Автор: Денис Аветисян
Представлен Text2GQL-Bench — комплексный набор данных и фреймворк для оценки способности моделей понимать естественный язык и генерировать корректные запросы к графовым базам данных.
Text2GQL-Bench: эталонный набор данных для оценки систем преобразования текста в язык запросов к графам.
Несмотря на растущую важность графовых моделей для анализа данных, эффективное преобразование естественного языка в исполняемые запросы к графовым базам данных остается сложной задачей. В данной работе представлен ‘Text2GQL-Bench: A Text to Graph Query Language Benchmark [Experiment, Analysis & Benchmark]’ — комплексный набор данных и методика оценки, призванные стимулировать прогресс в области систем Text-to-GQL. Мы демонстрируем, что существующие ограничения в покрытии предметных областей и поддержке различных языков запросов препятствуют объективному сравнению моделей, и предлагаем решение, включающее 178,184 пары (Вопрос, Запрос) по 13 доменам. Сможем ли мы, с помощью стандартизированных бенчмарков, преодолеть языковой барьер и раскрыть весь потенциал больших языковых моделей для интеллектуального анализа графовых данных?
От Реляционных Ограничений к Графовым Возможностям
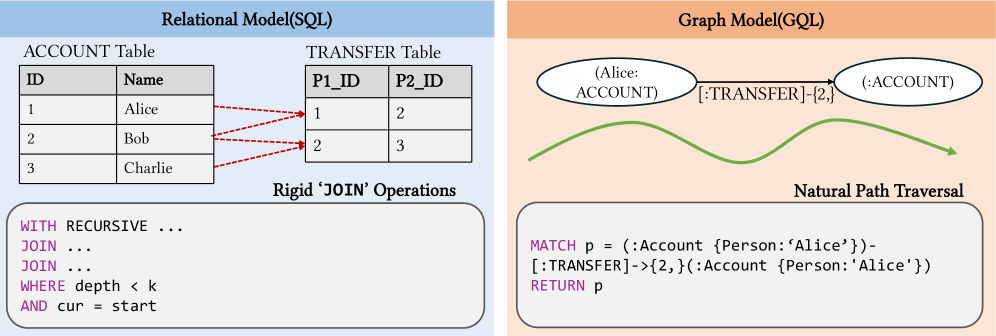
Традиционные реляционные базы данных и язык SQL, долгое время являвшиеся основой хранения и обработки информации, всё чаще сталкиваются с трудностями при работе со сложными, взаимосвязанными данными. Ограничения возникают из-за самой структуры реляционных моделей, где данные разбиваются на отдельные таблицы, а связи между ними устанавливаются через внешние ключи. По мере увеличения объёма данных и сложности взаимосвязей, запросы к таким базам данных становятся всё более ресурсоёмкими и медленными, что существенно затрудняет проведение углублённого анализа и получение ценных инсайтов. Особенно остро эта проблема проявляется в областях, где ключевое значение имеют не сами данные, а отношения между ними, таких как социальные сети, анализ сетевых взаимодействий или исследования в области биоинформатики. В результате, возможности для продвинутой аналитики, включая обнаружение скрытых закономерностей и прогнозирование, оказываются существенно ограничены.
В современных условиях, когда объемы данных растут экспоненциально, а потребность в понимании взаимосвязей между ними становится критически важной, традиционные методы управления данными оказываются недостаточными. Возникает необходимость в переходе к графовым базам данных, способным эффективно моделировать и анализировать сложные связи. В отличие от реляционных баз данных, где информация хранится в таблицах, графовые базы данных представляют данные в виде узлов и ребер, что позволяет быстро и точно выявлять паттерны и зависимости, которые остаются скрытыми при использовании традиционных подходов. Такой переход открывает новые возможности для анализа данных в различных областях, включая социальные сети, рекомендации, обнаружение мошенничества и многое другое, позволяя извлекать ценные знания из сложных информационных ландшафтов.
