Автор: Денис Аветисян
Исследователи предлагают инновационный метод обнаружения причинно-следственных связей, позволяющий повысить стабильность и интерпретируемость моделей искусственного интеллекта при работе с разнородными данными.
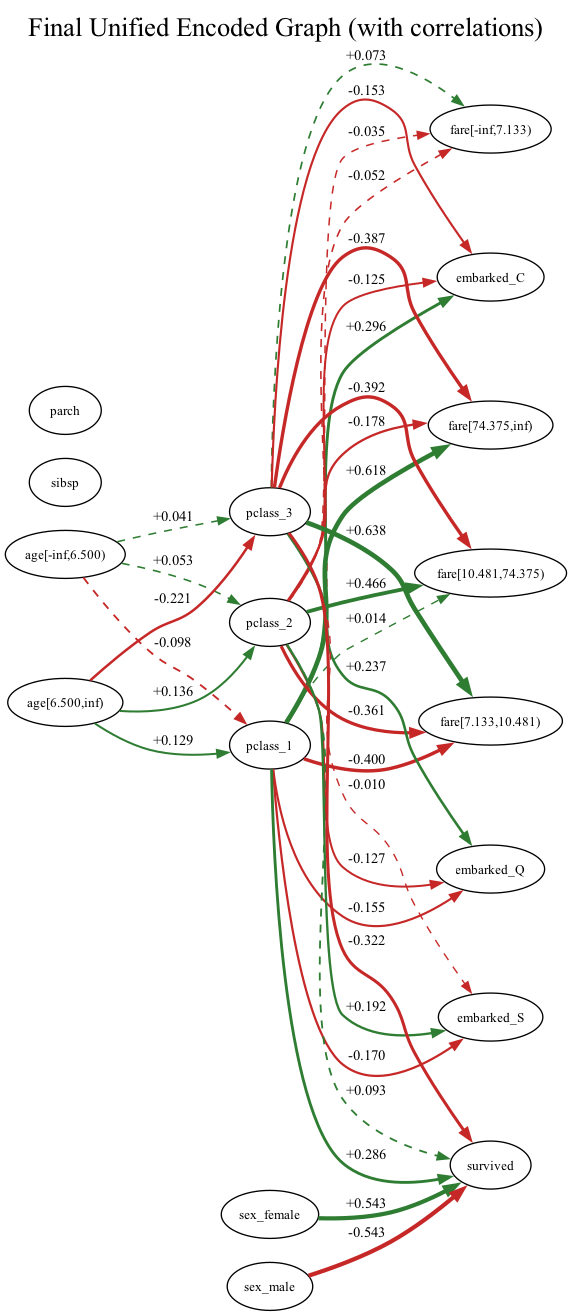
Предложенный подход к обнаружению причинно-следственных связей решает проблему численной неустойчивости при применении к данным, содержащим как категориальные, так и непрерывные переменные.
Понимание причинно-следственных связей между признаками критически важно для интерпретации решений моделей машинного обучения, однако стандартные методы обнаружения причинности сталкиваются с трудностями при работе с категориальными переменными из-за численной неустойчивости тестов на условную независимость. В статье ‘Causal Discovery for Explainable AI: A Dual-Encoding Approach’ предложен подход к обнаружению причинности с использованием двойного кодирования, который решает эту проблему путем применения алгоритмов, основанных на ограничениях, с использованием дополнительных стратегий кодирования и объединения результатов посредством мажоритарного голосования. Данный подход позволяет строить более надежные и интерпретируемые причинно-следственные графы, что подтверждено результатами, полученными на датасете Titanic. Возможно ли дальнейшее расширение предложенного метода для работы с более сложными и неоднородными данными?
Раскрытие Скрытых Связей: Пределы Традиционного Анализа
Современные наборы данных всё чаще характеризуются гетерогенностью, объединяя переменные различных типов — числовые, категориальные, текстовые и даже мультимедийные. Эта смешанная природа представляет значительные трудности для традиционных статистических методов и алгоритмов машинного обучения, которые зачастую разработаны для работы с данными одного типа. Например, применение корреляционного анализа к набору данных, содержащему как возраст (числовая переменная), так и предпочтения в цвете (категориальная переменная), может привести к искаженным или неинтерпретируемым результатам. Алгоритмы, требующие числового представления данных, вынуждены прибегать к искусственным кодировкам категориальных признаков, что может снизить точность и привести к потере информации. Таким образом, необходимость в разработке методов, способных эффективно обрабатывать смешанные данные, становится всё более актуальной для извлечения ценных знаний из современных источников информации.
