Автор: Денис Аветисян
Исследователи представили масштабные причинные модели, способные выявлять взаимосвязи во временных данных с беспрецедентной точностью и обобщающей способностью.
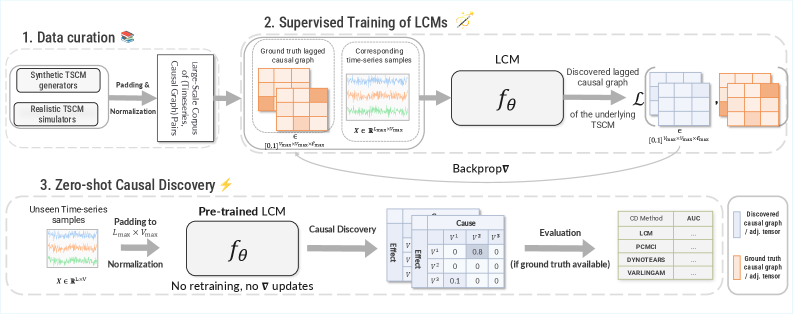
В статье рассматриваются Large Causal Models (LCM) — фундаментальные модели для обнаружения временных причинно-следственных связей, превосходящие традиционные методы в задачах zero-shot обобщения.
Традиционные подходы к выявлению причинно-следственных связей, как в статических, так и во временных данных, зачастую привязаны к конкретному набору данных, ограничивая потенциал предварительного обучения на больших объемах. В данной работе, посвященной ‘Large Causal Models for Temporal Causal Discovery’, предложен новый класс предварительно обученных нейронных сетей — большие причинные модели (LCM), специально разработанных для анализа временных причинно-следственных графов. Показано, что масштабирование моделей причинно-следственного вывода возможно благодаря обучению на разнообразных синтетических и реальных временных рядах, что позволяет превзойти классические и нейронные подходы, особенно в условиях обобщения на новые данные. Смогут ли LCM стать основой для создания универсальных моделей выявления причинно-следственных связей во временных данных?
Выявление Временных Зависимостей: Основа Причинно-Следственного Анализа
Традиционные методы выявления причинно-следственных связей часто оказываются неэффективными при анализе временных рядов данных. Основная сложность заключается в том, что они предполагают стационарность, то есть неизменность связей во времени, что редко соответствует действительности. Динамические системы, присущие большинству реальных процессов, характеризуются постоянно меняющимися взаимодействиями, в которых влияние одной переменной на другую может проявляться с задержкой или зависеть от текущего состояния системы. В результате, стандартные алгоритмы могут либо упускать важные связи, либо ложно определять причинность, игнорируя временную последовательность событий и сложные обратные связи, что существенно ограничивает их применимость для прогнозирования и разработки эффективных стратегий вмешательства.
Анализ временных рядов представляет собой существенную сложность в обнаружении причинно-следственных связей, поскольку традиционные методы часто не учитывают запаздывающие эффекты и направленность влияния. Необходимо разрабатывать подходы, способные выявлять, как прошлые значения одной переменной могут влиять на будущие значения другой, и учитывать, что это влияние может быть отложенным во времени. Определение этой временной зависимости — задача, требующая учета не только корреляций, но и последовательности событий, чтобы избежать ложных выводов о причинности. Игнорирование запаздывающих эффектов может привести к неверной интерпретации данных и, как следствие, к ошибочным прогнозам и неэффективным стратегиям вмешательства.
Понимание временных зависимостей имеет решающее значение для точного прогнозирования, планирования вмешательств и принятия надежных решений. Способность выявлять, как прошлые события влияют на текущие и будущие, позволяет создавать более реалистичные модели и предсказывать тенденции с большей уверенностью. В частности, в областях, таких как экономика, здравоохранение и климатология, точное прогнозирование жизненно необходимо для эффективного распределения ресурсов и смягчения рисков. Планирование вмешательств, основанное на понимании временных связей, позволяет оптимизировать стратегии, максимизируя положительные результаты и минимизируя нежелательные последствия. Наконец, принятие надежных решений требует учета динамических взаимосвязей, обеспечивая адаптивность и устойчивость в условиях неопределенности, что особенно важно для сложных систем, где последствия действий могут проявиться лишь спустя время.
