Автор: Денис Аветисян
Новый подход позволяет значительно повысить эффективность обучения больших языковых моделей в ситуациях, когда они уже демонстрируют высокую точность, фокусируясь на анализе ошибок.
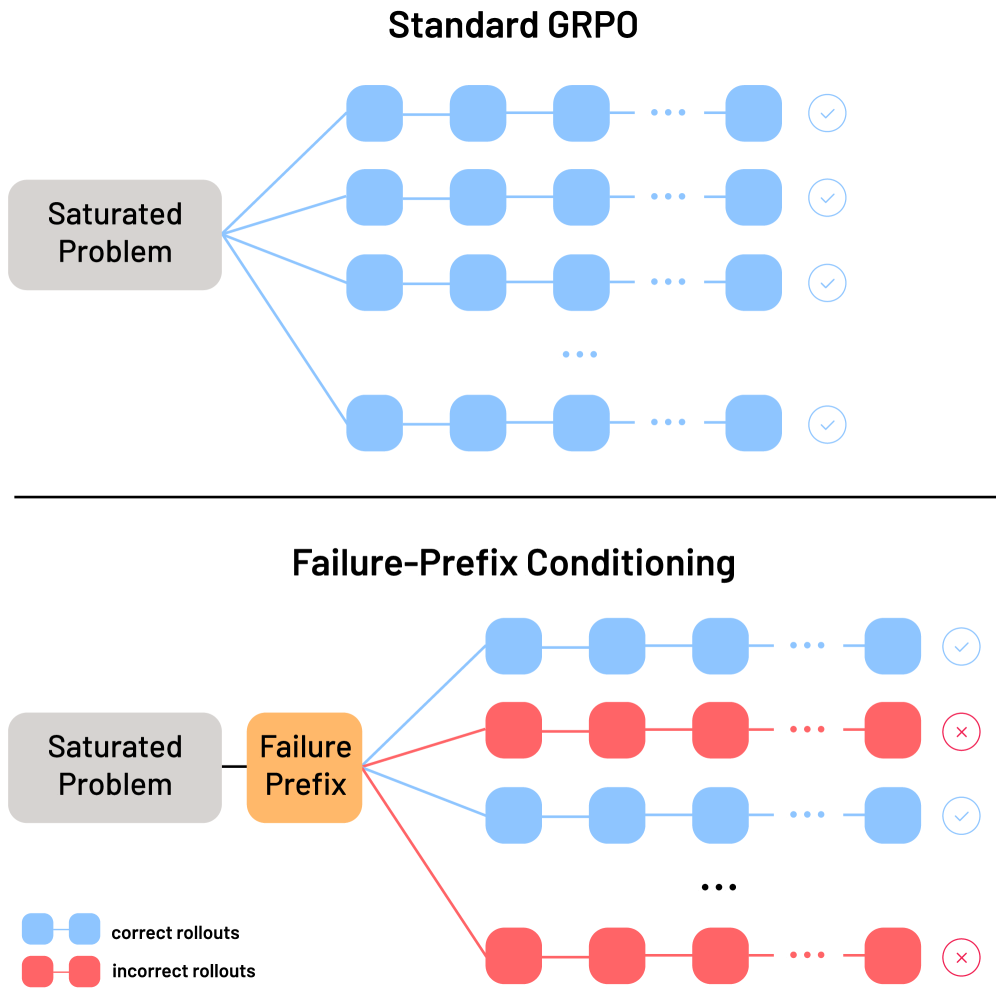
В статье представлена методика ‘обучения с учетом префиксов неудач’, направленная на повышение устойчивости и предотвращение стагнации в обучении языковых моделей, используемых в задачах, требующих рассуждений.
Несмотря на значительные успехи обучения больших языковых моделей с помощью обучения с подкреплением и проверяемыми наградами (RLVR), их прогресс часто замедляется при решении задач, близких к насыщению. В работе ‘Training Reasoning Models on Saturated Problems via Failure-Prefix Conditioning’ предложен новый подход, позволяющий преодолеть это ограничение за счет акцентирования обучения на состояниях, приводящих к ошибкам. Авторы демонстрируют, что использование “префиксов неудач” для инициализации процесса обучения позволяет модели более эффективно исследовать проблемные области и повышать устойчивость к вводящим в заблуждение данным. Возможно ли дальнейшее развитие данного метода для создания еще более надежных и адаптивных систем искусственного интеллекта, способных к решению сложных задач рассуждения?
