Автор: Денис Аветисян
Новая модель VLingNav позволяет роботам ориентироваться в сложных пространствах, используя визуальные подсказки, лингвистическую память и способность к адаптивному планированию.
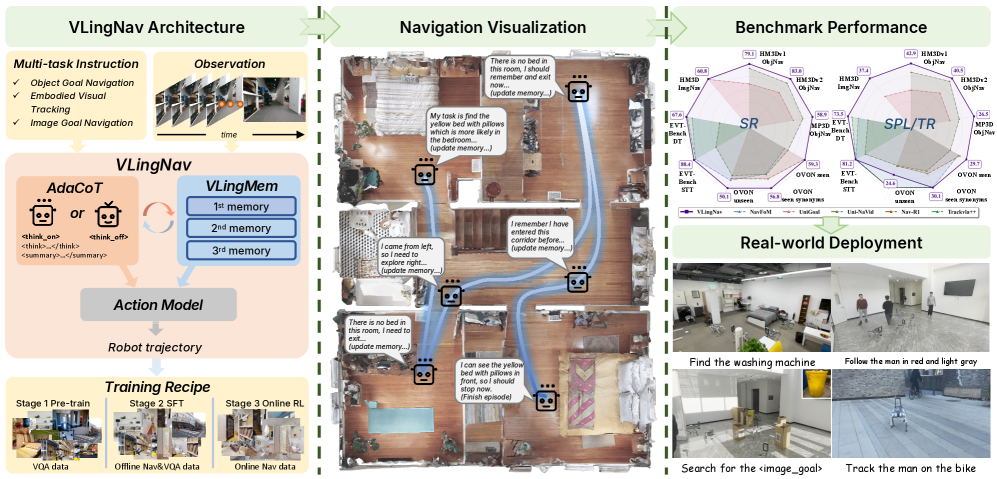
Представлена система, сочетающая обучение с подкреплением, визуально-языковые модели и цепочку рассуждений для достижения передовых результатов в задачах воплощенной навигации и демонстрирующая высокую обобщающую способность на реальных роботах.
Несмотря на успехи моделей «восприятие-действие» в навигации, большинство из них страдают от недостатка явного рассуждения и долговременной памяти, необходимых для сложных задач. В данной работе представлена модель VLingNav: Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic Memory, использующая адаптивное рассуждение и лингвистическую память для достижения передовых результатов в области воплощенной навигации. Модель сочетает в себе механизм адаптивного «chain-of-thought» и визуально-ориентированный модуль лингвистической памяти, позволяя агенту эффективно планировать действия и избегать повторных исследований. Способна ли такая архитектура открыть новые горизонты для обучения роботов и создания действительно автономных навигационных систем?
Преодоление когнитивных ограничений: вызов для воплощенного интеллекта
Современные модели, объединяющие зрение и язык, демонстрируют значительные трудности при решении сложных задач навигации в физическом мире, требующих последовательного выполнения нескольких шагов. Несмотря на впечатляющие успехи в обработке изображений и понимании естественного языка, эти модели часто оказываются неспособны эффективно планировать маршрут и адаптироваться к изменяющимся условиям окружающей среды. Например, при просьбе «принести книгу со второго этажа, а затем отнести её в сад», модель может столкнуться с проблемами в поддержании последовательности действий и правильном выполнении каждого шага. Это указывает на необходимость разработки более совершенных механизмов рассуждений, позволяющих моделям не просто воспринимать окружающий мир, но и активно планировать свои действия и предвидеть последствия, что является ключевым для успешной навигации и взаимодействия с физическим пространством.
Существующие методы искусственного интеллекта, предназначенные для работы в реальных условиях, часто демонстрируют ограниченность в способности сохранять и эффективно использовать информацию о предыдущих событиях и взаимодействиях. Отсутствие устойчивой памяти и способности к последовательному обдумыванию действий приводит к тому, что системы испытывают трудности в динамично меняющейся среде. Вместо комплексного планирования и адаптации к новым обстоятельствам, они полагаются на немедленную реакцию, что снижает эффективность при выполнении сложных, многоступенчатых задач, требующих учета контекста и долгосрочного планирования. Это особенно заметно в задачах, где необходимо учитывать последствия предыдущих действий и адаптировать стратегию в зависимости от изменений в окружающей среде.
