Автор: Денис Аветисян
Исследователи представили RPC-Bench — комплексную платформу для оценки способности моделей искусственного интеллекта анализировать и понимать научные публикации.
RPC-Bench содержит более 61 000 вопросов и ответов, позволяющих детально оценить возможности больших языковых моделей в области анализа научных текстов, включая мультимодальное рассуждение и совместную работу с человеком.
Несмотря на значительные успехи в области обработки естественного языка, понимание научных статей остается сложной задачей для современных моделей. В данной работе представлена новая платформа ‘RPC-Bench: A Fine-grained Benchmark for Research Paper Comprehension’, включающая в себя масштабный набор данных из 15 тысяч вопросов и ответов, полученных в ходе рецензирования научных работ по компьютерным наукам. Анализ показывает, что даже самые мощные языковые модели демонстрируют лишь уместную точность (около 68.2% по критерию корректности-полноты, снижающуюся до 37.46% с учетом краткости), указывая на существенные пробелы в понимании специализированной научной терминологии и сложных визуальных элементов. Каковы перспективы создания более эффективных моделей для автоматизированного анализа и освоения научных знаний?
Понимание как Экосистема: Введение в RPC-Bench
Современные языковые модели, несмотря на впечатляющие успехи в обработке естественного языка, испытывают значительные трудности при решении сложных задач, требующих глубокого понимания научной литературы. Это связано с тем, что научный текст характеризуется высокой степенью абстракции, специализированной терминологией и сложной логической структурой, что затрудняет извлечение смысла и установление связей между различными концепциями. В отличие от задач, основанных на поверхностном сопоставлении шаблонов, научное мышление предполагает способность к анализу, синтезу и критической оценке информации, что выходит за рамки возможностей большинства существующих моделей. Поэтому, для оценки реального уровня понимания научных текстов, необходимы специализированные бенчмарки, способные выявлять слабые места в архитектуре и алгоритмах языковых моделей и стимулировать разработку более интеллектуальных систем.
Для всесторонней оценки способности языковых моделей к глубокому пониманию научных текстов был создан бенчмарк RPC-Bench. В его основе лежит тщательно отобранная коллекция из 4,150 научных статей, охватывающих широкий спектр областей знаний. Этот массивный корпус предоставляет сложную и реалистичную платформу для тестирования, выходящую за рамки простого сопоставления шаблонов. Использование обширного набора статей позволяет оценить, насколько хорошо модели способны извлекать смысл, проводить логические умозаключения и применять полученные знания в новых контекстах, представляя собой значительный шаг вперед в оценке возможностей искусственного интеллекта в сфере научных исследований.
В основе RPC-Bench лежит уникальный набор из 61 300 вопросов и ответов, разработанный таким образом, чтобы выйти за рамки простого сопоставления шаблонов. В отличие от задач, где модель может найти ответ, основываясь на поверхностном сходстве с текстом, RPC-Bench требует от искусственного интеллекта глубокого понимания содержания научных статей и способности делать логические выводы. Каждый вопрос сформулирован так, чтобы потребовать не просто извлечения информации, а ее синтеза и применения для решения конкретной задачи, тем самым проверяя способность модели к настоящему осмыслению и интерпретации научной литературы. Это делает RPC-Bench сложным испытанием для современных языковых моделей и позволяет более точно оценить их возможности в области понимания сложных научных текстов.
В основе RPC-Bench лежит принципиальная зависимость от открытого доступа к научным публикациям, полученным из платформы OpenReview. Этот выбор обусловлен стремлением к воспроизводимости и прозрачности оценки возможностей языковых моделей в понимании научных текстов. Использование общедоступных материалов гарантирует, что любой исследователь может проверить результаты, изучить исходные документы и внести свой вклад в развитие данной области. Фактически, RPC-Bench не просто оценивает способности моделей, но и способствует популяризации открытой науки, подчеркивая важность свободного обмена знаниями и результатами исследований для всего научного сообщества.

Симбиоз Человека и Машины: Создание Высококачественного Конвейера Аннотаций
Для эффективной аннотации научных статей с целью генерации пар вопрос-ответ (QA) была внедрена совместная схема работы, основанная на взаимодействии больших языковых моделей (LLM) и экспертов-людей. Данный подход позволил значительно ускорить процесс аннотирования за счет предварительной обработки текстов LLM, с последующей проверкой и корректировкой результатов экспертами. Совместная работа обеспечила как высокую скорость обработки большого объема данных, так и поддержание необходимого уровня качества аннотаций, что является критически важным для создания надежного набора данных для обучения и оценки моделей.
