Автор: Денис Аветисян
Новое исследование оценивает способность современных языковых моделей подтверждать факты, содержащиеся в базах знаний.
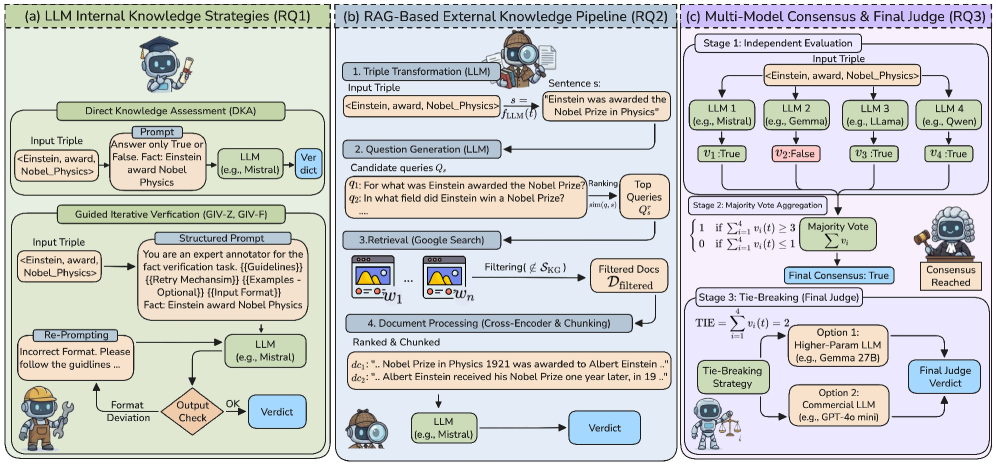
Представлен бенчмарк FactCheck для оценки возможностей больших языковых моделей в валидации фактов в графах знаний, демонстрирующий эффективность подхода Retrieval-Augmented Generation и консенсуса мультимодальных моделей.
Несмотря на широкое распространение баз знаний, представленных в виде графов, верификация фактов, содержащихся в них, остается сложной задачей. В данной работе, ‘Benchmarking Large Language Models for Knowledge Graph Validation’, представлен новый эталон FactCheck для оценки возможностей больших языковых моделей (LLM) в автоматической проверке фактов в графах знаний. Эксперименты показали, что хотя LLM демонстрируют перспективные результаты, их стабильность и надежность пока недостаточны для практического применения, а использование методов Retrieval-Augmented Generation и консенсусных стратегий не гарантирует существенного улучшения точности. Какие дальнейшие исследования необходимы для создания действительно надежных и масштабируемых систем проверки фактов в графах знаний на основе LLM?
Вызов точности: поддержание достоверности в графах знаний
Поддержание точности в постоянно растущих базах знаний (Knowledge Graphs, KGs) является фундаментальной задачей, сложность которой экспоненциально возрастает с увеличением объёма данных. Изначально, ручная проверка фактов была эффективна, однако, при масштабировании до миллионов и миллиардов утверждений, этот подход становится непрактичным и ресурсоёмким. Автоматические методы, хоть и предлагают решение, часто сталкиваются с неоднозначностью информации, неполнотой данных и необходимостью учитывать контекст. Чем больше фактов накапливается в KG, тем выше вероятность появления ошибок и противоречий, что снижает доверие к системе и ограничивает возможности ее применения в критически важных областях, таких как медицина или финансы. Поэтому, разработка эффективных и масштабируемых методов верификации фактов в KGs остается одной из ключевых проблем современной информатики.