Традиционные методы поиска информации, такие как простой ввод ключевых слов, оказываются неэффективными при работе со сложными взаимосвязями в современных базах данных. Эти методы оперируют преимущественно с отдельными записями, не учитывая контекст и связи между ними. В результате, даже при наличии релянтных данных, пользователю сложно получить целостную картину и выявить скрытые закономерности. Простые запросы не способны «пройтись» по графу взаимосвязей, обнаруживая косвенные связи и паттерны, которые могут быть критически важны для принятия обоснованных решений. Это приводит к упущенным возможностям и неполному пониманию данных, особенно в областях, где взаимосвязанность информации является ключевым фактором, например, в социальных сетях, анализе рисков или разработке персонализированных рекомендаций.
От Естественного Языка к Графовым Запросам: Новый Подход
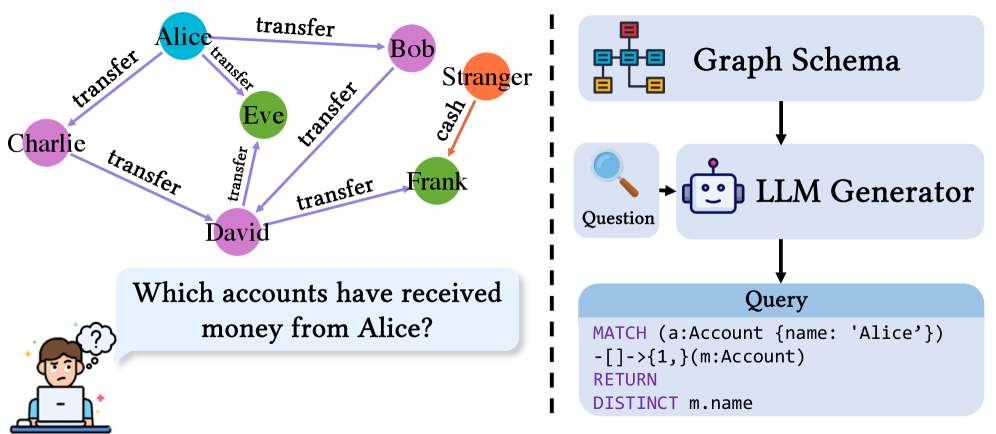
Технология Text-to-GQL направлена на создание интерфейсов, позволяющих пользователям получать доступ к данным в графовых базах данных посредством запросов, сформулированных на естественном языке. Цель разработки заключается в устранении необходимости знания языка запросов, такого как GraphQL или Cypher, и предоставлении возможности формулировать запросы в привычной для человека форме. Это достигается путем автоматического преобразования текстового запроса в соответствующий запрос к графовой базе данных, что существенно упрощает процесс получения информации и делает данные более доступными для широкого круга пользователей, не обладающих специализированными навыками работы с базами данных.
Эффективная трансляция естественного языка в запросы к графовым базам данных требует надежной привязки схемы (schema linking), представляющей собой процесс сопоставления концепций, выраженных в тексте, с конкретными элементами схемы базы данных — узлами, ребрами и свойствами. Этот процесс включает в себя идентификацию сущностей в тексте и их однозначное сопоставление с соответствующими узлами в графе, а также определение отношений между этими сущностями и их соответствия ребрам графа. Точность привязки схемы критически важна, поскольку ошибки в сопоставлении концепций и элементов схемы приводят к некорректным запросам и неверным результатам. Реализация надежной привязки схемы часто включает использование методов обработки естественного языка, таких как распознавание именованных сущностей (NER) и разрешение сущностей (entity resolution), а также применение онтологий и словарей для улучшения точности сопоставления.
Задача преобразования естественного языка в запросы к графовым базам данных сопряжена со значительными трудностями, обусловленными сложностью самих графовых схем и процессом построения запросов. Графовые схемы характеризуются высокой степенью взаимосвязанности и разнообразием типов узлов и ребер, что требует точного сопоставления элементов языка с конкретными элементами схемы. Построение корректного запроса предполагает не только идентификацию релевантных узлов и связей, но и учет их семантики, а также соблюдение синтаксиса языка запросов, например, SPARQL или Cypher. Неоднозначность естественного языка и вариативность формулировок усложняют процесс интерпретации и могут приводить к неверному построению запроса или возврату нерелевантных результатов. Автоматизация этого процесса требует разработки сложных алгоритмов и моделей, способных эффективно справляться с этими вызовами.
