Автор: Денис Аветисян
В статье представлен инновационный метод повышения надежности и интерпретируемости небольших языковых моделей при решении задач классификации текста.
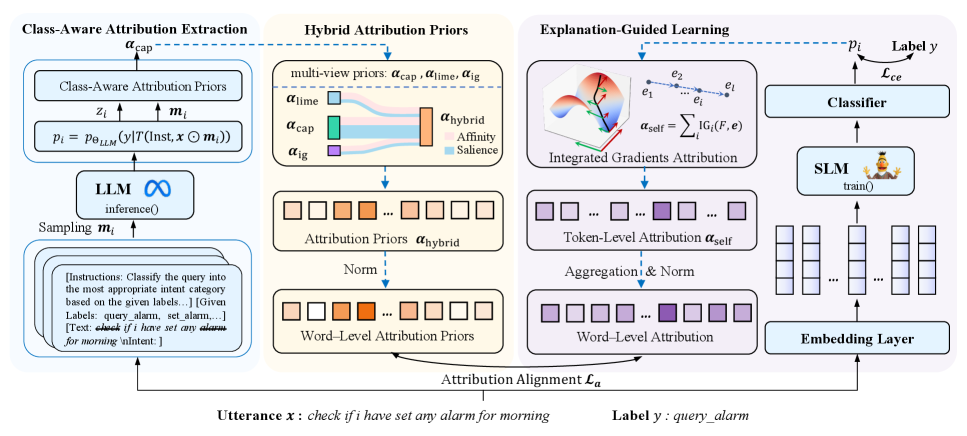
Разработка гибридных априорных оценок атрибуции для улучшения объяснимости и устойчивости моделей.
Несмотря на широкое применение малых языковых моделей в задачах классификации, обеспечение их интерпретируемости и устойчивости остается сложной задачей. В работе ‘Hybrid Attribution Priors for Explainable and Robust Model Training’ предложен новый подход к генерации надежных и масштабируемых атрибутивных приоритетов, направленный на повышение объяснимости и надежности моделей. Разработанный метод позволяет улавливать тонкие классовые различия и формировать более информативные сигналы обучения, комбинируя существующие техники атрибуции с предложенным классово-ориентированным подходом. Способствует ли это созданию более прозрачных и устойчивых моделей, способных эффективно решать задачи классификации текстов в различных условиях?
Проблема Интерпретируемости Определения Намерений
Современные диалоговые системы, стремясь к высокой точности определения намерений пользователя, зачастую страдают от недостатка прозрачности в процессе принятия решений. Несмотря на впечатляющие результаты в распознавании запросов, механизмы, лежащие в основе этих предсказаний, остаются непрозрачными. Это создает значительные трудности при отладке системы, поскольку сложно понять, какие факторы привели к конкретному выводу. Отсутствие понимания внутренней логики работы также препятствует выявлению и коррекции потенциальных предвзятостей, что особенно критично в областях, где решения диалоговой системы могут иметь серьезные последствия, например, в здравоохранении или финансовой сфере. В результате, несмотря на функциональность, эти системы остаются сложными для контроля и оптимизации, что подрывает доверие к ним со стороны пользователей и разработчиков.
Непрозрачность в работе систем определения намерений представляет серьезную проблему, особенно в приложениях, где ставки высоки, например, в здравоохранении или финансах. Отсутствие понимания логики, по которой система приходит к определенному выводу, затрудняет выявление и исправление ошибок, а также предвзятости, заложенной в алгоритмы. Это, в свою очередь, подрывает доверие к системе и ограничивает возможности её эффективной отладки и совершенствования. В ситуациях, где требуется высокая степень надежности и ответственности, способность объяснить принятое решение становится критически важной, ведь просто констатации факта недостаточно — необходимо понимать, почему система пришла к такому заключению.
Современные модели определения намерений, лежащие в основе диалоговых систем, зачастую функционируют как «черные ящики», что существенно затрудняет понимание логики, приводящей к конкретному прогнозу. Отсутствие прозрачности в процессе принятия решений не позволяет детально проанализировать, какие именно факторы и признаки в пользовательском запросе привели к определенному выводу. Это создает серьезные препятствия для отладки системы, выявления и исправления скрытых предвзятостей, а также для повышения доверия к ней, особенно в критически важных областях применения, где точность и объяснимость результатов имеют первостепенное значение. Вследствие этого, разработчикам становится сложно не только улучшить производительность модели, но и гарантировать ее надежность и справедливость.
