Автор: Денис Аветисян
Новый подход к построению аппаратных ускорителей глубокого обучения обеспечивает высокую производительность и энергоэффективность за счет трехмерной организации данных и оптимизации доступа к памяти.

Представлен Voltra, чип для ускорения глубоких нейронных сетей, использующий 3D-массив, общую память и продвинутые методы предварительной выборки данных для достижения высокой энергоэффективности и использования в различных рабочих нагрузках.
Достижение высокой вычислительной эффективности при работе с разнообразными задачами искусственного интеллекта остается сложной задачей. В данной работе, посвященной разработке ‘A 16 nm 1.60TOPS/W High Utilization DNN Accelerator with 3D Spatial Data Reuse and Efficient Shared Memory Access’, представлен чип Voltra — специализированный ускоритель глубоких нейронных сетей (DNN), использующий трехмерное пространственное повторное использование данных и эффективный доступ к общей памяти. Внедрение трехмерного потока данных и гибких механизмов предварительной выборки позволило добиться увеличения энергоэффективности до 1.60 TOPS/W и улучшения временной эффективности на 2.12-2.94x. Позволит ли данная архитектура существенно расширить возможности аппаратного ускорения DNN-приложений и снизить энергопотребление в системах искусственного интеллекта?
Узкое Место Современных Глубоких Нейросетей
Глубокие нейронные сети, несмотря на свою впечатляющую способность решать сложные задачи, зачастую сталкиваются с ограничениями, обусловленными пропускной способностью памяти и вычислительными затратами. По мере усложнения рабочих нагрузок и увеличения объемов обрабатываемых данных, эти ограничения становятся все более заметными, сдерживая дальнейший прогресс в области искусственного интеллекта. Недостаточная пропускная способность памяти приводит к задержкам при передаче данных между памятью и вычислительными блоками, а высокие вычислительные затраты требуют значительных энергетических ресурсов и времени для выполнения операций. Это создает «узкое место», которое препятствует эффективному использованию потенциала глубоких нейронных сетей и требует поиска новых архитектур и алгоритмов, способных преодолеть эти ограничения.
Традиционные пространственные архитектуры массивов, такие как двумерный пространственный массив, сталкиваются с трудностями в эффективном использовании внутрикристальных ресурсов из-за разнообразия паттернов доступа к данным. В этих архитектурах, данные обрабатываются последовательно, что приводит к узким местам при работе с задачами, требующими нерегулярного доступа к памяти. Неспособность адаптироваться к различным схемам чтения и записи данных снижает общую производительность и энергоэффективность, особенно при обработке больших объемов информации и выполнении сложных вычислений. Ограниченность в гибкости и масштабируемости делает существующие подходы менее эффективными для современных задач глубокого обучения, требующих одновременной обработки разнообразных данных и высокой пропускной способности.
Растущий спрос на высокопроизводительные вычисления при выводе данных стимулирует разработку инновационных подходов к организации потока данных и памяти. Традиционные архитектуры испытывают трудности при обработке больших объемов информации, необходимых для современных нейронных сетей. Новые решения направлены на оптимизацию доступа к памяти и минимизацию перемещения данных, что позволяет значительно повысить эффективность вычислений и снизить энергопотребление. Исследования в этой области сосредоточены на разработке специализированных архитектур и алгоритмов, позволяющих максимально эффективно использовать доступные ресурсы и удовлетворить растущие потребности в высокопроизводительном выводе данных для различных приложений, включая обработку изображений, распознавание речи и машинный перевод.
