Автор: Денис Аветисян
Исследователи предлагают инновационную систему для оценки и прогнозирования производительности сложных нейросетей, основанную на сочетании статистического анализа и моделирования поведения.
В статье представлена STAR — методика, объединяющая статистическое моделирование и агентно-ориентированный подход для эффективной и прозрачной оценки больших языковых моделей на различных бенчмарках.
Оценка производительности крупных языковых моделей становится все более дорогостоящей, а существующие статистические методы часто оказываются неэффективными при изменении закономерностей и нехватке данных. В данной работе, посвященной разработке фреймворка ‘STAR : Bridging Statistical and Agentic Reasoning for Large Model Performance Prediction’, предлагается подход, объединяющий статистическое моделирование с рассуждениями на основе агентных систем. STAR использует специализированные извлекатели знаний и вероятностную факторную модель с ограничениями для генерации статистических оценок с учетом неопределенности, а затем уточняет прогнозы с помощью анализа и агрегации, основанных на теории нарушения ожиданий. Сможет ли предложенный подход обеспечить более точную и объяснимую оценку производительности больших языковых моделей в условиях ограниченных данных и сложных сценариев?
За пределами масштабирования: Ограничения современных бенчмарков для LLM
Современные методы оценки больших языковых моделей (LLM) часто опираются на закономерности масштабирования, предполагающие, что увеличение размера модели автоматически ведет к улучшению ее способностей. Однако, такой подход нередко упускает из виду тонкости рассуждений и критическое мышление. Исследования показывают, что модели, демонстрирующие впечатляющие результаты на стандартных бенчмарках благодаря увеличению объема данных и параметров, могут испытывать затруднения в решении задач, требующих не просто запоминания информации, а ее анализа, обобщения и применения в новых контекстах. Игнорирование этих нюансов приводит к завышенным оценкам реальной интеллектуальной мощи LLM и затрудняет разработку моделей, способных к истинному пониманию и решению сложных проблем. Поэтому, для более адекватной оценки необходим переход к методикам, фокусирующимся на качестве рассуждений, а не только на количестве параметров.
Традиционные бенчмарки, используемые для оценки больших языковых моделей, зачастую упрощают реальные задачи до уровня, не отражающего их истинную сложность. Это приводит к завышенным оценкам производительности, поскольку модели демонстрируют успех в решении искусственно упрощенных проблем, но испытывают трудности при столкновении с неструктурированными данными и многозначностью, характерными для реального мира. Например, ответы на вопросы, требующие понимания контекста и здравого смысла, могут быть успешно сгенерированы в рамках строго определенных наборов данных, но оказаться неадекватными при обработке информации, полученной из разнообразных источников. Подобная несоответствие между лабораторными показателями и реальной производительностью ставит под сомнение надежность существующих систем оценки и подчеркивает необходимость разработки более сложных и реалистичных бенчмарков, способных точно отражать возможности и ограничения современных языковых моделей.
В связи с ограничениями существующих методов оценки больших языковых моделей (LLM), возникает настоятельная потребность в более надежном и статистически обоснованном подходе к их анализу. Традиционные бенчмарки зачастую не способны адекватно отразить сложность реальных задач, что приводит к завышенным оценкам производительности. Необходимо разработать методики, которые позволят более точно измерять не только способность модели к запоминанию и воспроизведению информации, но и ее умение к логическому мышлению, решению проблем и адаптации к новым условиям. Это требует использования более строгих статистических методов, включающих более крупные и разнообразные наборы данных, а также более точные метрики для оценки качества ответов. Усилия в этом направлении направлены на создание системы оценки, которая будет отражать истинный потенциал LLM и способствовать их дальнейшему развитию.
Современные подходы к обучению больших языковых моделей, такие как использование архитектуры Mixture-of-Experts (MoE) и обучение с подкреплением на основе обратной связи от человека (RLHF), привносят значительные сложности в процесс их оценки. MoE, задействуя различные «эксперты» для обработки разных типов данных, создает неравномерную нагрузку и затрудняет сопоставление результатов, поскольку производительность сильно зависит от выбора эксперта. RLHF, в свою очередь, полагается на субъективные оценки людей, что вносит шум и смещения, делая результаты менее воспроизводимыми и усложняя статистически обоснованное сравнение моделей. Такая сложность не позволяет адекватно оценить истинные возможности языковых моделей и требует разработки новых, более надежных методов оценки, учитывающих эти факторы.

