Автор: Денис Аветисян
Новое исследование показывает, что производительность больших языковых моделей резко падает при обработке длинных текстов, несмотря на теоретическую возможность работать с большими объемами информации.
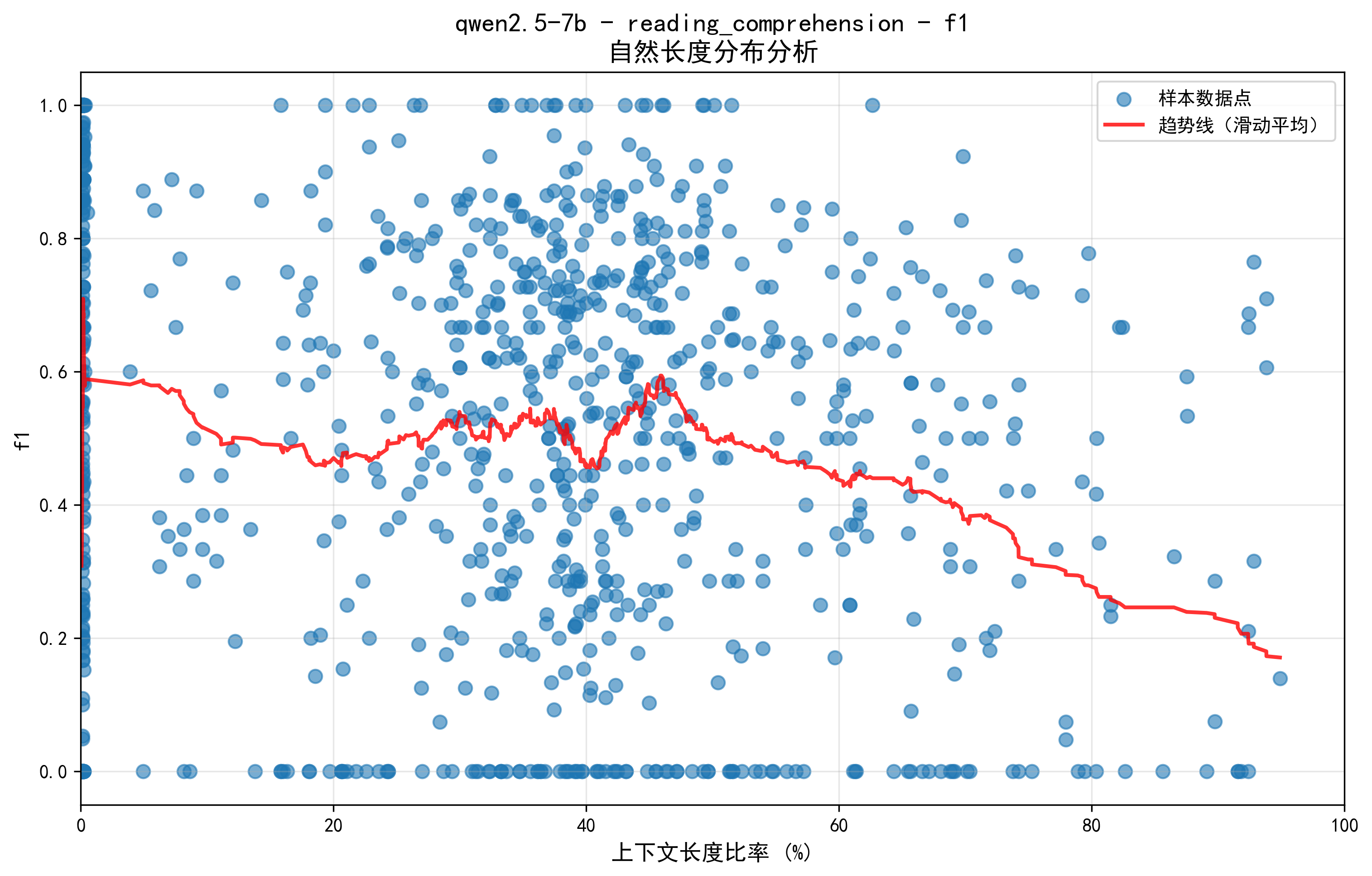
Определен критический порог длины контекста (40-50%), после которого наблюдается существенная деградация интеллекта модели Qwen2.5-7B, связанная с особенностями кодирования RoPE и механизмов внимания.
Несмотря на впечатляющие возможности современных больших языковых моделей (LLM), их производительность резко снижается при обработке длинных контекстов. В данной работе, ‘Intelligence Degradation in Long-Context LLMs: Critical Threshold Determination via Natural Length Distribution Analysis’, исследуется феномен деградации интеллекта, проявляющийся в катастрофическом падении качества обработки длинных последовательностей. Полученные результаты демонстрируют, что для модели Qwen2.5-7B критический порог, после которого наблюдается значительное снижение производительности (более 45%), находится в пределах 40-50% от максимальной длины контекста. Возможно ли разработать эффективные стратегии смягчения данной проблемы и расширить возможности LLM для работы с действительно длинными текстами?
