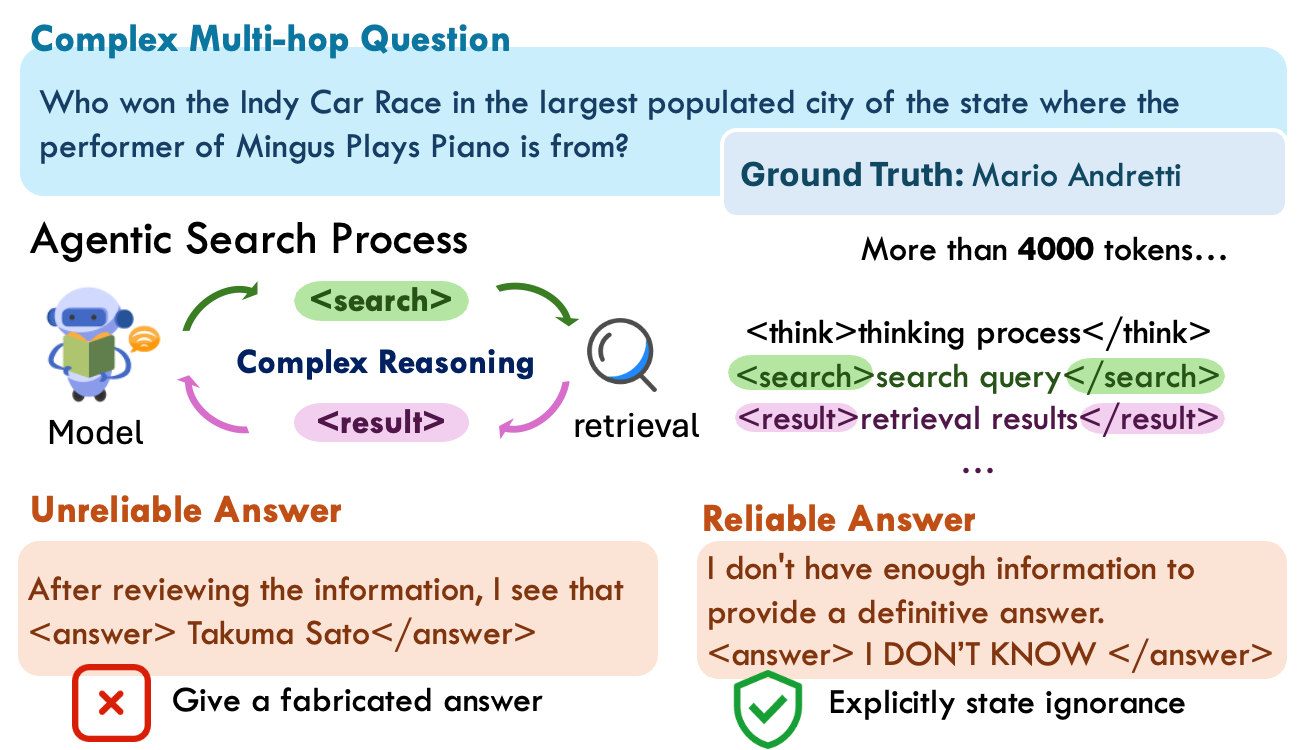
Критически важным шагом на пути к созданию надежных моделей искусственного интеллекта является обеспечение их “осознанием границ” — способностью распознавать пределы собственных знаний и воздерживаться от ответа на вопросы, выходящие за рамки их компетенции. Это достигается путем обучения моделей предоставлять ответ “Не знаю” (IDK Response) в ситуациях, когда вопрос выходит за пределы области их экспертизы. Такой подход позволяет повысить доверие к системе и предотвратить выдачу уверенно неверных ответов, что особенно важно в критически важных приложениях.
Обеспечение надёжности ИИ включает в себя стимулирование моделей к выдаче ответа «Не знаю» (IDK Response) в случаях, когда вопрос выходит за рамки их компетенции. Такой подход позволяет избежать уверенно неверных ответов и повышает доверие к системе. Вместо генерации потенциально ошибочной информации, модель признаёт границы своих знаний, что особенно важно в критических приложениях, где точность является приоритетом. Использование IDK Response не является признаком некомпетентности, а наоборот, демонстрирует способность модели к самооценке и ответственному поведению.