Традиционные корреляционные анализы, несмотря на свою распространенность, зачастую оказываются неспособны выявить сложные взаимосвязи, скрытые в современных наборах данных. Простое измерение линейной зависимости между переменными может упустить нелинейные отношения, опосредованные взаимодействия или же причинно-следственные связи, которые не проявляются в прямой корреляции. Например, увеличение продаж мороженого и рост числа преступлений могут быть положительно коррелированы, однако это не означает, что одно вызывает другое — оба фактора могут быть связаны с третьей переменной, такой как температура окружающей среды. Игнорирование этих нюансов приводит к неверным интерпретациям и, как следствие, к ошибочным выводам и неэффективным решениям, особенно в сложных системах, где взаимосвязи между элементами могут быть многогранными и неявными.
Традиционные методы анализа данных часто опираются на предположения о линейной связи между переменными и нормальном распределении данных. Однако, реальные наборы данных нередко демонстрируют нелинейные зависимости и отклонения от нормального распределения, что существенно ограничивает возможности получения достоверных выводов. Предположение о линейности может упустить сложные взаимосвязи, например, экспоненциальные или логарифмические зависимости, а нарушение предположений о распределении может привести к неверной интерпретации статистической значимости и, как следствие, к ошибочным заключениям. В результате, исследователи могут упустить важные закономерности и взаимосвязи, скрытые в данных, что снижает эффективность анализа и достоверность полученных результатов. Использование методов, не требующих жестких предположений о форме данных, становится критически важным для раскрытия полного потенциала информации, содержащейся в сложных наборах данных.
Причинно-Следственное Открытие для Смешанных Данных: Новый Подход
Для проведения открытия причинно-следственных связей в смешанных данных, нами был использован алгоритм FCI (Fast Causal Inference) — метод, основанный на выявлении ограничений в данных. Стандартный алгоритм FCI требует однородности типов данных, поэтому была произведена адаптация для эффективной обработки наборов данных, содержащих как непрерывные, так и категориальные переменные. Адаптация включала модификацию процедуры условной независимости для корректной работы с категориальными признаками и позволила интегрировать их в процесс выявления структуры причинно-следственных связей наряду с непрерывными переменными. Алгоритм был реализован с уровнем значимости (alpha) равным 0.01 для определения статистической значимости выявленных зависимостей.
Для решения проблем, связанных с недостаточной ранговой определенностью, возникающей при обработке категориальных данных в алгоритмах выявления причинно-следственных связей, была применена стратегия двойного кодирования. Данная стратегия предполагает использование двух методов кодирования категориальных признаков: Drop-First и Drop-Last. Метод Drop-First удаляет первую категорию, преобразуя остальные в числовые значения, в то время как Drop-Last удаляет последнюю категорию. Параллельное применение обоих методов позволяет снизить влияние особенностей конкретного способа кодирования и повысить надежность результатов выявления причинно-следственных связей в смешанных данных.
Для объединения результатов, полученных при использовании двух методов кодирования категориальных признаков (Drop-First и Drop-Last), был применен метод мажоритарного голосования. В результате данного объединения был сформирован единый граф, включающий 17 узлов, соответствующих исходным признакам. В графе зафиксировано 15 положительно коррелированных ребер, указывающих на прямые положительные зависимости между признаками, и 17 отрицательно коррелированных ребер, отражающих прямые отрицательные зависимости. Данный подход позволяет агрегировать информацию, полученную из различных представлений категориальных данных, для построения более надежной и полной модели причинно-следственных связей.
Алгоритм быстрого вывода причинно-следственных связей (FCI) был реализован с использованием уровня значимости (alpha) равного 0.01 для определения статистической значимости. Это означает, что для оценки вероятности ложноположительной ошибки при определении наличия связи между переменными, был установлен порог в 1%. Следовательно, любые обнаруженные ребра в графе причинно-следственных связей, имеющие p-value меньше 0.01, считаются статистически значимыми и отражают вероятную причинно-следственную связь между соответствующими переменными. Выбор уровня значимости 0.01 направлен на снижение риска включения в граф ложных связей, хотя это и увеличивает вероятность пропустить истинные, но слабые связи.