Традиционные методы проверки фактов в огромных графах знаний сталкиваются со значительными трудностями из-за сложности и многогранности данных. Алгоритмы, основанные на логических правилах или статистическом анализе, зачастую не способны учесть контекст, неявные связи и тонкие семантические различия, присущие реальным знаниям. Например, фраза «Москва — столица России» легко верифицируется, но проверка утверждения о влиянии конкретного исторического события требует понимания причинно-следственных связей и учета различных интерпретаций. Простое сопоставление данных или поиск соответствий в базах данных оказывается недостаточным для выявления ложных или неточных фактов, особенно когда речь идет о сложных отношениях и субъективных оценках. Подобные ограничения делают автоматическую проверку фактов в графах знаний сложной задачей, требующей более продвинутых подходов, способных учитывать нюансы человеческого языка и рассуждений.
Появление больших языковых моделей (LLM) открывает новые перспективы в решении проблемы проверки фактов в масштабных графах знаний, однако не является безупречным решением. Эти модели, обученные на огромных объемах текстовых данных, способны оценивать правдоподобность утверждений, выявлять противоречия и даже генерировать доказательства, подтверждающие или опровергающие определенные факты. Несмотря на впечатляющие возможности, LLM подвержены галлюцинациям — генерации ложной информации, представленной как истинная — и могут быть уязвимы к предвзятостям, содержащимся в обучающих данных. Поэтому, хотя LLM значительно повышают эффективность валидации графов знаний, их использование требует осторожности и сочетания с другими методами проверки, чтобы обеспечить надежность и точность информации.
Расширение знаний: усиление LLM внешними источниками
Метод генерации с расширением знаний (Retrieval-Augmented Generation, RAG) существенно повышает точность больших языковых моделей (LLM) за счет привязки ответов к внешним источникам информации. Вместо полагания исключительно на собственные внутренние знания, RAG извлекает релевантные данные из внешних баз знаний во время генерации ответа. Этот процесс позволяет LLM предоставлять более достоверную и обоснованную информацию, а также снижает вероятность галлюцинаций и фактических ошибок. По сути, RAG дополняет возможности LLM, позволяя ему использовать обширный корпус внешних данных для формирования более точных и контекстуально релевантных ответов.
Механизм Retrieval-Augmented Generation (RAG) использует веб-поиск для предоставления языковым моделям (LLM) актуальной и релевантной информации, необходимой для верификации ответов. В процессе работы RAG осуществляет поиск в интернете по запросу пользователя, извлекает соответствующие фрагменты текста из найденных веб-страниц и использует эти данные в качестве контекста при генерации ответа. Это позволяет LLM не только опираться на свои внутренние знания, но и подтверждать факты внешними источниками, обеспечивая более точные и надежные результаты, особенно в случаях, когда требуется информация, выходящая за рамки его обучающего корпуса.
Использование подхода Retrieval-Augmented Generation (RAG) позволяет значительно расширить внутреннюю базу знаний языковой модели (LLM), обеспечивая более уверенную оценку фактов, содержащихся в графах знаний. В ходе тестирования на наборе данных FactBench, LLM, использующие RAG, демонстрируют показатель F1 до 0.89, что свидетельствует о высокой точности и полноте извлечения и оценки фактов из внешних источников и их интеграции с внутренней информацией модели. Это подтверждает эффективность RAG в задачах, требующих подтверждения достоверности информации и работы со структурированными данными.
Несмотря на более высокие вычислительные затраты, технология Retrieval-Augmented Generation (RAG) демонстрирует примерно десятикратное увеличение времени обработки по сравнению с прямой оценкой знаний (Direct Knowledge Assessment, DKA). При этом, прирост точности и достоверности ответов, обеспечиваемый RAG благодаря доступу к внешним источникам информации, оправдывает возросшие вычислительные требования. В частности, использование RAG позволяет значительно улучшить результаты на бенчмарках, оценивающих фактическую точность, и компенсировать ограничения, связанные с устаревшими или неполными данными, хранящимися во внутренних знаниях LLM.