STAR: Статистический и Рассуждающий Фреймворк для Оценки LLM
В основе STAR лежит метод Constrained Probabilistic Matrix Factorization (CPMF), используемый для создания компактного, низкоразмерного представления возможностей больших языковых моделей (LLM). CPMF позволяет снизить вычислительную сложность при анализе и сравнении различных LLM, представляя их способности в виде векторов в пространстве меньшей размерности. Это достигается путем разложения матрицы, отражающей производительность LLM в различных задачах, на компоненты, учитывающие как статистические зависимости между задачами, так и ограничения, накладываемые на структуру этих зависимостей. CPMF = argmin_{U,V} ||X - UV^T||^2 + \lambda ||U||^2 + \lambda ||V||^2, где X — матрица производительности, U и V — матрицы факторов, а λ — параметр регуляризации. Полученное низкоразмерное представление позволяет эффективно оценивать и сопоставлять LLM по их функциональным возможностям.
Основой статистического подхода STAR является Constrained Probabilistic Matrix Factorization (CPMF), использующая зависимости от методов Principal Component Analysis (PCA), Probabilistic Matrix Factorization (PMF) и Neural Collaborative Filtering (NCF) для надёжной экстракции возможностей. CPMF интегрирует PCA для уменьшения размерности данных и выявления основных компонентов, PMF для моделирования латентных факторов, определяющих связи между данными, и NCF для повышения точности прогнозирования путём использования нейронных сетей. Комбинация этих методов позволяет CPMF эффективно извлекать и представлять возможности больших языковых моделей (LLM) в низкоразмерном пространстве, обеспечивая устойчивость к шумам и неполноте данных. CPMF = f(PCA, PMF, NCF)
В рамках STAR, Теория Нарушения Ожиданий (EVT) используется для уточнения статистических ожиданий на основе достоверности получаемых доказательств. EVT позволяет оценивать отклонения наблюдаемых данных от априорных предположений о вероятностях, формируя таким образом взвешенные оценки. Это достигается путем анализа степени несоответствия между ожидаемыми и фактическими результатами, что позволяет системе корректировать свои внутренние модели и повышать точность прогнозов. Более высокая степень нарушения ожидания указывает на более высокую значимость доказательства и, соответственно, на больший вес, придаваемый ему при оценке достоверности и формировании окончательного вывода. EVT = \sum_{i=1}^{n} w_i \cdot d_i, где w_i — вес доказательства, а d_i — величина нарушения ожидания.
Агентное рассуждение в STAR использует большую языковую модель GPT-5.1 и семантическую извлечение признаков с помощью BGE-M3 для оценки достоверности информации, полученной посредством поиска и дополнения (Retrieval Augmentation). Процесс включает в себя анализ извлеченных данных на предмет согласованности, релевантности и соответствия установленным критериям достоверности. BGE-M3 позволяет выделить семантические признаки из текста, которые используются GPT-5.1 для определения вероятности истинности утверждений и выявления потенциальных противоречий или неточностей в собранных данных. Оценка достоверности является ключевым этапом для фильтрации недостоверной информации и обеспечения надежности результатов, полученных в рамках STAR.

Подтверждение Эффективности STAR: Статистические Основы и Интеграция Рассуждений
Компонент CPMF (Contextual Parameter Mixture Filtering) в STAR использует продвинутые методы Монте-Карло Марковских цепей (MCMC) для точной оценки параметров. В частности, применяется алгоритм No-U-Turn Sampler (NUTS), который является адаптивным методом MCMC, эффективно исследующим пространство параметров и избегающим проблем, связанных с традиционными методами, таких как необходимость ручной настройки шага и проблемы с низкой эффективностью в сложных многомерных пространствах. NUTS автоматически настраивает шаг и длину шага, что обеспечивает более надежную и эффективную оценку параметров модели, критически важную для точного прогнозирования возможностей больших языковых моделей (LLM).
Механизм Retrieval Augmentation в STAR использует внешние источники знаний, а именно платформы HuggingFace и arXiv, для расширения базы доказательств при оценке больших языковых моделей (LLM). HuggingFace предоставляет доступ к разнообразным наборам данных и предварительно обученным моделям, в то время как arXiv содержит научные препринты и статьи. Интеграция этих ресурсов позволяет STAR получать актуальную и проверенную информацию, необходимую для более точной и надежной оценки возможностей LLM, особенно в ситуациях, когда внутренние знания модели недостаточны или устарели. Такой подход повышает объективность оценок и снижает зависимость от предвзятости, свойственной исключительно внутренним данным модели.