Преодоление Насыщения в Рассуждениях: Поиск Новых Горизонтов
Несмотря на впечатляющие возможности больших языковых моделей, они часто сталкиваются с проблемой насыщения, когда их производительность перестает расти, даже при увеличении масштаба и вычислительных ресурсов. Это явление демонстрирует, что простое увеличение размера модели не всегда приводит к дальнейшему улучшению результатов, и что существуют фундаментальные ограничения в текущих подходах к обучению. Данная проблема особенно заметна в задачах, требующих сложных рассуждений и обобщения знаний, где модель достигает определенного уровня производительности, а затем ее дальнейшее совершенствование становится затруднительным. Понимание причин этой насыщаемости имеет ключевое значение для разработки новых стратегий обучения, способных преодолеть эти ограничения и раскрыть полный потенциал больших языковых моделей.
Наблюдаемое насыщение производительности больших языковых моделей часто связано с недостаточной разнородностью обучающего сигнала, особенно при работе с задачами разной сложности. Когда модель сталкивается преимущественно с однотипными вопросами или задачами, её способность к обобщению снижается, и дальнейшее увеличение масштаба не приводит к существенному улучшению результатов. Этот феномен проявляется в том, что модель быстро достигает плато, поскольку она оптимизируется для решения узкого круга задач, не приобретая достаточной гибкости для эффективной работы с более сложными или новыми сценариями. Таким образом, разнообразие входящих данных играет ключевую роль в преодолении этого ограничения и раскрытии полного потенциала языковых моделей.
Стандартные алгоритмы обучения с подкреплением, такие как GRPO, полагаются на сигналы вознаграждения для улучшения производительности модели. Однако, по мере достижения почти идеальной точности, эти сигналы становятся детерминированными, то есть предсказуемыми и лишенными вариативности. Это приводит к “насыщению” процесса обучения, когда дальнейшее увеличение масштаба модели или объема данных не приносит существенного улучшения результатов. Модель, получив постоянное подтверждение своей высокой точности, перестает исследовать альтернативные решения и адаптироваться к новым, более сложным задачам, что существенно ограничивает ее потенциал для дальнейшего развития и обобщения знаний.
Обучение с Подкреплением и Верифицируемыми Наградами: Новый Взгляд на Процесс Обучения
Предлагаемый фреймворк использует обучение с подкреплением с верифицируемыми наградами для решения проблемы насыщения в процессе обучения, что позволяет достичь производительности, сопоставимой с обучением на задачах средней сложности. Традиционные методы обучения часто демонстрируют снижение эффективности по мере приближения к оптимальному решению, поскольку модель перестает получать значимые сигналы для улучшения. Данный подход позволяет поддерживать стабильный процесс обучения, предоставляя четкие и верифицируемые сигналы даже при высокой точности, что способствует дальнейшему улучшению модели и предотвращает ее преждевременную остановку на субоптимальном решении.
Метод ‘Обусловливания по Префиксам Неудачи’ (Failure-Prefix Conditioning) предполагает явное включение в процесс обучения последовательностей шагов, приводящих к неверным ответам. Вместо фокусировки исключительно на успешных решениях, модель обучается на примерах, демонстрирующих типичные ошибки и неправильные подходы. Это достигается путем добавления префиксов, содержащих ошибочные вычисления или логические построения, к обучающим данным. Такой подход позволяет модели лучше распознавать и избегать подобных ошибок в будущем, усиливая сигнал обучения и повышая общую точность решения задач.
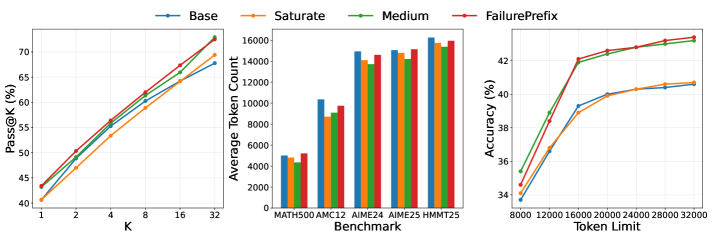
Обучение с подкреплением, ориентированное на анализ ошибочных последовательностей, позволяет значительно улучшить процесс обучения по сравнению с традиционным подходом, основанным исключительно на положительном подкреплении за правильные ответы. Акцентирование внимания на состояниях, приводящих к неверным решениям, предоставляет более информативный сигнал для алгоритма, поскольку позволяет ему идентифицировать и корректировать конкретные ошибки в рассуждениях. В результате, применение данной методики демонстрирует среднее увеличение точности на 2.8% при тестировании на пяти стандартных математических наборах данных.