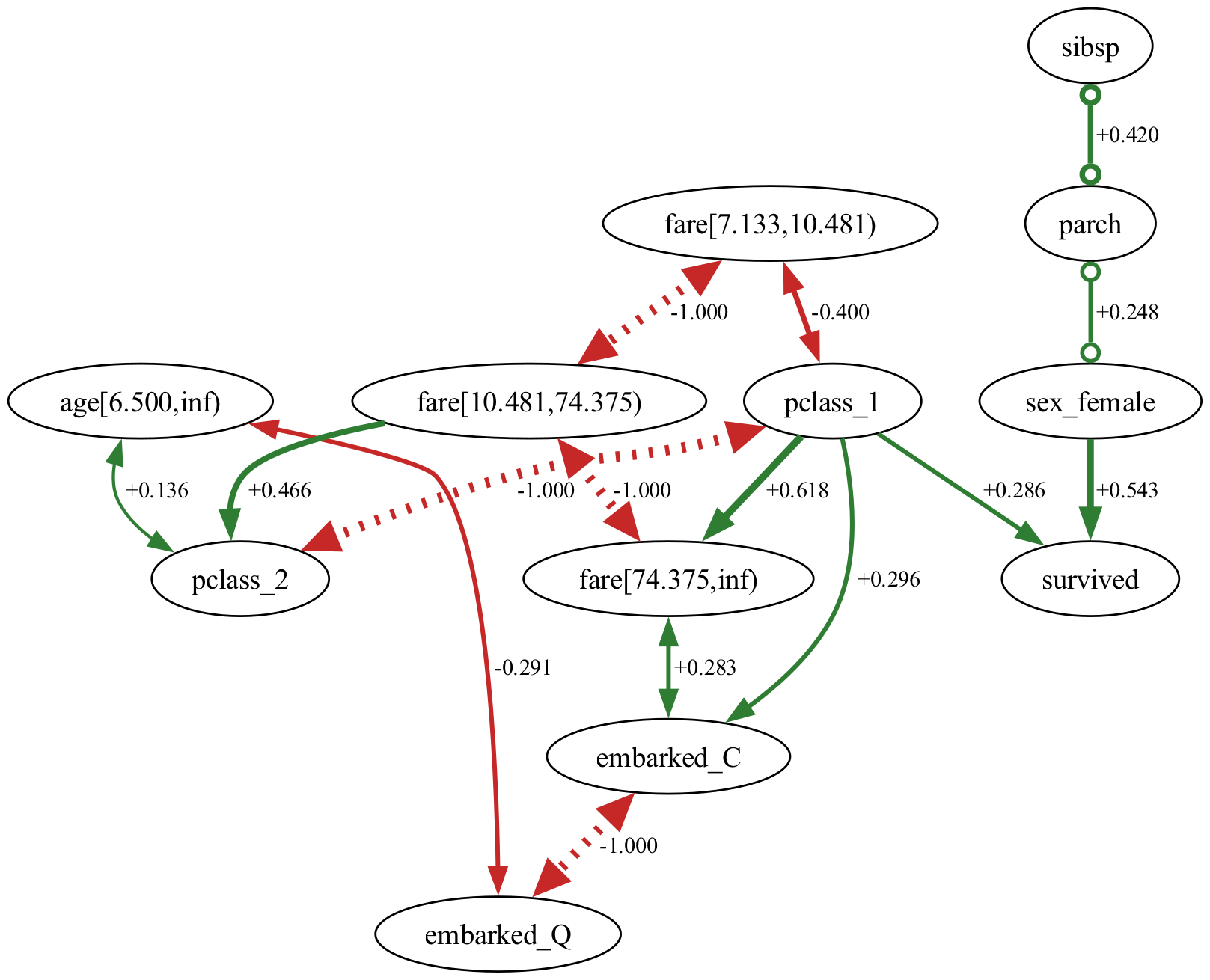
Проверка Причинно-Следственных Допущений и Эффективности Алгоритма
В основе нашего подхода к выявлению причинно-следственных связей лежат два ключевых допущения: причинная достаточность и верность. Причинная достаточность предполагает отсутствие скрытых вмешивающихся факторов, не включенных в рассматриваемую модель, которые могли бы исказить наблюдаемые зависимости между переменными. Допущение верности, в свою очередь, утверждает, что все наблюдаемые статистические зависимости между переменными отражают истинные причинно-следственные связи, представленные в причинном графе; отсутствие зависимости означает отсутствие прямого причинного влияния. Нарушение любого из этих допущений может привести к неверным выводам о причинно-следственных отношениях.