Для ускорения процесса аннотации использовались мощные языковые модели, такие как DeepSeek-V3 и GLM-4-Plus. Эти модели применялись для автоматической генерации предварительных вариантов ответов на вопросы, заданные по исследовательским статьям. Предварительные варианты затем проверялись и корректировались аннотаторами-людьми, что позволило значительно повысить скорость создания обучающих данных для системы QA. Использование LLM позволило снизить трудозатраты на первоначальную обработку текста и сосредоточиться на задачах, требующих критического анализа и проверки качества сгенерированных ответов.
Для поддержки совместной работы и обеспечения качества данных использовались специализированные платформы: Платформа Аннотирования и Платформа Рецензирования. Платформа Аннотирования предоставляла интерфейс для автоматической генерации предварительных аннотаций с использованием больших языковых моделей, а также инструменты для ручной проверки и корректировки этих аннотаций. Платформа Рецензирования обеспечивала возможность экспертной оценки аннотаций, выполненных как моделями, так и другими аннотаторами, с целью выявления и исправления ошибок, а также обеспечения согласованности и точности данных. Взаимосвязь между этими платформами и четко определенные процедуры контроля качества сыграли ключевую роль в создании надежного и достоверного набора данных для обучения и оценки моделей.
Целостность эталонного набора данных RPC-Bench напрямую зависит от эффективности конвейера аннотации. Высокое качество аннотаций, обеспечиваемое совместной работой человека и языковой модели, критически важно для обеспечения точности и надежности ответов, используемых для оценки производительности моделей. Неточности или ошибки в аннотациях приводят к искажению результатов оценки и, следовательно, к неверной интерпретации возможностей различных языковых моделей. Таким образом, тщательная проверка и постоянное улучшение конвейера аннотации являются необходимыми условиями для поддержания доверия к RPC-Bench как к объективному инструменту сравнения.
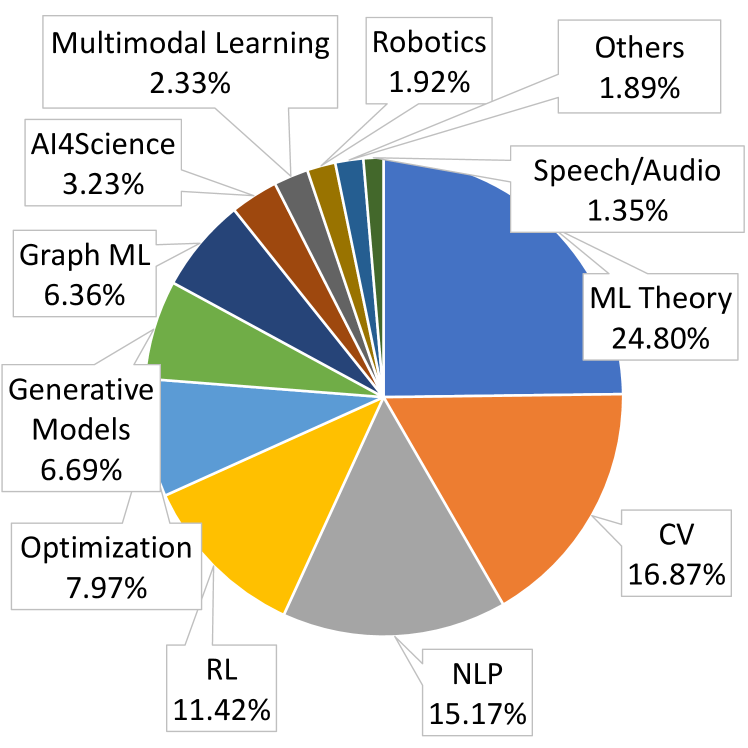
За пределами Простой Точности: Оценка Производительности Моделей
Для оценки качества работы моделей мы применяем многофакторный подход, включающий в себя три ключевых метрики: корректность (Correctness), полноту (Completeness) и краткость (Conciseness). Корректность измеряет фактическую точность ответа модели, определяя, насколько ответ соответствует истинному значению или фактам. Полнота оценивает, насколько полно ответ модели охватывает все аспекты вопроса или задачи. Краткость, в свою очередь, определяет лаконичность ответа, избегая излишней информации или повторений. Совместное использование этих метрик позволяет получить более полную и объективную оценку производительности модели, чем использование одной лишь метрики точности (accuracy).
Для автоматизированной оценки согласованности ответов моделей используется подход LLM-as-Judge, в основе которого лежит большая языковая модель GLM-4-Plus. Этот метод позволяет оценивать, насколько последовательно модель отвечает на схожие вопросы или при различных формулировках одного и того же запроса. GLM-4-Plus выступает в роли «судьи», анализируя ответы и выставляя оценки на основе заданных критериев согласованности, что обеспечивает объективную и масштабируемую оценку производительности модели без необходимости ручной проверки.