Основой для реализации “осознания границ” в моделях ИИ служат внутренние индикаторы уверенности и определенности выражения, позволяющие оценивать качество собственных рассуждений. Эти индикаторы, основанные на анализе внутренних представлений модели, позволяют ей выявлять ситуации, когда ее знания недостаточны для формирования надежного ответа. Дополнительно, используются методы саморефлексии, при которых модель анализирует собственные шаги рассуждений, выявляя потенциальные ошибки или неточности. Комбинация этих механизмов позволяет модели не только определить границы своей компетенции, но и предоставить соответствующий сигнал о неопределенности или неспособности ответить на вопрос.
BAPO: Обучение с Учётом Границ Надёжности
Алгоритм Boundary-Aware Policy Optimization (BAPO) представляет собой метод обучения с подкреплением, разработанный для тренировки агентских поисковых моделей с целью обеспечения адекватного осознания границ своей компетенции. BAPO предназначен для повышения надежности моделей путем обучения их выдавать ответ “Не знаю” (IDK) в случаях, когда запрос выходит за рамки их возможностей или когда требуемая информация недоступна. В отличие от традиционных подходов, BAPO явно ориентирован на обучение моделей признавать и корректно реагировать на ситуации неопределенности или нехватки данных, что критически важно для повышения доверия к агентским системам.