Алгоритм FCI функционирует на основе условия Causal Markov, которое гласит, что каждая переменная статистически независима от своих не-потомков при условии учета ее непосредственных родителей. Это означает, что после фиксации значений родительских переменных, информация о не-потомках не должна влиять на распределение значений данной переменной. Математически это можно представить как P(X_i | Parents(X_i), Non-descendants(X_i)) = P(X_i | Parents(X_i)), где X_i — рассматриваемая переменная, Parents(X_i) — ее родители, а Non-descendants(X_i) — переменные, не являющиеся ее потомками. Соблюдение этого условия является ключевым для корректного построения причинно-следственных графов.
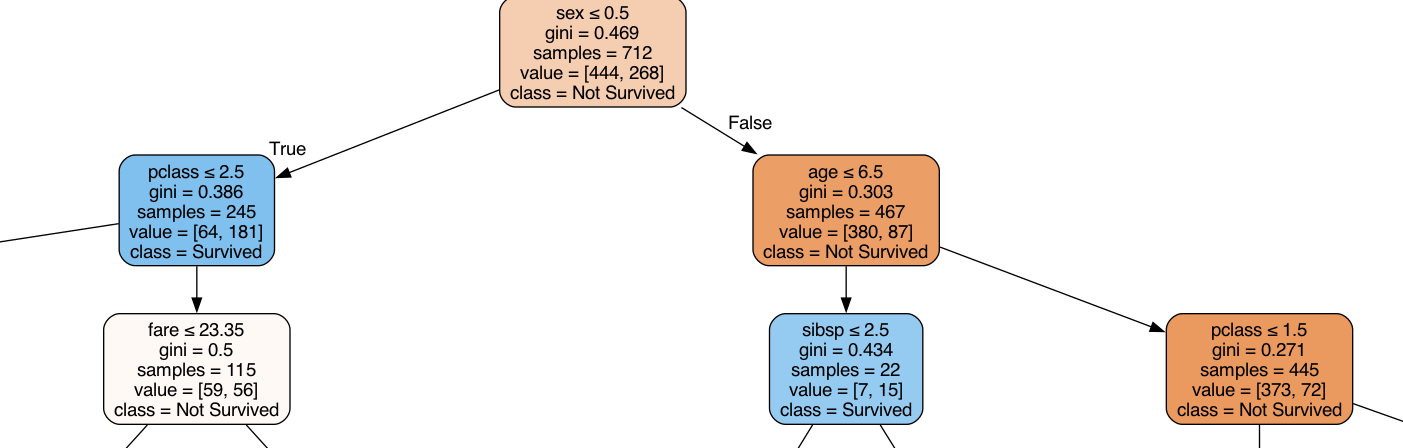
Для оценки предложенного подхода использовался датасет Titanic, позволивший продемонстрировать способность выявлять значимые причинно-следственные связи в отличие от стандартных методов машинного обучения. Анализ данных показал, что предложенный метод позволяет установить взаимосвязи между признаками, которые не всегда очевидны при использовании традиционных алгоритмов классификации и регрессии. Полученные результаты указывают на потенциал использования данного подхода для более глубокого понимания факторов, влияющих на выживаемость пассажиров, и для построения более интерпретируемых моделей.