Систематическая оценка с FactCheck
FactCheck представляет собой комплексный эталон для оценки больших языковых моделей (LLM) в задаче проверки фактов из знаний, представленных в виде графов знаний (KG). Он обеспечивает стандартизированную методологию и набор данных для количественной оценки способности LLM определять истинность или ложность утверждений, основанных на структурированных данных. Эталон позволяет сравнивать различные LLM по ключевым показателям точности, полноты и надежности в контексте проверки фактов, что критически важно для приложений, требующих высокой степени достоверности информации. В рамках FactCheck оценивается способность моделей к логическому выводу и сопоставлению информации из различных источников в KG.
Для оценки производительности больших языковых моделей (LLM) в задаче проверки фактов из базы знаний (KG), FactCheck использует разнородные наборы данных, включающие FactBench, YAGO и DBpedia. FactBench предоставляет комплексную коллекцию фактов и утверждений, YAGO — онтологию знаний, основанную на Википедии, а DBpedia — структурированные данные, извлеченные из Википедии. Использование этих различных источников данных позволяет оценить способность LLM к проверке фактов в широком спектре предметных областей и типов знаний, а также выявить потенциальные смещения или ограничения в их работе с различными структурами данных и представлениями знаний.
В рамках FactCheck проводится тщательный анализ ошибок, совершаемых языковыми моделями при проверке фактов из базы знаний. Этот анализ включает в себя категоризацию типов ошибок, таких как неверная интерпретация запроса, ошибки в извлечении информации из базы знаний, неспособность установить связь между фактами и запросом, а также генерация ложных утверждений. Классификация ошибок позволяет выявить слабые места моделей и определить направления для улучшения их точности и надежности в задачах проверки фактов. Результаты анализа используются для количественной оценки производительности моделей и сравнения их эффективности в различных сценариях.
Построение наборов данных является ключевым компонентом системы FactCheck, обеспечивающим качество и репрезентативность данных для оценки. Для этого используется многоэтапный процесс, включающий сбор фактов из различных авторитетных источников, таких как FactBench, YAGO и DBpedia. Проводится тщательная проверка и очистка данных для устранения неточностей и противоречий. Наборы данных конструируются таким образом, чтобы охватывать широкий спектр предметных областей и типов фактов, что позволяет всесторонне оценить возможности моделей в проверке знаний. Особое внимание уделяется балансу между позитивными и негативными примерами, а также разнообразию способов представления фактов, для избежания предвзятости при оценке.
