Автор: Денис Аветисян
Новое исследование сравнивает возможности больших языковых моделей в преобразовании естественного языка в код на Python и SQL, выявляя ключевые различия в их устойчивости к неполной информации.
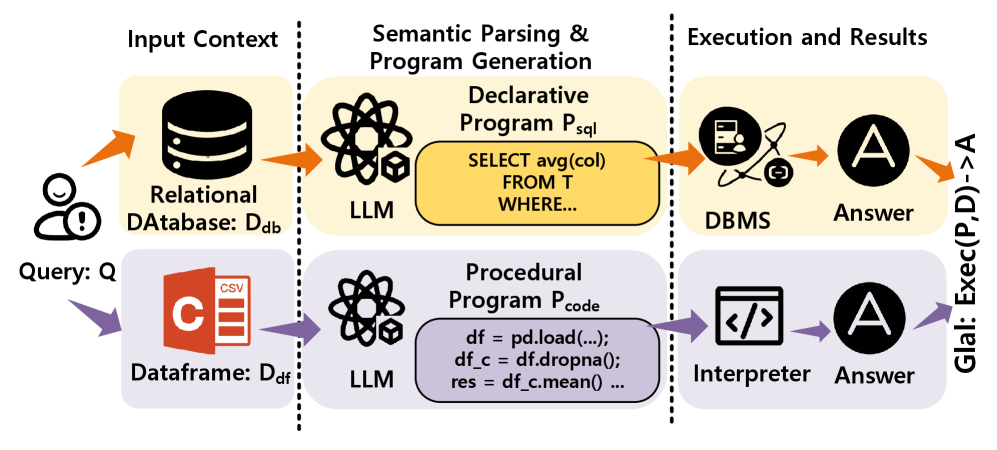
Исследование показывает, что модели, генерирующие код на Python, более чувствительны к отсутствию логических связей, и что улучшение контекста значительно повышает точность в обеих парадигмах.
Несмотря на растущую потребность в гибкости языков программирования общего назначения для анализа данных, надёжность преобразования естественного языка в Python остаётся недостаточно изученной по сравнению с устоявшейся областью Text-to-SQL. В своей работе ‘Benchmarking Text-to-Python against Text-to-SQL: The Impact of Explicit Logic and Ambiguity’ авторы представляют BIRD-Python — эталон для кросsparadigматической оценки, выявляющий фундаментальное различие: в то время как SQL опирается на неявное поведение СУБД, Python требует явной процедурной логики, что делает его более чувствительным к неполноте запроса. Полученные результаты демонстрируют, что разница в производительности обусловлена, прежде всего, отсутствием контекста, а не ограничениями генерации кода, и что восполнение этого пробела позволяет Text-to-Python достичь сопоставимой производительности с Text-to-SQL. Каким образом можно эффективно интегрировать доменные знания в системы преобразования естественного языка в код для создания надёжных и гибких аналитических агентов?
Преодолевая Неоднозначность: Вызовы Понимания Естественного Языка
Несмотря на впечатляющий прогресс в области больших языковых моделей (БЯМ), точное преобразование естественного языка в исполняемые инструкции по-прежнему представляет собой серьезную проблему. БЯМ демонстрируют способность генерировать текст, похожий на человеческий, и понимать сложные запросы, однако их способность надежно переводить эти запросы в конкретные действия, необходимые для решения задач, остается ограниченной. Это связано с тем, что естественный язык по своей природе неоднозначен и контекстуально зависим, что требует от моделей не только лингвистического понимания, но и способности к логическому выводу и интерпретации намерений. Неспособность адекватно учитывать нюансы языка и контекст приводит к ошибкам в выполнении задач, даже если модель демонстрирует высокий уровень языковой компетенции. Таким образом, преодоление этого препятствия является ключевым шагом на пути к созданию действительно интеллектуальных систем, способных взаимодействовать с человеком на естественном языке и эффективно выполнять поставленные задачи.
Неоднозначность формулировок и пробелы в знаниях часто приводят к ошибочным интерпретациям при работе систем, преобразующих естественный язык в исполняемые инструкции. Это особенно заметно в системах Text-to-SQL и Text-to-Python, где нечетко сформулированные условия или отсутствие необходимой информации для понимания контекста приводят к неверному построению запросов или кода. В результате, надежность таких систем снижается, поскольку они могут выдавать неточные результаты или вовсе не выполнять поставленную задачу. Преодоление этих сложностей требует разработки методов, способных разрешать неоднозначность и эффективно восполнять пробелы в знаниях, обеспечивая более точное и надежное преобразование человеческого намерения в машинное исполнение.
Для эффективного решения существующих проблем в области понимания естественного языка необходимы глубокие исследования, направленные на установление прочной связи между человеческим намерением и машинным исполнением. Это требует не просто распознавания слов, но и интерпретации скрытого смысла, контекста и неявных предположений, которые человек использует при формулировании запроса. Успех в данной области зависит от разработки алгоритмов, способных моделировать когнитивные процессы, лежащие в основе человеческого мышления, и преобразовывать неструктурированные текстовые данные в четкие и однозначные инструкции для вычислительных систем. Исследования в области семантического анализа, онтологий и логического вывода играют ключевую роль в создании интеллектуальных систем, способных надежно и точно выполнять поставленные задачи, преодолевая разрыв между языком и действием.
