Автор: Денис Аветисян
Новый подход ProtoQuant позволяет повысить интерпретируемость замороженных моделей компьютерного зрения, разбивая пространство признаков на понятные концепции.

ProtoQuant использует векторизацию и дискретизацию для повышения стабильности и масштабируемости представления признаков в нейронных сетях.
Несмотря на привлекательность интерпретируемых моделей, основанных на прототипических частях, их масштабируемость и стабильность остаются сложной задачей. В данной работе, посвященной ‘ProtoQuant: Quantization of Prototypical Parts For General and Fine-Grained Image Classification’, предложен новый подход, использующий квантизацию векторного пространства для обеспечения устойчивости и интерпретируемости прототипов. Ключевым результатом является создание концептуального кодекса, ограничивающего прототипы дискретным представлением и позволяющего избежать «сдвига прототипов» без переобучения базовой модели. Сможет ли данная архитектура ProtoQuant стать эффективным инструментом для создания надежных и объяснимых систем компьютерного зрения, способных к обобщению на крупных датасетах?
Тёмные Ящики и Шепот Хаоса: Проблема Интерпретируемости
Несмотря на значительный прогресс в области глубокого обучения, современные модели, такие как ResNet и ViT, зачастую демонстрируют недостаток интерпретируемости. Это означает, что сложно понять, какие именно факторы и признаки влияют на принятие моделью того или иного решения. Отсутствие прозрачности в работе этих «черных ящиков» создает серьезные препятствия для формирования доверия к ним, особенно в критически важных областях, таких как медицина или финансы. Кроме того, сложность понимания внутренних механизмов затрудняет отладку и выявление потенциальных ошибок или предвзятостей, что может привести к непредсказуемым и нежелательным последствиям. В результате, несмотря на высокую точность, ограниченная интерпретируемость становится существенным ограничением для широкого внедрения и эффективного использования этих мощных алгоритмов.
Исследования показывают, что общепринятые методы постобработки для объяснения решений сложных моделей, известные как XAI (Explainable AI), часто демонстрируют нестабильность. Даже незначительные изменения во входных данных могут приводить к существенным изменениям в объяснениях, генерируемых этими методами. Это подрывает доверие к ним, поскольку объяснение, кажущееся логичным для одного входного сигнала, может оказаться совершенно иным для слегка модифицированного. Такая чувствительность к малым возмущениям ставит под сомнение надежность этих методов в критически важных приложениях, где требуется последовательное и достоверное обоснование принимаемых решений, например, в медицине или автономном транспорте. По сути, объяснения, полученные с помощью этих инструментов, могут оказаться иллюзией понимания, а не отражением истинной логики модели.
В условиях растущей зависимости от алгоритмов машинного обучения, потребность в моделях, которые можно легко понять и объяснить, становится критически важной. Приложения, где решения напрямую влияют на жизнь людей — например, в медицине, юриспруденции или финансовой сфере — требуют не только высокой точности, но и прозрачности процесса принятия решений. Модели, работающие по принципу «черного ящика», не позволяют понять, какие факторы привели к конкретному результату, что создает риски ошибок и снижает доверие. В связи с этим, разработка и внедрение принципиально интерпретируемых моделей, где логика работы понятна с самого начала, является необходимым условием для обеспечения ответственности и надежности в критически важных областях применения искусственного интеллекта.

Визуальное Рассуждение: Открывая Скрытые Связи
Прототипические сети частей (Prototypical Parts Networks) идентифицируют репрезентативные фрагменты изображений — “прототипы” — для обоснования принимаемых решений. В отличие от традиционных подходов, где предсказания основаны на абстрактных признаках, данная методика стремится к более интуитивно понятному и близкому к человеческому восприятию процессу рассуждения. Идентифицированные прототипы служат визуальным подтверждением, объясняющим, почему модель пришла к определенному выводу, что повышает прозрачность и интерпретируемость системы. Этот подход позволяет не только предсказывать, но и “показывать”, на основе каких конкретных визуальных элементов было принято решение, что важно для доверия к системе и ее отладке.
