Автор: Денис Аветисян
Исследование сравнивает принципы работы традиционных поисковых систем и генеративных моделей искусственного интеллекта, таких как GPT-4, выявляя различия в источниках информации и подходе к ответам на запросы.
Сравнительный анализ поисковых систем и генеративных моделей ИИ в контексте разнообразия источников, актуальности данных и влияния предвзятости, полученной в процессе обучения.
Появление генеративных моделей искусственного интеллекта ставит под вопрос устоявшиеся подходы к поиску информации. В своей работе ‘Navigating the Shift: A Comparative Analysis of Web Search and Generative AI Response Generation’ авторы проводят масштабное исследование, выявляющее фундаментальные различия между результатами, выдаваемыми традиционными поисковыми системами и современными генеративными сервисами. Полученные данные демонстрируют, что эти системы существенно различаются по источникам информации, типу этих источников, пониманию запросов пользователей и актуальности предоставляемых сведений. Как эти различия повлияют на эволюцию методов оптимизации контента и приведут ли они к формированию принципиально новых стратегий в сфере информационного поиска?
От списка к ответу: новая парадигма поиска
Традиционные поисковые системы, такие как Google, исторически предоставляют пользователям структурированный список ссылок в ответ на запрос, возлагая на него ответственность за анализ и синтез информации из различных источников. Этот подход требует значительных когнитивных усилий и времени, поскольку пользователю необходимо самостоятельно оценить релевантность и достоверность каждой ссылки, а затем объединить полученные сведения в единый ответ. Фактически, процесс поиска информации превращается в задачу по сбору и обработке разрозненных фрагментов, а не в получение готового решения. Такая модель взаимодействия, хотя и проверенная временем, предполагает активное участие пользователя в формировании ответа, что может быть обременительно, особенно при сложных или срочных запросах.
В отличие от традиционных поисковых систем, предоставляющих пользователю списки ссылок для самостоятельного анализа, генеративные модели искусственного интеллекта предлагают принципиально иной подход к извлечению информации. Они способны непосредственно синтезировать ответы на запросы, представляя готовый результат, а не требуя от пользователя трудоемкой работы по отбору и обобщению данных. Этот переход обещает значительно повысить эффективность поиска, позволяя пользователям получать необходимую информацию быстрее и удобнее. Такая возможность особенно актуальна в условиях информационного перегруза, когда время, затрачиваемое на поиск, может быть критичным.