Text2GQL-Bench: Стандартизированная Оценка Преобразования Текста в Графовые Запросы
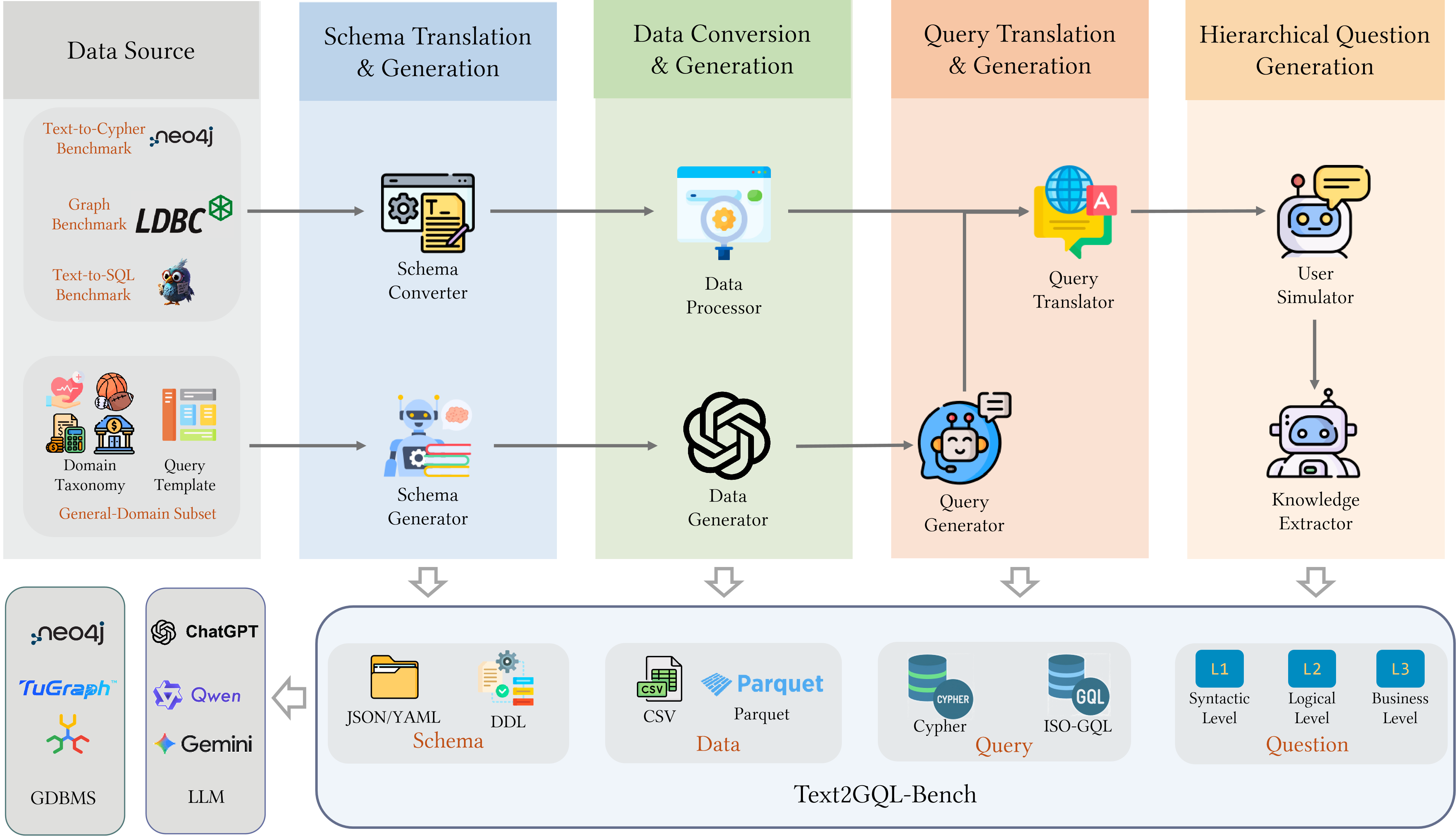
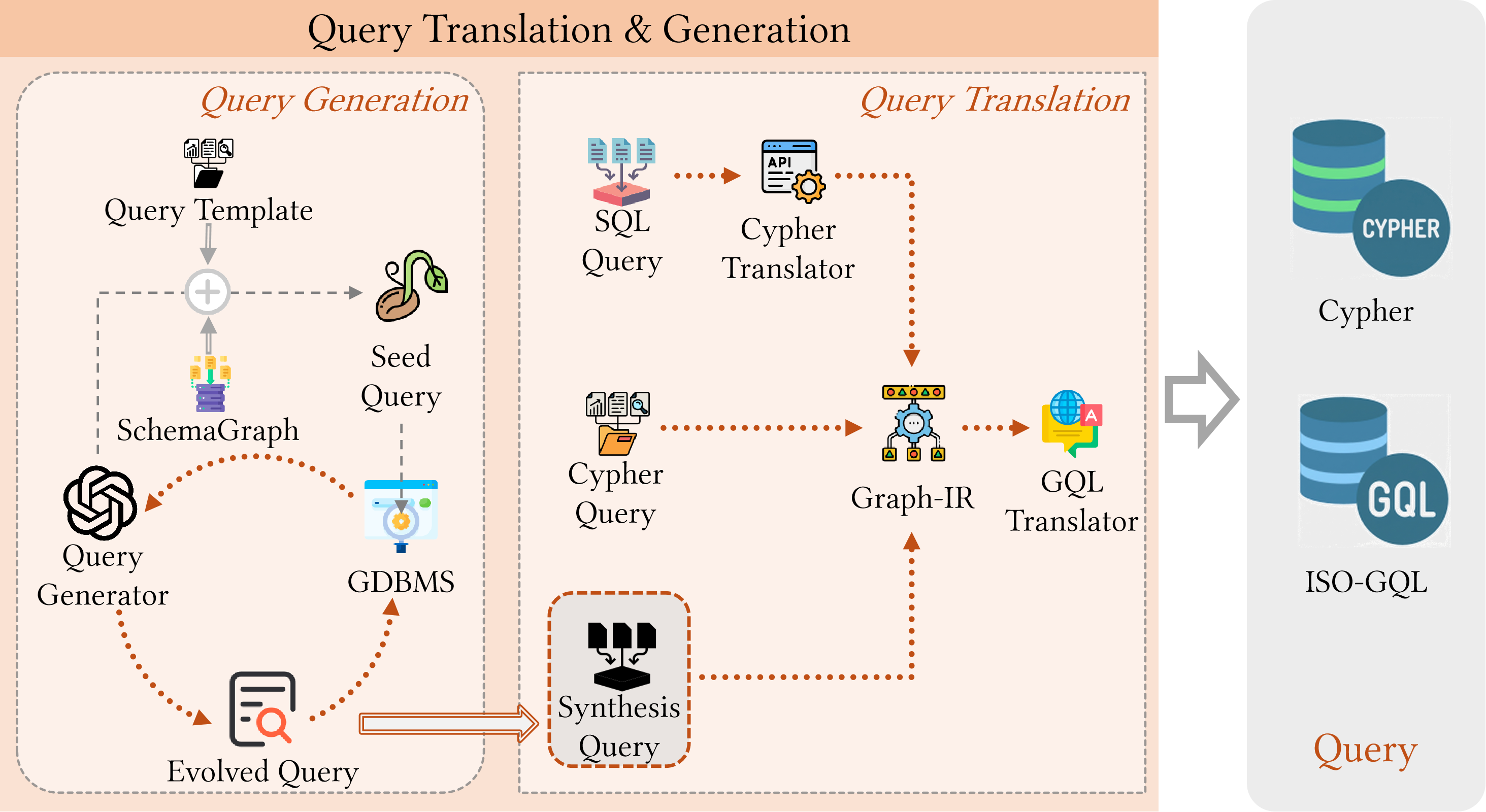
Текстовый бенчмарк Text2GQL-Bench представляет собой унифицированную платформу для оценки моделей, преобразующих естественный язык в запросы к графовым базам данных (Text-to-GQL). В его состав входит комплексный набор данных, включающий 178 184 пары (Вопрос, Запрос), охватывающих 13 различных предметных областей. Этот набор данных предназначен для стандартизации процесса оценки и обеспечения сопоставимости результатов, полученных с использованием различных моделей Text-to-GQL. Разнообразие доменов в наборе данных позволяет оценить обобщающую способность моделей на различные типы графовых данных и запросов.
