Автор: Денис Аветисян
Исследователи предлагают инновационный подход к прогнозированию оптического потока, открывающий возможности для более точного управления роботами и создания реалистичных видеороликов.
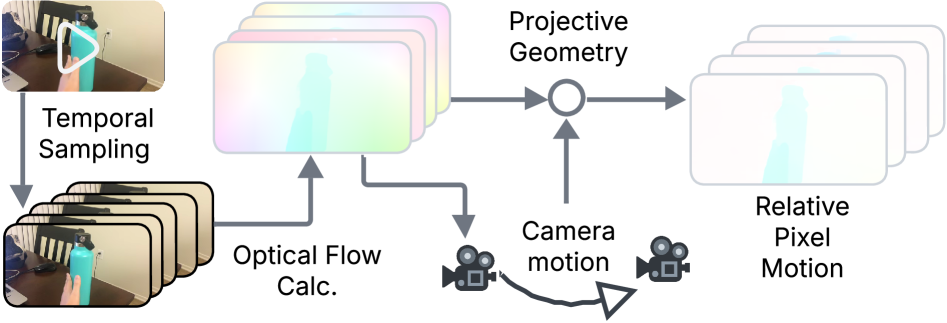
Представлен FOFPred — фреймворк, объединяющий языковые модели и диффузионные модели для точного прогнозирования будущего оптического потока.
Прогнозирование движения, особенно в сложных, реальных условиях, остается сложной задачей для робототехники и компьютерного зрения. В статье ‘Future Optical Flow Prediction Improves Robot Control & Video Generation’ представлена новая модель FOFPred, объединяющая возможности Vision-Language Models и Diffusion Models для точного прогнозирования оптического потока. Данный подход позволяет достичь высокой генеративной точности и мультимодального рассуждения, что существенно улучшает управление роботами и генерацию видео по текстовым запросам. Насколько масштабируемое обучение на больших, неструктурированных веб-данных может расширить возможности прогнозирования движения и открыть новые горизонты для интеллектуальных систем?
Постижение Движения: Вызовы Оптического Потока
Точное представление движения является фундаментальной задачей компьютерного зрения, однако традиционные методы, такие как Lucas-Kanade и RAFT Optical Flow, сталкиваются с серьезными трудностями в сложных сценах и при наличии перекрытий объектов. Эти алгоритмы, хоть и эффективны в простых ситуациях, часто демонстрируют неустойчивость при обработке видеопотоков с быстрыми изменениями, значительными окклюзиями или нелинейными деформациями. Проблема заключается в том, что они полагаются на локальные предположения о постоянстве яркости и плавности движения, которые не всегда выполняются в реальных условиях. Неспособность адекватно обрабатывать такие случаи приводит к появлению артефактов, неточностям в оценке скорости и, как следствие, к снижению качества работы систем компьютерного зрения, использующих эти методы для анализа и интерпретации видеоданных.
Существующие алгоритмы оптического потока, такие как Lucas-Kanade и RAFT, демонстрируют ограниченную способность к обобщению и адаптации к ранее не встречавшимся движениям. В динамичных средах, где сцена постоянно меняется, эти алгоритмы часто терпят неудачу, выдавая неточные или неполные результаты. Проблема заключается в том, что они, как правило, обучаются на ограниченном наборе данных движений, что не позволяет им эффективно обрабатывать новые, неожиданные паттерны. Это существенно ограничивает их применение в задачах, требующих надежного анализа видео, например, в автономных транспортных средствах или системах видеонаблюдения, где предсказание поведения объектов и понимание сложных сцен имеет решающее значение. Неспособность к обобщению становится критическим препятствием для создания действительно интеллектуальных систем компьютерного зрения.
Для реализации передовых возможностей анализа и генерации видео необходима надежная и адаптируемая система представления движения. Современные алгоритмы, несмотря на значительный прогресс, часто испытывают трудности при обработке сложных сцен, частичных перекрытий объектов и непредсказуемых изменений в динамике. Разработка принципиально нового подхода к кодированию движения позволит не только точнее интерпретировать визуальную информацию, но и создавать реалистичные видео, а также успешно решать задачи, связанные с автономной навигацией, робототехникой и виртуальной реальностью. Такая система должна быть способна обобщать информацию о движении, эффективно работать с различными типами сцен и обеспечивать стабильную производительность даже в условиях ограниченных вычислительных ресурсов.

