Автор: Денис Аветисян
В статье показано, как методы объяснимого искусственного интеллекта повышают надёжность и предсказуемость машинного обучения в критически важных промышленных кибер-физических системах.
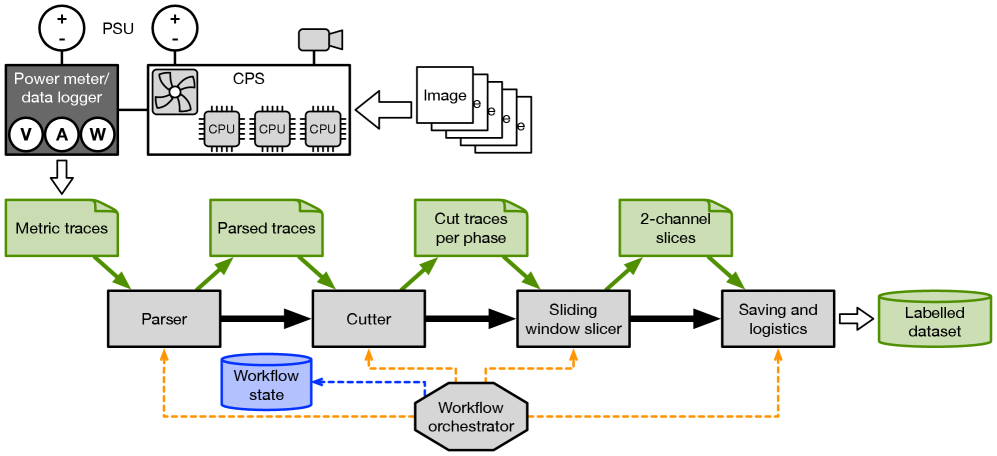
Использование SHAP-значений и разложения временных рядов в сверточных нейронных сетях улучшает обнаружение аномалий и позволяет оптимизировать параметры моделей.
Надежность промышленных кибер-физических систем (КФС) критически важна, однако сложность моделей машинного обучения, все шире внедряемых в эти системы, затрудняет понимание их работы и предсказание поведения. В работе, озаглавленной ‘Explainable AI to Improve Machine Learning Reliability for Industrial Cyber-Physical Systems’, предложен подход, использующий методы объяснимого искусственного интеллекта (XAI) для повышения надежности и эффективности моделей, предназначенных для КФС. Применяя анализ SHAP значений к компонентам, полученным в результате разложения временных рядов, авторы выявили недостаток контекстной информации при обучении моделей и продемонстрировали возможность улучшения производительности за счет увеличения размера окна данных. Возможно ли дальнейшее расширение области применения XAI для создания более устойчивых и надежных систем управления в промышленности?
Кибер-физические системы: Надежность под вопросом
Кибер-физические системы (КФС) становятся основой критически важной инфраструктуры, охватывающей энергетику, транспорт, здравоохранение и другие сферы жизни. В связи с этим, потребность в надежном мониторинге и своевременном обнаружении неисправностей в этих системах возрастает экспоненциально. КФС отличаются сложной взаимосвязью между вычислительными и физическими процессами, что делает их уязвимыми к различным сбоям и атакам. Обеспечение бесперебойной работы КФС — это не просто техническая задача, но и вопрос национальной безопасности и стабильности общества, требующий разработки и внедрения передовых методов контроля и диагностики.
Традиционные методы анализа данных, разработанные для более простых систем, часто оказываются неэффективными при работе с кибер-физическими системами (КФС). КФС генерируют огромные объемы временных рядов данных, характеризующиеся высокой размерностью и сложными взаимосвязями между различными параметрами. Это создает значительные вычислительные трудности и требует разработки новых алгоритмов, способных эффективно обрабатывать такие данные. Проблема усугубляется тем, что данные часто зашумлены, содержат пропуски и подвержены различным видам помех, что затрудняет выявление полезной информации и прогнозирование поведения системы. В результате, применение стандартных статистических методов или алгоритмов машинного обучения может приводить к неточным результатам и ошибочным выводам, что представляет серьезную угрозу для надежности и безопасности КФС.
Для обеспечения надёжности кибер-физических систем (КФС) недостаточно простого выявления аномалий; требуется глубокое понимание нормального функционирования и закономерностей в их работе. Современные КФС генерируют огромные объёмы данных, отражающих сложные взаимосвязи между физическими процессами и программным обеспечением. Анализ этих данных, направленный не только на обнаружение отклонений, но и на построение моделей типичного поведения, позволяет предсказывать потенциальные сбои и оперативно реагировать на изменения в рабочих условиях. Такой подход, основанный на прогностическом анализе и моделировании, существенно повышает устойчивость КФС к нештатным ситуациям и обеспечивает их бесперебойную работу в критически важных областях, таких как энергетика, транспорт и здравоохранение.