Большие Причинно-Следственные Модели: Новый Подход к Анализу Временных Рядов
Большие причинно-следственные модели (LCM) представляют собой масштабируемое и эффективное решение для обнаружения временных причинно-следственных связей, использующее возможности предварительно обученных моделей (foundation models). В отличие от традиционных методов, требующих значительных вычислительных ресурсов и зачастую ограниченных небольшими наборами данных, LCM позволяют анализировать длительные временные ряды и выявлять сложные зависимости. Использование архитектуры Transformer обеспечивает параллельную обработку данных и эффективное масштабирование на больших объемах информации, что делает LCM применимыми к задачам, где временные зависимости критически важны, например, в прогнозировании, диагностике и анализе динамических систем. Масштабируемость достигается за счет использования предварительно обученных весов, что снижает потребность в обучении с нуля и позволяет адаптировать модели к новым данным с меньшими затратами.
Модели больших причинно-следственных связей (LCM) используют архитектуру Transformer, что позволяет им эффективно обрабатывать и анализировать временные ряды, выявляя зависимости между событиями, произошедшими в разные моменты времени. В отличие от традиционных рекуррентных нейронных сетей, Transformer использует механизм внимания (attention), позволяющий модели взвешивать важность различных временных точек при прогнозировании или объяснении текущего состояния системы. Это особенно важно для сложных временных систем, где события, произошедшие в далеком прошлом, могут оказывать существенное влияние на текущую динамику. Способность архитектуры Transformer учитывать долгосрочные зависимости является ключевым фактором, обеспечивающим высокую производительность LCM при обнаружении причинно-следственных связей во временных данных.
Большие причинно-следственные модели (LCM) используют принципы структурного причинно-следственного моделирования (SCM) для представления и анализа причинно-следственных связей во времени. В рамках SCM, каждая переменная в системе определяется функциональной зависимостью от своих прямых причин и случайного шума. LCM адаптируют эту концепцию, представляя временные ряды как взаимосвязанные переменные, а причинно-следственные связи — как функциональные зависимости, которые могут меняться во времени. Это позволяет не просто выявлять корреляции между переменными, но и строить графические модели, отражающие предполагаемые причинно-следственные механизмы, что обеспечивает возможность проведения контрфактического анализа и прогнозирования последствий вмешательств в систему. Такой подход позволяет моделировать динамические системы с учетом временной задержки и обратной связи.
В отличие от традиционных методов анализа временных рядов, которые ограничиваются выявлением корреляций, большие причинно-следственные модели (LCM) направлены на установление механизмов, определяющих динамику временных процессов. Данный подход позволяет не только констатировать взаимосвязь между событиями, но и определить, какое событие является причиной другого. Результаты, представленные в данной работе, демонстрируют, что LCM превосходят существующие методы в задачах выявления причинно-следственных связей во временных данных, достигая передовых показателей эффективности и предоставляя более глубокое понимание сложных систем.
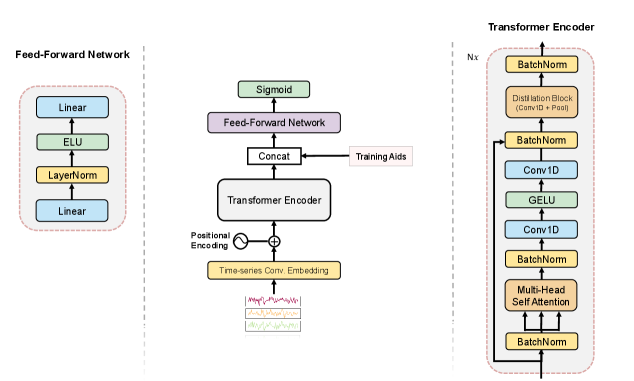
Архитектура и Принципы Вывода в Моделях Informer
Архитектура Informer, являющаяся расширением Transformer, оптимизирует модели причинно-следственного вывода (LCM) для прогнозирования длинных временных рядов за счет внедрения инноваций, таких как ProbSparse attention и активация SwiGLU. ProbSparse attention уменьшает вычислительную сложность механизма внимания, фокусируясь на наиболее значимых временных шагах, что критически важно для обработки длинных последовательностей. Активация SwiGLU, в свою очередь, обеспечивает более эффективное обучение и улучшает способность модели к обобщению. Эти усовершенствования позволяют Informer достигать более высокой точности и эффективности по сравнению со стандартными Transformer-моделями при решении задач прогнозирования временных рядов.