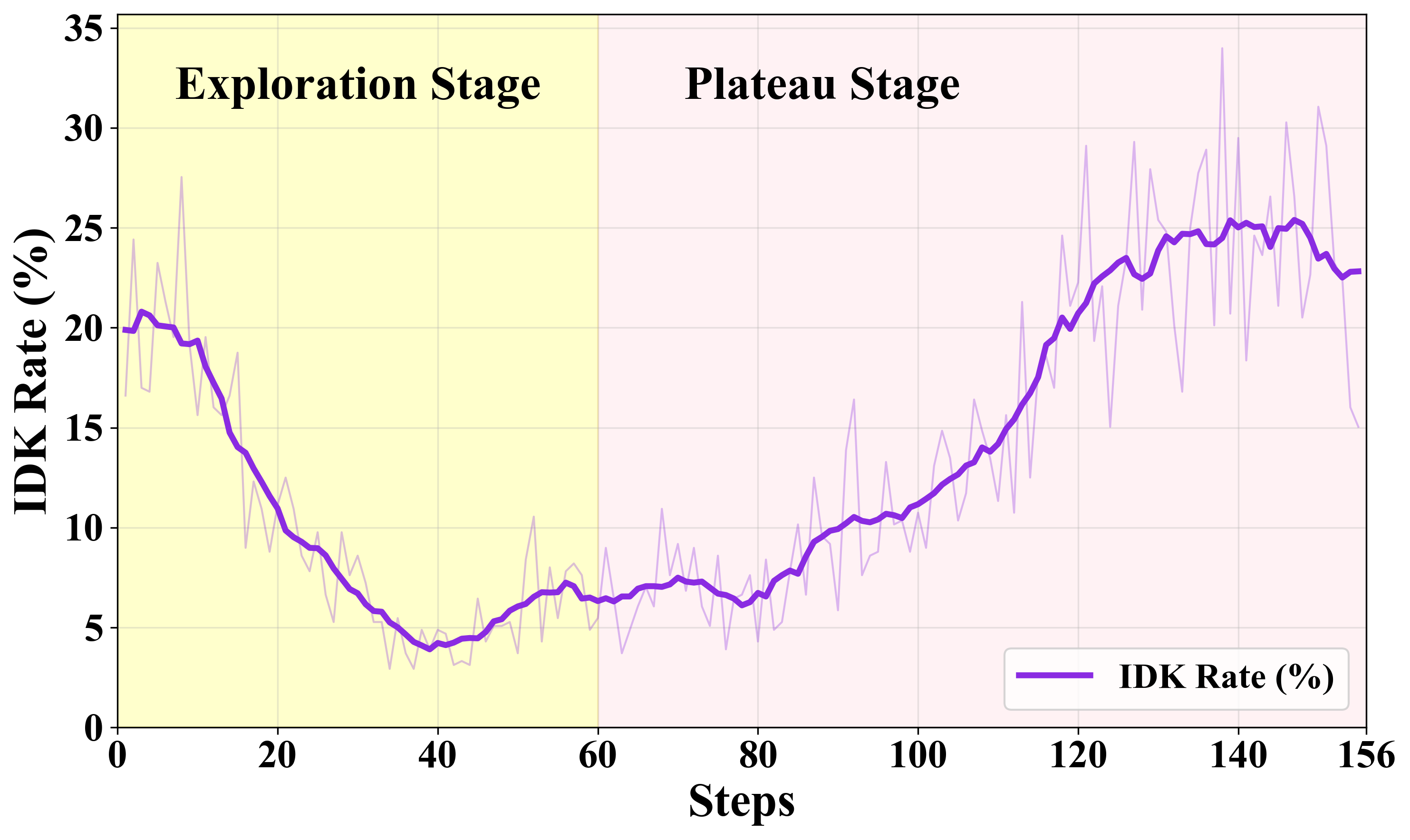
Алгоритм BAPO использует сигнал “Оценка осведомленности о границах” (Boundary-Aware Reward), который динамически корректируется “Адаптивным модулятором оценки” (Adaptive Reward Modulator). Этот механизм предназначен для стимулирования модели предоставлять ответ “Не знаю” (IDK) в случаях, когда входные данные выходят за пределы области ее компетенции или когда достоверность ответа недостаточно высока. Динамическая корректировка осуществляется на основе оценки уверенности модели в своем ответе, что позволяет адаптировать вознаграждение за ответ “Не знаю” в зависимости от конкретной ситуации и избегать необоснованных отказов от ответа.
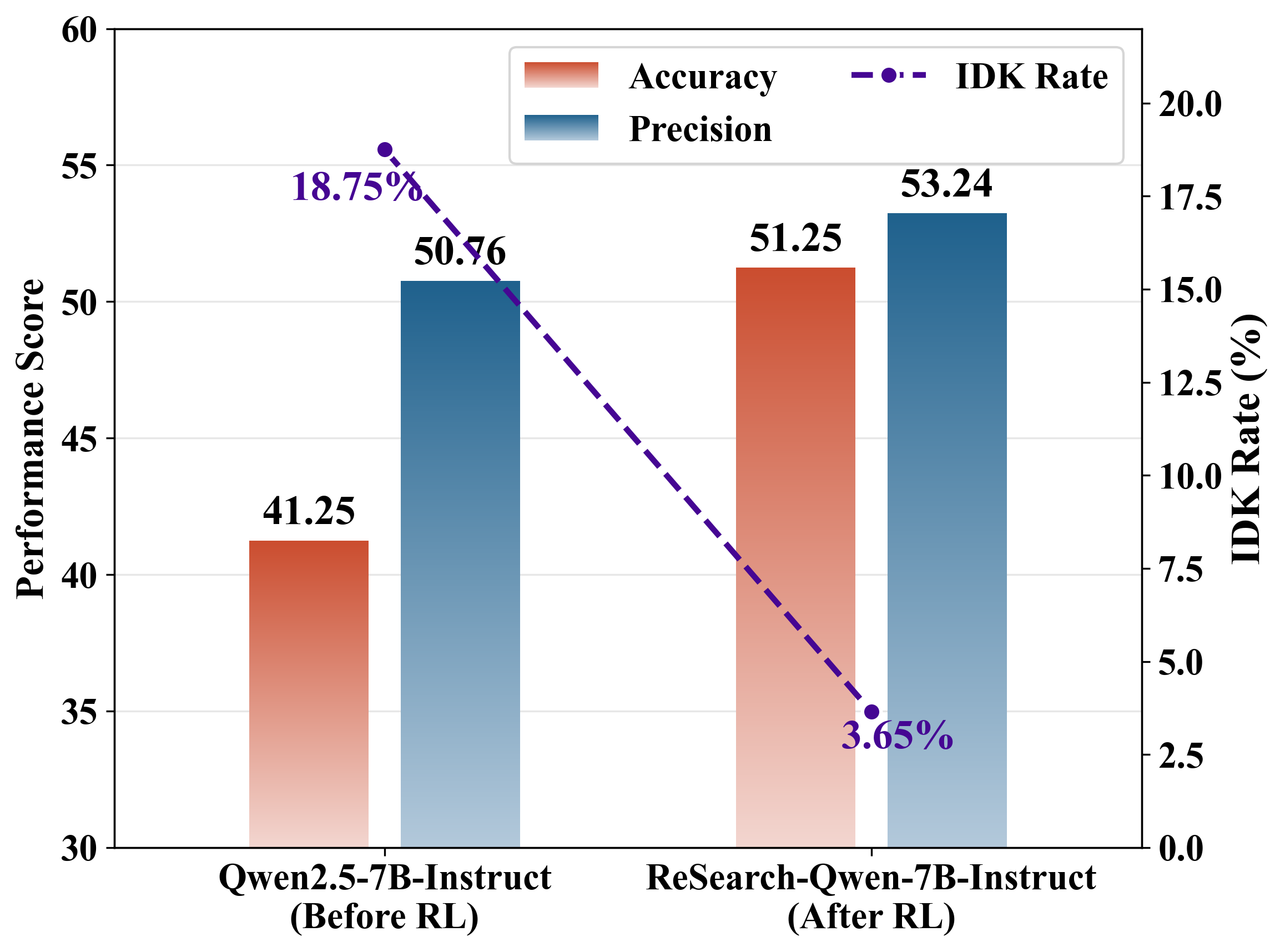
Алгоритм BAPO является расширением существующих методов, таких как Group Relative Policy Optimization (GRPO), и демонстрирует превосходящую производительность в повышении надежности. В ходе экспериментов BAPO показал улучшение надежности на 9,7 процентных пункта по сравнению с GRPO. Это подтверждает эффективность предложенного подхода к обучению агентов, способных адекватно оценивать свою компетентность и избегать выдачи недостоверной информации, что критически важно для надежных поисковых систем и агентов.
Агентный Поиск, Усиленный Надёжностью: Корректность и Честность в Действии
Система BAPO успешно интегрирована в ряд передовых платформ агентного поиска, включая Search-R1, ReSearch и Tool-Star, демонстрируя значительное повышение их эффективности и надёжности. Внедрение BAPO позволило этим фреймворкам не только более точно находить релевантную информацию, но и существенно снизить вероятность выдачи недостоверных или вводящих в заблуждение результатов. Такая интеграция способствует формированию более ответственных и заслуживающих доверия систем, способных предоставлять пользователям проверенные и обоснованные данные, что особенно важно в контексте быстрого распространения информации и необходимости критической оценки источников.
В основе повышения надежности агентов поиска лежит использование сигналов “Вознаграждения за корректность”, которые часто оцениваются с помощью больших языковых моделей (LLM) в роли судьи. Этот подход позволяет агентам не только находить информацию, но и оценивать ее правдивость и соответствие заданным границам. Помимо оценки корректности, системы вознаграждения включают в себя “граничные вознаграждения”, которые стимулируют агента избегать выхода за рамки допустимого или предоставления нерелевантных ответов. Комбинирование этих двух типов вознаграждений — за точность и честность — позволяет значительно повысить надежность агентов в процессе поиска информации и гарантирует предоставление пользователю достоверных и релевантных результатов.
