Автор: Денис Аветисян
Исследователи представляют ASQ — набор данных, отражающий поисковые стратегии искусственного интеллекта, демонстрируя существенные отличия от поведения человека при поиске информации.
Представлен набор данных ASQ, позволяющий изучить поисковые паттерны ИИ-агентов и пересмотреть базовые принципы информационного поиска.
По мере того, как автоматизированные системы все активнее участвуют в формировании поисковых запросов наряду с человеком, традиционные подходы к информационному поиску (IR) сталкиваются с фундаментальным смещением парадигмы. В работе ‘A Picture of Agentic Search’ анализируется, что, несмотря на это, IR остается ориентированным на человека, а существующие модели, метрики и наборы данных разработаны с учетом исключительно человеческого поведения. Это приводит к несоответствию между предпосылками и реальной практикой, влияя на эффективность систем и оптимизацию поиска. Представленный набор данных Agentic Search Queryset (ASQ) призван заполнить критический пробел в понимании поискового поведения искусственного интеллекта, открывая новые возможности для адаптации IR к новым реалиям.
Поиск глубины: когда ключевые слова бессильны
Традиционные методы информационного поиска, основанные на сопоставлении ключевых слов, зачастую не способны уловить тонкие нюансы и сложные взаимосвязи между данными. Вместо глубокого понимания смысла запроса, такие системы оперируют лишь поверхностным соответствием слов, что приводит к нерелевантным или неполным результатам. Например, запрос о «лечении головной боли» может выдать статьи о любых видах головных болей, игнорируя специфику мигрени или напряжения, о которых пользователь мог подразумевать. Такой подход особенно проблематичен при поиске информации, требующей синтеза данных из различных источников и понимания контекста, что ограничивает эффективность поиска в сложных областях знаний и препятствует удовлетворению информационных потребностей пользователей, стремящихся к глубокому и всестороннему ответу на свой вопрос.
Несмотря на впечатляющие возможности, большие языковые модели (LLM) часто испытывают трудности при решении задач, требующих многоступенчатого логического вывода. В отличие от простого поиска информации, сложные вопросы зачастую требуют последовательного анализа нескольких источников и установления связей между, казалось бы, не связанными фактами. LLM, обученные на огромных объемах текста, могут успешно распознавать паттерны и генерировать правдоподобные ответы, однако им не хватает способности к глубокому логическому анализу и построению сложных умозаключений. Это проявляется в неспособности последовательно объединять информацию из разных фрагментов текста для получения окончательного ответа, что ограничивает их эффективность в задачах, требующих критического мышления и решения проблем.
Ограничения в способности к многоступенчатому логическому выводу негативно сказываются на эффективности систем генерации с использованием поиска (RAG). Несмотря на мощь больших языковых моделей, их применение в RAG-системах сталкивается с трудностями при поиске и синтезе информации, необходимой для ответа на сложные вопросы, требующие анализа нескольких источников и установления между ними связей. Вследствие этого, возникает потребность в разработке более надежных и совершенных методов поиска, способных обеспечить предоставление релевантных данных для последующей обработки языковой моделью и формирования точных и содержательных ответов. Такие методы должны учитывать не только ключевые слова, но и семантические связи, контекст и логические зависимости между фрагментами информации, что позволит значительно повысить качество работы RAG-систем.
Агентный поиск: имитация разумного пользователя
Набор данных ASQ (Agent Search Queries) разработан для моделирования поведения агентов при поиске информации, имитируя реалистичные процессы уточнения запросов. Он содержит значительный объем данных, позволяющий проводить статистически значимые тесты и анализировать стратегии поиска. Объем набора данных позволяет исследовать сложные сценарии, включающие многошаговые запросы и адаптацию стратегий поиска в зависимости от полученных результатов. Это особенно важно для оценки эффективности и надежности систем, использующих большие языковые модели (LLM) для автоматизированного поиска и анализа информации.
Агентный поиск использует большие языковые модели (LLM) для декомпозиции сложных запросов на последовательность более простых поисковых запросов. Этот процесс итеративно уточняет стратегию поиска, позволяя LLM анализировать результаты каждого запроса и формировать последующие запросы на основе полученной информации. Вместо однократной отправки сложного запроса, агентный поиск эмулирует поведение человека, разбивающего задачу на более мелкие шаги и последовательно уточняющего свои поисковые намерения для достижения искомого результата. Такой подход позволяет более эффективно извлекать релевантную информацию из больших объемов данных, особенно в случаях, когда исходный запрос является неоднозначным или требует глубокого контекстного понимания.
