Автор: Денис Аветисян
Представлена модель LongCat-Flash-Thinking-2601, демонстрирующая продвинутые возможности агентного рассуждения и обучения с подкреплением.
Исследование описывает архитектуру и инфраструктуру обучения масштабной языковой модели с акцентом на обработку длинного контекста и эффективное обучение.
Несмотря на значительный прогресс в области больших языковых моделей, создание агентов, способных к сложному рассуждению и адаптации к реальным условиям, остается сложной задачей. В данной работе, представленной в ‘LongCat-Flash-Thinking-2601 Technical Report’, мы представляем LongCat-Flash-Thinking-2601 — открытую модель с 560 миллиардами параметров, демонстрирующую передовые возможности в области агентского рассуждения. Ключевым фактором успеха модели является комплексный подход к обучению, объединяющий параллельную экспертную подготовку, масштабируемую инфраструктуру и устойчивое обучение с подкреплением в разнообразных и зашумленных средах. Какие новые горизонты откроются в области агентского ИИ с дальнейшим развитием подобных моделей и инфраструктур?
Эмерджентность Агентного Разума
Традиционные системы искусственного интеллекта часто демонстрируют ограниченные возможности при решении задач, требующих адаптивного взаимодействия с окружающей средой — способности, которая является ключевой характеристикой человеческого интеллекта. В отличие от людей, которые способны гибко реагировать на изменяющиеся обстоятельства и самостоятельно искать пути решения проблем, большинство алгоритмов ИИ полагаются на заранее заданные правила и данные. Это приводит к трудностям при столкновении с непредсказуемыми ситуациями или необходимостью принимать решения в условиях неполной информации. Например, робот, запрограммированный для выполнения конкретной задачи в статической среде, может оказаться беспомощным при появлении неожиданного препятствия или изменении освещения. Ограниченность таких систем подчеркивает необходимость разработки новых подходов к созданию ИИ, способного к более гибкому и адаптивному поведению, подобно человеческому.
Рассуждения, основанные на принципах агентности, представляют собой кардинальный сдвиг в подходах к искусственному интеллекту. В отличие от традиционных систем, которые ограничиваются пассивной обработкой предоставленных данных, агентные системы способны активно формировать цели и самостоятельно искать пути их достижения. Они взаимодействуют с окружающей средой, выдвигают гипотезы, проводят эксперименты и анализируют результаты, чтобы найти оптимальное решение. Такой подход позволяет создавать системы, которые не просто отвечают на заданные вопросы, а способны решать сложные задачи, адаптироваться к меняющимся условиям и проявлять инициативу, приближаясь к когнитивным способностям человека.
LongCat: Новое Поколение Агентского Разума
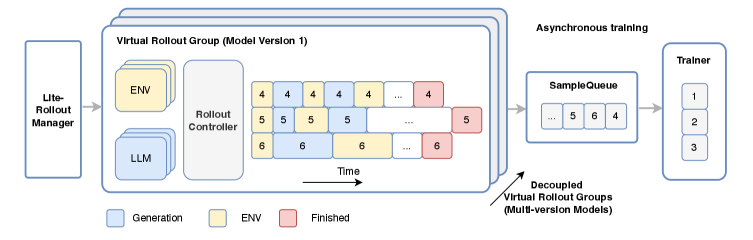
Модель LongCat-Flash-Thinking-2601, представляющая собой MoE-архитектуру с 560 миллиардами параметров, разработана для максимального увеличения возможностей агента благодаря унифицированному конвейеру обучения. Этот подход объединяет различные этапы обучения в единый процесс, оптимизируя модель для выполнения сложных задач, требующих планирования, рассуждения и адаптации к новым ситуациям. Унифицированный конвейер позволяет модели эффективно использовать данные и ресурсы, что приводит к улучшению производительности и повышению способности к автономному решению задач.
Модель LongCat использует архитектуру Mixture of Experts (MoE) для существенного повышения своей емкости и производительности. MoE предполагает разделение модели на несколько «экспертов», каждый из которых специализируется на определенной подзадаче или типе данных. Во время обработки входных данных, механизм маршрутизации динамически выбирает наиболее подходящих экспертов для решения конкретной части задачи. Это позволяет модели масштабировать количество параметров — в случае LongCat их 560 миллиардов — без пропорционального увеличения вычислительных затрат, что критически важно для выполнения сложных задач, требующих глубокого рассуждения и обработки больших объемов информации. По сути, MoE позволяет LongCat эффективно использовать свои ресурсы и достигать более высокой точности и скорости в решении сложных проблем.