В отличие от существующих бенчмарков, Text2GQL-Bench оценивает сгенерированные запросы не только на грамматическую корректность, но и на точность выполнения. Это означает, что помимо проверки синтаксиса, система проверяет, возвращает ли запрос правильные результаты на целевом графовом хранилище данных. Оценка точности выполнения осуществляется путем сравнения результатов, полученных из сгенерированного запроса, с эталонным набором данных, что позволяет комплексно оценить способность модели преобразовывать текстовые запросы в функциональные запросы к графам знаний.
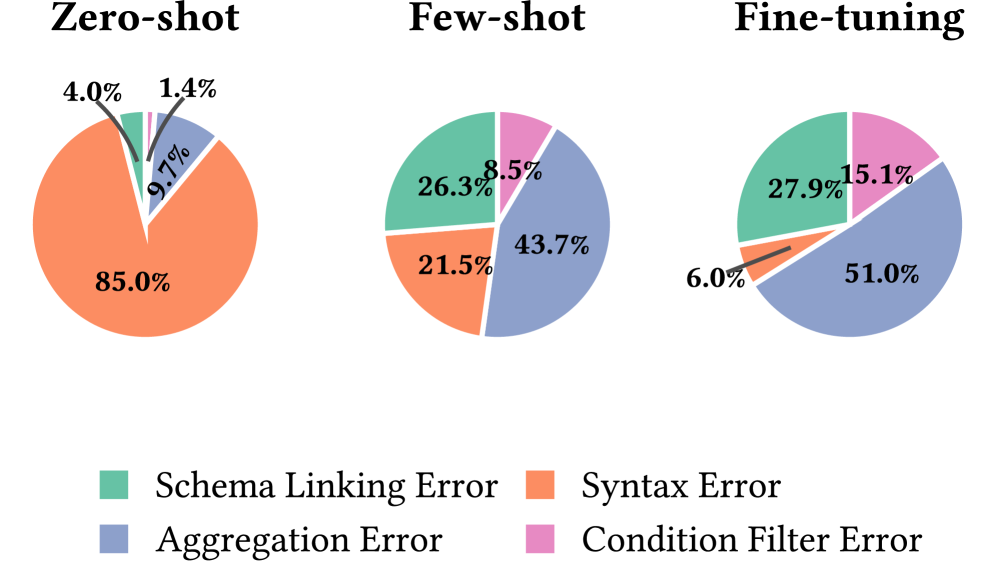
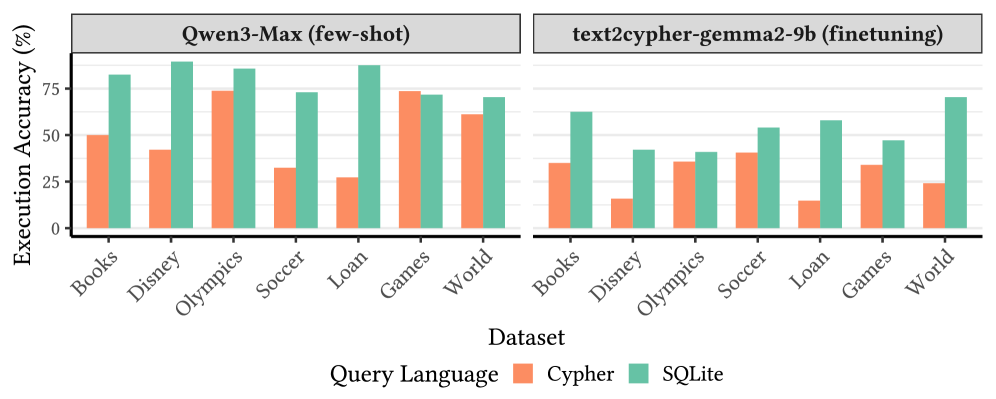
Тонкая настройка 8-ми параметровой модели на бенчмарке Text2GQL-Bench позволила достичь 45.1% точности выполнения (execution accuracy) и 90.8% грамматической корректности. Данный результат свидетельствует о значительном прогрессе в области разработки моделей, преобразующих естественный язык в запросы к графовым базам данных. Показатели точности выполнения демонстрируют способность модели генерировать запросы, возвращающие корректные результаты, в то время как высокая грамматическая корректность указывает на синтаксическую правильность сгенерированных запросов GQL.