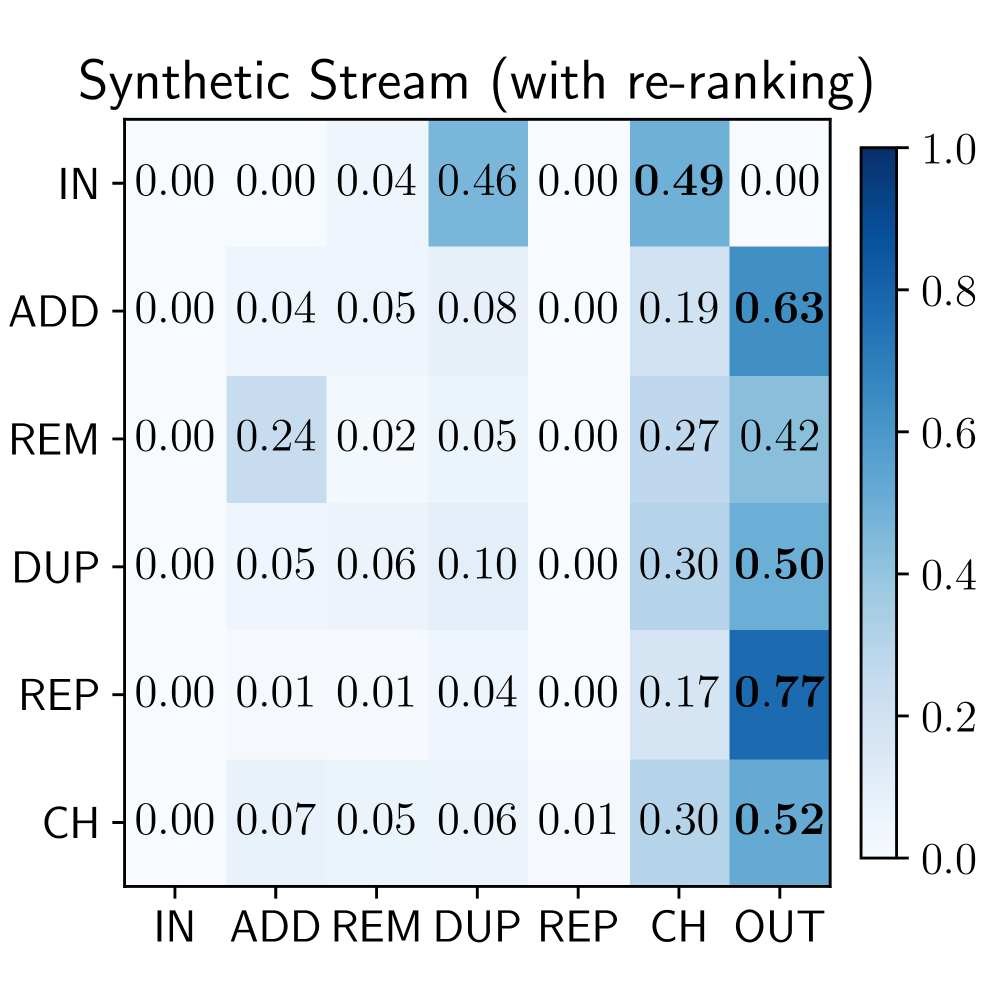
Эффективность агентного поиска напрямую зависит от переформулировки запросов для улучшения результатов и выявления релевантной информации. Анализ данных ASQ показывает, что синтетические запросы, генерируемые агентами, характеризуются значительно более низким соотношением хапаксов (уникальных слов) — от 21% до 43% — по сравнению с органическими запросами пользователей, где этот показатель составляет от 62% до 78%. Более низкий показатель хапаксов в синтетических запросах указывает на тенденцию к использованию более распространенной лексики и меньшей вариативности формулировок, что может быть связано со стратегиями, используемыми агентами для уточнения поисковых интентов.
AutoRefine: автоматическая генерация потока запросов
AutoRefine представляет собой агентическую систему RAG (Retrieval-Augmented Generation), предназначенную для генерации синтетических потоков запросов (Synthetic Query Stream). Данная система обеспечивает масштабируемый источник данных о поведении пользователей при поиске, позволяя создавать большие объемы запросов для тестирования и улучшения поисковых систем, а также для обучения моделей обработки естественного языка. Использование агента позволяет автоматизировать процесс генерации запросов, что значительно эффективнее ручного создания и позволяет охватить более широкий спектр поисковых намерений.