Первые реализации прототипных сетей, такие как ProtoPNet и InfoDisent, продемонстрировали перспективность подхода, основанного на выявлении и использовании репрезентативных фрагментов изображения для обоснования предсказаний. Однако, эти методы страдали от недостаточной привязки к обучающим данным, что выражалось в низкой устойчивости и обобщающей способности. Несмотря на то, что они успешно идентифицировали прототипы, процесс обучения не обеспечивал надежной связи между этими прототипами и соответствующими концептуальными представлениями, что ограничивало их эффективность в реальных сценариях.
Первые методы, использующие прототипы, такие как ProtoPNet и InfoDisent, продемонстрировали перспективность подхода, основанного на выделении репрезентативных фрагментов изображения для обоснования предсказаний. Однако, анализ их работы выявил потребность в более структурированной архитектуре, которая бы не только идентифицировала эти прототипы, но и обеспечивала надежное представление лежащих в их основе концепций. Отсутствие четкой связи между выделенными фрагментами и семантическим значением ограничивало обобщающую способность моделей и затрудняло интерпретацию результатов. Таким образом, возникла необходимость в разработке фреймворка, объединяющего процесс идентификации прототипов с эффективным представлением концептуальной информации, что позволило бы повысить точность и объяснимость моделей визуального рассуждения.

Дискретизация Знания: Создавая Стабильные Объяснения
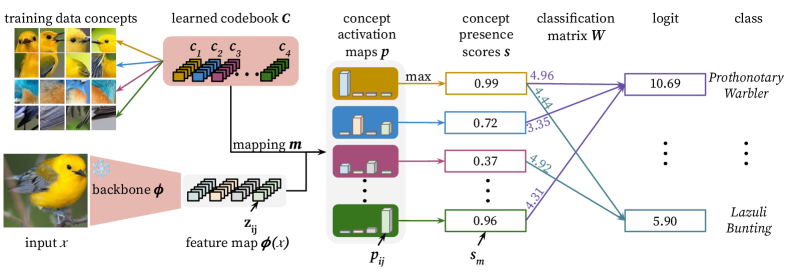
В основе ProtoQuant лежит использование Vector-Quantized Variational Autoencoders (VQ-VAE) для создания дискретного “Кодекса Концепций”, представляющего визуальные признаки. VQ-VAE позволяет сжать непрерывное пространство признаков в конечное число дискретных векторов, формирующих этот кодекс. Каждый вектор в кодексе соответствует определенной визуальной концепции или части изображения. Этот процесс квантизации позволяет представить сложные визуальные данные в более интерпретируемой и структурированной форме, что является ключевым для последующего анализа и объяснения решений модели. В результате, вместо работы с непрерывными значениями, ProtoQuant оперирует с дискретными кодами, что упрощает установление связи между признаками и человеко-понятными концепциями.
В ProtoQuant сопоставление фрагментов изображения с элементами ‘Кодекса Концепций’ осуществляется посредством вычисления косинусного сходства. Этот метод позволяет установить прямую связь между активациями, генерируемыми моделью, и понятными человеку визуальными концепциями. Каждый фрагмент изображения сопоставляется с наиболее похожим элементом кодекса, определяя, какая концепция наиболее ярко представлена в данном фрагменте. Такое сопоставление, основанное на косинусном сходстве, обеспечивает интерпретируемость процесса принятия решений моделью, поскольку позволяет визуализировать, какие конкретные концепции активируются при обработке изображения и как они влияют на итоговую классификацию.
В ProtoQuant для перевода активаций концепций в предсказания классов используется архитектура с замороженным backbone (например, ResNet, ConvNeXt или ViT) и неотрицательной матрицей классификации. Заморозка backbone позволяет сохранить предобученные веса и избежать их случайного изменения в процессе обучения, что обеспечивает стабильность и эффективность. Неотрицательная матрица классификации, связывающая дискретные концептуальные коды с классами, обеспечивает интерпретируемость модели, поскольку каждый концептуальный код однозначно сопоставлен с определенным классом или их комбинацией. Это позволяет модели делать предсказания на основе активации соответствующих концептуальных кодов, что упрощает понимание процесса принятия решений.