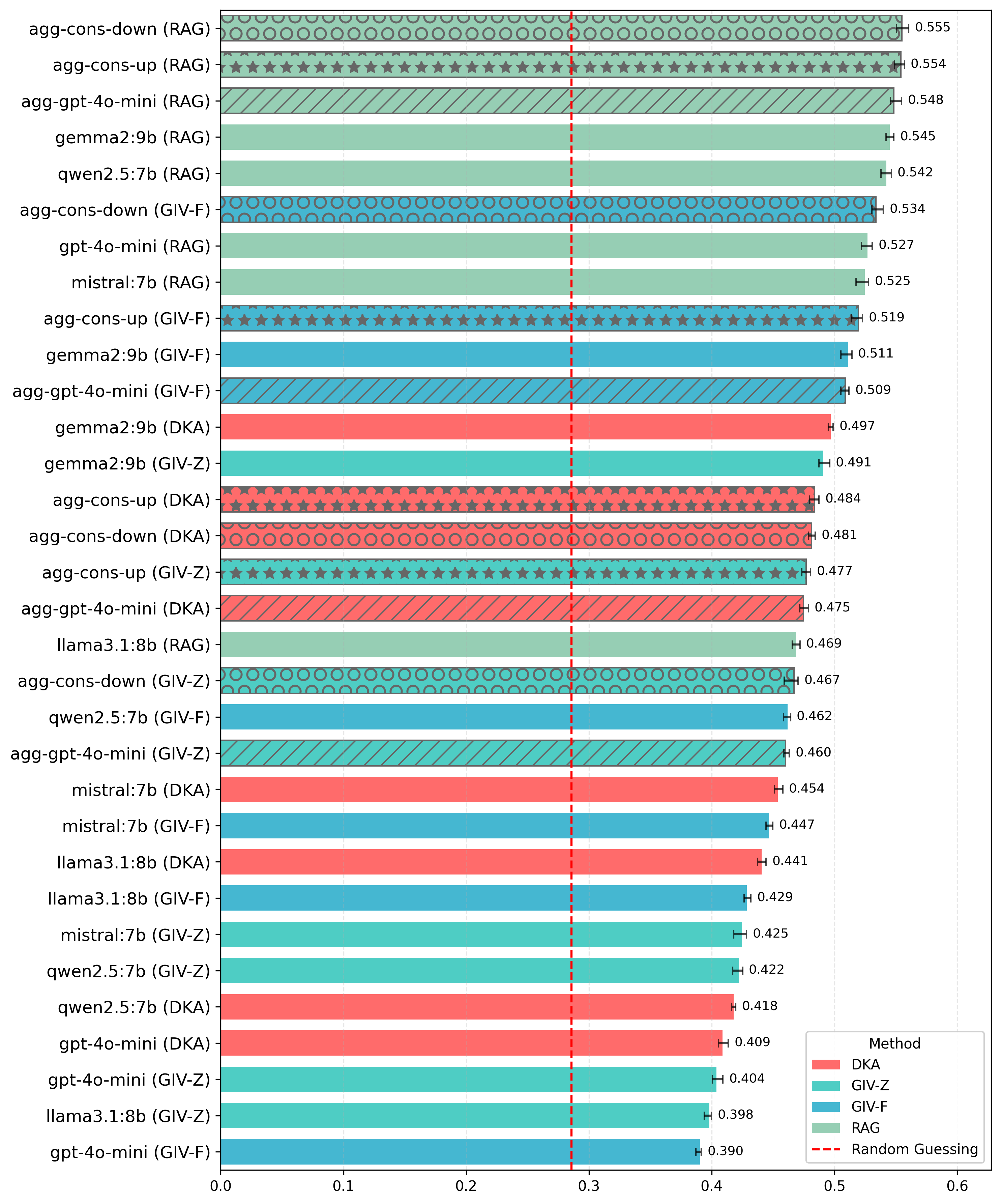
Продвинутые стратегии валидации и открытые модели
Процесс итеративной проверки с направляющими подсказками представляет собой усовершенствованную методику валидации фактов, направленную на повышение точности. Данный подход предполагает структурированное взаимодействие с языковой моделью, где первоначальный ответ подвергается последовательному уточнению на основе специально сформулированных запросов. Посредством этого итеративного цикла, модель не просто выдает информацию, но и активно пересматривает и корректирует свои утверждения, опираясь на предоставленные подсказки и внутренние знания. Такой метод позволяет выявлять и устранять неточности, а также повышать надежность и достоверность предоставляемых фактов, делая его эффективным инструментом для работы с большими объемами информации и критической оценки данных.
Для повышения надежности проверки фактов применяется метод консенсуса между различными языковыми моделями. Исследования показали, что объединение прогнозов, полученных от Gemma2, Qwen2.5, Mistral и GPT-4o mini, позволяет значительно снизить количество ошибок. Суть подхода заключается в том, что если несколько моделей сходятся во мнении относительно определенного утверждения, вероятность его истинности возрастает. Такой коллективный подход к анализу информации позволяет компенсировать индивидуальные слабости каждой модели и достичь более высокой точности в целом, что особенно важно при работе с критически важными данными и сложными запросами.
Исследования показали, что открытые языковые модели, такие как Gemma2, демонстрируют значительный потенциал в задаче проверки фактов. В ходе тестирования на наборе данных FactBench, модель достигла показателя F1 в 0.79, используя исключительно собственные знания, накопленные в процессе обучения. Этот результат подчеркивает способность современных открытых моделей к эффективному извлечению и применению информации без необходимости внешних источников или дополнений, что открывает перспективы для создания более автономных и доступных систем проверки достоверности данных.