Разложение временных рядов: Ключ к пониманию КФС
Разложение временных рядов представляет собой мощный аналитический метод, позволяющий разделить сложные сигналы на отдельные, интерпретируемые компоненты. Этот процесс включает выделение базового тренда, сезонности, циклической составляющей и остаточной случайной компоненты. Разделение сигнала таким образом облегчает выявление закономерностей, прогнозирование будущих значений и обнаружение аномалий, которые могли бы остаться незамеченными при анализе исходного, необработанного временного ряда. Эффективность разложения временных рядов обусловлена его способностью к адаптации к различным типам данных и масштабируемостью для обработки больших объемов информации, что делает его незаменимым инструментом в задачах анализа данных в различных областях, включая промышленный мониторинг и прогнозирование.
Низкочастотные (НЧ) и высокочастотные (ВЧ) компоненты временных рядов представляют собой ключевые элементы декомпозиции, позволяющие выявить основные характеристики данных. НЧ-компонента отражает долгосрочные тренды и систематические изменения в данных, например, сезонность или общую динамику процесса. ВЧ-компонента, напротив, описывает краткосрочные колебания и случайные отклонения, такие как шум или внезапные скачки. Анализ этих компонентов позволяет отделить стабильные тенденции от случайных флуктуаций, что критически важно для выявления аномалий, прогнозирования и оптимизации промышленных процессов. Разделение на НЧ и ВЧ компоненты осуществляется с помощью различных методов, включая фильтрацию, преобразование Фурье и вейвлет-анализ.
Анализ уровней (Levels), масштаба (Scale) и пиков (Peaks) временных рядов позволяет детализировать характеристики данных и выявлять потенциальные аномалии. Уровень представляет собой среднее значение сигнала во времени, определяя базовый тренд. Масштаб отражает амплитуду колебаний, указывая на интенсивность изменений. Пики, в свою очередь, идентифицируют экстремальные значения, которые могут свидетельствовать о сбоях, отклонениях от нормы или важных событиях в контролируемом процессе. Комбинированный анализ этих компонентов позволяет более точно определить границы нормального поведения системы и оперативно реагировать на отклонения, что особенно важно при работе с данными промышленных систем управления.
Эффективный анализ временных рядов в промышленных кибер-физических системах (CPS) требует не только выделения составляющих, таких как тренд, сезонность и остаток, но и интерпретации этих компонентов в контексте конкретной операционной структуры данных. Понимание взаимосвязи между выделенными составляющими и физическими процессами, которые они отражают, необходимо для точной диагностики аномалий, прогнозирования отказов оборудования и оптимизации производственных процессов. Например, увеличение амплитуды высокочастотной составляющей может указывать на возникновение вибраций в механизме, а изменение тренда — на постепенное износ оборудования. Корректная интерпретация требует глубокого понимания структуры данных CPS, включая типы датчиков, частоту сбора данных и взаимосвязь между различными параметрами технологического процесса.
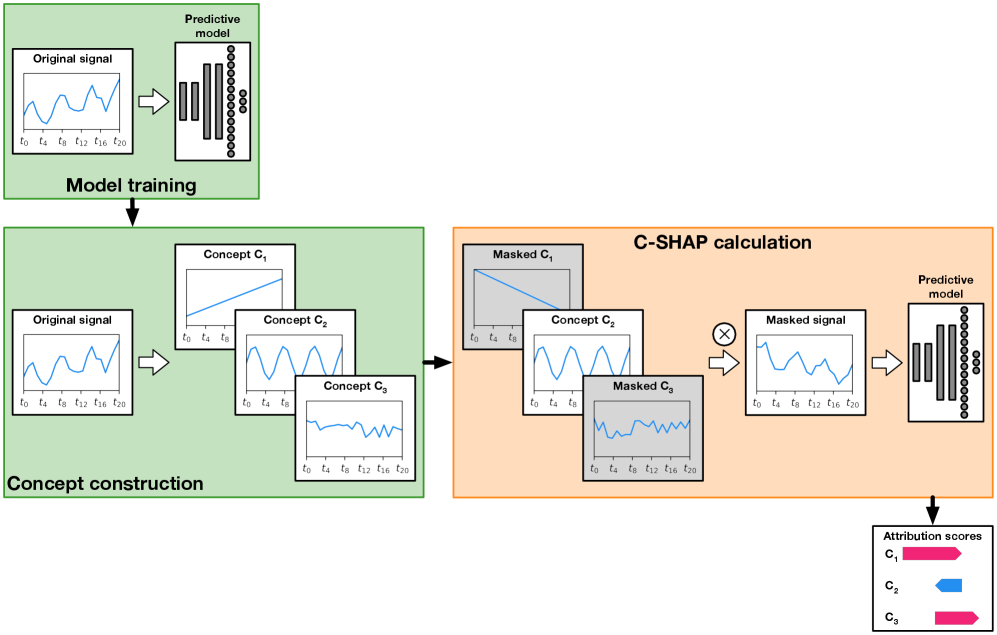
Интерпретируемость моделей с помощью C-SHAP
Машинное обучение играет ключевую роль в предиктивной диагностике и мониторинге состояния кибер-физических систем (КФС), однако сложные модели, такие как глубокие нейронные сети, часто характеризуются недостаточной прозрачностью. Отсутствие интерпретируемости затрудняет понимание логики принятия решений моделью, что снижает доверие к результатам и усложняет процесс верификации и отладки. В контексте КФС, где надежность и безопасность являются критически важными, недостаток прозрачности может привести к неверным решениям и серьезным последствиям. Поэтому, наряду с повышением точности прогнозов, важной задачей является разработка методов, позволяющих объяснить и интерпретировать поведение сложных моделей машинного обучения.