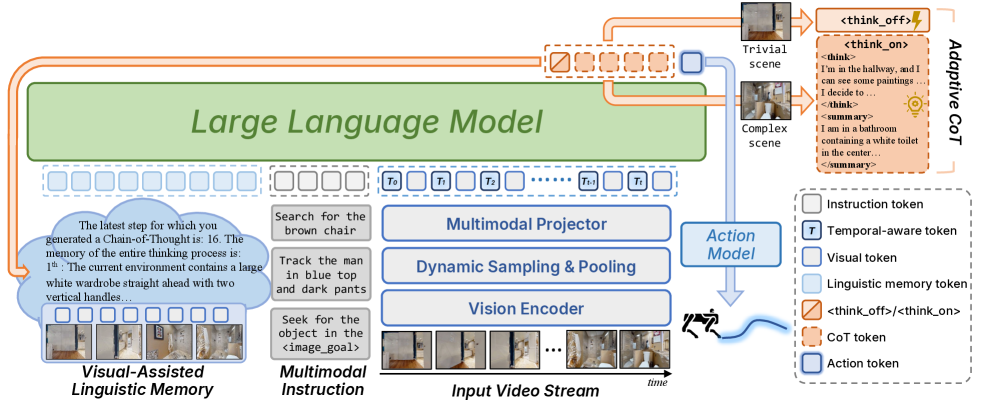
VLingNav: синтез восприятия и действия
Система VLingNav использует адаптивное рассуждение посредством Adaptive Chain-of-Thought (AdaCoT), которое динамически балансирует между глубоким обдумыванием и эффективностью действий. AdaCoT вдохновлено теорией двойных процессов, предполагающей сосуществование двух основных типов мышления: “Системы 1” — быстрой, интуитивной и эмоциональной, и “Системы 2” — медленной, аналитической и рациональной. В VLingNav, AdaCoT позволяет системе переключаться между этими режимами в зависимости от сложности задачи и доступных ресурсов, обеспечивая как быструю реакцию в простых ситуациях, так и тщательный анализ в более сложных сценариях. Этот механизм адаптации позволяет оптимизировать процесс принятия решений и повысить общую производительность системы навигации.
Визуально-лингвистическая память (VLingMem) является ключевым компонентом системы, обеспечивающим преобразование визуальных данных в лингвистические обобщения для долгосрочного хранения и межмодального понимания. Этот процесс включает в себя дистилляцию информации, полученной из визуальных наблюдений, в структурированные лингвистические представления, что позволяет системе сохранять и извлекать информацию о визуальной среде в текстовом формате. Такой подход способствует более эффективному использованию накопленного опыта для решения задач, требующих сопоставления визуальной информации с лингвистическими знаниями, и улучшает способность системы к обобщению и адаптации в различных ситуациях.
Система использует методы модельно-прогнозного управления (MPC) и нелинейного MPC для обеспечения надежной навигации. MPC позволяет предсказывать будущие состояния системы на основе текущих данных и модели динамики, а затем оптимизировать управляющие воздействия для достижения желаемой траектории. Нелинейный MPC применяется в случаях, когда модель системы содержит нелинейные зависимости, что позволяет более точно учитывать реальное поведение робота в сложных условиях. Оптимизация проводится с учетом ограничений на управляющие воздействия и состояния системы, что гарантирует безопасность и устойчивость навигации. \hat{x}_{k+1} = f(x_k, u_k) — общая схема прогноза состояния, где x — состояние, u — управляющее воздействие, а f — функция динамики системы.