Усиление Сигнала Через Обучение на Ошибках: Путь к Устойчивости Модели
Метод «Обучения на основе префиксов ошибок» (Failure-Prefix Conditioning) повышает эффективность обучения модели за счет целенаправленной работы с состояниями рассуждений, которые наиболее часто приводят к ошибкам. Суть подхода заключается в предоставлении модели частичной последовательности, содержащей типичные ошибочные состояния, перед генерацией остальной части выходных данных. Это позволяет модели активно тренироваться в коррекции ошибок и повышает ее устойчивость к вводящей в заблуждение информации, поскольку она учится распознавать и избегать состояний, которые обычно приводят к неверным результатам.
Метод префиксного кондиционирования (Prefix Conditioning) заключается в предоставлении модели частичной последовательности входных данных перед генерацией оставшейся части выходных данных. В процессе обучения, модель получает не полный запрос, а его начальный фрагмент, что позволяет ей предсказать и сгенерировать продолжение. Данный подход стимулирует модель к более активному анализу предоставленной информации и формированию более надежных стратегий генерации, поскольку она вынуждена учитывать контекст, заданный префиксом, при предсказании последующих элементов последовательности. Эффективность префиксного кондиционирования заключается в его способности направлять процесс обучения, фокусируя модель на конкретных аспектах задачи и улучшая её способность к обобщению.
Разнообразие префиксов, используемых в процессе обучения, и связанное с этим изменение вознаграждения (reward variance) оказывает прямое влияние на способность модели восстанавливаться после получения вводящей в заблуждение информации и повышать устойчивость. Экспериментальные данные показывают, что при обучении с использованием префиксов, содержащих 30% ошибок, наблюдается снижение точности на 11.5 процентных пункта. Для сравнения, базовая модель без подобной предварительной подготовки демонстрирует более значительное падение точности — на 23.8 процентных пункта — при аналогичных вводящих в заблуждение данных. Это свидетельствует о том, что целенаправленное обучение на ошибочных примерах значительно улучшает способность модели к адаптации и коррекции ошибок.

Итеративное Совершенствование и Эффективность Использования Токенов: Путь к Оптимизации Модели
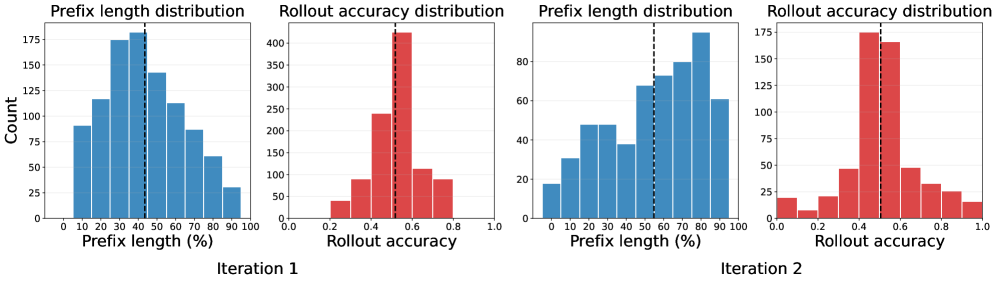
Процесс итеративного обновления «префиксов неудач» значительно усиливает способность модели к обучению, динамически адаптируя набор сложных для анализа состояний. Вместо статического списка ошибок, модель постоянно сталкивается с новыми, ранее не встречавшимися проблемами в рассуждениях. Это достигается путем регулярного обновления префиксов, представляющих собой фрагменты текста, вызывающие затруднения в процессе логического вывода. Такой подход предотвращает переобучение на конкретных ошибках и способствует обобщению знаний, позволяя модели более эффективно решать широкий спектр задач, требующих сложного анализа и логических построений. Постоянная стимуляция новыми вызовами поддерживает высокую производительность и способствует более глубокому пониманию принципов рассуждения.
Данная методика обеспечивает постоянную встречу модели с новыми, ранее не встречавшимися ошибками в рассуждениях, что предотвращает её переобучение на уже известных проблемах. Вместо заучивания ответов на конкретные вопросы, модель стимулируется к развитию более обобщенных стратегий решения задач. Постоянное предъявление новых “узких мест” в логике рассуждений заставляет модель адаптироваться и совершенствовать свои алгоритмы, повышая устойчивость к разнообразным входным данным и обеспечивая более надежные результаты в целом. Такой подход позволяет избежать ситуации, когда модель демонстрирует высокую производительность на тренировочном наборе данных, но терпит неудачу при столкновении с незнакомыми задачами или данными.