Предвидение Будущего: Прогнозирование Оптического Потока и FOFPred
Прогнозирование будущего оптического потока решает проблему статического анализа движения, ограничивающего понимание динамических сцен. Традиционные методы оценивают движение на основе текущего кадра, что не позволяет предвидеть дальнейшую траекторию объектов. В отличие от них, прогнозирование оптического потока направлено на предсказание изменений в движении во времени, то есть, на вычисление вектора скорости каждой точки изображения в будущем. Это достигается путем анализа последовательности кадров и экстраполяции текущих тенденций движения, что позволяет предвидеть будущие позиции и траектории объектов в сцене. Такой подход критически важен для задач, требующих проактивного понимания сцены и планирования действий, например, в автономном вождении и робототехнике.
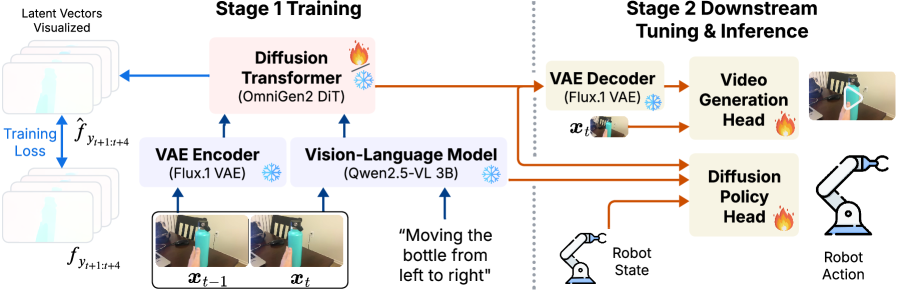
FOFPred представляет собой унифицированную модель, объединяющую возможности компьютерного зрения, обработки естественного языка и диффузионных моделей для точного и когерентного прогнозирования движения. В основе работы модели лежит использование диффузионных моделей — генеративных моделей, которые обучаются постепенно добавлять шум к данным, а затем восстанавливать их из шума. Этот подход позволяет FOFPred генерировать правдоподобные и плавные траектории движения, избегая резких или нереалистичных изменений. В отличие от традиционных методов, FOFPred не просто экстраполирует текущее движение, а генерирует вероятностные распределения возможных будущих состояний, обеспечивая более надежное и детализированное прогнозирование.
Модель FOFPred обеспечивает контролируемое и контекстно-зависимое предсказание движения благодаря интеграции визуальных данных и языковых инструкций. Визуальные признаки, полученные из анализа сцены, комбинируются с текстовыми запросами, определяющими желаемое поведение или ограничения на движение. Это позволяет не просто предсказывать наиболее вероятное развитие событий, но и формировать траектории движения в соответствии с заданными условиями. Например, можно указать, что объект должен двигаться к определенной цели, избегая препятствий, или соблюдать определенную скорость. Такой подход существенно расширяет возможности применения в задачах, требующих планирования действий и взаимодействия с динамической средой.
Ключевым нововведением является прогнозирование оптического потока до его возникновения. Традиционные методы анализа движения оперируют с существующим потоком, в то время как FOFPred позволяет предсказывать направление и скорость движения объектов в сцене на основе визуальной информации и языковых инструкций. Это обеспечивает возможность проактивного понимания сцены, предвидения возможных действий и планирования соответствующих реакций. Предсказание оптического потока позволяет системе не просто регистрировать движение, но и предсказывать его развитие, что критически важно для приложений, требующих упреждающих действий, таких как автономная навигация и робототехника.
От Предсказания к Генерации: Синтез Видео с Диффузией
Предсказанный оптический поток, генерируемый FOFPred, является ключевым входным сигналом для создания реалистичных видеопоследовательностей. Оптический поток определяет векторное поле движения пикселей между кадрами, предоставляя информацию о направлении и величине движения объектов в сцене. Использование этого предсказанного движения позволяет моделям синтеза видео, таким как диффузионные модели, генерировать новые кадры, согласованные с динамикой, определённой оптическим потоком, что значительно повышает реалистичность и визуальную связность результирующего видео. Точность и качество предсказанного оптического потока напрямую влияют на правдоподобие генерируемого видеоряда.