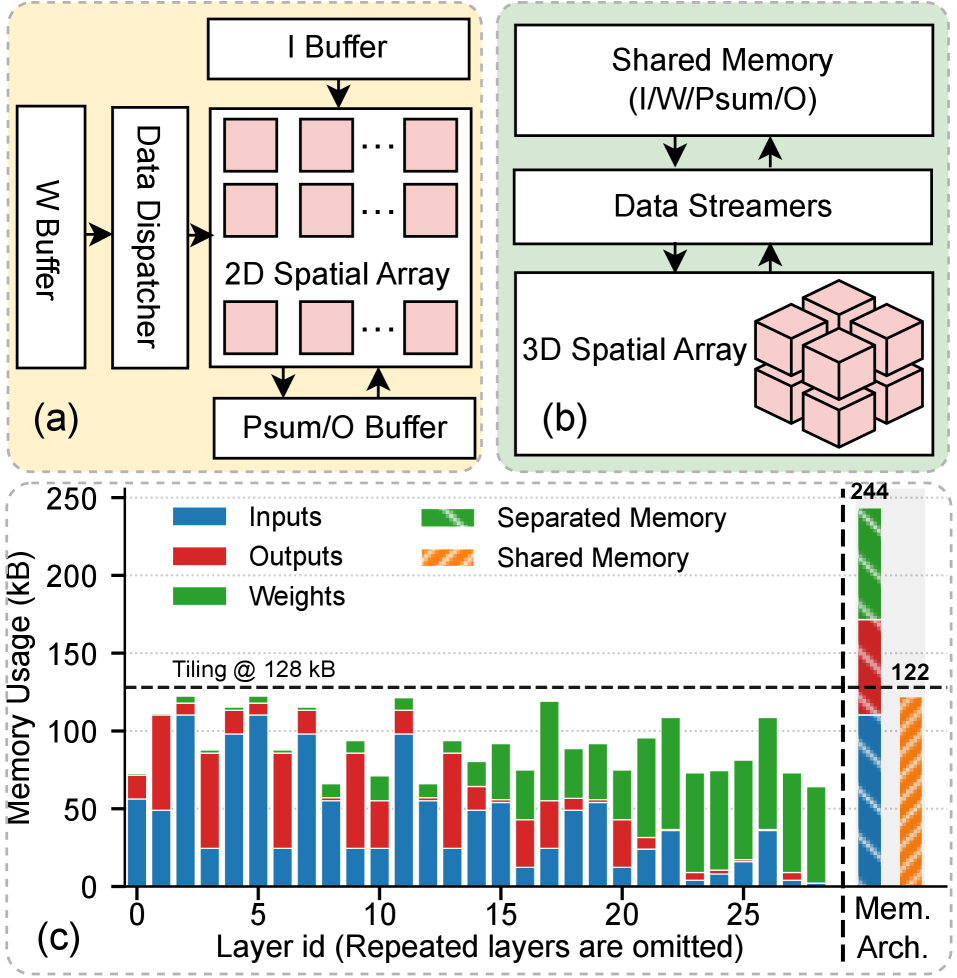
Voltra: Трехмерная Пространственная Архитектура
Архитектура Voltra использует трехмерную пространственную матрицу (3D Spatial Array) для балансировки развертки вычислений по трем измерениям. Такой подход позволяет достичь более высокой пропускной способности и улучшенной пространственной утилизации по сравнению с двухмерной (2D) пространственной матрицей. В частности, заявлено увеличение эффективности пространственного использования до 2.0×, что обусловлено возможностью более плотной компоновки вычислительных элементов и оптимизацией путей передачи данных в трехмерном пространстве.
Архитектура с общей памятью в Voltra обеспечивает гибкое разделение и повторное использование данных внутри чипа, что позволяет адаптироваться к различным требованиям разных слоев нейронных сетей (DNN). Вместо фиксированного распределения памяти, система динамически выделяет и перераспределяет ресурсы памяти в зависимости от потребностей конкретного слоя, оптимизируя использование пропускной способности и снижая задержки. Такой подход позволяет эффективно использовать ограниченные ресурсы памяти, особенно при обработке DNN с разнородными слоями, требующими разного объема памяти для хранения весов и активаций. Гибкость архитектуры позволяет избежать узких мест, возникающих при жестком разделении памяти, и повысить общую производительность ускорителя.
В архитектуре Voltra используется RISC-V Snitch Core для обеспечения точного управления потоком данных и координации работы функциональных блоков ускорителя. Этот процессор RISC-V выступает в роли центрального контроллера, определяя последовательность операций, распределение данных между различными блоками и синхронизацию их работы. Snitch Core позволяет динамически адаптировать процесс обработки данных к специфическим требованиям каждого слоя нейронной сети, оптимизируя использование ресурсов и повышая общую производительность. Это достигается за счет гибкой настройки параметров потока данных и управления доступом к памяти, что обеспечивает эффективное выполнение вычислительных задач.