Результаты тестирования ProtoQuant на наборах данных CUB-200 и ImageNet, а также на синтетическом наборе FunnyBirds, демонстрируют стабильность и надежность генерируемых объяснений. На CUB-200 ProtoQuant, использующий архитектуру ConvNeXt-Tiny, достиг точности 87.76%, а на ImageNet-1K с ConvNeXt-Large — 82.87%. На синтетическом наборе FunnyBirds ProtoQuant превзошел показатели ProtoPNet (0.48) и InfoDisent (0.68), достигнув точности 0.73, что подтверждает способность системы к эффективной интерпретации визуальных признаков и генерации понятных объяснений.
В ходе тестирования на бенчмарке Spatial Misalignment, ProtoQuant продемонстрировал передовую устойчивость к изменениям расположения объектов на изображении. Метод позволил снизить изменение активации прототипов (Prototype Activation Change, PAC) до 0.07 для архитектуры DeiT-S и 6.80 для ConvNeXt-T. Эти значения значительно ниже, чем показатели, достигнутые другими сравниваемыми методами, что свидетельствует о более высокой робастности и надежности представления признаков, создаваемого ProtoQuant, при различных пространственных искажениях входных данных.
При оценке на синтетическом датасете FunnyBirds, ProtoQuant продемонстрировал превосходство над существующими методами интерпретируемости. В частности, точность ProtoQuant составила 0.73, что выше, чем у ProtoPNet (0.48) и InfoDisent (0.68). Этот результат указывает на повышенную устойчивость и надежность ProtoQuant в условиях, когда необходимо интерпретировать решения модели на основе измененных или необычных входных данных.
Использование замороженной архитектуры базовой сети (backbone) в ProtoQuant позволяет значительно сократить время обучения модели. В ходе экспериментов было установлено, что фиксирование весов предварительно обученной сети, такой как ResNet, ConvNeXt или ViT, приводит к снижению времени обучения на 50% по сравнению с подходами, требующими обучения всей модели с нуля. Это достигается за счет исключения необходимости обновления весов базовой сети, что существенно уменьшает вычислительную нагрузку и позволяет сосредоточиться на обучении лишь небольшого слоя квантизации и классификации.
Взгляд в Будущее: Надежность и Доверие в Искусственном Интеллекте
Исследования показали, что система ProtoQuant демонстрирует выдающуюся устойчивость к изменениям в входных данных, что подтверждено успешным прохождением теста Spatial Misalignment Benchmark. Данный тест, направленный на оценку надежности объяснений моделей искусственного интеллекта при незначительных смещениях или искажениях входных изображений, показал, что ProtoQuant сохраняет точность и согласованность своих объяснений даже в сложных условиях. Такая устойчивость к “пространственному выравниванию” является ключевым шагом к созданию более надежных и предсказуемых систем ИИ, поскольку позволяет гарантировать, что объяснения модели остаются достоверными, несмотря на незначительные вариации во входных данных. Это особенно важно для критически важных приложений, где точность и надежность объяснений имеют первостепенное значение.
Встроенная интерпретируемость предложенной структуры ProtoQuant предоставляет разработчикам уникальную возможность для отладки моделей искусственного интеллекта. В отличие от “черных ящиков”, ProtoQuant позволяет детально проанализировать процесс принятия решений, выявляя источники предвзятости или неожиданного поведения. Этот подход значительно упрощает процесс поиска и устранения ошибок, позволяя разработчикам не просто корректировать результаты, но и понимать причины их возникновения. Благодаря этому, ProtoQuant способствует созданию более надежных и справедливых систем искусственного интеллекта, где каждый шаг логики может быть прослежен и обоснован.