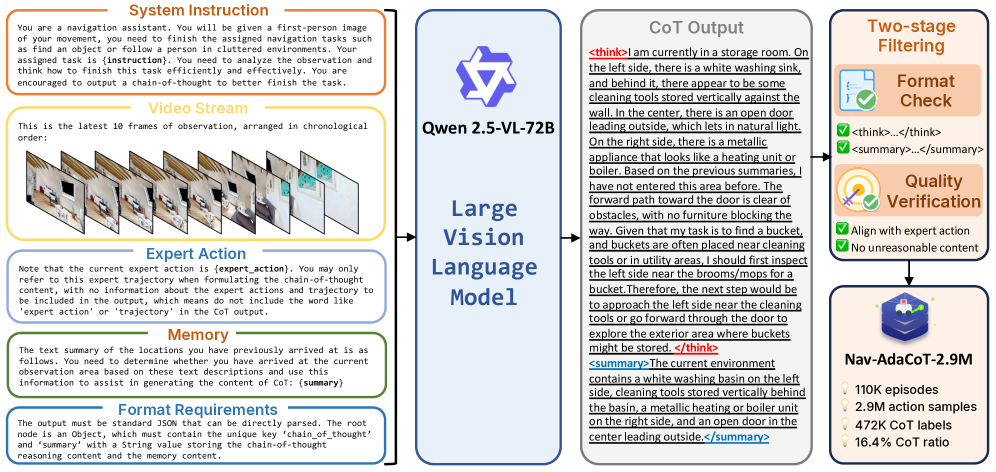
Оттачивая навигацию посредством обучения и опыта
Начальная политика агента VLingNav формируется посредством контролируемого обучения (Supervised Fine-tuning, SFT) на наборе данных Nav-AdaCoT-2.9M, содержащем 2.9 миллиона примеров навигационных задач. Этот этап обучения позволяет создать прочную основу для дальнейшего обучения с подкреплением, обеспечивая агента базовыми навыками понимания инструкций и планирования маршрута в визуальной среде. Использование большого и разнообразного набора данных Nav-AdaCoT-2.9M критически важно для обобщающей способности модели и ее способности успешно справляться с новыми, ранее не встречавшимися задачами навигации.
Для дальнейшего повышения эффективности модели VLingNav применяется онлайн-обучение с подкреплением, управляемое экспертом (Online Expert-guided Reinforcement Learning). Этот метод использует демонстрации эксперта для уточнения политики навигации и улучшения процесса принятия решений. В процессе обучения модель получает вознаграждение за действия, приближающие её к траектории эксперта, что позволяет ей эффективно осваивать сложные стратегии навигации и адаптироваться к новым условиям. Такой подход позволяет не только улучшить текущую производительность, но и обеспечить более устойчивую и надежную работу модели в различных сценариях.
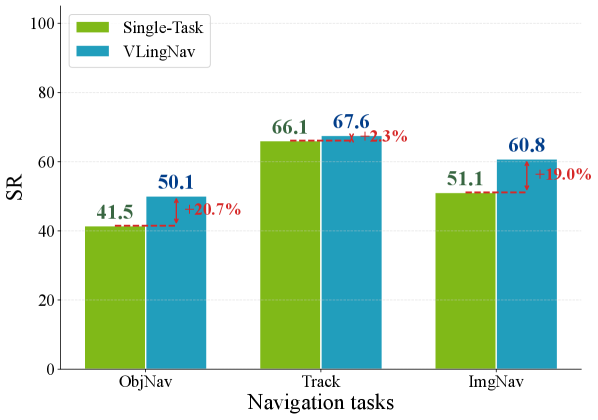
Комбинация обучения с учителем (Supervised Fine-tuning, SFT) и обучения с подкреплением с использованием экспертных демонстраций (Reinforcement Learning, RL) позволила добиться значительного улучшения показателей успешной навигации. На тестовом наборе HM3D OVON val unseen модель VLingNav достигла успеха в 79.1% случаев, что на 5.4% превышает результаты предыдущих лучших моделей. Дополнительно, на наборе EVT-Bench Distracted Tracking зафиксирован показатель успешности в 67.6% (превышение на 1.1%), а на HM3D Instance ImageNav val — 60.8% (превышение на 0.6%) по сравнению с предыдущими результатами.
В процессе обучения и работы модели VLingNav, архитектура AdaCoT демонстрирует высокую эффективность рассуждений, требуя активации механизма всего в 2.1% случаев от общего числа шагов. Это указывает на низкую вычислительную стоимость процесса принятия решений, поскольку модель в большинстве ситуаций способна успешно ориентироваться и выполнять задачи без использования ресурсоемких процедур логического вывода. Низкая частота активации AdaCoT способствует повышению скорости работы модели и снижению потребления вычислительных ресурсов, что является важным преимуществом при развертывании в реальных условиях.
