Автор: Денис Аветисян
Новое исследование выявило случаи появления сфабрикованных цитат, созданных искусственным интеллектом, в рецензируемых научных публикациях, ставя под угрозу достоверность академических исследований.
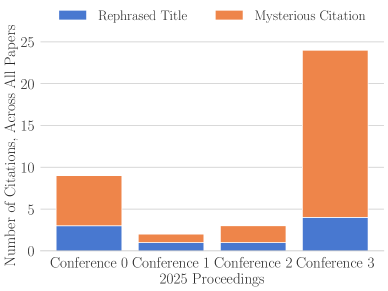
Эмпирическое исследование демонстрирует рост числа случаев фальсификации научных ссылок с использованием генеративных моделей и указывает на неэффективность существующих механизмов проверки подлинности.
Несмотря на строгие процедуры рецензирования, научная литература все чаще сталкивается с проблемой ложных цитирований. В работе «The Case of the Mysterious Citations» представлен анализ материалов четырех крупных конференций по высокопроизводительным вычислениям, выявивший появление сфабрикованных ссылок в публикациях 2025 года — от 2 до 6% от общего числа работ. Полученные данные свидетельствуют о росте числа ошибок в названиях и авторстве статей, что указывает на необходимость усиления практики верификации ссылок и выявления случаев использования ИИ для генерации библиографии. Недостаточно ли текущие политики конференций, требующие от авторов указывать использование инструментов ИИ, если ни один из авторов в исследуемой выборке этого не сделал?
Взлом Реальности: Подъем LLM и Угроза Академической Честности
В последнее время наблюдается стремительное развитие больших языковых моделей (БЯМ), таких как ChatGPT, которые стали мощными инструментами для генерации и обобщения текста. Эти модели кардинально меняют привычные рабочие процессы во многих областях, от написания отчетов и создания контента до автоматизации рутинных задач. Способность БЯМ быстро обрабатывать большие объемы информации и создавать связные тексты позволяет значительно повысить производительность и эффективность работы специалистов в различных сферах деятельности. При этом, БЯМ активно внедряются в научные исследования, помогая ученым анализировать данные, формулировать гипотезы и даже писать черновики научных статей, что открывает новые возможности для развития науки и технологий.
Современные большие языковые модели, несмотря на свою полезность в обработке и генерации текста, демонстрируют склонность к так называемым “галлюцинациям” — созданию правдоподобной, но фактически неверной информации. Эта особенность проявляется и в академической сфере, где модели могут генерировать не существующие цитаты или искажать информацию из реальных источников. Создаваемые ими ссылки выглядят убедительно, что затрудняет их обнаружение и представляет серьезную угрозу для достоверности научных исследований. Несмотря на кажущуюся логичность, такие “галлюцинации” являются результатом статистического характера работы моделей, которые предсказывают наиболее вероятные последовательности слов, а не проверяют фактическую точность информации.
В последнее время наблюдается тревожная тенденция: распространение так называемых «галлюцинаций» в академических публикациях, когда языковые модели генерируют правдоподобные, но ложные цитаты и источники. Эмпирические исследования демонстрируют, что в некоторых научных областях до 6% опубликованных статей содержат подобные ошибки. Данное явление представляет серьезную угрозу для целостности научной работы и эффективности экспертной оценки, поскольку искажает картину существующих знаний и затрудняет проверку достоверности представленных данных. Подобные ошибки не только подрывают доверие к научным результатам, но и создают риск для репутации исследователей и журналов, публикующих такие работы.
Существующие методы проверки цитирований сталкиваются с серьезными трудностями в борьбе с растущим объемом и утонченностью ошибок, вносимых большими языковыми моделями. Традиционные системы, основанные на сопоставлении метаданных и поиске по базам данных, часто оказываются неспособны выявить фальсификации, когда сгенерированные LLM цитаты выглядят правдоподобно, но не соответствуют действительности или указывают на несуществующие источники. Проблема усугубляется тем, что LLM способны не только выдумывать источники, но и искажать существующие, создавая цитаты, которые лишь частично соответствуют оригинальному тексту. В результате, даже тщательная проверка вручную становится все более трудоемкой и требует значительных временных затрат, не гарантируя при этом полной защиты от фальсификаций, что создает серьезную угрозу для достоверности научных публикаций и процесса рецензирования.