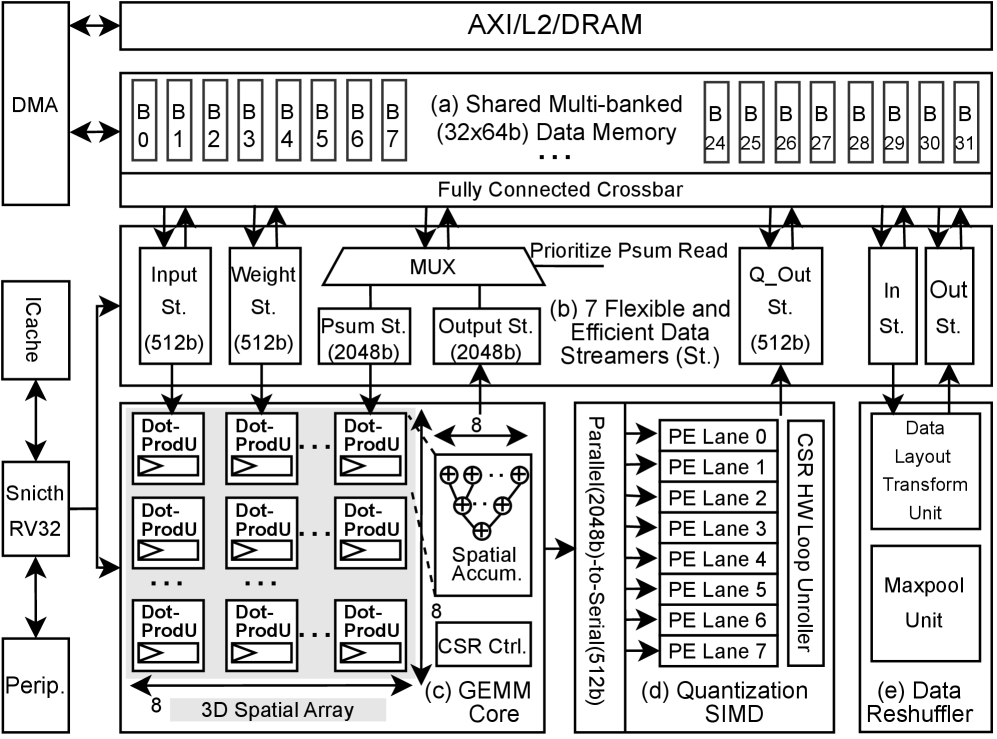
Оптимизация Потока Данных и Доступа к Памяти
В Voltra реализована технология предиктивной предварительной выборки данных (Mixed-Grained Data Prefetching) с использованием FIFO-очередей. Данный подход позволяет проактивно загружать данные в кэш до того, как они потребуются вычислительным блокам, эффективно скрывая задержки, связанные с доступом к памяти. Использование FIFO обеспечивает последовательную выдачу данных, поддерживая непрерывный поток информации и минимизируя простои, вызванные ожиданием данных. Это особенно важно для приложений, интенсивно работающих с памятью, и позволяет значительно повысить общую производительность системы.
Программируемое динамическое распределение памяти в Voltra позволяет чипу адаптироваться к особенностям рабочей нагрузки, оптимизируя использование памяти и снижая объем перемещения данных. В отличие от статического распределения, данная система позволяет гибко назначать память различным вычислительным блокам в процессе выполнения программы, основываясь на текущих потребностях. Это достигается за счет анализа характеристик данных и алгоритмов, что позволяет минимизировать фрагментацию памяти и уменьшить количество операций записи/чтения. Динамическое распределение также обеспечивает более эффективное использование ограниченных ресурсов памяти, особенно в сценариях с переменной интенсивностью вычислений и сложными структурами данных.
Ядро GEMM использует архитектуру потоковой обработки данных с сохранением выходных данных (Output-Stationary Dataflow), что максимизирует повторное использование временных данных и минимизирует обращения к частичным суммам, критически важным для эффективного выполнения операций матричного умножения. Данный подход позволяет значительно снизить общую задержку вычислений на 1.15-2.36 раза по сравнению с архитектурами, использующими раздельные структуры памяти. Это достигается за счет сохранения результатов промежуточных вычислений в локальной памяти ядра, что уменьшает необходимость в постоянном обмене данными с внешней памятью и, следовательно, снижает задержки, связанные с обменом данными.