Синтетические Данные: Преодоление Дефицита Информации и Обеспечение Надежности
Создание синтетических данных играет ключевую роль в формировании обучающих наборов, особенно когда реальные данные ограничены или недоступны, что часто встречается при работе со сложными схемами графов. В ситуациях, когда сбор и аннотация данных требуют значительных ресурсов или сопряжены с проблемами конфиденциальности, искусственно сгенерированные данные позволяют преодолеть эти препятствия и обеспечить достаточный объем информации для обучения моделей. Особенную ценность синтез данных представляет при работе с графовыми базами данных, где сложность взаимосвязей между элементами требует обширных и разнообразных обучающих примеров. Использование синтетических данных позволяет не только обучать модели, но и проверять их устойчивость к различным сценариям и обеспечивать обобщающую способность, что критически важно для надежной работы систем, основанных на анализе графов.
Исследователи активно используют синтетические данные для повышения устойчивости и обобщающей способности моделей, преобразующих естественный язык в запросы к графовым базам данных (Text-to-GQL). Недостаток размеченных данных, необходимых для обучения таких моделей, часто ограничивает их производительность и способность к адаптации к новым, ранее не встречавшимся схемам графов. Генерация искусственных данных позволяет существенно расширить обучающую выборку, охватывая широкий спектр возможных сценариев и структур графов. Это, в свою очередь, способствует повышению надежности моделей в условиях реальных данных, а также улучшает их способность к обобщению знаний на новые, незнакомые графовые схемы, обеспечивая более эффективный доступ к информации в сложных графовых базах данных.
Сочетание синтетических данных и эталонных наборов, таких как Text2GQL-Bench, значительно ускоряет прогресс в области доступа к данным, представленным в виде графов. Разработчики и исследователи получают возможность тестировать и совершенствовать модели преобразования естественного языка в запросы к графовым базам данных Text-to-GQL в условиях, когда реальные данные ограничены или недоступны. Использование стандартизированных бенчмарков позволяет объективно сравнивать различные подходы и стимулирует появление новых, более эффективных алгоритмов. Это, в свою очередь, открывает перспективы для более интуитивного и удобного взаимодействия с большими графовыми данными, что особенно важно для таких областей, как анализ социальных сетей, биоинформатика и интеллектуальный анализ знаний.
Перспективы Развития: Стандартизация и Расширение Графовых Технологий
Разработка международных стандартов, таких как ISO-GQL, играет ключевую роль в обеспечении совместимости и упрощении управления графовыми данными. Отсутствие единого стандарта ранее приводило к фрагментации экосистемы графовых баз данных, затрудняя обмен данными и переносимость приложений между различными платформами. Стандартизация позволяет разработчикам создавать более гибкие и масштабируемые решения, поскольку приложения, написанные с учетом стандарта ISO-GQL, могут взаимодействовать с различными графовыми базами данных без необходимости внесения существенных изменений в код. Это не только снижает затраты на разработку и обслуживание, но и способствует более широкому внедрению графовых технологий в различных отраслях, открывая новые возможности для анализа связей и извлечения ценной информации из сложных данных.