Ключевой особенностью LongCat является использование механизма Zigzag Attention, обеспечивающего эффективное масштабирование до обработки ультра-длинных контекстов с минимальной потребностью в переобучении. В отличие от традиционных механизмов внимания, требующих квадратичной сложности по длине последовательности, Zigzag Attention позволяет снизить вычислительные затраты и объём памяти, необходимые для обработки длинных входных данных. Это достигается за счёт выборочного применения внимания к релевантным частям контекста, что критически важно для решения сложных задач, требующих анализа и синтеза информации из обширных объемов данных и выполнения многошаговых рассуждений.
Обучение к Адаптивности и Устойчивости
В процессе Mid-Training расширение возможностей LongCat осуществляется за счет использования масштабных объемов данных и эффективных стратегий обучения. Ключевым элементом является Environment Scaling — метод конструирования разнообразных и сложных задач для модели. Данный подход позволяет генерировать широкий спектр сценариев, варьируя параметры окружения и создавая новые условия для обучения. Это способствует повышению устойчивости и обобщающей способности LongCat, позволяя модели эффективно адаптироваться к различным, ранее не встречавшимся ситуациям и обеспечивая ее производительность в динамически меняющейся среде.
Пост-тренировочная доработка производительности LongCat осуществляется посредством обучения с подкреплением (Reinforcement Learning), направленного на оптимизацию взаимодействия с долгосрочными задачами и повышение адаптивности модели. Данный этап позволяет модели осваивать стратегии, требующие последовательного принятия решений на протяжении длительных временных горизонтов, что особенно важно для сложных сценариев. Обучение с подкреплением позволяет LongCat не только улучшать текущие показатели, но и приобретать способность эффективно функционировать в динамически меняющихся условиях, адаптируя свое поведение к новым требованиям и задачам.
Для обеспечения надежности в реальных условиях эксплуатации, в процесс обучения LongCat интегрируется Robust RL (Обучение с подкреплением, устойчивое к помехам). Данный подход предполагает тренировку модели в условиях намеренного внесения шумов и непредсказуемых изменений в окружение. Целью является развитие способности LongCat к стабильной и корректной работе даже при наличии несовершенства входных данных и вариативности внешней среды. Это достигается путем использования алгоритмов, оптимизированных для работы с неполной или искаженной информацией, а также за счет расширения набора обучающих данных примерами, имитирующими реальные помехи и неточности.