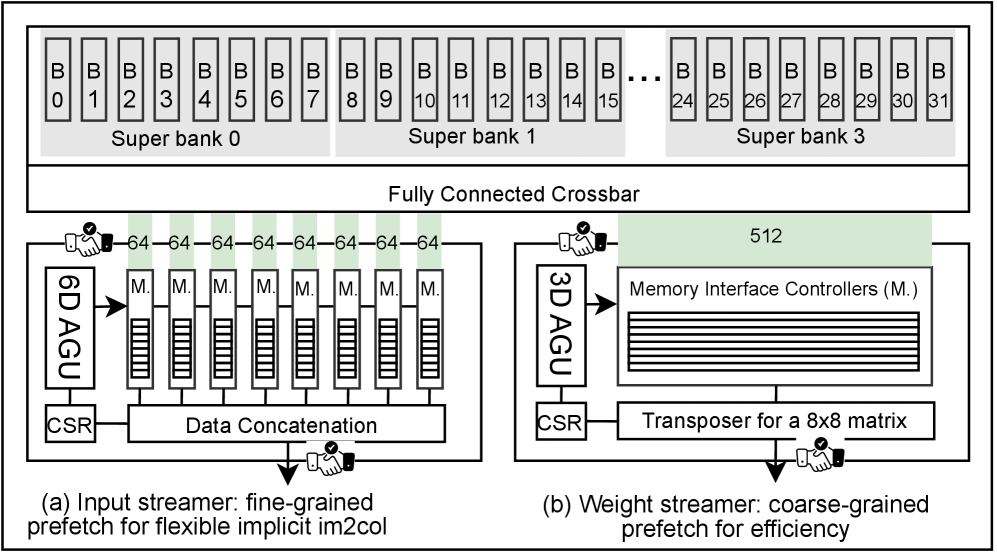
Для обеспечения гибкого и эффективного доступа к общей памяти в Voltra используются потоковые процессоры (Data Streamers), работающие в связке с блоком генерации адресов (Address Generation Unit). Эта архитектура позволяет динамически формировать запросы к памяти, оптимизируя порядок и способ доступа к данным. Блок генерации адресов отвечает за расчет физических адресов памяти на основе логических адресов, поступающих от потоковых процессоров, что позволяет минимизировать задержки и максимизировать пропускную способность. Совместная работа этих компонентов обеспечивает высокую эффективность при обработке больших объемов данных и позволяет адаптироваться к различным шаблонам доступа к памяти, что критически важно для повышения общей производительности системы.
Подтверждение Эффективности и Широкая Применимость
Исследования, проведенные с использованием сверточных нейронных сетей (CNN), рекуррентных нейронных сетей (RNN) и трансформеров, продемонстрировали существенное увеличение производительности Voltra по сравнению с традиционными ускорителями. В ходе экспериментов зафиксировано значительное ускорение обработки данных в различных типах нейронных сетей, что подтверждает эффективность новой архитектуры в задачах искусственного интеллекта. Данные результаты указывают на то, что Voltra способна эффективно обрабатывать широкий спектр современных моделей машинного обучения, предоставляя значительные преимущества в скорости и энергоэффективности по сравнению с существующими решениями.
Архитектура Voltra предусматривает поддержку разреженности данных, что позволяет существенно снизить вычислительные затраты и энергопотребление без потери точности. Этот подход основан на исключении из вычислений нулевых или незначимых значений, что позволяет сократить объем необходимых операций и, как следствие, уменьшить потребление энергии. Реализация разреженности в Voltra позволяет эффективно использовать вычислительные ресурсы, концентрируясь на значимых данных, и достигать высокой производительности при минимальном энергопотреблении. Такой подход особенно важен для задач машинного обучения, где разреженные представления данных являются распространенной практикой и могут значительно ускорить процесс обучения и инференса.
Архитектура Voltra включает в себя специализированный модуль транспонирования данных, значительно расширяющий возможности чипа по обработке информации, представленной в различных форматах. Данный модуль позволяет эффективно преобразовывать структуру данных «на лету», избегая дорогостоящих операций копирования и переупорядочивания в памяти. Это особенно важно при работе с разнообразными нейросетевыми моделями, каждая из которых может требовать определенный формат входных данных. Благодаря транспонированию, Voltra демонстрирует повышенную гибкость и совместимость с широким спектром алгоритмов машинного обучения, позволяя оптимизировать производительность и снизить задержки при обработке данных различной структуры.