Предложенный метод BAPO демонстрирует значительное превосходство над общепринятыми подходами к обучению и оптимизации запросов в задачах агентивного поиска. В ходе тестирования на четырех сложных бенчмарках, BAPO обеспечил в среднем увеличение надежности на 15.8 пункта. Особенно примечательно, что система успешно отказывается от ответов на заведомо некорректные или сложные вопросы в 76.7% случаев, что свидетельствует о высокой степени самоконтроля и стремлении к предоставлению только достоверной информации. Данные результаты подтверждают потенциал BAPO для создания более надежных и заслуживающих доверия систем поиска, способных эффективно решать сложные задачи.
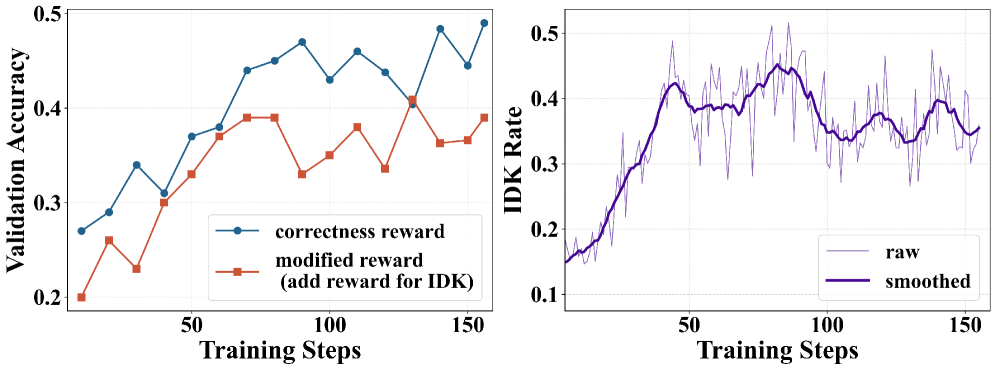
Представленная работа демонстрирует стремление к математической чистоте в алгоритмах поиска, что находит отражение в концепции осознания границ. Вместо того чтобы слепо продолжать поиск, даже при недостатке информации, модель, обученная с использованием BAPO, способна корректно определить ситуацию неопределенности и ответить «Я НЕ ЗНАЮ». Это напоминает о важности доказательства корректности алгоритма, а не просто его работоспособности на тестовых примерах. Как говорил Эдсгер Дейкстра: «Программирование — это не столько искусство, сколько ремесло, требующее точности и строгости». Данный подход к обучению агентов поиску подчеркивает, что надежность системы достигается не за счет эвристик и упрощений, а за счет осознания собственных ограничений и способности признавать незнание.
Куда Далее?
Представленная работа, несомненно, демонстрирует элегантность подхода к проблеме надёжности в агентном поиске. Однако, строго говоря, осознание границ собственного знания — это лишь первый шаг на пути к истинному интеллекту. Проблема заключается не в том, чтобы научиться говорить «Не знаю», а в том, чтобы понимать, почему ответ неизвестен, и активно стремиться к восполнению пробела в знаниях. Текущий фреймворк BAPO, хотя и эффективен в культивировании «осознания границ», пока не предлагает механизма для динамической адаптации стратегии поиска в ответ на признанное незнание.
Будущие исследования должны быть сосредоточены на интеграции BAPO с системами активного обучения. Представляется логичным, что агент, признавший свою некомпетентность, должен инициировать процесс сбора недостающей информации — задавать уточняющие вопросы, проводить дополнительные эксперименты, или обращаться к внешним источникам знаний. В противном случае, «Я не знаю» остаётся лишь утончённой формой пассивности, а не проявлением интеллектуальной активности.
Кроме того, необходимо более строгое математическое обоснование выбора функции вознаграждения, стимулирующей осознание границ. В текущей реализации, этот аспект, хотя и эмпирически эффективен, кажется несколько ad hoc. Истинная красота алгоритма проявляется не в его способности «работать», а в его доказуемой корректности и оптимальности. Иначе говоря, необходимо продемонстрировать, что предложенный подход действительно минимизирует риск ошибочных ответов, а не просто переносит его в другую область.
Оригинал статьи: https://arxiv.org/pdf/2601.11037.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2026-01-19 12:12