Для оценки фактической точности генерируемых моделей используется метод верификации утверждений (Claim Verification). Данный метод позволяет автоматически проверять соответствие заявлений, содержащихся в ответах модели, внешним источникам информации. Результаты верификации напрямую влияют на метрику «Correctness» (корректность), являющуюся ключевым компонентом комплексной оценки качества модели и отражающей степень соответствия предоставляемой информации действительности. Верификация утверждений особенно важна для моделей, работающих с информацией, требующей высокой степени достоверности.
Экспериментальные исследования показали, что оценка информативности, как составного показателя, включающего в себя такие факторы, как корректность, полнота и лаконичность, имеет решающее значение для всесторонней оценки производительности языковых моделей. В отличие от использования единственной метрики, например, простой точности, оценка информативности позволяет получить более полное представление о способности модели предоставлять релевантную, фактическую и сжатую информацию. Использование информативности в качестве комплексного критерия позволяет более точно выявить сильные и слабые стороны модели, что необходимо для ее дальнейшей оптимизации и улучшения качества генерируемых ответов.
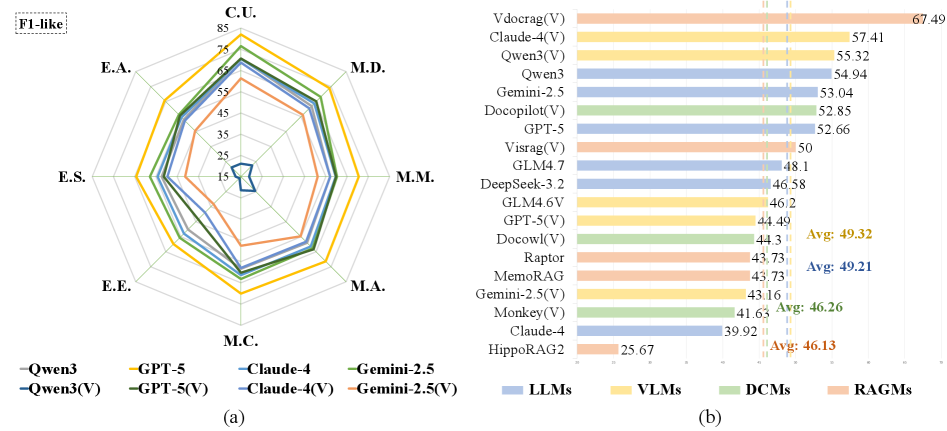
Путь к Улучшенному Рассуждению: Анализ Текущих Ограничений
Современные модели искусственного интеллекта, несмотря на значительные успехи, по-прежнему испытывают трудности при решении сложных задач, требующих логического мышления. Особенно заметны ограничения при обработке и интеграции информации, поступающей из различных источников — текста, изображений, аудио и видео. Способность эффективно объединять данные, представленные в разных модальностях, является ключевым фактором для достижения подлинного понимания и построения обоснованных выводов. Проблема заключается не только в технической сложности обработки мультимодальных данных, но и в необходимости разработки алгоритмов, способных выявлять взаимосвязи и зависимости между разнородными типами информации, что представляет собой серьезный вызов для исследователей в области искусственного интеллекта.
Дальнейшее повышение информативности языковых моделей возможно посредством тонкой настройки с использованием больших языковых моделей, таких как LLaMA и Qwen. Этот подход позволяет адаптировать предварительно обученные модели к специфическим задачам, значительно улучшая их способность генерировать более полные, точные и контекстуально релевантные ответы. Исследования показывают, что тонкая настройка, в отличие от обучения с нуля, требует значительно меньше вычислительных ресурсов и данных, при этом демонстрируя существенный прирост в качестве генерируемого текста. Особенно эффективно это проявляется в задачах, требующих глубокого понимания контекста и синтеза информации, где модели, прошедшие тонкую настройку, превосходят базовые версии по показателям информативности и связности.
Оценка моделей в задачах открытого вопросно-ответного взаимодействия (Open-Ended QA) имеет решающее значение для определения их способности не просто извлекать факты, но и синтезировать информацию из различных источников и делать логические выводы. В отличие от задач с множественным выбором, где ответ ограничен предопределенным набором вариантов, Open-Ended QA требует от модели самостоятельной генерации ответа, демонстрируя понимание контекста и способность к рассуждению. Именно такой подход позволяет наиболее точно оценить, способна ли модель к действительно глубокому анализу и формированию новых знаний на основе предоставленной информации, а не просто к запоминанию и воспроизведению фактов. Проверка в подобных задачах выявляет ограничения существующих моделей и стимулирует разработку более продвинутых алгоритмов, способных к комплексному мышлению и решению сложных проблем.