В основе генерации синтетических поисковых запросов в AutoRefine лежит языковая модель Qwen2.5. Данная модель используется для формулирования разнообразных и релевантных запросов, имитирующих поведение пользователей. Qwen2.5 позволяет системе генерировать запросы, охватывающие широкий спектр тем и формулировок, обеспечивая тем самым получение данных о поисковом поведении, максимально приближенных к реальным пользовательским сценариям. Использование Qwen2.5 обеспечивает не только лингвистическую корректность генерируемых запросов, но и их семантическую согласованность, что критически важно для оценки эффективности систем поиска и извлечения информации.
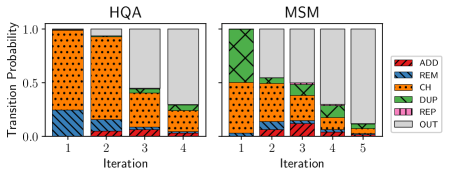
В процессе каждой итерации AutoRefine формируется Trace — последовательность кадров, детально описывающих действия и шаги рассуждений агента. Анализ полученных данных показывает, что частота повторения запросов у агентов составляет 5% в рамках RQ (Retrieval-Questioning), что существенно ниже показателя в 12%, характерного для поведения реальных пользователей. Данный аспект указывает на более эффективное разнообразие запросов, генерируемых AutoRefine, и снижение избыточности в процессе формирования синтетического потока запросов.
Улучшение поиска: новые методы и перспективы
Набор данных ASQ (Answer Selection Query) играет ключевую роль в оценке эффективности современных методов информационного поиска, таких как BM25 и MonoElectra. Этот ресурс предоставляет стандартизированную платформу для сопоставления различных алгоритмов, позволяя исследователям количественно оценить их способность находить наиболее релевантные документы в ответ на заданные запросы. Благодаря ASQ, можно объективно сравнить производительность различных подходов, выявить их сильные и слабые стороны, а также внести вклад в разработку более совершенных систем поиска информации. Набор данных включает в себя реальные поисковые запросы и соответствующие им релевантные ответы, что обеспечивает реалистичную оценку эффективности алгоритмов в практических условиях.
Для повышения точности и полноты поиска информации применяются методы расширения запроса и семантического кэширования. Расширение запроса предполагает добавление к исходному запросу синонимов, связанных терминов или понятий, что позволяет системе охватить более широкий спектр релевантных документов. Семантическое кэширование, в свою очередь, сохраняет результаты обработки запросов, основанные на их смысловом содержании, что значительно сокращает время отклика и вычислительные затраты при повторных запросах, близких по значению. Сочетание этих подходов позволяет не только находить больше релевантной информации, но и улучшать пользовательский опыт за счет скорости и эффективности поиска.
В основе современных методов информационного поиска лежит принцип вероятностного ранжирования, согласно которому релевантные документы определяются на основе оценки вероятности их соответствия запросу. Исследования показывают, что более крупные языковые модели, такие как Qwen-7B, демонстрируют значительно более широкое исследование поискового пространства — количество обращений к поисковой системе увеличивается до +265% по сравнению с небольшими моделями. Это свидетельствует о способности больших моделей учитывать большее количество потенциально релевантных документов и, как следствие, повышать точность и полноту поиска, поскольку они не ограничиваются наиболее очевидными результатами и активно исследуют менее явные, но потенциально важные источники информации.
Исследования показали, что поисковые запросы, возникшие из одного и того же исходного вопроса, демонстрируют значительное сходство, оцениваемое с помощью коэффициента Жаккара в диапазоне от 35 до 83%. Это указывает на то, что пользователи, стремясь уточнить свою потребность в информации, часто формулируют несколько запросов, которые тесно связаны между собой по смыслу. Такая закономерность позволяет разрабатывать системы поиска, способные эффективно использовать взаимосвязанные запросы для улучшения точности и полноты выдаваемых результатов, а также оптимизировать процесс поиска информации для пользователя. Высокий уровень сходства между запросами открывает возможности для применения методов семантического кэширования и расширения запросов, направленных на повышение релевантности найденных документов.
Будущее RAG: адаптация, рассуждения и интеллект
Набор данных ASQ, в сочетании с методологиями агентного поиска, значительно расширяет возможности систем RAG (Retrieval-Augmented Generation). В отличие от традиционных методов, где поиск информации является пассивным процессом, агентный поиск позволяет системе активно формулировать запросы, оценивать релевантность полученных результатов и итеративно уточнять поисковые критерии. ASQ, представляя собой сложные вопросы, требующие синтеза информации из различных источников, служит идеальной платформой для тестирования и совершенствования подобных систем. Такой подход позволяет не просто извлекать информацию, но и рассуждать над ней, приближая возможности автоматизированных систем к человеческому пониманию и решению задач, что открывает новые перспективы в области обработки естественного языка и интеллектуального поиска.