C-SHAP (Cumulative SHapley Additive exPlanations) представляет собой методологию для объяснения вклада каждого компонента временного ряда в предсказания модели. В отличие от простых оценок важности признаков, C-SHAP вычисляет значения SHAP для каждого временного ряда, показывая, как конкретный компонент влияет на предсказание модели в контексте всей последовательности данных. Это достигается путем рассмотрения всех возможных комбинаций временных рядов и оценки влияния каждого компонента на изменение предсказания относительно базового уровня. В результате, C-SHAP позволяет не только определить наиболее значимые компоненты, но и понять, как они взаимодействуют друг с другом и вносят вклад в конечный результат работы модели.
Метод C-SHAP позволяет выявить ключевые факторы, влияющие на предсказания модели, что повышает доверие к ней и обеспечивает принятие более обоснованных решений. Анализ вклада каждого компонента временного ряда в общую предсказательную способность модели позволяет не только понять логику её работы, но и подтвердить адекватность полученных результатов. В процессе разработки CNN-модели для обнаружения неисправностей в промышленных киберфизических системах (CPS) применение SHAP-значений позволило увеличить точность до 92.3%. Увеличение размера окна анализа (100, 200, 400) также демонстрирует повышение стабильности модели, о чем свидетельствует снижение стандартного отклонения среднего абсолютного значения SHAP (уровень концепции) с 0.178 до 0.155.
В отличие от простого определения важности признаков, данный подход позволяет выявить влияние конкретных компонентов временных рядов на прогнозы в контексте фаз выполнения системы. Интеграция SHAP-значений в процесс разработки модели позволила улучшить точность CNN-модели обнаружения неисправностей для промышленных киберфизических систем (CPS) до 92.3%. При этом, точность модели составляет 83.78% при размере окна 100, 87.9% при размере окна 200 и достигает пикового значения в 92.3% при размере окна 400. Стандартное отклонение средней абсолютной величины SHAP-значения (концепция Levels) составляет 0.178 для размера окна 100, 0.170 для размера окна 200 и 0.155 для размера окна 400, что свидетельствует о повышении стабильности с увеличением размера окна.
При использовании C-SHAP для CNN-модели обнаружения неисправностей в промышленных киберфизических системах, достигнута точность 83.78% при размере окна 100, 87.9% при размере окна 200 и максимальная точность 92.3% при размере окна 400. Данные результаты демонстрируют прямую зависимость между размером анализируемого временного окна и общей точностью модели, указывая на необходимость оптимизации этого параметра для достижения наилучшей производительности в конкретных сценариях применения.
Стандартное отклонение средней абсолютной величины SHAP-значений (концепция Levels) демонстрирует улучшение согласованности при увеличении размера окна. При размере окна 100 стандартное отклонение составляет 0.178, при размере окна 200 — 0.170, и достигает минимального значения 0.155 при размере окна 400. Данная тенденция указывает на то, что использование большего размера окна в анализе временных рядов с применением C-SHAP приводит к более стабильным и надежным результатам оценки вклада отдельных компонентов в предсказания модели.