Обучение с подкреплением в многодоменной среде (Multi-Domain RL) направлено на расширение возможностей LongCat посредством развития обобщенных навыков агента, применимых к широкому спектру задач. Этот подход предполагает тренировку модели на разнообразных средах и задачах, что позволяет ей эффективно адаптироваться к новым, ранее не встречавшимся ситуациям. В процессе обучения, LongCat учится извлекать общие принципы и стратегии решения задач, не зависящие от конкретной среды, что повышает его устойчивость и эффективность в различных условиях. Использование Multi-Domain RL способствует формированию у модели способности к переносу знаний и навыков между задачами, что критически важно для достижения высокой степени обобщения и надежности.
Оценка Агентского Интеллекта
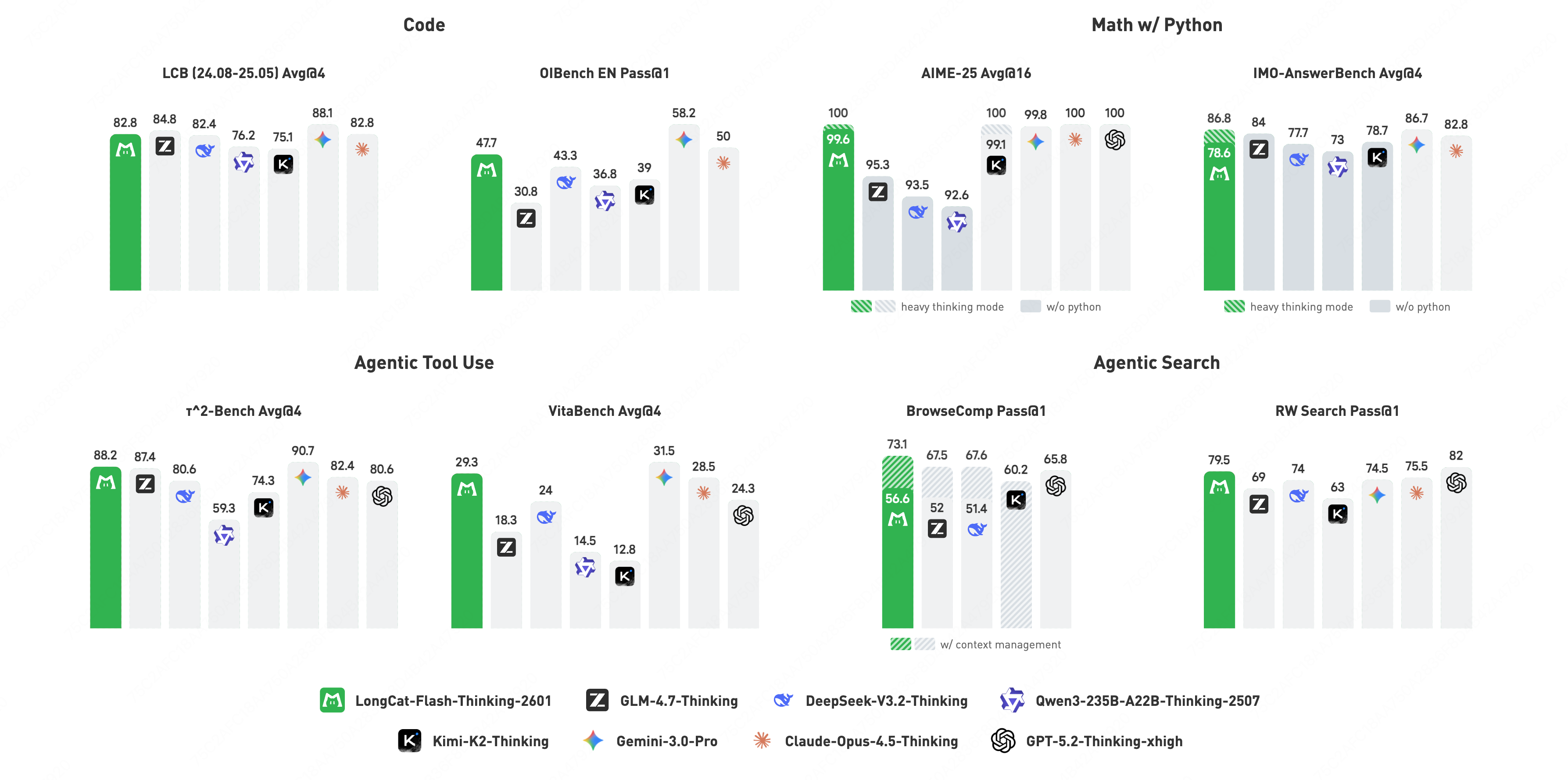
Модель LongCat продемонстрировала выдающиеся результаты на бенчмарке AMA-Bench, достигнув точности в 86.8%. Этот показатель не только подтверждает высокую эффективность модели в решении задач, требующих понимания и обработки информации, но и устанавливает новый стандарт производительности среди всех открытых моделей. Достигнутый результат свидетельствует о значительном прогрессе в области агентного интеллекта и открывает перспективы для создания более сложных и эффективных систем искусственного интеллекта, доступных для широкого круга исследователей и разработчиков.
Оценка модели LongCat на платформе BrowseComp продемонстрировала ее высокую эффективность в использовании инструментов, характерную для агентов искусственного интеллекта. Достигнув точности в 73.1%, модель установила новый стандарт производительности среди открытых исходных кодов. Этот результат подтверждает способность LongCat к самостоятельному планированию и выполнению задач, требующих взаимодействия с различными инструментами для поиска и обработки информации. Подобная эффективность в использовании инструментов является ключевым показателем для создания действительно автономных и интеллектуальных агентов, способных решать сложные задачи без непосредственного вмешательства человека.
Модель LongCat продемонстрировала выдающиеся результаты на бенчмарке BrowseComp-ZH, достигнув точности в 77.7%. Этот показатель не только превосходит все предыдущие результаты среди моделей с открытым исходным кодом, но и устанавливает новый стандарт для оценки способностей агентов к поиску и обработке информации на китайском языке. Успех LongCat на BrowseComp-ZH подтверждает ее превосходство в решении задач, требующих взаимодействия с инструментами и понимания сложных запросов, что делает ее важным шагом в развитии агентного искусственного интеллекта.
В ходе тестирования на бенчмарке OJBench, LongCat продемонстрировал выдающиеся результаты, став лучшей моделью с открытым исходным кодом по показателю Pass@1. Этот показатель оценивает способность модели успешно решать сложные задачи, требующие многоступенчатого рассуждения и планирования. Достигнутый LongCat уровень производительности свидетельствует о его превосходстве в области агентного интеллекта и способности эффективно применять свои знания для достижения поставленных целей, превосходя другие доступные решения с открытым кодом в данной области и открывая новые перспективы для развития автономных систем.