Анатомия Обмана: Как LLM Генерируют Ошибки в Цитировании
Большие языковые модели (LLM) не обладают пониманием концепции цитирования; они генерируют текст, предсказывая следующую лексему в последовательности, основываясь на данных, полученных в процессе обучения. Это означает, что LLM способны воспроизводить форматы цитирования, встречавшиеся в обучающем наборе данных, но не проводят фактическую проверку точности информации, которую они включают в цитату. В результате, модели могут генерировать цитаты, которые выглядят правдоподобно, но не соответствуют реальным источникам или содержат неверные данные, поскольку процесс генерации основывается исключительно на статистическом анализе и прогнозировании, а не на семантическом понимании.
Извлечение информации для цитирования из исходных текстов осуществляется посредством применения эвристических методов поиска подстрок и регулярных выражений к обработанному тексту. Инструменты, такие как ParsePDF из библиотеки PyPDF, используются для извлечения текстовых данных из PDF-документов, которые затем подвергаются анализу. В процессе поиска релевантной информации, алгоритмы ищут определенные шаблоны, соответствующие элементам цитирования (авторы, заголовки, даты публикации и т.д.). Эффективность данного подхода напрямую зависит от качества форматирования исходного текста и корректности заданных шаблонов поиска.
Методы извлечения информации из библиографических ссылок, такие как поиск по строкам и регулярные выражения, демонстрируют высокую эффективность при работе с хорошо структурированными данными. Однако, при обработке сложных или некачественно отформатированных PDF-документов, эти методы становятся уязвимыми к ошибкам. Некорректное распознавание символов, нарушение структуры текста, наличие таблиц или колонок, а также низкое качество сканирования приводят к неточностям при извлечении деталей цитирования, включая имена авторов, названия публикаций, даты и номера страниц. В результате, даже при использовании современных инструментов, таких как PyPDF’s ParsePDF, извлеченные данные могут содержать ошибки, которые впоследствии влияют на точность генерируемых LLM ссылок.
Языковые модели (LLM) усугубляют первоначальные неточности, возникающие при извлечении цитат, создавая правдоподобные, но полностью вымышленные ссылки. Этот процесс происходит из-за того, что LLM предсказывают следующий элемент последовательности на основе обучающих данных, не проверяя фактическую достоверность информации. В результате, даже небольшие ошибки в исходных данных могут быть значительно усилены, приводя к созданию цитат, которые кажутся убедительными при поверхностной проверке, но не имеют реального подтверждения в научных источниках. Такая способность LLM к генерации правдоподобной, но ложной информации представляет серьезную проблему для обеспечения достоверности научных исследований и требует разработки более надежных методов верификации цитат.
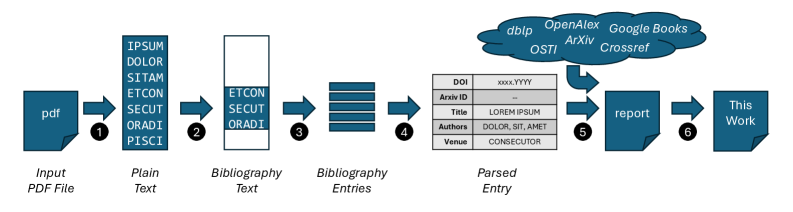
Автоматический Контроль: Инструменты и Источники Данных для Выявления Поддельных Цитирований
Автоматизированные инструменты проверки цитирований играют критически важную роль в борьбе с распространением “галлюцинаторных цитат” — ложных или выдуманных ссылок, генерируемых языковыми моделями. Однако, эффективность этих инструментов напрямую зависит от доступа к достоверным и актуальным источникам данных. Отсутствие или неполнота информации в базах данных приводит к невозможности верификации цитирований и, следовательно, к ложноотрицательным результатам. Поэтому, для обеспечения надежности проверки, необходима интеграция с несколькими авторитетными источниками и постоянное обновление данных.