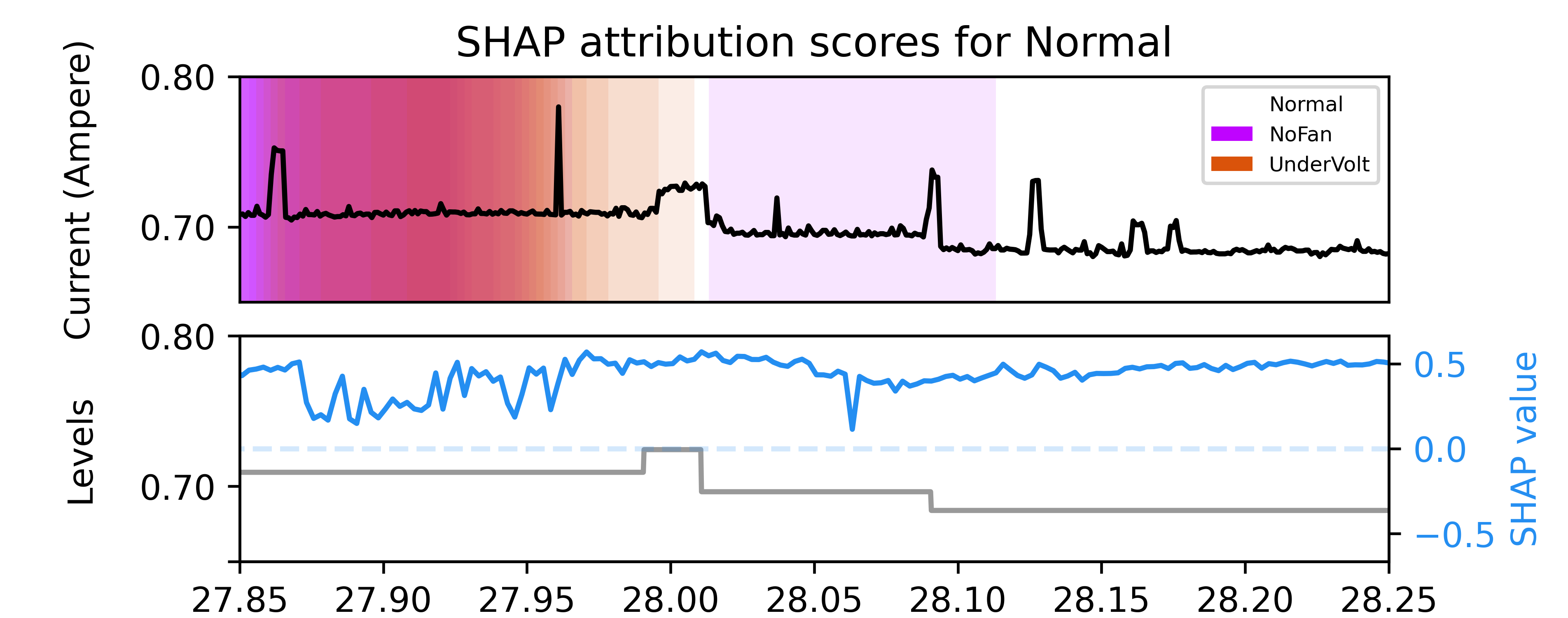
Статья, как обычно, пытается придать видимость осмысленности процесса, который в конечном итоге сведётся к тонкой настройке параметров до тех пор, пока графики не начнут выглядеть убедительно. Упор на Explainable AI и SHAP values — это, конечно, прекрасно, но не стоит забывать, что даже самое детальное объяснение не гарантирует, что система не начнёт выдавать абсурдные результаты в столкновении с реальными данными. Как метко заметил Джон Маккарти: «Искусственный интеллект — это попытка сделать машины умными, а не просто быстрыми». И в этом контексте, попытки объяснить логику работы CNN для выявления аномалий в промышленных системах — это лишь ещё одна попытка отложить неизбежный момент, когда всё придёт в негодность, а прод снова придётся спасать вручную.
Что дальше?
Представленная работа, как и большинство попыток приручить искусственный интеллект для промышленных систем, демонстрирует лишь временное облегчение боли. Объяснимость, достигаемая через SHAP-значения и разложение временных рядов, — это, по сути, попытка создать иллюзию контроля над сложной системой. В конечном счете, любой «интеллект» в этих системах — лишь статистическая модель, которая неизбежно даст сбой в условиях, не предусмотренных обучающей выборкой. Не стоит забывать, что багтрекер — это дневник боли, и ни одна модель не может предвидеть все возможные способы, которыми продакшен найдёт способ сломать элегантную теорию.
Будущие исследования, вероятно, сосредоточатся на автоматизации процесса интерпретации SHAP-значений, что, в сущности, является попыткой автоматизировать постмортем. Настоящая проблема заключается не в том, чтобы понять, почему модель ошиблась, а в том, чтобы построить систему, которая будет более устойчива к неопределенности. И, вероятно, мы увидим еще больше инструментов, обещающих «самообъяснимый» ИИ, что, по сути, является просто маркетингом.
Не стоит обольщаться. У них не DevOps-культура, у них культ DevOops. Аномалии будут возникать, гиперпараметры потребуют настройки, и цикл повторится. Это не прогресс, это просто перераспределение усилий. И, в конечном счете, мы не деплоим — мы отпускаем.
Оригинал статьи: https://arxiv.org/pdf/2601.16074.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-23 13:59