Механизмы самовнимания (Self-Attention) в основе архитектуры Transformer позволяют модели динамически оценивать важность различных временных шагов при обработке последовательностей. В отличие от рекуррентных нейронных сетей, обрабатывающих данные последовательно, самовнимание вычисляет взвешенную сумму всех временных шагов, где веса определяются на основе релевантности каждого шага к текущей позиции. Это позволяет модели фокусироваться на наиболее информативных частях входной последовательности, игнорируя менее важные, что приводит к повышению точности прогнозирования и снижению вычислительных затрат по сравнению с традиционными подходами. Вычисление внимания включает в себя три матрицы: Query, Key и Value, используемые для определения весов внимания и формирования контекстного представления последовательности. Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}})V, где d_k — размерность ключей.
Нормализация слоев (Layer Normalization) является ключевым компонентом, обеспечивающим стабильность процесса обучения и улучшающим обобщающую способность модели. В отличие от пакетной нормализации (Batch Normalization), которая нормализует активации по батчу, нормализация слоев выполняет нормализацию по признакам внутри каждого отдельного слоя. Это особенно важно для рекуррентных нейронных сетей и моделей, работающих с последовательностями переменной длины, где батчи могут быть нестабильными. Применение нормализации слоев снижает внутреннее ковариационное смещение, позволяя использовать более высокие скорости обучения и упрощая оптимизацию. В результате, модель демонстрирует улучшенную производительность на новых, ранее не встречавшихся данных, что критически важно для практических приложений, требующих надежной и точной работы в реальных условиях.
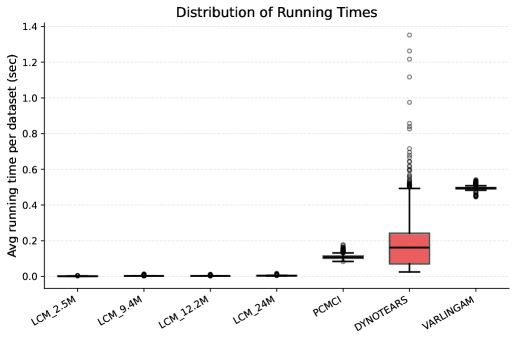
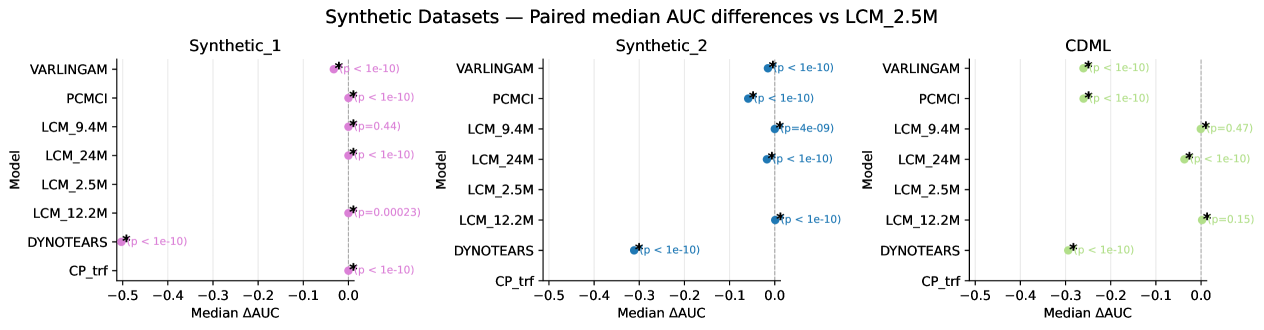
Для оценки точности графов причинно-следственных связей, выведенных с помощью линейных причинных моделей (LCM), используются стандартные методы, такие как VARLiNGAM, DYNOTEARS и PCMCI. Сравнительный анализ показывает, что LCM демонстрируют значительное улучшение метрики AUC (площадь под кривой ROC) на синтетических, полусинтетических и реалистичных наборах данных по сравнению с указанными базовыми методами. Данный результат подтверждает эффективность LCM в задачах выявления причинно-следственных связей и их превосходство над альтернативными подходами в различных сценариях.