Перспективные исследования в области систем извлечения информации с помощью генерации (RAG) сосредоточены на внедрении более сложных паттернов рассуждений и адаптивных стратегий поиска. Вместо простого сопоставления запроса с релевантными документами, будущие системы будут стремиться к моделированию более глубокого понимания контекста и намерений пользователя. Это предполагает разработку алгоритмов, способных к многошаговому рассуждению, выявлению скрытых связей между фрагментами информации и динамической корректировке стратегии поиска в зависимости от полученных результатов. Внедрение механизмов самообучения и reinforcement learning позволит системам RAG адаптироваться к изменяющимся потребностям пользователей и повышать точность и релевантность извлекаемой информации, приближаясь к уровню человеческого понимания и анализа.
Стремление к созданию поисковых систем, способных не просто находить информацию, а и осмысливать её подобно человеку, открывает новые горизонты в области извлечения знаний. Современные системы часто сталкиваются с трудностями при обработке сложных запросов, требующих не только фактических данных, но и логических умозаключений. Попытки имитировать человеческое мышление, включая способность к абстракции, аналогии и критическому анализу, позволяют создавать более адаптивные и эффективные инструменты поиска. Сочетание автоматизированного поиска с моделями, способными к сложному рассуждению, позволит не только предоставлять релевантные ответы, но и выявлять скрытые закономерности и предлагать новые решения, что значительно расширяет потенциал информационного поиска и делает его по-настоящему интеллектуальным.
Исследование, представленное в статье, закономерно выявляет расхождение в поведении поисковых агентов и людей. Как будто кто-то удивляется, что автоматизированная система не стремится к поэзии в запросах. Андрей Колмогоров однажды заметил: «Математика — это искусство не думать». Похоже, агенты просто воплощают этот принцип, безжалостно оптимизируя запросы до состояния, лишенного всякой человеческой прихоти. Идея о необходимости пересмотра базовых предположений информационного поиска (IR) выглядит не как научный прорыв, а как констатацию очевидного — элегантные теории разбиваются о суровую реальность продакшена. Созданный датасет ASQ — это, скорее, не инструмент для улучшения поиска, а подробный отчет о том, как машины учатся игнорировать красоту.
Что дальше?
Представленный набор данных, ASQ, конечно, зафиксировал некую картину поведения «агентов» при поиске. Однако, не стоит обольщаться, будто теперь все стало ясно. История информационного поиска богата на «революционные» наборы, которые через пару лет оказывались лишь слегка переупакованными версиями старых проблем. Разница в поведении агентов и людей, выявленная в работе, скорее указывает на необходимость переосмысления базовых предположений, чем на возможность окончательно «победить» поиск. Вполне вероятно, что в погоне за «агентным» интеллектом, мы просто изобретаем новые способы столкнуться со старыми ограничениями.
В дальнейшем, вместо того, чтобы фокусироваться на создании все более сложных «агентов», возможно, стоит потратить усилия на понимание, что именно делает человеческий поиск таким… неэффективным, но при этом рабочим. Если тесты показывают, что агент успешно справляется с задачами, это, вероятно, означает лишь, что задачи были слишком простыми. Или, что более вероятно, что данные для обучения были тщательно подобраны, чтобы скрыть реальные сложности.
В конечном итоге, вся эта история с «агентным» поиском — лишь очередной виток в бесконечном цикле оптимизации. Через несколько лет появятся новые архитектуры, новые метрики, новые наборы данных… и все это снова потребует переосмысления. Каждый «прорыв» неизбежно превратится в техдолг. И это, пожалуй, самое предсказуемое будущее.
Оригинал статьи: https://arxiv.org/pdf/2602.17518.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Временная запутанность: от хаоса к порядку
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Квантовое программирование: Карта развивающегося мира
- Предел возможностей: где большие языковые модели теряют разум?
- ЭКГ-анализ будущего: От данных к цифровым биомаркерам
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Сердце музыки: открытые модели для создания композиций
- Квантовый шум: за пределами стандартных моделей
- Квантовые кольца: новые горизонты спиновых токов
- Искусственный разум и квантовые данные: новый подход к синтезу табличных данных
2026-02-20 17:07