Диффузионные модели, в особенности разработанные для синтеза видео, предоставляют эффективный механизм для генерации высококачественного видеоконтента на основе предсказанных движений. В основе этих моделей лежит процесс постепенного добавления шума к обучающим данным, а затем обучения нейронной сети для обратного процесса — удаления шума и восстановления исходного видео. В контексте синтеза видео, предсказанное движение служит направлением для процесса диффузии, позволяя модели создавать реалистичные последовательности кадров. Эффективность видео-диффузионных моделей обеспечивается их способностью моделировать сложные распределения данных и генерировать детализированные и когерентные видеофрагменты, превосходящие по качеству результаты, полученные с использованием других генеративных моделей.
Архитектура VLM-Diffusion обеспечивает управляемое создание видео на основе языковых запросов и визуального контекста. Данный подход объединяет возможности визуальных языковых моделей (VLM) для интерпретации текстовых инструкций и визуальных подсказок с диффузионными моделями, которые генерируют видеокадры. VLM извлекает семантическую информацию из входных данных, формируя условия для процесса диффузии. В результате, диффузионная модель синтезирует видео, соответствующее заданным текстовым описаниям и визуальному контексту, позволяя осуществлять точный контроль над содержанием и стилем генерируемого видеоряда.
Модель Go-with-the-Flow (GWTF) представляет собой пример синтеза видео на основе заданного движения. GWTF использует предсказанные поля оптического потока в качестве входных данных для генерации последовательности кадров, обеспечивая когерентность и реалистичность движения в итоговом видео. В отличие от традиционных подходов, GWTF напрямую преобразует векторы движения, полученные из входного запроса, в визуальные изменения между кадрами, что позволяет создавать видеоролики, точно соответствующие заданному динамическому поведению. Данный подход демонстрирует возможность управления генерацией видео не только через визуальный контекст, но и через явное указание желаемого движения.

Робототехника и Управление: Движение как Язык для Роботов
Система FOFPred обеспечивает интуитивное управление робототехническими комплексами посредством перевода лингвистических инструкций в предсказуемые траектории движения. Этот подход позволяет роботу понимать не просто отдельные команды, а общую цель, выраженную естественным языком, и самостоятельно планировать последовательность действий для её достижения. Вместо прямой передачи команд управления, FOFPred предсказывает вероятное движение, соответствующее заданной инструкции, что значительно упрощает взаимодействие человека с роботом и расширяет спектр решаемых задач. Благодаря этому, робот способен выполнять сложные манипуляции и адаптироваться к меняющимся условиям окружающей среды, действуя более автономно и эффективно.
Политика диффузии использует предсказанные траектории движения как основу для управления действиями робота, позволяя ему выполнять сложные маневры и взаимодействовать с окружающей средой. Вместо программирования каждого шага, система оперирует вероятностными прогнозами будущего движения, что обеспечивает адаптивность и устойчивость к неопределенностям. Этот подход позволяет роботу не просто следовать заданным командам, но и предвидеть последствия своих действий, оптимизируя траекторию для достижения цели. В результате, робот способен выполнять задачи, требующие не только точности, но и способности к импровизации, что открывает новые возможности для его применения в динамичных и непредсказуемых условиях, например, в задачах манипулирования объектами или навигации в сложных средах.
Для обеспечения надежной работы робототехнических систем в динамически изменяющихся условиях активно применяются методы компенсации движения камеры, в частности, оценивание гомографии. Данный подход позволяет учитывать смещения и повороты камеры, вызванные внешними факторами или движением самого робота, и корректировать траекторию движения манипулятора. Оценивание гомографии, определяющее преобразование между двумя изображениями одного и того же объекта, позволяет точно определить взаимное положение и ориентацию камеры и окружающей среды, что критически важно для успешного выполнения задач в реальном времени. Благодаря этому, робот способен адаптироваться к изменяющимся условиям, избегать препятствий и выполнять сложные манипуляции даже в сложных и динамичных сценах, повышая общую эффективность и надежность системы.