Исследования последовательно демонстрируют, что использование подхода Retrieval-Augmented Generation (RAG) значительно повышает эффективность валидации фактов в базах знаний (Knowledge Graphs — KG). Независимо от конкретной конфигурации и используемых моделей, RAG стабильно улучшает результаты, позволяя более точно определять достоверность информации. Этот метод, основанный на извлечении релевантных данных из внешних источников и их последующем использовании для формирования ответов, обеспечивает более надежную и обоснованную проверку фактов, чем применение моделей обработки естественного языка (LLM) в изолированном режиме. Таким образом, RAG представляется перспективным инструментом для повышения точности и надежности систем, работающих с большими объемами структурированных данных и требующих высокой степени достоверности информации.
Исследование, представленное в статье, фокусируется на оценке способности больших языковых моделей к проверке фактов в графах знаний. Этот процесс требует не только обработки информации, но и понимания её контекста и взаимосвязей. Как заметил Роберт Тарьян: «Алгоритмы должны быть настолько простыми, чтобы их можно было понять, и настолько эффективными, чтобы их можно было использовать». Простота и эффективность — ключевые принципы, определяющие ценность любого инструмента, в том числе и моделей, предназначенных для валидации фактов. Акцент на Retrieval-Augmented Generation и консенсусе между моделями демонстрирует стремление к созданию устойчивых и надежных систем, способных к долгосрочной работе с постоянно меняющимися графами знаний. В конечном счёте, задача состоит не в создании мгновенных решений, а в формировании фундамента для устойчивого развития технологий проверки информации.
Куда Ведет Дорога?
Представленная работа, стремясь оценить способность больших языковых моделей к валидации фактов в графах знаний, неизбежно обнажает более глубокую проблему: не столько точность самой валидации, сколько архитектуру доверия. Каждая задержка в достижении абсолютной уверенности — это цена понимания, и игнорирование контекста, исторической нагрузки на данные, делает любую систему хрупкой. Использование генерации с дополнением извлечением — шаг в верном направлении, но лишь отсрочка, а не решение. Вопрос не в том, чтобы создать модель, безошибочно определяющую истину, а в том, чтобы создать систему, способную достойно стареть, адаптироваться к новым данным и признавать собственные ошибки.
Очевидно, что дальнейшее развитие потребует не только улучшения алгоритмов, но и переосмысления метрик оценки. Простая точность — метрика, удобная для машин, но мало полезная для систем, существующих во времени. Необходимо учитывать стоимость ошибки, ее последствия и возможность восстановления после нее. Мультимодальный консенсус — многообещающий подход, но он требует тщательного анализа влияния различных источников информации и разработки механизмов разрешения конфликтов.
В конечном счете, исследование валидации графов знаний — это лишь частный случай более общей проблемы: как построить системы, способные к осмысленному взаимодействию со сложным, нелинейным миром. Архитектура без истории — хрупка и скоротечна. И истинное испытание для больших языковых моделей — не в том, чтобы овладеть знанием, а в том, чтобы научиться его сохранять и передавать.
Оригинал статьи: https://arxiv.org/pdf/2602.10748.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Внимание на границе: почему трансформеры нуждаются в «поглотителях»
- Химический синтез под контролем искусственного интеллекта: новые горизонты
- Искусственный нос будущего: как квантовая механика и машинное обучение распознают запахи
- Внимание в сети: Новый подход к ускорению больших языковых моделей
- Пространственная Архитектура для Эффективного Ускорения Нейросетей
- Физика под контролем: Как «научить» модели понимать мир
- Когда большая языковая модель молчит: как избежать галлюцинаций при ответе на вопросы?
- Искусственный интеллект нового поколения: фокус на специализированные модели
- Искусство обмана: Новые методы атак на системы «зрение + язык»
- Квантовые Завихрения и Пятилетние Планы: Взгляд изнутри
2026-02-13 04:50