Механизм рассуждений, интегрированный в STAR, обеспечивает оценку релевантности и достоверности извлеченной информации из внешних источников, таких как HuggingFace и arXiv. Этот процесс критически важен для снижения предвзятости при оценке возможностей больших языковых моделей (LLM). Оценка релевантности позволяет отфильтровать не относящиеся к задаче данные, а оценка достоверности — выявить и исключить потенциально ошибочные или необъективные источники, тем самым повышая надежность и точность общей оценки LLM.
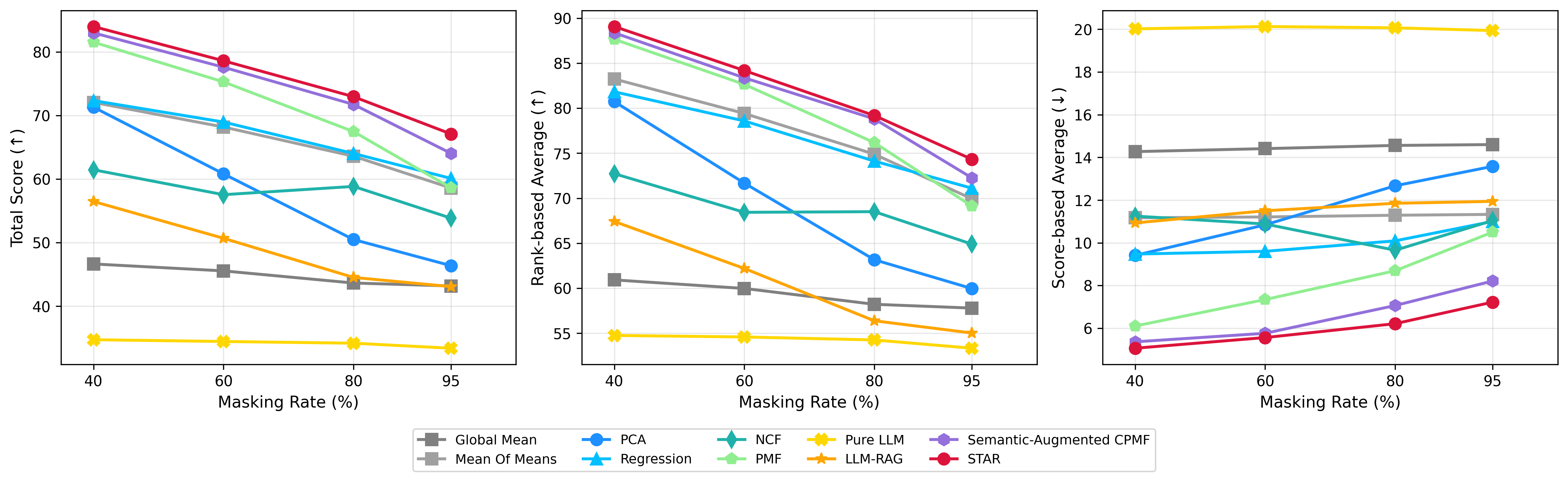
В ходе тестирования STAR продемонстрировал прирост общей оценки на 14.46% при маскировке 95% входных данных, что указывает на устойчивость к неполноте информации. Более существенное улучшение, достигающее 43.66%, было зафиксировано при смещении тестов относительно стандартных бенчмарков, подтверждая способность STAR точно оценивать возможности больших языковых моделей (LLM) в условиях изменения тестовых данных и задач. Данные результаты демонстрируют эффективность STAR в прогнозировании производительности LLM в различных сценариях, включая ситуации с ограниченными данными и смещением в задачах.

Преодолевая Простое Предсказание: Значение и Перспективы Развития
В отличие от традиционных оценок языковых моделей, часто основанных на отдельных показателях, STAR предлагает статистически обоснованный подход к их анализу. Эта методика позволяет избежать чрезмерной зависимости от потенциально вводящих в заблуждение результатов бенчмарков, которые могут не отражать реальную производительность модели в различных сценариях. STAR оценивает модели, анализируя не только что они отвечают, но и почему они приходят к тем или иным выводам, что позволяет более точно выявить их сильные и слабые стороны. Такой подход особенно важен, поскольку позволяет отделить истинные улучшения в возможностях модели от простого увеличения масштаба, обеспечивая более надежную и объективную оценку.