Обеспечение Достоверности и Устойчивости Причинно-Следственного Анализа
Предположение о причинной достаточности — то есть, что все общие причины наблюдаются и учтены в анализе — является критически важным для получения корректных выводов о причинно-следственных связях. Отсутствие учета существенных общих причин может привести к смещенным оценкам эффекта и неверным интерпретациям результатов. Тщательная проверка данных и теоретическое обоснование включения всех релевантных ковариат необходимы для минимизации риска нарушения данного предположения и обеспечения валидности выводов. Несоблюдение принципа причинной достаточности ставит под сомнение надежность любых выводов о причинно-следственных связях, полученных на основе наблюдательных данных.
Проверка временных рядов на стационарность является критически важной, поскольку нестационарные данные могут приводить к ложным корреляциям и, как следствие, к ошибочным выводам о причинно-следственных связях. Нестационарность проявляется в изменении статистических свойств временного ряда, таких как среднее значение и дисперсия, во времени. Использование нестационарных данных в анализе причинности может привести к выявлению кажущихся причинно-следственных связей, которые на самом деле являются результатом общих трендов или сезонности, а не истинных взаимосвязей между переменными. Для устранения нестационарности часто применяются методы дифференцирования или преобразования данных, такие как логарифмирование, перед проведением анализа причинности.
Оценка производительности методов линейного причинного моделирования (LCM) проводится с использованием метрик, таких как площадь под ROC-кривой (AUC). Для коррекции вероятности ложноположительных результатов при множественных сравнениях применяется поправка Бонферрони. В ходе тестирования на синтетическом наборе данных LCM продемонстрировали идеальное значение AUC, равное 1.00, что свидетельствует о высокой точности и способности к разделению классов в контролируемых условиях.
Синтетические данные играют ключевую роль в оценке производительности методов обнаружения причинно-следственных связей (LCMs), поскольку обеспечивают контролируемые условия для тестирования. В отличие от реальных данных, которые часто содержат скрытые факторы и шумы, синтетические наборы данных позволяют точно определить истинные причинно-следственные связи, что необходимо для объективной оценки алгоритмов. Это позволяет исследователям и разработчикам проверять, насколько точно LCMs могут выявлять заданные причинно-следственные связи в идеальных условиях, прежде чем применять их к более сложным и непредсказуемым реальным данным. Использование синтетических данных также упрощает процесс отладки и оптимизации алгоритмов, поскольку позволяет изолировать и контролировать отдельные параметры и переменные.
Будущее Причинно-Следственного Искусственного Интеллекта
Линейные причинные модели (LCM) представляют собой значительный прорыв в создании более понятных и надежных систем искусственного интеллекта, отходя от традиционных моделей, основанных исключительно на корреляциях. В отличие от них, LCM стремятся выявить и представить истинные причинно-следственные связи между переменными, что позволяет не только предсказывать будущие события, но и понимать, почему они происходят. Такой подход критически важен для областей, где требуется не просто точный прогноз, но и возможность вмешательства и контроля над ситуацией. Благодаря способности явно моделировать причинные механизмы, LCM обеспечивают более высокую степень прозрачности и объяснимости, что способствует укреплению доверия к принимаемым решениям и позволяет избежать нежелательных последствий, связанных с «черным ящиком» традиционных алгоритмов. Использование LCM позволяет перейти от простого наблюдения за связями к пониманию лежащих в их основе причин, открывая новые возможности для анализа и управления сложными системами.