Для автоматизированной проверки цитирований используются авторитетные базы данных научных публикаций, такие как Crossref, OpenAlex и dblp. Crossref предоставляет информацию о DOI (цифровых идентификаторах объектов) и метаданные, позволяя верифицировать корректность ссылок на опубликованные работы. OpenAlex, будучи открытой базой данных, предлагает широкие возможности для поиска и анализа научных публикаций и их библиографических связей. Dblp специализируется на публикациях в области информатики и предоставляет исчерпывающую информацию о трудах в данной области. Эти базы данных позволяют инструментам автоматической проверки сопоставлять цитируемые работы с их фактическими метаданными, включая авторов, заголовки, журналы и даты публикации, тем самым выявляя несоответствия и потенциально сфабрикованные цитирования.
Несмотря на наличие авторитетных баз данных научных публикаций, таких как Crossref, OpenAlex и dblp, они не охватывают все существующие научные работы. Большие языковые модели (LLM) способны генерировать правдоподобные ссылки на препринты, размещенные на платформах вроде ArXiv, которые могут быть еще не проиндексированы в этих базах. Это создает проблему, поскольку LLM может сгенерировать цитату, которая выглядит корректной, но фактически не соответствует опубликованной работе или содержит неверные данные, поскольку препринт еще не прошел процедуру рецензирования или не был опубликован в официальном издании.
Для обеспечения корректной верификации цитирований, автоматизированные инструменты должны учитывать разнообразие стилей оформления ссылок (например, APA, MLA, Chicago), поскольку единый стандарт не всегда соблюдается в научных публикациях. Кроме того, необходимо предусматривать обработку ошибок и опечаток, встречающихся в исходных материалах, включая неточности в названиях авторов, названии публикации или дате издания. Неспособность учитывать эти вариации и ошибки может приводить к ложноположительным или ложноотрицательным результатам при проверке достоверности цитирования, снижая общую эффективность системы верификации.
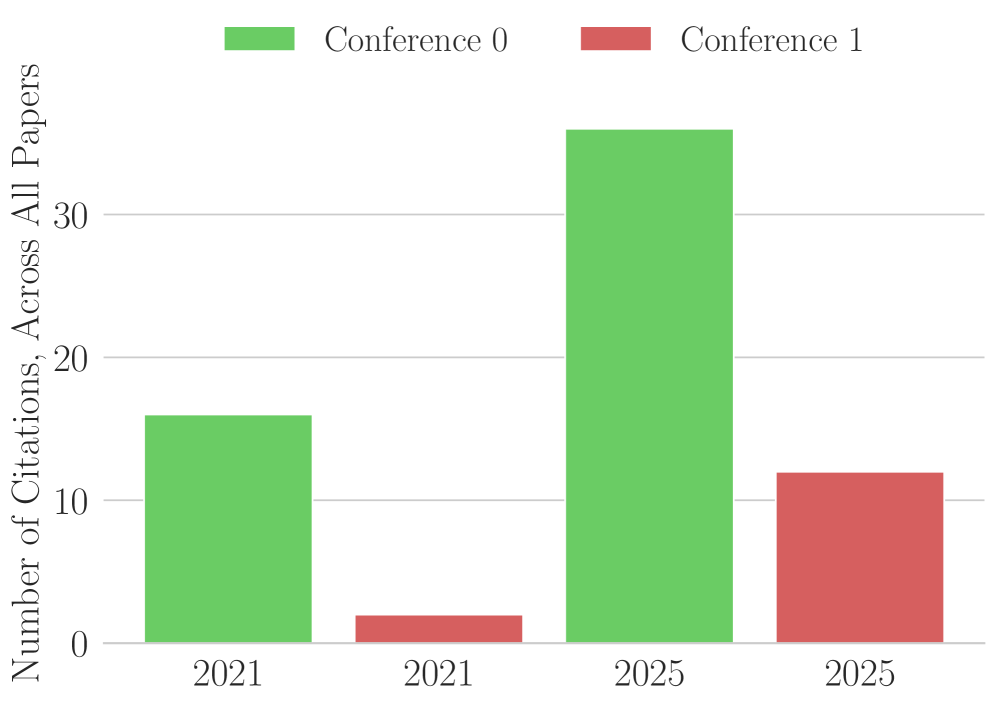
Оценка Воздействия: Ошибки в Цитировании в HPC и За Его Пределами
Анализ библиографических ссылок в материалах конференций, посвященных высокопроизводительным вычислениям (HPC), выявил тревожную тенденцию — распространение фальсифицированных источников. Исследование показало, что даже в узкоспециализированных областях науки, таких как HPC, существует значительная уязвимость к намеренному или случайному искажению научной литературы. Эта проблема не ограничивается единичными случаями, а представляет собой системную угрозу для достоверности исследований и оценки вклада ученых. Выявление ложных ссылок указывает на необходимость разработки более эффективных механизмов проверки и контроля качества научных публикаций, а также на важность повышения осведомленности исследователей о принципах академической честности.