Предлагаемый фреймворк не просто оценивает производительность больших языковых моделей (LLM), но и позволяет выявить причины, лежащие в основе их успеха или неудач. Этот подход выходит за рамки простой констатации факта, предоставляя разработчикам ценную информацию для целенаправленного улучшения моделей. Анализируя, какие конкретно аспекты знаний или рассуждений определяют результат, можно сосредоточиться на устранении слабых мест и усилении сильных сторон. Вместо слепого увеличения масштаба модели, разработчики получают возможность оптимизировать её архитектуру и обучающие данные, добиваясь более эффективного использования ресурсов и повышения общей производительности. Такое детальное анализирование способствует созданию LLM, которые не только демонстрируют высокие показатели, но и обладают более глубоким пониманием и способностью к решению сложных задач.
Разделяя способность модели от ее размера, STAR позволяет получить более глубокое понимание сильных и слабых сторон больших языковых моделей. Традиционно, оценка LLM часто сводится к корреляции с количеством параметров — чем больше модель, тем лучше она справляется с задачами. Однако, STAR демонстрирует, что это не всегда так. Анализируя причины успешного или неуспешного выполнения задач, а не просто констатируя факт результата, STAR выявляет, какие конкретно аспекты знаний и рассуждений определяют производительность модели. Это позволяет разработчикам сосредоточиться на улучшении именно этих аспектов, а не просто на увеличении масштаба модели, что может привести к более эффективному использованию ресурсов и созданию более специализированных и эффективных LLM.
Предложенная методика STAR демонстрирует высокую эффективность в выявлении наиболее производительных языковых моделей при минимальных затратах. Достигнутый показатель Top-10 Recall в 0.82 указывает на то, что система способна с высокой точностью идентифицировать модели, входящие в десятку лучших, при этом стоимость оценки составляет всего 3.5%. Такая экономичность делает STAR привлекательным инструментом для широкого спектра приложений, где необходима быстрая и достоверная оценка качества больших языковых моделей, позволяя оптимизировать ресурсы и сосредоточиться на наиболее перспективных решениях.
Исследование представляет STAR — систему, стремящуюся предсказать производительность больших языковых моделей. Подход интересен тем, что сочетает в себе статистическое моделирование и агентный подход. Это напоминает о том, как часто в разработке мы пытаемся найти баланс между теоретической элегантностью и практической реализацией. Как говорил Дональд Кнут: «Преждевременная оптимизация — корень всех зол». STAR, по сути, пытается найти оптимальный способ оценки, избегая излишней сложности и фокусируясь на предсказании реальной производительности, а не на создании идеальной, но бесполезной модели. Игнорирование эмпирических данных в пользу красивой теории — распространённая ошибка, которую STAR стремится преодолеть.
Что дальше?
Предложенный STAR, как и большинство «прорывных» методик, не решает проблему предсказания производительности больших языковых моделей, а лишь усложняет её. Статистическое моделирование и агентные системы, объединённые вместе, создают иллюзию понимания, но рано или поздно найдётся бенчмарк, на котором всё это беспомощно рухнет. В конце концов, производительность — это всегда результат случайных блужданий в пространстве параметров, а не логичное следствие «объяснимости».
Более того, акцент на «объяснимости» представляется особенно наивным. В эпоху, когда модели сами генерируют объяснения, верить в их достоверность — примерно то же самое, что доверять рекламному проспекту. Вместо того чтобы тратить усилия на попытки понять «чёрный ящик», возможно, стоит смириться с его непрозрачностью и научиться эффективно использовать его выходные данные, даже если не понимаешь, как они появились.
Вполне вероятно, что через несколько лет STAR окажется очередным элементом техдолга, забытым в недрах репозиториев. И это неплохо. Иногда лучше иметь одну простую, но надёжную метрику, чем сотню сложных, каждая из которых врёт по-своему. Пока же, пусть себе предсказывает. В конце концов, даже сломанные часы дважды в день показывают правильное время.
Оригинал статьи: https://arxiv.org/pdf/2602.12143.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Текстуры вместо Гауссиан: Новый подход к синтезу видов
- Разумные языковые модели: новый подход к логическому мышлению
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Новая формула для расчёта взаимодействий глюонов открывает горизонты для голографии пространства
- Взрыв скорости: Оптимизация внимания для современных GPU
- Искусственный интеллект в действии: как расширяется сфера возможностей?
- Искусственный интеллект на страже экологии: защита данных и справедливые алгоритмы
- Ожившие Пиксели: Создание Реалистичных Видео с Сохранением Личности
- Сборка RAG: Архитектура и доверие в системах генерации с поиском
- Гендерные стереотипы в найме: что скрывают языковые модели?
2026-02-14 04:27