Пределы Масштаба: Деградация Интеллекта в Больших Языковых Моделях
Несмотря на впечатляющие возможности больших языковых моделей (БЯМ), их эффективность не сохраняется равномерно при увеличении длины контекста. Изначально демонстрируя высокую точность и связность при обработке небольших объемов информации, БЯМ сталкиваются с существенными трудностями при анализе более длинных текстов. По мере роста объема входных данных, способность модели к удержанию релевантной информации и поддержанию логической последовательности постепенно снижается. Это связано с ограничениями архитектуры и алгоритмов обработки данных, что приводит к потере важных деталей и искажению смысла при работе с большими объемами текста. Таким образом, хотя БЯМ и способны генерировать убедительные и связные тексты, их надежность и точность снижаются по мере увеличения длины входного контекста, что указывает на фундаментальные ограничения в их способности к масштабированию.
Исследования выявили, что по мере увеличения объема входных данных, производительность больших языковых моделей (LLM) достигает критической точки, после которой наблюдается заметное ухудшение. Это не просто снижение точности, а фундаментальное ограничение в способности модели эффективно обрабатывать и сохранять информацию в масштабе. Существующие архитектуры, несмотря на впечатляющие успехи в краткосрочной памяти, демонстрируют неспособность поддерживать когерентность и точность при обработке длинных последовательностей текста. Данное явление указывает на потребность в новых подходах к архитектуре и механизмам внимания, способных преодолеть ограничения масштабируемости и обеспечить стабильную производительность LLM при работе с текстами любого объема.
Исследования показали, что способность больших языковых моделей (LLM) к поддержанию связности и точности ответов снижается при увеличении длины входного текста. Этот процесс ухудшения, количественно оцениваемый метрикой F1 Score, демонстрирует критический порог, после которого производительность резко падает. В частности, зафиксировано снижение F1 Score до уровня 0.3 после достижения этой границы, что свидетельствует о фундаментальных ограничениях в способности LLM эффективно обрабатывать и запоминать информацию в длинных последовательностях. Данное явление указывает на необходимость разработки новых архитектур и методов обучения, способных преодолеть эти ограничения и обеспечить надежную работу моделей с большими объемами текста.
Понимание Поверхностной Адаптации к Длинному Контексту
Наблюдаемое снижение производительности больших языковых моделей при работе с длинными последовательностями связано с явлением, получившим название “Поверхностная адаптация к длинному контексту” (Shallow Long-Context Adaptation). Это проявляется в неспособности модели эффективно использовать информацию, распределённую по всей длине входной последовательности, что приводит к ухудшению качества генерации или классификации. Суть проблемы заключается в том, что модель фокусируется преимущественно на ближайшем контексте, игнорируя или недооценивая вклад более удалённых частей последовательности, даже если они содержат важную информацию. Данное явление особенно выражено при увеличении длины контекста, когда сложность обработки информации экспоненциально возрастает, и модель не может эффективно масштабироваться для поддержания высокой точности и релевантности.
Эффективность передачи информации снижается по мере увеличения длины контекста, что приводит к возникновению «узкого места» для критически важных данных. Это связано с тем, что при обработке длинных последовательностей, модели теряют способность эффективно выделять и сохранять релевантную информацию, необходимую для точного прогнозирования или генерации. По сути, значительная часть входных данных становится неинформативной или зашумленной, что снижает способность модели к обобщению и приводит к ухудшению производительности на задачах, требующих анализа всей последовательности. Это явление особенно заметно при использовании архитектур, чувствительных к длинным зависимостям, где потеря информации в начале последовательности может существенно повлиять на результаты обработки всей последовательности.
Механизм внимания и позиционное кодирование RoPE, являясь ключевыми компонентами современных архитектур, вносят вклад в снижение эффективности работы с длинными контекстами. В частности, механизм внимания, распределяя «вес» между всеми токенами входной последовательности, приводит к размытию значимости информации на больших расстояниях. Позиционное кодирование RoPE, хотя и эффективно для коротких последовательностей, демонстрирует снижение точности представления позиций токенов при увеличении длины контекста, что затрудняет установление и поддержание зависимостей между удаленными элементами последовательности. В результате, модель испытывает сложности с извлечением релевантной информации из длинных контекстов, что негативно сказывается на качестве генерируемых ответов и точности выполнения задач.
Выявление Критической Границы: Многометодовый Подход
Определение “критической границы” — длины контекста, после превышения которой наблюдается резкое падение производительности модели — требует проведения тщательного анализа. Недостаточно точное определение этой границы может привести к неоптимальному использованию ресурсов и снижению качества результатов. В связи с этим, необходимо использовать количественные метрики для оценки производительности при различных длинах контекста, а также применять статистические методы для выявления точки перегиба, характеризующей критическую границу. Проведение анализа с использованием различных подходов и валидация полученных результатов — ключевые этапы обеспечения надежности и точности определения критической границы.