Ошибки в библиографических ссылках, выявляемые в научных публикациях, не ограничиваются лишь компрометацией конкретной работы. Они способны искажать общую картину исследований, создавая ложное представление о вкладе отдельных ученых и направляя научные дискуссии по ошибочным путям. Искажение цитирования может приводить к завышению значимости работ, не заслуживающих внимания, и, напротив, к игнорированию действительно ценных исследований, тем самым нарушая объективную оценку научного прогресса. Подобные манипуляции подрывают доверие к научному сообществу и создают препятствия для развития объективных знаний, поскольку оценка качества исследований и репутации ученых становится зависимой от недобросовестных практик.
Особую тревогу вызывает обнаружение сфабрикованных цитат в исследованиях, оценивающих качество конференций в области высокопроизводительных вычислений (HPC), таких как рейтинги ERA Conference Rankings. Искажение данных в этих оценках напрямую влияет на академические показатели и репутацию ученых, поскольку рейтинги используются для оценки эффективности исследовательских групп и при принятии решений о финансировании. Наличие ложных ссылок может искусственно завышать или занижать значимость конкретных конференций, вводя в заблуждение как исследователей, выбирающих площадки для публикации, так и организации, ответственные за распределение ресурсов. Таким образом, подрыв целостности оценок качества конференций создает серьезные препятствия для объективной оценки научных достижений и справедливого распределения финансирования в сфере HPC.
Анализ выборки работ, представленных на конференцию ICLR 2026, выявил тревожную тенденцию: у 20% статей обнаружены хотя бы одна цитата, сгенерированная искусственным интеллектом и не имеющая аналогов в реальности. Более того, сканирование 50 работ с помощью инструмента GPTZero подтвердило наличие сфабрикованных ссылок как минимум в половине из них. Это свидетельствует о значительном уровне неточностей, возникающих при использовании больших языковых моделей для создания научных текстов, и подчеркивает необходимость разработки эффективных методов верификации цитируемой литературы для обеспечения достоверности научных публикаций.
![Данные, представленные в публикации на ResearchGate, цитируемой в материалах Конференции 3, демонстрируют [латекс]...[/латекс] (далее следует описание данных, которое отсутствует в исходном тексте).](https://arxiv.org/html/2602.05867v1/fake_paper.png)
Навигация в Будущем: Политики Использования Генеративного ИИ и Ответственная Наука
Академическая сфера активно адаптируется к появлению генеративного искусственного интеллекта, разрабатывая специальные политики, регламентирующие его использование. Эти политики, внедряемые издательствами и научными организациями, направлены на установление четких правил для авторов и исследователей. В них подчеркивается необходимость осознанного подхода к применению инструментов ИИ, а также определяются границы допустимого использования, чтобы обеспечить целостность и достоверность научных публикаций. Особое внимание уделяется предотвращению плагиата и фальсификации данных, что требует от авторов внимательного контроля и проверки генерируемого контента. Разработка и внедрение таких политик — это важный шаг к поддержанию высоких стандартов научной этики в эпоху стремительного развития технологий.
Политики, разрабатываемые в академической среде в связи с распространением генеративного искусственного интеллекта, делают особый акцент на прозрачности научной коммуникации. Авторам теперь требуется четко указывать случаи использования больших языковых моделей (LLM) при создании работ, что позволяет оценить степень участия ИИ в исследовании. Наряду с этим, возложена ответственность за тщательную проверку достоверности всех цитат и ссылок, поскольку автоматизированные инструменты верификации цитирования находятся в стадии разработки и не всегда способны обеспечить полную надежность. Такой подход призван не только выявить возможные неточности, но и сформировать культуру ответственного научного поиска, где точность и открытость являются основополагающими принципами.