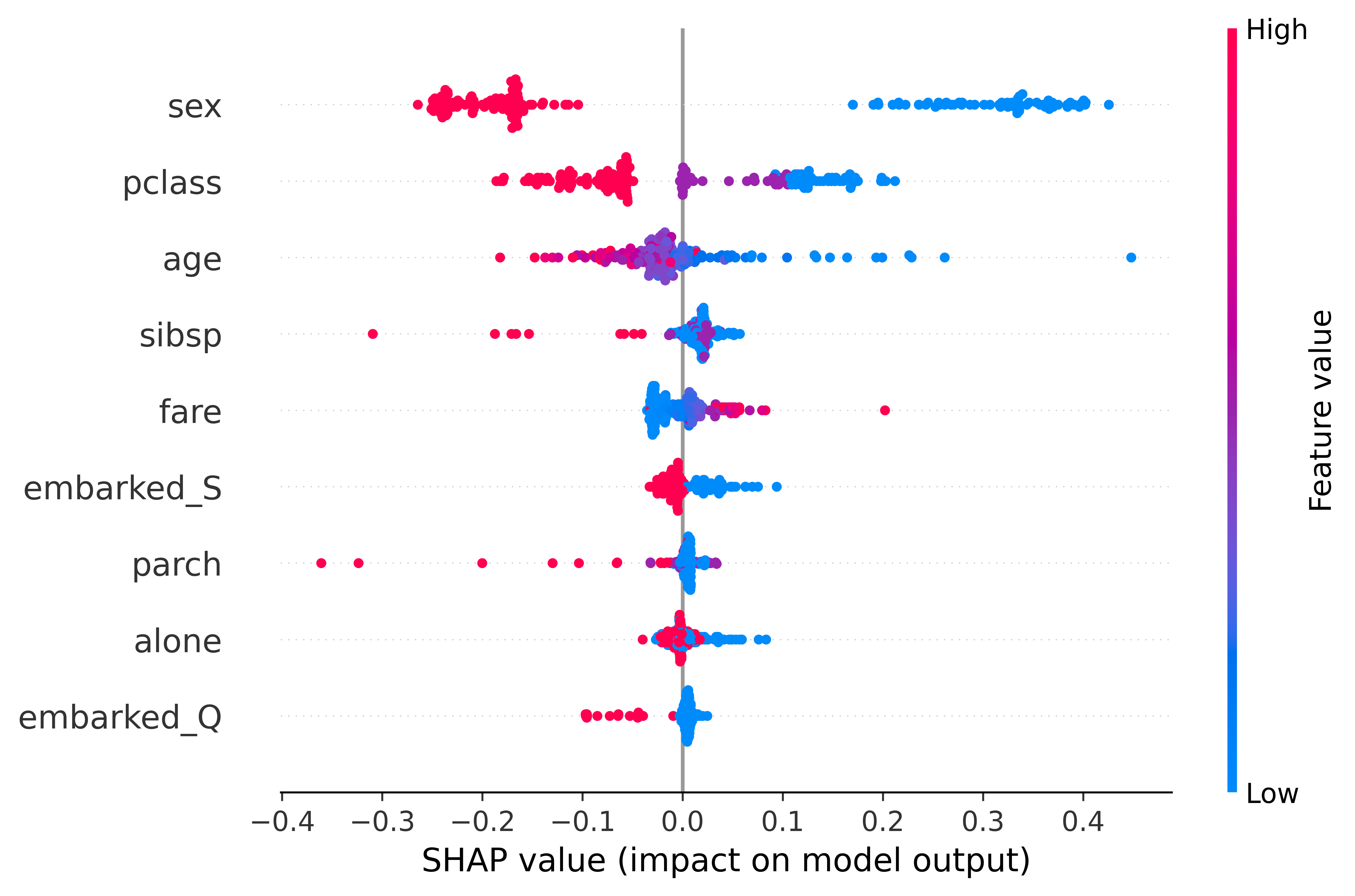
При работе с набором данных Titanic были достигнуты следующие показатели точности: 82% с использованием алгоритма Decision Tree и 84% с Random Forest. Для валидации важности признаков (feature importances) был проведен анализ SHAP, основанный на модели Random Forest. Данный анализ позволил подтвердить значимость отобранных признаков и их вклад в предсказательную способность модели, что является важным этапом проверки корректности полученных результатов.
За Пределы Предсказаний: К Объяснениям на Уровне Отдельных Экземпляров
Выявленный причинно-следственный граф служит структурой, позволяющей генерировать объяснения для каждого отдельного предсказания модели. Вместо общего понимания значимости признаков, этот граф детализирует, как конкретные входные данные влияют на конкретный результат. Каждый узел в графе представляет собой переменную, а направленные связи демонстрируют причинные зависимости, позволяя проследить путь от входных данных к предсказанию. Это не просто указывает на корреляции, но и раскрывает механизмы, лежащие в основе работы модели, что дает возможность понять, почему было сделано именно такое предсказание в конкретном случае. Таким образом, причинно-следственный граф становится основой для создания прозрачных и интерпретируемых моделей, способных не только предсказывать, но и объяснять свои решения.