Разработанные модели линейных причинных связей (LCM) открывают новые возможности для анализа и прогнозирования в различных областях науки. В климатологии, например, они позволяют не только выявлять корреляции между различными факторами, влияющими на изменение климата, но и устанавливать причинно-следственные связи, что критически важно для разработки эффективных стратегий адаптации и смягчения последствий. В эпидемиологии LCMs способствуют более точному моделированию распространения инфекционных заболеваний и оценке эффективности различных мер профилактики. В экономике эти модели позволяют выявлять ключевые факторы, определяющие экономический рост, и прогнозировать последствия различных политических решений, что позволяет разрабатывать более эффективные стратегии экономического планирования и управления рисками. Благодаря способности выявлять и учитывать причинные связи, LCMs значительно повышают точность прогнозов и позволяют разрабатывать более обоснованные и эффективные стратегии вмешательства в сложных системах.
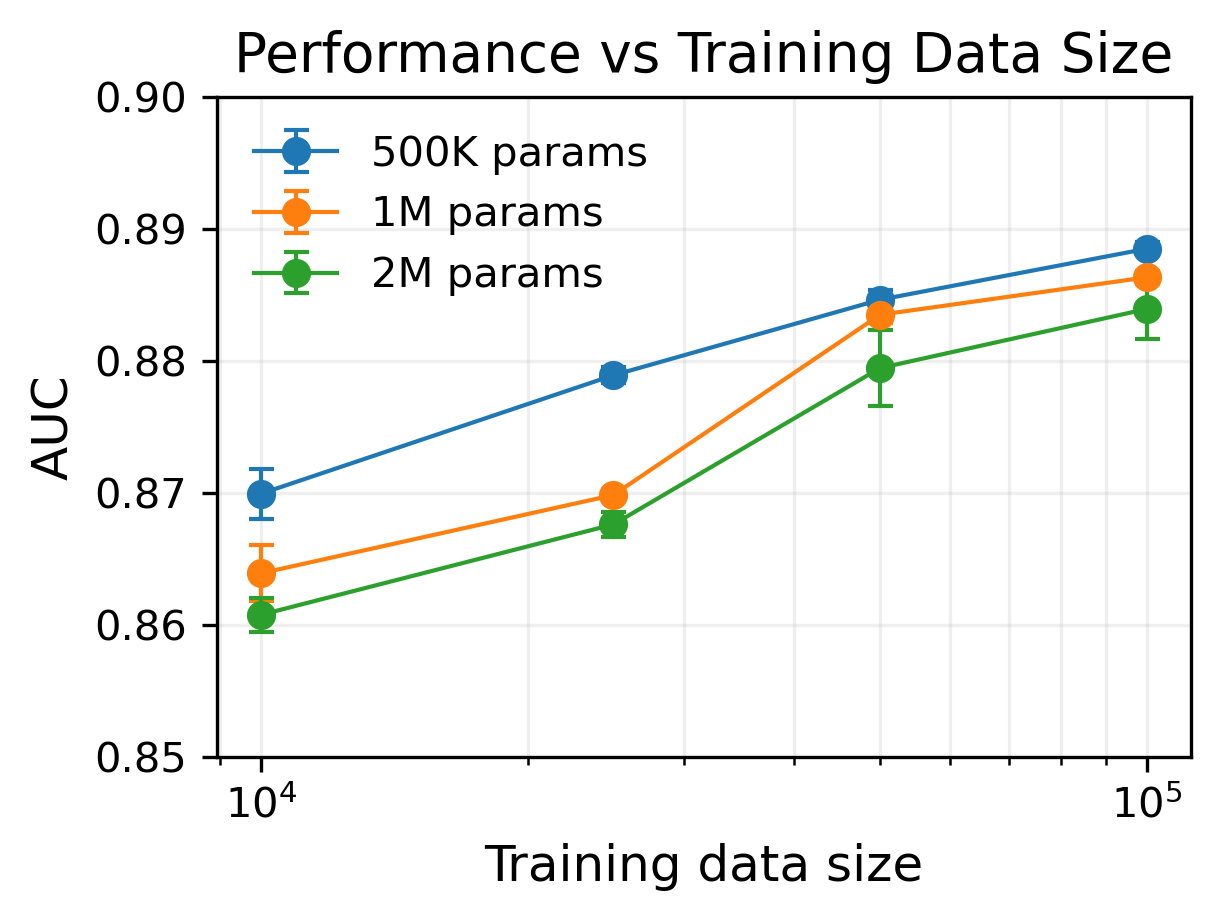
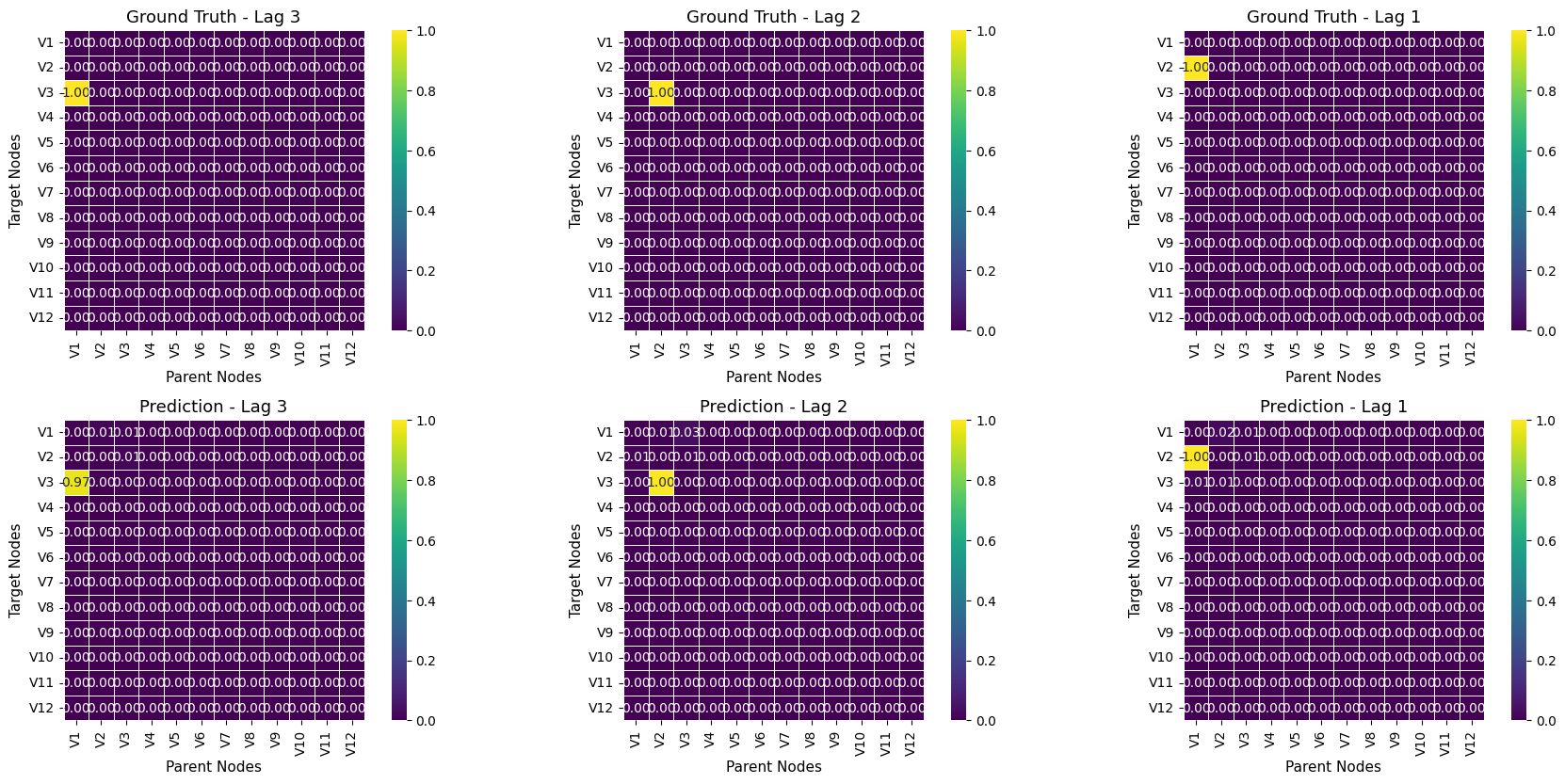
В настоящее время научные исследования направлены на расширение возможностей линейных причинных моделей (LCM), в частности, на повышение их масштабируемости, устойчивости и обобщающей способности. Особое внимание уделяется преодолению сложностей, возникающих при работе с многомерными и сложными данными. Показанная в исследованиях масштабируемость до V_{max} = 12 и l_{max} = 3 демонстрирует способность LCM эффективно обрабатывать переменное количество переменных и временные лаги. Улучшение этих характеристик позволит применять модели к более широкому спектру реальных задач, включая анализ сложных систем и прогнозирование в условиях неопределенности, открывая новые перспективы для их использования в различных областях науки и техники.