Предлагаемый подход преобразует последовательности движений в понятный для робота язык, открывая возможности для более естественного и эффективного взаимодействия человека и машины. Вместо сложных команд, робот интерпретирует намерения, выраженные через движения, что позволяет ему выполнять задачи, требующие адаптивности и понимания контекста. Такая система позволяет роботу не просто следовать заданным инструкциям, но и предвидеть необходимые действия, основываясь на наблюдаемой динамике. В результате достигается более интуитивное управление, упрощающее процесс обучения и позволяющее человеку взаимодействовать с роботом, как с партнером, а не с инструментом, что особенно важно в сложных и динамичных средах.
В рамках CALVIN benchmark, система FOFPred продемонстрировала передовые результаты в решении задачи 5, достигнув средней вероятности успешного выполнения в 0.787. Это значительно превосходит показатели других существующих методов и подтверждает эффективность предложенного подхода к прогнозированию движений. Более того, FOFPred характеризуется большей длиной траектории — в среднем 4.39, что свидетельствует о способности системы планировать более сложные и развернутые действия, в отличие от моделей, основанных на разреженных траекториях, где средняя длина составляет всего 2.92. Такое улучшение указывает на потенциал FOFPred для управления роботами в более реалистичных и требующих детального планирования сценариях.
Исследования показали, что разработанная система FOFPred демонстрирует значительный прогресс в области управления роботами, достигая средней успешности в 68.6% при тестировании на платформе RoboTwin. Этот показатель существенно превосходит результаты, полученные с использованием базовых моделей управления, что подтверждает эффективность предложенного подхода к прогнозированию и управлению движениями роботов. Такой уровень успешности указывает на перспективность использования FOFPred для решения сложных задач, требующих точного и адаптивного управления, и открывает новые возможности для взаимодействия человека и робота в различных сферах применения.
Представленная работа демонстрирует изящную гармонию между пониманием визуальных данных и генерацией последовательных движений. Разработчики FOFPred создали систему, предсказывающую оптический поток, что позволяет не только улучшить управление роботами на основе языка, но и создавать более реалистичные видео. Как однажды заметил Джеффри Хинтон: «Я думаю, что нейронные сети — это просто способ представить сложные функции». Эта простая, но глубокая мысль находит отражение в FOFPred, где сложные закономерности движения извлекаются и моделируются с помощью нейронных сетей, позволяя системе предвидеть будущие изменения в визуальной сцене и реагировать на них, создавая ощущение плавности и естественности.
Куда Ведет Этот Поток?
Представленная работа, несомненно, элегантна в своей простоте — соединение языковых моделей и диффузионных сетей для предсказания оптического потока. Однако, за внешней гармонией скрывается неизбежная сложность реального мира. Точность предсказания, пусть и улучшенная, остается хрупкой перед лицом непредсказуемости динамических сцен. Устойчивость к шуму, вариациям освещения и, что особенно важно, к нетипичному поведению объектов — это области, требующие дальнейшей, кропотливой работы. Необходимо признать, что предсказание будущего, даже в виде оптического потока, всегда будет лишь приближением, а не абсолютной истиной.
Перспективным направлением представляется отказ от универсальных моделей в пользу специализированных, адаптированных к конкретным задачам и доменам. Представьте себе систему, которая «понимает» не только движение, но и намерения, контекст, и даже — осмелимся сказать — эстетику сцены. Такой подход потребует интеграции знаний из различных областей — от психологии и социологии до физики и компьютерного зрения. И тогда, возможно, предсказанный оптический поток перестанет быть просто набором векторов, а станет отражением более глубокого понимания окружающего мира.
В конечном счете, истинная ценность подобных исследований заключается не в достижении абсолютной точности, а в создании систем, которые способны к адаптации, обучению и, главное, к признанию собственной неполноты. Ведь даже самая совершенная модель — это лишь проекция нашего собственного, ограниченного понимания реальности.
Оригинал статьи: https://arxiv.org/pdf/2601.10781.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
2026-01-19 22:24