Язык запросов Cypher представляет собой мощный инструмент для работы с графовыми базами данных, отличающийся декларативным подходом к определению желаемого результата. Вместо указания конкретных шагов для извлечения данных, Cypher позволяет пользователю описать что необходимо получить, а система сама оптимизирует процесс поиска. Это достигается за счет использования интуитивно понятного синтаксиса, основанного на паттернах и отношениях между узлами графа. Такой подход значительно упрощает разработку сложных запросов и повышает читаемость кода, делая анализ и манипулирование данными более эффективными. Благодаря своей выразительности и оптимизированной реализации, Cypher позволяет исследователям и разработчикам быстро и легко извлекать ценную информацию из сложных графовых структур данных.
Развитие технологий работы с графовыми данными требует не только стандартизации языков запросов, но и создания надежной базы для оценки эффективности различных подходов. Подобно тому, как бенчмарк BIRD для Text-to-SQL позволил значительно продвинуть технологии работы с реляционными базами данных, инвестиции в создание бенчмарков, синтетических данных и стандартизированных языков запросов для графовых баз данных открывают путь к их полному раскрытию потенциала. Такая унификация позволит сравнивать различные системы, оптимизировать производительность и упростить разработку приложений, работающих с графовыми данными, что, в свою очередь, стимулирует инновации и широкое внедрение этой перспективной технологии.
Представленное исследование демонстрирует, что создание надежных систем преобразования естественного языка в запросы к графовым базам данных требует не просто достижения высокой точности, но и формирования комплексного набора данных для оценки. Подобно тому, как время испытывает любую систему, Text2GQL-Bench призван выявить слабые места современных LLM в задаче schema grounding и cross-language transfer. Кен Томпсон однажды заметил: «Всякий код со временем становится грязным». Эта фраза отражает суть проблемы, с которой сталкиваются разработчики: даже самые элегантные решения требуют постоянной поддержки и адаптации к меняющимся требованиям, а в случае с LLM — к растущему объему и сложности данных.
Что Дальше?
Представленный набор данных, Text2GQL-Bench, безусловно, закладывает основу для оценки систем, переводящих естественный язык в запросы к графовым базам данных. Однако, как и любая абстракция, он несёт в себе отпечаток текущего момента. Проблема заключается не в количестве тестовых примеров, а в их неизбежной ограниченности. Со временем, любая метрика становится лишь историческим артефактом, отражающим лишь часть той сложности, которую она пытается измерить. Вопрос не в том, чтобы создать «идеальный» набор данных, а в том, чтобы признать его временную природу.
Более фундаментальные вызовы лежат в плоскости самой парадигмы перевода. Неизбежная потеря контекста при сжатии естественного языка в формальный запрос — это не техническая проблема, которую можно «решить», а онтологическая неизбежность. Будущие исследования должны сместиться от простой оценки точности к изучению способов сохранения, а не устранения этой потери. Интерес представляет исследование устойчивости систем к неоднозначности, а не стремление к её полному искоренению.
И, наконец, необходимо признать, что перенос знаний между различными схемами графов — это не просто задача адаптации, а глубокая проблема понимания. Каждая схема — это модель мира, и попытка «перевести» вопрос между этими моделями неизбежно влечёт за собой искажение. Настоящий прогресс заключается не в достижении «универсального» переводчика, а в создании систем, способных осознавать и отражать эту неизбежную потерю информации, делая её частью самого ответа.
Оригинал статьи: https://arxiv.org/pdf/2602.11745.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Моделирование кровотока мозга: новый взгляд на скорость и точность
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Симуляция, которая видит себя: новый подход к физическому моделированию
- Искусственный интеллект на службе правосудия: моделируя вопросы в судебных дебатах
- Грань между Творчеством и Риском: Искусственный Интеллект и Эротический Контент
- Самообучающиеся агенты: извлечение навыков из открытого кода
- Видеомонтаж без следов: Новый подход к удалению и вставке объектов
- Зона ближайшего развития LLM: где синтез данных взламывает границы разума.
- Раскрывая потенциал языковых моделей: новый взгляд на оценку
2026-02-14 19:26