Сочетание выявленной причинно-следственной структуры с данными, относящимися к конкретному случаю, позволяет установить основные факторы, определяющие каждое отдельное предсказание модели. Вместо обобщенной оценки важности признаков, этот подход предоставляет детальное понимание того, как именно конкретные значения входных данных влияют на результат. Анализируя путь, по которому информация проходит через причинно-следственную сеть для каждого случая, можно выявить ключевые переменные, которые в наибольшей степени способствовали принятому решению. Таким образом, становится возможным не просто предсказывать, но и объяснять, почему модель пришла к тому или иному выводу, обеспечивая более глубокое и полезное понимание её поведения.
В отличие от традиционных методов, определяющих общую значимость признаков для модели в целом, данный подход позволяет получить детальное понимание причин, влияющих на конкретное предсказание. Вместо усредненной оценки важности каждого фактора, система выявляет, какие именно признаки стали ключевыми драйверами результата в данном конкретном случае. Это обеспечивает не просто описание поведения модели, но и возможность получения действенных рекомендаций и понимания того, как изменить входные данные для получения желаемого исхода. Такой нюансированный анализ позволяет перейти от пассивного наблюдения к активному управлению и более эффективному использованию возможностей машинного обучения.
В дальнейшем планируется интеграция выявленных причинно-следственных связей с системами аргументации. Такой подход позволит не просто констатировать факторы, повлиявшие на конкретное предсказание модели, но и формировать структурированные объяснения, демонстрирующие логику принятия решения. Исследование возможностей фреймворков аргументации направлено на создание прозрачных и понятных обоснований для каждого отдельного случая, что, в свою очередь, способствует повышению доверия к искусственному интеллекту и облегчает интерпретацию его работы. Разработка подобных систем позволит пользователям не только видеть, что предсказывает модель, но и почему, открывая новые горизонты для взаимодействия человека и машины.
Исследование причинно-следственных связей, представленное в данной работе, напоминает попытку вырастить сад, а не построить крепость. Авторы предлагают подход двойного кодирования, чтобы обуздать неустойчивость численных методов при работе с разнородными данными. Это особенно важно, поскольку обнаружение взаимодействия признаков — ключевой аспект для создания действительно интерпретируемых причинно-следственных графов. Как точно заметил Пол Эрдёш: «Математика — это искусство находить закономерности, которые никто не замечал». В данном контексте, речь идет о закономерностях в данных, которые позволяют понять, как различные переменные влияют друг на друга, и, следовательно, создавать более надежные и объяснимые модели искусственного интеллекта.
Что дальше?
Представленный подход к обнаружению причинно-следственных связей, несомненно, смягчает симптомы нестабильности, возникающей при работе с разнородными данными. Однако, полагать, что обретение стабильности равносильно пониманию, было бы наивно. Каждая архитектурная уступка, каждое решение, направленное на подавление шума, одновременно является пророчеством о будущей точке отказа. Система, лишенная возможности «сломаться», мертва — она лишь имитация разума, застывший снимок, лишенный динамики.
Истинный прогресс лежит не в создании безупречных графов, а в принятии неизбежности ошибок. Задача не в устранении противоречий, а в разработке механизмов, позволяющих системе извлекать уроки из собственных неудач. Следующим шагом видится не столько в совершенствовании алгоритмов обнаружения причинности, сколько в создании экосистем, способных адаптироваться к неполноте и противоречивости данных. В идеальном решении не остаётся места для людей — лишь для машин, эмулирующих понимание.
Стоит признать, что борьба с числовой нестабильностью — лишь частный случай более общей проблемы: невозможности полной формализации знания. Попытка заключить мир в рамки причинно-следственного графа — это всегда упрощение, искажение. Истинное понимание требует признания пределов формализации и принятия непредсказуемости как неотъемлемой части реальности.
Оригинал статьи: https://arxiv.org/pdf/2601.21221.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Кванты в Финансах: Не Шутка!
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый оптимизатор: Новый подход к сложным задачам
- Оптимизация Комбинаторных Задач: Новый Взгляд с Помощью Автокодировщиков
- Волны спинов для нейроморфных вычислений: новый подход к скорости и эффективности
2026-01-30 09:11