Обучение с Объяснениями: Новый Подход
Обучение с объяснениями (Explanation-Guided Learning) использует методы, такие как SHAP (SHapley Additive exPlanations), LIME (Local Interpretable Model-agnostic Explanations) и Integrated Gradients для анализа вклада отдельных признаков в прогнозы модели. SHAP вычисляет важность признаков на основе теории игр, распределяя «плату» за вклад каждого признака в предсказание. LIME аппроксимирует поведение модели локально, вокруг конкретного примера, используя интерпретируемую модель. Integrated Gradients определяет вклад признака путем интегрирования градиентов функции потерь по пути от базового входа к текущему. Эти методы позволяют определить, какие признаки наиболее сильно влияют на решение модели, предоставляя информацию для отладки, повышения доверия и выявления потенциальных смещений.
Анализ определяющих факторов, влияющих на принятие решений моделью, позволяет выявить потенциальные смещения и области для улучшения. Идентификация наиболее значимых признаков, используемых моделью для прогнозирования, помогает обнаружить, что модель может опираться на нерелевантные или предвзятые данные. Например, если модель при оценке кредитоспособности чрезмерно полагается на пол или место жительства, это указывает на наличие смещения. Выявление таких закономерностей позволяет скорректировать данные для обучения, изменить архитектуру модели или применить методы устранения смещений, что в конечном итоге повышает справедливость и надежность системы.
Традиционно, оценка эффективности моделей искусственного интеллекта фокусировалась преимущественно на достижении высокой точности прогнозов. Однако, переход к объяснимому ИИ (XAI) предполагает смещение акцента на обеспечение доверия и ответственности систем. Это означает, что помимо корректности предсказаний, важно понимать почему модель пришла к тому или иному выводу. Прозрачность процесса принятия решений позволяет выявлять потенциальные предвзятости, обеспечивать соответствие поведения модели этическим нормам и требованиям регуляторов, а также повышать уверенность пользователей в надежности и справедливости системы. В конечном итоге, фокус на доверии и ответственности способствует более широкому и ответственному внедрению ИИ в критически важные области.
Согласованность атрибуции (Attribution Alignment) является критически важным компонентом в Explanation-Guided Learning, обеспечивающим соответствие между внутренними механизмами принятия решений моделью и внешними ожиданиями экспертов или заданными правилами. Это достигается путем анализа атрибуций — вклада отдельных признаков в итоговый прогноз — и их сопоставления с известными закономерностями или экспертными знаниями в предметной области. Несоответствие между атрибуциями модели и внешними ожиданиями может указывать на наличие скрытых смещений, неверную интерпретацию данных или недостаточное обучение модели, требующее дальнейшей корректировки и улучшения.
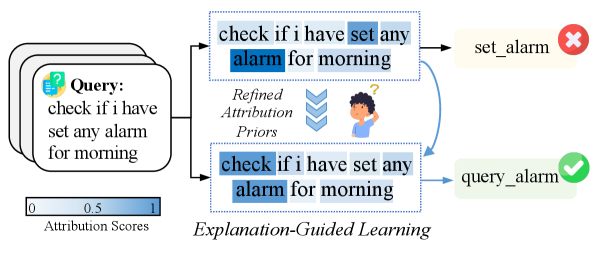
Использование Больших Языковых Моделей для Приоритетов Атрибуции
Метод генерации устойчивых атрибутивных приоритетов, названный Class-Aware Attribution Prior, заключается в использовании запросов к большим языковым моделям (LLM) с предоставлением инструкций по задаче и информации о пространстве меток. Данный подход позволяет направлять внимание модели на наиболее релевантные признаки, определяющие намерение пользователя. Предоставляемые инструкции и информация о метках формируют контекст для LLM, позволяя ей генерировать приоритеты атрибуции, отражающие значимость различных входных признаков для конкретной классификации намерений. Это позволяет создавать более точные и интерпретируемые модели классификации намерений, основанные на осознанном выборе признаков.
Предложенный метод позволяет направлять внимание модели на наиболее релевантные признаки, определяющие намерение пользователя. Это достигается за счет формирования атрибуционных приоритетов (attribution priors), которые служат сигналом для выделения ключевых элементов входных данных, влияющих на классификацию намерения. По сути, модель не просто анализирует все входные данные одинаково, а фокусируется на тех частях, которые, согласно сформированным приоритетам, наиболее важны для определения конкретного намерения. Данный подход позволяет повысить точность классификации за счет снижения влияния нерелевантных признаков и усиления влияния определяющих.
Гибридное объединение признаков (Hybrid Attribution Prior Fusion) предполагает комбинирование атрибутивных признаков, полученных из различных источников, для создания более надежного и всестороннего сигнала. Этот процесс позволяет интегрировать информацию, полученную, например, от больших языковых моделей и традиционных методов анализа признаков, что повышает устойчивость и точность определения наиболее релевантных факторов, влияющих на классификацию намерений. В результате, комбинированный сигнал обеспечивает более полное представление о взаимосвязи между входными данными и целевыми метками, что способствует улучшению производительности модели в целом и снижению влияния шума или нерелевантных признаков.