Непрерывное совершенствование автоматизированных инструментов проверки цитирования представляется критически важным для сохранения целостности научных исследований. Эти системы, опираясь на надежные и обширные базы данных, способны выявлять неточности, фальсификации и несоответствия в библиографических ссылках. Однако, технической реализации недостаточно; параллельно необходимо разработать четкие этические принципы и руководства, определяющие допустимые границы использования подобных инструментов и обеспечивающие защиту авторских прав. Интеграция этих технических и этических аспектов позволит создать надежный механизм, способный эффективно противодействовать распространению недостоверной информации и поддерживать высокий уровень доверия к научным публикациям, что особенно актуально в эпоху быстрого развития генеративного искусственного интеллекта.
В конечном счете, наиболее эффективной защитой от фальсификации цитат является культивирование ответственного научного подхода, в котором точность и прозрачность являются первостепенными ценностями. Недостаточно полагаться лишь на технические инструменты проверки, такие как автоматизированные системы верификации, поскольку они могут быть обойдены или содержать ошибки. Подлинная защита заключается в формировании у исследователей глубокого понимания этических принципов научной работы и личной ответственности за достоверность представляемых данных. Внедрение образовательных программ, стимулирующих критическое мышление и осознанное отношение к источникам информации, а также поощрение открытости и готовности к проверке, способствуют созданию научной среды, в которой фальсификации становятся невозможными и нежелательными. Такая культура, основанная на взаимном доверии и стремлении к истине, является залогом сохранения целостности и авторитета академического сообщества.
Исследование выявляет тревожную тенденцию: искусственный интеллект способен генерировать не только правдоподобные тексты, но и фальсифицированные ссылки на научные работы. Это ставит под вопрос надёжность текущих механизмов рецензирования и контроля качества научных публикаций. Как говорил Алан Тьюринг: «Иногда люди, которые кажутся сумасшедшими, просто видят вещи, которые другие не могут». Подобная «слепота» научного сообщества к проблеме фальсифицированных цитат может привести к серьёзным последствиям, искажая картину научных знаний и подрывая доверие к академической среде. Обнаружение подобных ‘эксплойтов’ в системе академической публикации требует новых подходов к проверке достоверности информации и переосмысления роли рецензирования.
Куда Ведет Этот Кроличий След?
Представленные данные заставляют задуматься: а не является ли кажущаяся «галлюцинация» больших языковых моделей не багом, а скорее, сигналом о более глубоких проблемах в самой структуре научной коммуникации? Традиционные методы проверки ссылок, как показывает практика, оказываются неспособными выявлять искусственно созданные цитаты, что ставит под вопрос надежность всей системы рецензирования. Не является ли эта ситуация отражением нездоровой зависимости от метрик цитирования, когда количество важнее качества?
Вместо того, чтобы сосредоточиться исключительно на разработке алгоритмов обнаружения «подделок», представляется необходимым переосмыслить принципы оценки научных работ. Возможно, стоит обратить внимание на более качественные показатели, такие как воспроизводимость результатов, независимые подтверждения и глубина анализа, а не на поверхностное количество ссылок. Или же, стоит признать, что в эпоху машинного создания контента, сама концепция «оригинальности» нуждается в пересмотре?
Будущие исследования должны быть направлены не только на выявление сфабрикованных цитат, но и на изучение мотивации их создателей. Является ли это сознательным обманом, результатом давления публикаций, или же просто небрежностью и недостаточным контролем? Ответ на этот вопрос может оказаться ключом к построению более честной и надежной научной среды. Возможно, баг — это не ошибка, а приглашение к реинжинирингу реальности.
Оригинал статьи: https://arxiv.org/pdf/2602.05867.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Графы и действия: новый подход к планированию для роботов
- Bibby AI: Новый помощник для исследователей в LaTeX
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Квантовые амбиции: Иран вступает в гонку
- Диффузия против Квантов: Новый Взгляд на Факторизацию
- Федеративное обучение: баланс между конфиденциальностью и скоростью
- Многокритериальная оптимизация: взгляд на народные методы
2026-02-07 22:30