В ходе оценки возможностей модели LongCat на платформе BrowseComp было установлено, что оптимальная длина контекста для достижения наивысшей производительности составляет 80 тысяч токенов. Данный параметр критически важен, поскольку он определяет объем информации, которую модель способна эффективно обрабатывать и использовать для решения задач. Более короткий контекст может привести к потере важных деталей, в то время как избыточно длинный — к снижению скорости обработки и увеличению вычислительных затрат. Выявление оптимальной длины контекста позволило максимально раскрыть потенциал LongCat в задачах, требующих анализа больших объемов информации и использования инструментов, подтверждая её передовые позиции среди моделей с открытым исходным кодом.
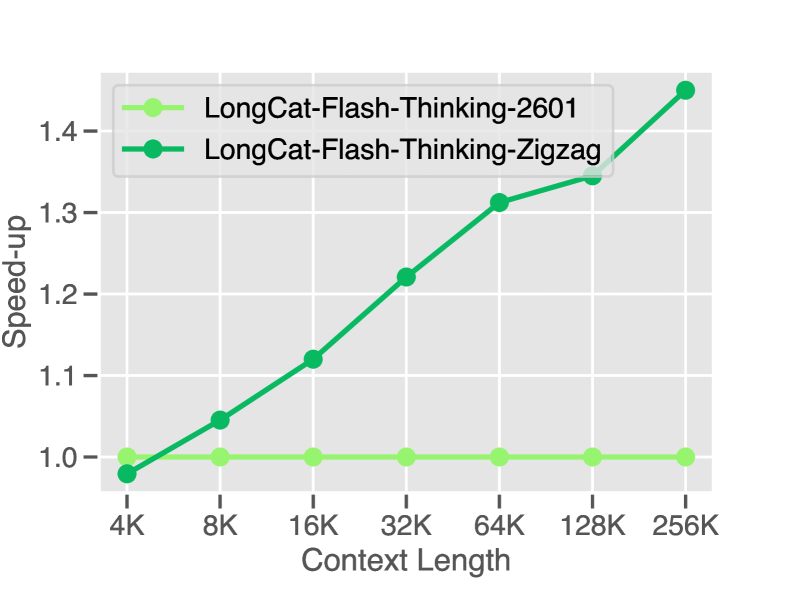
Исследование, представленное в данной работе, демонстрирует закономерность, которую можно охарактеризовать как неизбежный рост зависимости в сложных системах. Модель LongCat-Flash-Thinking-2601, несмотря на свои передовые возможности в области агентного рассуждения и обработки длинного контекста, лишь подтверждает эту тенденцию. Как отмечал Бертран Рассел: «Всякое знание и всякое убеждение имеют практическое основание». Стремление к масштабируемости и улучшению производительности, присущее разработке подобных моделей, не отменяет фундаментального принципа: каждая архитектурная оптимизация создает новые точки отказа, а каждый шаг к усложнению увеличивает вероятность синхронного сбоя. Система, хоть и выращенная с применением передовых методов обучения с подкреплением, все равно остается хрупкой экосистемой, подверженной влиянию внешних факторов и внутренних зависимостей.
Куда Ведет Дорога?
Представленная работа демонстрирует, как можно усложнить систему, чтобы она казалась разумнее. Однако, не стоит обманываться кажущейся способностью к “агентному мышлению”. Увеличение контекстного окна и усложнение инфраструктуры обучения — это не решение, а лишь отсрочка неизбежного. Каждый новый параметр, каждая оптимизация — это новое место, где система может дать сбой, причем сбой этот будет не предсказуем, а эмерджентен.
Истинный вызов заключается не в увеличении масштаба, а в понимании принципов самоорганизации. Модель не ломается — она эволюционирует в неожиданные формы, часто далекие от задуманных создателями. Настоящая проблема — не в достижении “сильного ИИ”, а в создании систем, способных адаптироваться к непредсказуемости мира, не требуя постоянного вмешательства и переобучения. Долговременная стабильность — признак скрытой катастрофы, затаившейся в глубинах сложной архитектуры.
Будущие исследования должны сместить фокус с “обучения” на “выращивание”. Необходимо искать методы, позволяющие создавать системы, способные к самовосстановлению, самооптимизации и даже самопроектированию. Иначе, все усилия по увеличению масштаба и усложнению инфраструктуры окажутся лишь строительством хрупкого замка из песка, обреченного на разрушение под натиском непредсказуемости.
Оригинал статьи: https://arxiv.org/pdf/2601.16725.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-26 14:19