Метод был протестирован на различных наборах данных для классификации намерений, включая HWU64, Banking77 и Clinc150. На наборе данных Banking77 была достигнута общая точность до 93.51%. Использование разнообразных наборов данных позволило оценить обобщающую способность подхода в различных сценариях классификации намерений и подтвердить его эффективность в задачах понимания естественного языка.
Повышение Устойчивости и Доверия к Модели
Исследования показали, что внедрение обучения, ориентированного на объяснения, в сочетании с надежными априорными оценками атрибуции, значительно повышает устойчивость моделей к враждебным атакам. Данный подход позволяет моделям не просто предсказывать результаты, но и обосновывать их, что делает их менее восприимчивыми к намеренным искажениям входных данных. Усиление устойчивости достигается за счет обучения модели учитывать причины, лежащие в основе её решений, и избегать полагаться на незначительные или манипулируемые признаки. Это не только повышает надежность системы, но и позволяет лучше понимать и отлаживать её поведение, обеспечивая более предсказуемые и контролируемые результаты даже в условиях неблагоприятных воздействий.
Повышенная устойчивость моделей искусственного интеллекта к воздействию атак, направленных на искажение результатов, играет ключевую роль в укреплении доверия к этим системам, особенно в критически важных областях, таких как финансовый сектор. Исследования показали значительный прогресс в этой области: на наборе данных Banking77, предназначенном для оценки устойчивости моделей к мошенническим операциям, достигнута точность в 84.97% при атаках, что на 14.68 процентных пункта выше, чем у базовых методов (70.29%). Это свидетельствует о значительном улучшении способности моделей правильно классифицировать данные даже при намеренных попытках их искажения, что является необходимым условием для надежного и безопасного применения искусственного интеллекта в чувствительных областях.
Разработанный подход открывает путь к созданию более прозрачных и ответственных систем искусственного интеллекта, что способствует укреплению доверия пользователей. Обеспечивая возможность понимания логики принятия решений моделью, данный метод позволяет не только повысить надежность и предсказуемость работы ИИ, но и облегчить выявление и устранение потенциальных предвзятостей или ошибок. Это, в свою очередь, стимулирует ответственные инновации, позволяя внедрять искусственный интеллект в критически важные области, такие как финансы и здравоохранение, с большей уверенностью и безопасностью. Повышенная прозрачность и подотчетность являются ключевыми факторами для широкого принятия и эффективного использования технологий ИИ в будущем.
Исследования показали, что предложенный подход демонстрирует высокую эффективность в задачах небольшого количества примеров (5-shot learning) на датасете HWU64, достигая точности в 79.09%. Этот результат сопровождается показателями comprehensiveness (полноты) в 69.12% и sufficiency (достаточности) в 30.66%, что указывает на способность модели эффективно извлекать и использовать информацию из ограниченного набора данных. Полученные значения не только подтверждают работоспособность метода, но и устанавливают новый ориентир производительности в задачах, где доступ к большим объемам размеченных данных ограничен, способствуя развитию более адаптивных и эффективных систем искусственного интеллекта.
Исследование, представленное в статье, акцентирует внимание на важности структуры в определении поведения системы, что находит глубокий отклик в словах Дональда Дэвиса: «Архитектура — это поведение системы во времени, а не схема на бумаге». Разработка надежных механизмов атрибуции априорных знаний, как предложено в данной работе для повышения интерпретируемости и устойчивости малых языковых моделей, демонстрирует, что понимание внутренней структуры модели необходимо для предсказания и контроля ее поведения. Попытки оптимизировать отдельные аспекты без учета целостной архитектуры неизбежно приводят к возникновению новых узлов напряжения, что подтверждает фундаментальный принцип: хорошая система — живой организм, требующий целостного подхода к пониманию и модификации.
Куда Ведет Дорога?
Представленная работа, безусловно, демонстрирует возможность создания более устойчивых и понятных моделей обработки текста, используя концепцию атрибутивных априорных знаний. Однако, не стоит обольщаться иллюзией полного контроля. Модульность, даже при наличии четко определенных априорных ограничений, не гарантирует истинного понимания внутренних механизмов модели. Если система держится на костылях, значит, мы переусложнили её, пытаясь «объяснить» то, что изначально требовало более элегантного подхода к проектированию.
Перспективные направления исследований лежат не только в усовершенствовании самих априорных знаний, но и в разработке методов оценки их истинной ценности. Необходимо отличать формальную интерпретируемость от реального понимания причинно-следственных связей. Важно помнить, что «объяснение» — это не просто набор выделенных признаков, а реконструкция логики принятия решений.
В конечном счете, истинный прогресс требует отхода от представления о модели как о «черном ящике», который нужно насильно «открывать». Гораздо важнее строить системы, прозрачность которых заложена в самой архитектуре. Если структура определяет поведение, то элегантное решение всегда будет проще и надежнее любого искусственного «объяснения».
Оригинал статьи: https://arxiv.org/pdf/2512.14719.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2025-12-18 15:57