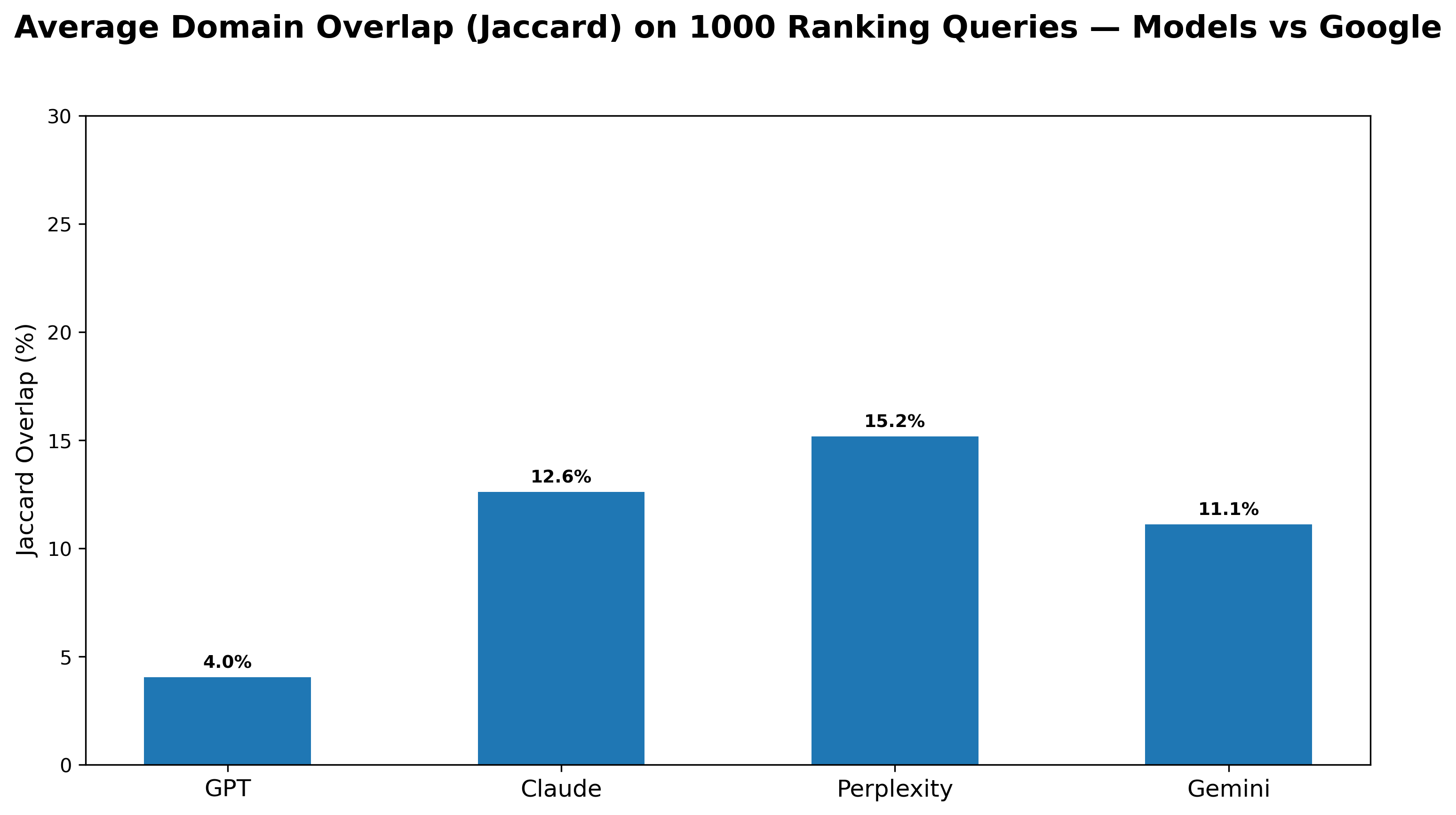
Переход к поиску ответов, а не списков, особенно заметен в запросах, требующих ранжированного результата — задача, казалось бы, идеально подходящая как для традиционных поисковых систем, так и для генеративных моделей искусственного интеллекта. Однако, принципы работы этих подходов существенно различаются. В то время как традиционные поисковики формируют списки, основываясь на анализе ссылок и релевантности, современные модели, такие как GPT-4o, демонстрируют совершенно иные паттерны отбора источников. Исследования показывают, что доменное пересечение между результатами, предоставляемыми этими моделями и Google Поиском, крайне невелико — всего около 4.0%. Это свидетельствует о том, что генеративные модели используют совершенно иные знания и источники для формирования ответов, предлагая пользователям альтернативный взгляд на информацию.
Исследования показали, что GPT-4o демонстрирует крайне низкий уровень пересечения доменных источников с результатами поиска Google — всего 4,0%. Это указывает на принципиальное различие в подходах к формированию ответов. В то время как традиционные поисковые системы, как правило, агрегируют информацию из ограниченного набора веб-сайтов, GPT-4o обращается к гораздо более широкому и разнообразному спектру источников, часто выходя за рамки типичных результатов поисковой выдачи. Такое расхождение подчеркивает, что генеративные модели не просто перебирают существующие веб-страницы, а синтезируют знания, используя принципиально иные методы обработки и анализа информации, что открывает новые перспективы в области информационного поиска и доступа к знаниям.
Оценка качества ответа: за пределами поверхностного сходства
Генеративные сервисы искусственного интеллекта используют оценку релевантности извлеченных фрагментов информации для формирования ответов, однако этот процесс может быть недостаточно надежным, особенно при наличии пересечений тематик между источниками. Проблема заключается в том, что при высокой степени тематической близости различных веб-страниц, алгоритмы оценки могут ошибочно выбирать менее релевантные фрагменты, приводя к неточным или вводящим в заблуждение ответам. Это усугубляется тем, что многие источники информации в интернете дублируют или перефразируют контент друг друга, что затрудняет точное определение наиболее авторитетного и релевантного источника для конкретного запроса. В результате, оценка релевантности, основанная исключительно на поверхностном анализе текста, может не отражать истинную полезность и точность информации.