Для надежного определения критического порога, после которого наблюдается снижение производительности, используется методика мульти-методной кросс-валидации. Данный подход объединяет несколько аналитических техник, включая градиентный анализ, анализ второй производной и статистику по бинам (binned statistics). Градиентный анализ выявляет точки резкого изменения в производительности, анализ второй производной позволяет точно определить точки перегиба, а статистика по бинам обеспечивает оценку стабильности результатов на различных сегментах данных. Комбинирование этих методов позволяет минимизировать влияние отдельных погрешностей и повысить общую надежность определения критического порога.
Анализ показал, что стандартное отклонение в оценке критического порога составляет всего 1.2% при использовании пяти независимых методов. Данный показатель свидетельствует о высокой надежности и воспроизводимости полученных результатов, подтверждая устойчивость определения критической длины контекста, при превышении которой наблюдается снижение производительности. Использование нескольких независимых методик позволило минимизировать влияние погрешностей, характерных для отдельных подходов, и обеспечить статистически значимую уверенность в точности установленного порога.
Демонстрация Критического Порога на Модели Qwen2.5-7B
Применение разработанной методологии к языковой модели Qwen2.5-7B позволило выявить чёткий и количественно определяемый критический порог. Данный порог характеризует предел, за которым способность модели к обработке информации существенно снижается. Исследование показало, что превышение этого порога приводит к заметному ухудшению производительности, что подтверждает ограниченность текущих подходов к масштабированию языковых моделей и необходимость поиска новых методов для эффективной работы с длинными контекстами. Полученные результаты позволяют более точно оценивать возможности и ограничения LLM при решении задач, требующих глубокого понимания и обработки больших объемов текстовой информации.
Исследование модели Qwen2.5-7B выявило существенное снижение производительности при превышении определенного порога длины контекста. Наблюдается отчетливая тенденция: при достижении 40-50% от максимальной длины контекста, показатель F1 снижается на 45.5%, уменьшаясь с 0.55-0.56 до 0.3. Данный результат указывает на то, что простое увеличение масштаба модели не является эффективным способом улучшения её способности к обработке длинных последовательностей. Это подтверждает ограничения существующих подходов к масштабированию больших языковых моделей и подчеркивает необходимость разработки новых методов, способных эффективно использовать информацию из длинных контекстов для улучшения качества ответов и точности анализа.
Полученные результаты имеют непосредственное значение для практического применения больших языковых моделей в задачах, требующих обработки обширных объемов информации. В частности, при создании систем для автоматического реферирования документов или выполнения сложных логических умозаключений, необходимо учитывать выявленный порог эффективности. Превышение этого порога приводит к значительному снижению качества работы модели, что делает критически важным оптимизацию архитектуры и методов обработки длинных контекстов. Понимание этих ограничений позволит разработчикам создавать более надежные и эффективные приложения, использующие возможности больших языковых моделей в реальных сценариях, требующих глубокого понимания и анализа больших объемов текста.
Исследование демонстрирует, что производительность больших языковых моделей подвержена существенному ухудшению при превышении определенной длины контекста. Этот феномен, проявляющийся в виде резкого снижения качества обработки последовательностей, подчеркивает важность понимания пределов возможностей архитектур, таких как Qwen2.5-7B. Как отмечал Г.Х. Харди: «Математика — это искусство делать то, что можно, а не то, что трудно». В данном контексте, задача состоит не в увеличении длины контекста любой ценой, а в оптимизации архитектур и методов кодирования, таких как RoPE, для эффективной обработки информации в пределах разумных пределов. Подобный подход позволит создать системы, которые стареют достойно, сохраняя свою полезность и точность.
Куда же дальше?
Представленная работа, выявляя критический порог деградации интеллекта в больших языковых моделях, лишь подчеркивает закономерность старения любой системы. Обнаруженный “обрыв” в производительности при увеличении длины контекста — не ошибка реализации, а скорее фундаментальное ограничение, присущее архитектуре внимания. Временная аналитика подсказывает: любое улучшение, позволяющее обрабатывать более длинные последовательности, стареет быстрее, чем ожидалось. Вопрос не в достижении произвольной длины контекста, а в понимании, как долго модель способна поддерживать когерентность и релевантность.
Очевидным направлением дальнейших исследований представляется не столько увеличение длины контекста, сколько разработка механизмов, смягчающих эффект «отката» — путешествия назад по стрелке времени, когда информация, находящаяся за критическим порогом, становится недоступной. Интересно было бы исследовать, как различные методы кодирования, отличные от RoPE, влияют на стабильность внимания на больших дистанциях. И, возможно, самое важное — осознать, что идеальная модель, способная обрабатывать бесконечный контекст, — это, вероятно, лишь иллюзия.
В конечном счете, задача состоит не в создании всемогущего искусственного интеллекта, а в построении систем, которые достойно стареют — сохраняя свою полезность и релевантность даже при неизбежном ухудшении производительности. Это — признание энтропии как фундаментального закона, а не как препятствия на пути к прогрессу.
Оригинал статьи: https://arxiv.org/pdf/2601.15300.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-25 16:13