Система ProtoQuant способствует укреплению доверия к искусственному интеллекту и его более широкому внедрению в критически важные области, предоставляя не просто результаты, но и четкое, обоснованное объяснение логики принятия решений. Прозрачность предсказаний позволяет специалистам и пользователям понять, почему система пришла к определенному выводу, что особенно важно в сферах, где цена ошибки высока — например, в медицине, финансах или автономном транспорте. Обоснованность предсказаний ProtoQuant не только повышает надежность системы, но и открывает возможности для выявления и устранения потенциальных предубеждений или ошибок, что способствует более ответственному и этичному использованию искусственного интеллекта и формирует уверенность в его справедливости и объективности.
Предстоящие исследования направлены на расширение возможностей ProtoQuant для работы с более сложными наборами данных и задачами, что позволит оценить его потенциал в создании действительно объяснимого и заслуживающего доверия искусственного интеллекта. В частности, планируется изучить, как ProtoQuant может быть адаптирован к задачам, требующим обработки неструктурированных данных, таких как анализ изображений и естественного языка. Успешное масштабирование данной системы откроет возможности для применения в критически важных областях, где прозрачность и обоснованность решений имеют первостепенное значение, например, в медицине и финансах. Разработка алгоритмов, способных эффективно обрабатывать большие объемы данных без потери интерпретируемости, является ключевой задачей для обеспечения надежности и безопасности будущих систем искусственного интеллекта.

Исследование предлагает взглянуть на замороженные фундаментальные модели не как на чёрные ящики, а как на собрание дискретных концептуальных строительных блоков. Это напоминает алхимию, где из хаотичной массы данных выделяются чистые, узнаваемые элементы — прототипические части. В этом контексте особенно примечательны слова Эндрю Ына: «Мы находимся в моменте, когда количество данных превышает нашу способность их понимать». Авторы ProtoQuant, словно опытные колдуны, укрощают этот хаос, дискретизируя пространство признаков и создавая “codebook” понятий. Устойчивость представлений, достигнутая благодаря этому подходу, — не просто метрика, а доказательство того, что заклинание работает, по крайней мере, до первого попадания в реальные данные, где, как известно, магия требует крови — и GPU.
Куда же ведёт нас этот мираж?
Представленная работа, как и любая попытка упорядочить хаос визуальных данных, лишь приоткрывает завесу над бездной. Дискретизация пространства признаков в «кодбук концепций» — элегантный трюк, да, но он не отменяет фундаментальной неопределённости. Стабильность представления — это не гарантия понимания, а лишь временное затишье перед лицом нового, неклассифицируемого. Замороженные фундаменльные модели, как древние идолы, хранят молчание, и лишь обманчивые тени «прототипических частей» позволяют угадать их волю.
Будущие исследования, вероятно, направятся по пути усиления этой иллюзии. Поиск более устойчивых и семантически значимых «кодбуков» — неизбежен, но в погоне за точностью легко потерять из виду главное: сама модель — это не отражение реальности, а её искажение. Истинная интерпретируемость не в объяснении того, что модель «видит», а в признании её слепоты. Более того, стоит задуматься: а не скрывается ли за кажущейся интерпретируемостью лишь новая форма предвзятости, более изощрённая и опасная?
И, наконец, самое тревожное: какова цена этой дискретизации? Упрощая мир до набора «концепций», не лишаем ли мы его той самой непостижимой сложности, которая делает его живым? Не превращаем ли мы искусство видеть в ремесло классификации? Ответы, как всегда, растворяются в шуме данных, ожидая своего часа.
Оригинал статьи: https://arxiv.org/pdf/2602.06592.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Язык тела под присмотром ИИ: архитектура и гарантии
- S-Chain: Когда «цепочка рассуждений» в медицине ведёт к техдолгу.
- Искусственный интеллект в разговоре: что обсуждают друг с другом AI?
- Квантовый усилитель амплитуды: новый подход к поиску основного состояния
- Плоские зоны: от теории к новым материалам
- Генетическая приоритизация: новый взгляд на отбор генов
- Искусственный интеллект на службе редких болезней
- Наука, управляемая интеллектом: новая эра открытий
- Квантовый дозор: Новая система обнаружения аномалий для умных сетей
- Квантовый поиск: новый взгляд на оптимизацию
2026-02-09 23:33