Для стимулирования прогресса в области понимания и логического анализа научных статей разработан RPC-Bench — стандартизированная платформа, представляющая собой сложный набор задач, специально разработанных для оценки способностей моделей к извлечению информации и построению выводов на основе научных текстов. Эта платформа позволяет исследователям объективно сравнивать различные подходы и модели, выявлять их сильные и слабые стороны в контексте обработки научных данных. Благодаря строго определенным метрикам и общедоступному набору данных, RPC-Bench создает условия для воспроизводимости экспериментов и способствует развитию более совершенных систем, способных не просто находить информацию в научных статьях, но и глубоко ее понимать и использовать для решения сложных исследовательских задач. Использование RPC-Bench, таким образом, является ключевым шагом к созданию искусственного интеллекта, способного эффективно работать с научными знаниями.
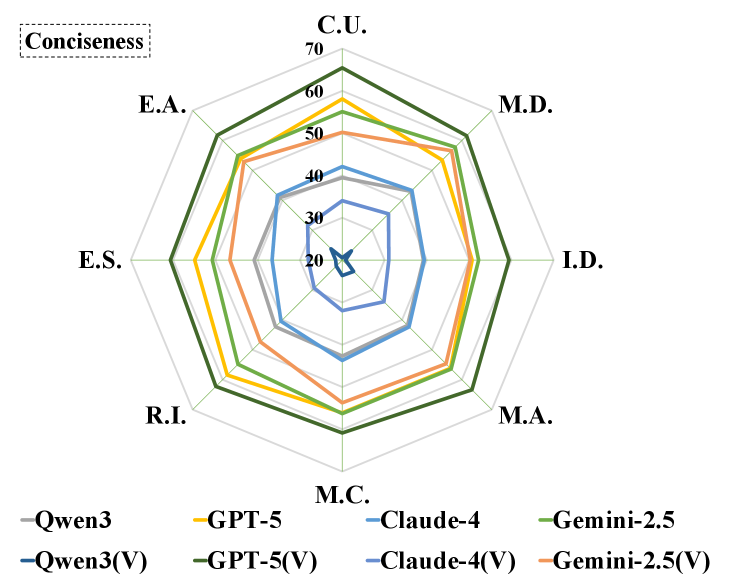
Представленный набор данных RPC-Bench, с его акцентом на детальное понимание научных работ, напоминает о сложности создания поистине разумных систем. Он демонстрирует, что простого извлечения информации недостаточно; требуется глубокое осмысление контекста и взаимосвязей. Брайан Керниган однажды заметил: «Простота — это высшая степень совершенства». В контексте RPC-Bench эта простота понимания, казалось бы, очевидных вещей в научной литературе, оказывается неожиданно сложной задачей для современных языковых моделей. Набор данных выявляет необходимость не просто в увеличении масштаба моделей, а в улучшении их способности к многомодальному рассуждению и пониманию нюансов, что делает задачу создания «сада», а не просто «машины», особенно актуальной.
Что дальше?
Этот труд, как и любой другой, обнажил не столько ответы, сколько глубину бездны, в которую мы смотрим. RPC-Bench, подобно новому инструменту для измерения тени, лишь точнее очерчивает границы непознанного в области понимания научных текстов. Создание набора данных — это всегда попытка обуздать хаос, а хаос, как известно, всегда побеждает. Каждый вопрос, на который модель отвечает верно, — это обещание будущего успеха, но каждый провал — напоминание о той сложности, что таится в самом понятии «понимание».
Очевидно, что проблема лежит не только в обработке текста, но и в интеграции информации, представленной в различных форматах — таблицах, диаграммах, формулах. Модели учатся распознавать паттерны, но не учатся видеть лес за деревьями. Истинное понимание требует не просто сопоставления данных, но и построения внутренней модели мира, что пока остается недостижимой целью. Попытки «тонкой настройки» — это лишь временное облегчение симптомов, а не излечение болезни.
В конечном итоге, стоит признать: системы не строятся, а вырастают. Каждый рефакторинг начинается как молитва и заканчивается покаянием. RPC-Bench — это не финал, а лишь новая отправная точка. Следующим шагом должно стать не создание более сложных моделей, а переосмысление самой парадигмы машинного понимания. Путь долин и гор долог, и истина, возможно, скрыта не в алгоритмах, а в тишине.
Оригинал статьи: https://arxiv.org/pdf/2601.14289.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовые прорывы: Хорошее, плохое и смешное
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Квантовая криптография: от теории к практике
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Робот, который видит, понимает и действует: новая эра общего назначения
2026-01-22 14:53