Для строгой оценки стабильности ранжирования используются методы пертурбации, такие как перемешивание сниппетов (Snippet Shuffle). Данный подход заключается в случайном изменении порядка представленных извлеченных фрагментов текста и последующей оценке, насколько существенно изменится сгенерированное ранжирование ответов. Значительные изменения в ранжировании после перемешивания сниппетов указывают на нестабильность системы и ее чувствительность к порядку представления информации, что может свидетельствовать о недостаточной надежности алгоритмов оценки релевантности и необходимости их доработки. Этот метод позволяет выявить, насколько система полагается на поверхностные признаки или действительно понимает содержание представленных фрагментов.
Метод инъекции замены сущностей (Entity-Swap Injection, ESI) представляет собой технику оценки контекстного понимания языковых моделей. В рамках ESI в извлеченных фрагментах текста производится замена одних сущностей на другие, семантически связанные, но отличающиеся. Анализ изменений в ранжировании и генерации ответов после такой замены позволяет определить, насколько модель способна корректно интерпретировать смысл текста и поддерживать когерентность, несмотря на модификацию ключевых элементов. ESI позволяет выявить случаи, когда модель полагается исключительно на поверхностное сопоставление ключевых слов, а не на глубокое понимание контекста.
Оценка качества ответов генеративных AI-сервисов показала существенные различия в актуальности используемой информации. Анализ медианного возраста статей, привлекаемых для ответов на запросы в категории “Потребительская электроника”, выявил, что Claude использует материалы со средним возрастом 62 дня, в то время как Google опирается на статьи со средним возрастом 493 дня. Данное различие указывает на то, что Claude в большей степени полагается на более свежую информацию при формировании ответов, в отличие от Google, который в значительной степени использует более устаревшие источники.
Обеспечение надежного ранжирования: строгая привязка и парное сравнение
Методы строгой привязки (Strict Grounding) являются критически важными для современных генеративных моделей, поскольку ограничивают процесс генерации информации исключительно данными, содержащимися в извлеченных фрагментах (snippets). Это позволяет эффективно предотвратить генерацию галлюцинаций — ложных или не подтвержденных фактов — и существенно повысить точность предоставляемых ответов. Ограничение генерации внешними источниками информации гарантирует, что модель опирается исключительно на проверенные данные, что особенно важно для приложений, требующих высокой достоверности, таких как информационный поиск и ответы на вопросы.
Метод парного сравнения представляет собой надежный способ построения ранжирования, основанный на прямом выборе модели между двумя сущностями для заданного запроса. Вместо абсолютной оценки каждой сущности, модель определяет, какая из двух является более релевантной или предпочтительной в контексте конкретного запроса. Этот подход позволяет избежать проблем, связанных с калибровкой оценок и субъективностью абсолютных критериев, сосредотачиваясь на относительном порядке сущностей. В процессе обучения или оценки модель последовательно сравнивает пары сущностей, формируя тем самым упорядоченный список, отражающий предпочтения для каждого запроса.
Эффективность метода парного сравнения (Pairwise Comparison) для определения ранжирования оценивается с помощью коэффициента Кендалла τ. Данная статистическая метрика измеряет корреляцию между ранжированием, предложенным моделью, и эталонным (ground truth) или экспертным ранжированием. Для популярных сущностей (entities) коэффициент Кендалла демонстрирует практически полную согласованность между различными методами ранжирования, указывая на высокую надежность и воспроизводимость результатов для широко известных объектов.
Наблюдается снижение согласованности результатов ранжирования при работе с нишевыми сущностями. Это указывает на проблему поддержания надежности ранжирования для всех типов запросов, поскольку модели демонстрируют меньшую способность корректно оценивать и упорядочивать сущности с ограниченным количеством доступной информации или низкой частотой упоминаний в обучающих данных. Снижение согласованности проявляется в уменьшении коэффициента корреляции τ Кендалла по сравнению с популярными сущностями, что свидетельствует о повышенной вероятности ошибок в ранжировании нишевых объектов.