В перспективе, линейные причинные модели (LCM) призваны существенно расширить возможности принятия обоснованных решений и способствовать решению ключевых проблем, стоящих перед обществом. Их способность выявлять и учитывать причинно-следственные связи, а не просто корреляции, открывает новые горизонты в таких областях, как прогнозирование климатических изменений, разработка эффективных стратегий борьбы с эпидемиями и моделирование экономических процессов. Особенно важно, что LCM способны не только предсказывать, но и оценивать потенциальное влияние различных вмешательств, позволяя выбирать наиболее оптимальные решения для достижения желаемых результатов. Развитие и внедрение этих моделей представляет собой значительный шаг к созданию более надежных и ответственных систем искусственного интеллекта, способных приносить пользу человечеству.
В основе любого эффективного анализа временных рядов лежит строгое определение задачи. Без чёткого понимания причинно-следственных связей, любые выводы остаются лишь шумом. Данное исследование демонстрирует, что масштабирование методов обнаружения причинности возможно при использовании больших наборов данных и надёжной тренировки, что позволяет создавать фундаментальные модели, превосходящие традиционные подходы в обобщении. Как однажды заметил Джон фон Нейманн: «В науке не бывает случайностей, есть лишь неизвестные причинно-следственные связи». Эта мысль особенно актуальна в контексте представленной работы, где акцент делается на построении надёжных и доказуемых причинно-следственных графов, а не просто на эмпирической «работе на тестах».
Что Дальше?
Представленные модели, демонстрируя масштабируемость открытия причинно-следственных связей, не решают фундаментальной проблемы: гарантии корректности выстроенных графов. Успешная работа на тестовых данных — это лишь иллюзия, а истинная проверка — это математическая доказуемость алгоритма. В настоящее время, большинство методов, включая и представленные, полагаются на эвристики и приближения, что делает их уязвимыми к шуму и систематическим ошибкам в данных. Необходим переход от эмпирической проверки к формальной верификации.
Перспективы связаны с разработкой методов, способных не просто выявлять корреляции, но и устанавливать истинные причинно-следственные связи, устойчивые к искажениям и неполноте данных. Особенно актуально это для временных рядов, где проблема лага и обратной связи требует принципиально новых подходов. Вместо гонки за размером моделей, необходимо сосредоточиться на повышении их надежности и интерпретируемости.
В хаосе данных спасает только математическая дисциплина. Будущее открытия причинно-следственных связей лежит не в создании все более сложных нейронных сетей, а в разработке строгих математических инструментов, способных выделить причинную структуру из шума и неопределенности. Именно здесь, в математической чистоте алгоритмов, и кроется истинная элегантность и надежность.
Оригинал статьи: https://arxiv.org/pdf/2602.18662.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Разделяй и Властвуй: Новый Подход к Развёртке 3D-Моделей
- Оживший аватар: Генерация видео в реальном времени по голосу
- Серебро и медь: новый взгляд на наноаллои
- Самосознание в обучении: Модель вознаграждения, основанная на самоанализе
- Научные эксперименты с ИИ: новая платформа для проверки интеллекта
- Искусственный интеллект и квантовая физика: кто кого?
- Нейросети: проявление неклассической статистики?
- Пространственное мышление видео: новый подход к обучению ИИ
- Нейронные сети и астроциты: новый подход к обнаружению аномалий
2026-02-24 17:01