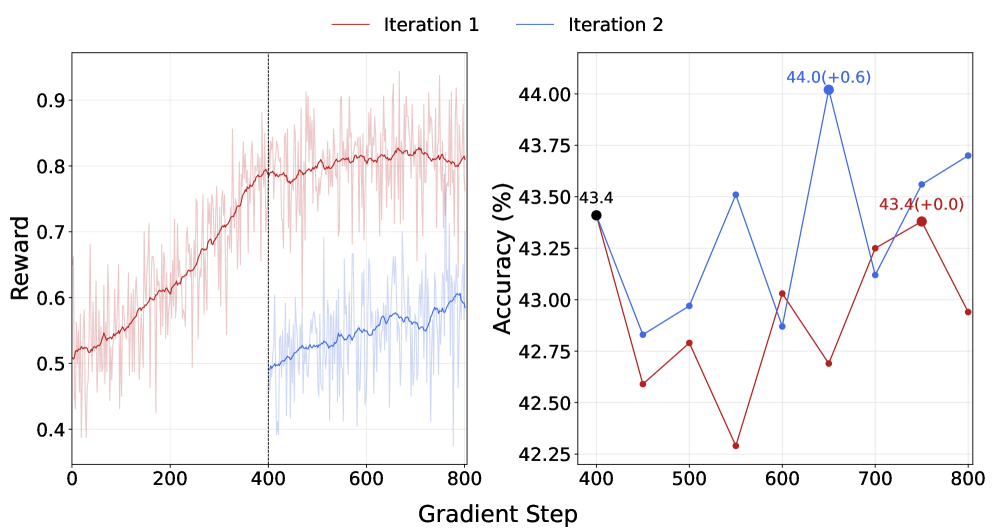
Тщательный отбор префиксов, используемых в процессе обучения, позволяет значительно повысить эффективность использования токенов. Дополнительная итерация, основанная на обучении по префиксам, выявляющим проблемные случаи, демонстрирует прирост точности на 0.6% от уже достигнутого пикового значения. Этот подход позволяет модели не только углублять понимание сложных задач, но и более рационально использовать вычислительные ресурсы, избегая избыточности в обработке информации. В результате, модель достигает лучших результатов при меньших затратах на обработку данных, что особенно важно для масштабных задач и ограниченных вычислительных мощностей.
Представленное исследование демонстрирует, что оптимизация системы, даже при достижении высокой точности, не является концом пути, а лишь точкой, где необходимо сфокусироваться на потенциальных точках отказа. Это созвучно идее о том, что структура определяет поведение: фокусировка на «насыщенных» проблемах и обучении на префиксах ошибок позволяет модели не просто демонстрировать высокую производительность, но и сохранять устойчивость в условиях непредсказуемости. Как заметил Дональд Дэвис: «Простота — это высшая степень изысканности». Это особенно верно в контексте сложных систем, где излишняя сложность может привести к новым узлам напряжения и снижению надежности. Обучение на ошибках, как предлагается в данной работе, является элегантным путем к повышению надежности и предотвращению плато производительности.
Куда же дальше?
Представленная работа, подобно тщательному ремонту сложного механизма, выявляет не столько новые детали, сколько принципиальные ограничения существующих подходов к обучению языковых моделей с подкреплением. Акцент на “насыщенных” задачах и обучении на ошибках — это, безусловно, шаг в правильном направлении, но не стоит забывать, что сама постановка задачи часто определяет её решение. Мы не можем просто “пересадить” улучшенную логику, не понимая, как циркулирует информация во всей системе.
Очевидным направлением дальнейших исследований представляется не просто улучшение алгоритмов, а переосмысление самой концепции “насыщения”. Действительно ли достижение высокой точности является конечной целью? Или же, возможно, истинная ценность заключается в способности модели к адаптации, к поиску новых, неожиданных решений, даже когда старые уже неэффективны? Подобный подход требует развития метрик, способных оценивать не только точность, но и гибкость, и устойчивость к изменениям.
В конечном счете, прогресс в этой области будет зависеть не столько от сложности алгоритмов, сколько от простоты и ясности фундаментальных принципов. Элегантный дизайн рождается из простоты. Истинная задача состоит в том, чтобы создать систему, которая не просто решает текущие проблемы, но и способна к саморазвитию и адаптации к неизбежным изменениям окружающей среды.
Оригинал статьи: https://arxiv.org/pdf/2601.20829.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Ранжирование с умом: новый подход к предсказанию кликов
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Лунный гелий-3: Охлаждение квантового будущего
2026-01-29 21:20