Решение проблем нишевых сущностей и актуальности данных
Генеративные модели искусственного интеллекта часто испытывают трудности при работе с узкоспециализированными сущностями, поскольку их предварительное обучение, как правило, не содержит достаточного объема данных для точной оценки релевантности и контекста. Это связано с тем, что большая часть обучающих данных сосредоточена на общеизвестных темах и понятиях, в то время как информация о нишевых объектах или явлениях представлена в недостаточном объеме. В результате, модели могут допускать ошибки при интерпретации запросов, связанных с такими сущностями, или предоставлять неточные или неполные ответы. Ограниченность данных особенно критична для быстро развивающихся областей знаний, где информация о новых или малоизвестных объектах постоянно обновляется и дополняется.
Актуальность информации играет ключевую роль в работе генеративных систем, поскольку использование устаревших данных может приводить к неточным или вводящим в заблуждение ответам, особенно в динамично развивающихся областях знаний. Исследования показывают, что такие модели, как Gemini, Claude и Perplexity, демонстрируют значительное пересечение с доменом Google Search — 11.1%, 12.6% и 15.2% соответственно — однако каждая из них отдает предпочтение различным источникам информации. Это подчеркивает важность не только доступа к широкому спектру данных, но и способности системы оперативно обновлять и верифицировать информацию, чтобы обеспечивать пользователям достоверные и своевременные ответы.
Для создания действительно надежных поисковых систем, основанных на генеративных моделях, необходим комплексный подход. Он предполагает не только строгую привязку к проверенным источникам информации — так называемый “strict grounding”, но и применение надежных методов оценки качества генерируемых ответов. Особое внимание следует уделять актуальности данных, поскольку устаревшая информация может приводить к неточностям и вводить пользователей в заблуждение, особенно в быстро меняющихся областях знаний. Сочетание этих факторов — всестороннего охвата информации, ее достоверности и свежести — является ключевым для формирования доверия к генеративным поисковым системам и обеспечения предоставления пользователям релевантных и точных результатов.
Исследование показывает, как генеративные модели, в отличие от традиционного поиска, опираются на уже существующие знания, особенно когда речь идет о популярных сущностях. Это закономерно — ведь каждая «революционная» технология завтра станет техдолгом. Как заметил Марвин Минский: «Лучший способ предсказать будущее — создать его». В данном случае, будущее поиска создается за счет огромных объемов предварительного обучения, но и эта база знаний, как и любая абстракция, однажды устареет. Именно поэтому, свежесть источников, как подчеркивает работа, становится критически важным фактором, а «любая абстракция умирает от продакшена». Однако, умирает она, стоит признать, весьма изящно.
Куда же мы катимся?
Исследование закономерно показало, что генеративные модели ищут не там, где все ищут. И это, знаете ли, не открытие века. Каждая «революционная» технология в конечном итоге превращается в новый уровень технического долга. Сейчас все восхищаются способностью этих систем «знать» ответы. Но стоит помнить: всё, что обещает быть самовосстанавливающимся, просто ещё не сломалось. Вопрос не в том, что они знают, а в том, как они это забывают, когда в продакшене что-то пойдёт не так.
Особого внимания заслужила проблема предвзятости, унаследованной от данных предварительного обучения. Как будто можно было ожидать чего-то другого. Документация — это форма коллективного самообмана, и эти модели — не исключение. Они аккуратно маскируют свои ограничения под уверенные ответы. И если баг воспроизводится — значит, у нас стабильная система, верно?
Будущие исследования неизбежно столкнутся с проблемой «свежести» информации. Пока модель переваривает очередной терабайт данных, мир успевает измениться. И тогда мы снова будем изобретать велосипед, только на этот раз — самообучающийся. Впрочем, это и есть вся суть прогресса — вечное движение по кругу.
Оригинал статьи: https://arxiv.org/pdf/2601.16858.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Сердце музыки: открытые модели для создания композиций
- Эмоциональный отпечаток: Как мы научили ИИ читать душу (и почему рейтинги вам врут)
- Квантовый скачок из Андхра-Прадеш: что это значит?
- LLM: математика — предел возможностей.
- Волны звука под контролем нейросети: моделирование и инверсия в вязкоупругой среде
- Почему ваш Steam — патологический лжец, и как мы научили компьютер читать между строк
2026-01-26 16:04