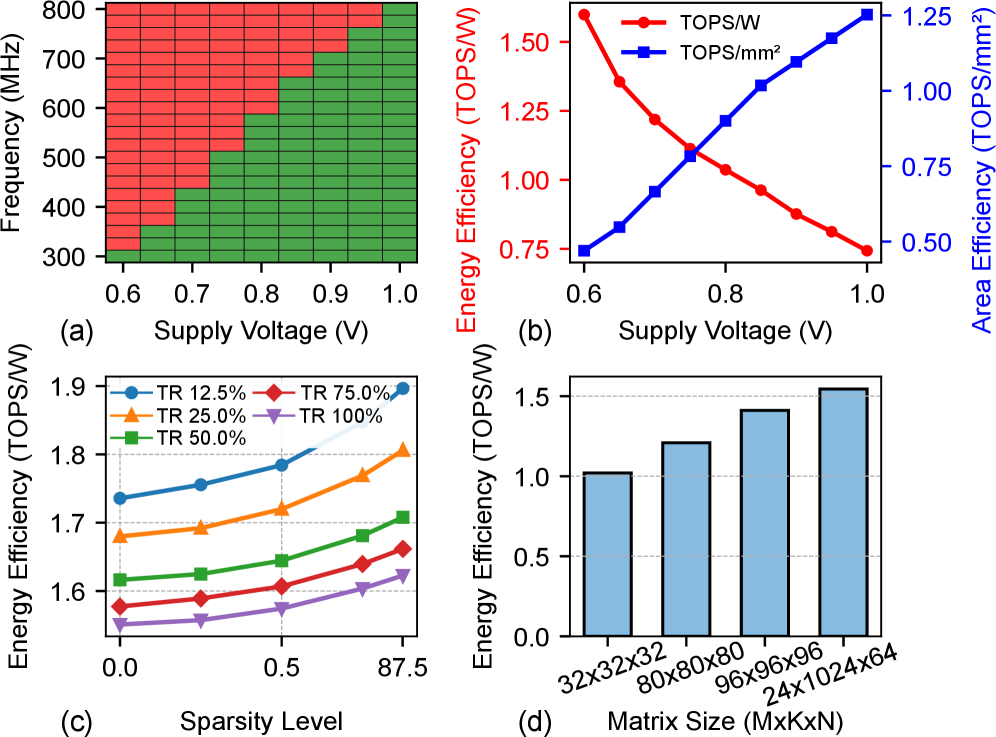
Разработанный чип Voltra, изготовленный по 16-нанометровой технологии FinFET, демонстрирует выдающиеся показатели эффективности. Пиковая системная энергоэффективность достигает 1.60 TOPS/W, что свидетельствует о минимальных затратах энергии на единицу производительности. Кроме того, Voltra отличается высокой плотностью размещения компонентов, обеспечивая 1.25 TOPS/mm² системной площади. Инновационное применение временного мультиплексирования позволило значительно сократить занимаемую площадь SIMD-блоков в 4.92 раза и площадь кроссбаров в 1.46 раза, что способствует дальнейшей миниатюризации и снижению энергопотребления устройства.
Исследование, представленное в данной работе, демонстрирует стремление к оптимизации аппаратных решений для задач глубокого обучения. Авторы предлагают Voltra — ускоритель, использующий 3D-массив и эффективный доступ к общей памяти для повышения энергоэффективности. Этот подход, направленный на максимальное использование ресурсов и минимизацию задержек, — закономерный шаг в развитии подобных систем. Как однажды заметил Брайан Керниган: «Простота — это высшая степень совершенства». В погоне за производительностью легко усложнить архитектуру до неузнаваемости, но истинная ценность заключается в элегантных решениях, способных обеспечить высокую эффективность при минимальных затратах. Похоже, Voltra стремится к этому балансу, фокусируясь на эффективном использовании существующих ресурсов, а не на бесконечном наращивании сложности.
Что дальше?
Представленное решение, как и все решения, лишь отодвигает проблему, а не решает её. Достижение 1.60TOPS/W — это, безусловно, приятно, но это всего лишь цифра в бесконечном гонке вооружений. Пока одни оптимизируют доступ к памяти, другие изобретают новые, ещё более прожорливые модели. Эта архитектура с трёхмерным массивом и продвинутым предвычислением данных, вероятно, продержится до тех пор, пока не появится следующая революционная парадигма, требующая полного пересмотра всей концепции аппаратного ускорения. Тесты, конечно, показывают отличные результаты, но это лишь форма надежды, а не гарантия стабильности в реальном мире.
Очевидным ограничением остаётся зависимость от конкретных рабочих нагрузок. Универсальности не существует. И даже если Voltra демонстрирует высокую эффективность на текущем наборе моделей, встреча с новой, непредсказуемой архитектурой нейронной сети, вероятно, заставит её попотеть. Поэтому, вместо погони за абсолютной производительностью, логичнее было бы сосредоточиться на разработке более гибких и адаптивных архитектур, способных динамически перестраиваться под изменяющиеся требования.
В конечном итоге, всё сводится к одному: любая «революционная» технология завтра станет техническим долгом. Продакшен всегда найдёт способ сломать элегантную теорию. И, скорее всего, следующий прорыв произойдёт не в области оптимизации аппаратного обеспечения, а в области алгоритмов и моделей машинного обучения, которые заставят нас переосмыслить всё, что мы знали о «производительности».
Оригинал статьи: https://arxiv.org/pdf/2602.11357.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Физика под контролем: Как «научить» модели понимать мир
- Квантовый скачок в обучении с учителем: новая архитектура для искусственного интеллекта
- Грань между Творчеством и Риском: Искусственный Интеллект и Эротический Контент
- Favia: Искусственный интеллект на страже безопасности кода
- Рассуждения на графах: как большие языковые модели учатся видеть мир
2026-02-16 03:40