Перспективы развития: к более разумным воплощенным агентам
В настоящее время система VLingNav опирается на монокулярное зрение, однако интеграция многовидового зрения представляется перспективным путем к значительному улучшению восприятия и устойчивости в сложных условиях. Использование нескольких камер позволит агенту формировать более полное и точное представление об окружающей среде, преодолевая ограничения, связанные с недостатком глубинной информации и окклюзиями, характерными для монокулярных систем. Такой подход позволит агенту надежнее ориентироваться в пространстве, распознавать объекты и избегать препятствий, особенно в условиях низкой освещенности или зашумленности. Улучшенное восприятие, полученное благодаря многовидовому зрению, не только повысит эффективность навигации, но и откроет возможности для решения более сложных задач, требующих детального понимания окружающей среды.
Принципы, лежащие в основе системы VLingNav — адаптивное рассуждение, сохранение устойчивой памяти и обучение под руководством эксперта — демонстрируют свою универсальность, выходя далеко за рамки задач навигации. Эти механизмы способны значительно улучшить производительность воплощенных интеллектуальных систем в самых разных областях, включая манипулирование объектами, сборку, исследование окружающей среды и даже социальное взаимодействие. Возможность адаптироваться к новым ситуациям, сохранять информацию о предыдущем опыте и использовать знания, полученные от экспертов, позволяет создавать агентов, способных к более гибкому и эффективному решению сложных задач в реальном мире. Такой подход открывает перспективы для разработки роботов-помощников, способных к самостоятельному обучению и выполнению широкого спектра действий в различных условиях.
Данная работа закладывает основу для создания интеллектуальных и адаптивных агентов, способных к беспрепятственному взаимодействию и обучению в реальном мире. Разработанный подход позволяет преодолеть ограничения традиционных систем искусственного интеллекта, предоставляя возможность агентам не просто выполнять заданные инструкции, но и самостоятельно адаптироваться к изменяющимся условиям окружающей среды. Возможность интеграции с различными сенсорами и платформами открывает перспективы для широкого спектра применений, включая робототехнику, автономные транспортные средства и интеллектуальные системы помощи. В перспективе, подобные агенты смогут не только понимать сложные инструкции на естественном языке, но и самостоятельно формулировать цели и находить оптимальные пути их достижения, значительно расширяя границы возможностей искусственного интеллекта и приближая будущее, в котором машины смогут эффективно сотрудничать с человеком в самых разнообразных сферах деятельности.

Исследование, представленное в данной работе, демонстрирует стремление к упрощению сложности в области навигации, что находит отклик в философии минимализма. Модель VLingNav, объединяя визуальное восприятие, лингвистическую память и обучение с подкреплением, стремится к достижению оптимального решения без излишних вычислений. В этом контексте уместно вспомнить слова Винтона Серфа: «Интернет — это жизнь». Данное высказывание подчеркивает необходимость создания систем, способных эффективно функционировать в реальном мире, подобно тому, как VLingNav адаптируется к новым условиям и демонстрирует обобщающую способность. Чёткость и лаконичность алгоритмов, как показано в статье, являются ключевыми факторами для успешной работы робототехнических систем.
Куда Далее?
Представленная работа, безусловно, демонстрирует прогресс в области воплощённой навигации. Однако, истинная ясность требует признания: текущие модели, даже самые эффективные, остаются сложными конструкциями, перегруженными параметрами. Успех в симуляции не гарантирует элегантности решения. Следующим шагом представляется не добавление новых слоёв абстракции, а радикальное упрощение. Необходимо искать принципы, позволяющие достичь сопоставимых результатов с меньшими вычислительными затратами, приближаясь к эффективности биологических систем.
Особое внимание следует уделить проблеме обобщения. Переход от контролируемой среды к реальному миру, с его непредсказуемостью и шумом, обнажает хрупкость текущих подходов. Модели, зависящие от точных лингвистических инструкций, оказываются уязвимыми к малейшим неточностям. Поиск инвариантных представлений, устойчивых к вариациям в языке и сенсорных данных, представляется ключевой задачей.
Наконец, необходимо помнить, что навигация — это лишь часть более широкой проблемы — построения разумных агентов, способных к адаптивному поведению в сложных средах. Следует стремиться не к созданию специализированных систем, решающих узкий круг задач, а к разработке универсальных платформ, способных к обучению и обобщению на основе минимального набора принципов. Тогда, возможно, и появится подлинная ясность.
Оригинал статьи: https://arxiv.org/pdf/2601.08665.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2026-01-15 02:06