От Структурированных Данных к Гибкости Файловых Форматов
Традиционные системы преобразования текста в SQL запросы эффективно работают со структурированными данными, опираясь на точное связывание схемы (Schema Linking). Этот процесс подразумевает установление однозначного соответствия между элементами запроса на естественном языке и конкретными таблицами, столбцами и отношениями в базе данных. В ходе Schema Linking система определяет, какие части запроса относятся к каким элементам схемы, что позволяет корректно транслировать запрос в SQL-команду. Точность связывания схемы критически важна для правильного выполнения запроса и получения релевантных результатов. Без точного Schema Linking система не сможет интерпретировать запрос и вернет ошибку или неверные данные.
В отличие от структурированных данных, где системы преобразования текста в SQL могут опираться на точное связывание со схемой, многие современные приложения работают с файловыми данными. Это требует перехода к подходу «текст в Python», который подразумевает необходимость явного определения процедурной логики для обработки данных. Вместо автоматического построения SQL-запросов, система должна генерировать Python-код, включающий шаги для чтения файла, обработки данных и формирования ответа, что требует более детального описания требуемых операций.
Возможности Text-to-Python обусловлены использованием библиотек, таких как Pandas, для манипулирования и анализа данных посредством DataFrame — структур данных, обеспечивающих эффективную обработку. При наличии достаточного контекста, производительность Text-to-Python сопоставима с Text-to-SQL, однако системы Text-to-Python более чувствительны к неполноте или отсутствию необходимых знаний о структуре и содержании данных, что может приводить к ошибкам или неоптимальным результатам.

Обеспечение Корректности: За Пределами Простого Выполнения
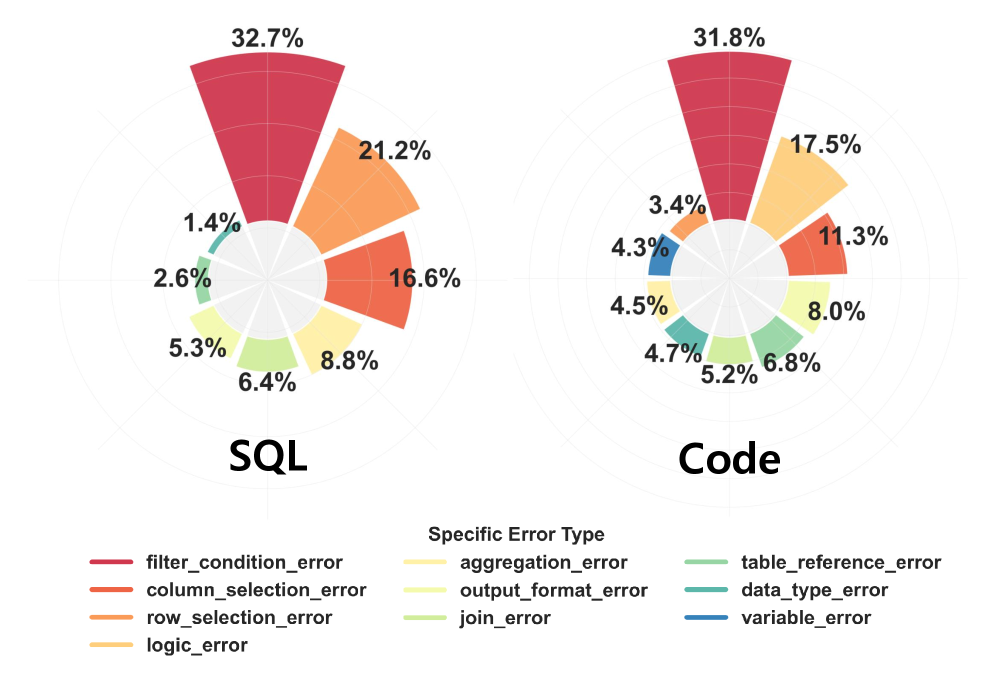
Оценка производительности систем Text-to-SQL и Text-to-Python не ограничивается простой проверкой на возможность выполнения кода. Ключевым показателем является Точность Выполнения (Execution Accuracy, EX), отражающая корректность результатов, полученных в ходе выполнения сгенерированного кода. Проверка только на синтаксическую корректность и отсутствие ошибок во время выполнения недостаточна, так как код может быть запущен, но при этом возвращать неверные или нерелевантные данные. Высокий показатель EX свидетельствует о способности системы генерировать код, который не только запускается, но и корректно решает поставленную задачу, используя предоставленные данные и логику.
Для стандартизированной оценки систем преобразования текста в SQL или Python используется бенчмарк BIRD, позволяющий проводить сравнительный анализ и выявлять области для улучшения. Согласно результатам тестирования на BIRD, модель Qwen3-Max демонстрирует точность выполнения (Execution Accuracy) в 63.43%, что незначительно превышает показатель DeepSeek-R1, составляющий 62.52%. Данный бенчмарк обеспечивает объективную метрику для сравнения различных моделей и отслеживания прогресса в области генерации исполняемого кода по текстовому описанию.
Обеспечение высокой точности выполнения (Execution Accuracy) в системах преобразования текста в SQL или Python напрямую зависит от согласованности данных (Data Consistency). Это означает, что сгенерированный код должен корректно интерпретировать и манипулировать данными, на которых он работает, избегая ошибок, связанных с неправильным пониманием типов данных, форматов или логики доступа к данным. Несоблюдение согласованности данных приводит к неверным результатам, даже если код синтаксически верен и успешно выполняется. Поэтому, при оценке таких систем, особое внимание уделяется способности генерировать код, который надежно и точно обрабатывает данные в соответствии с заданным запросом.
Усиление Рассуждений с Помощью Логического Завершения
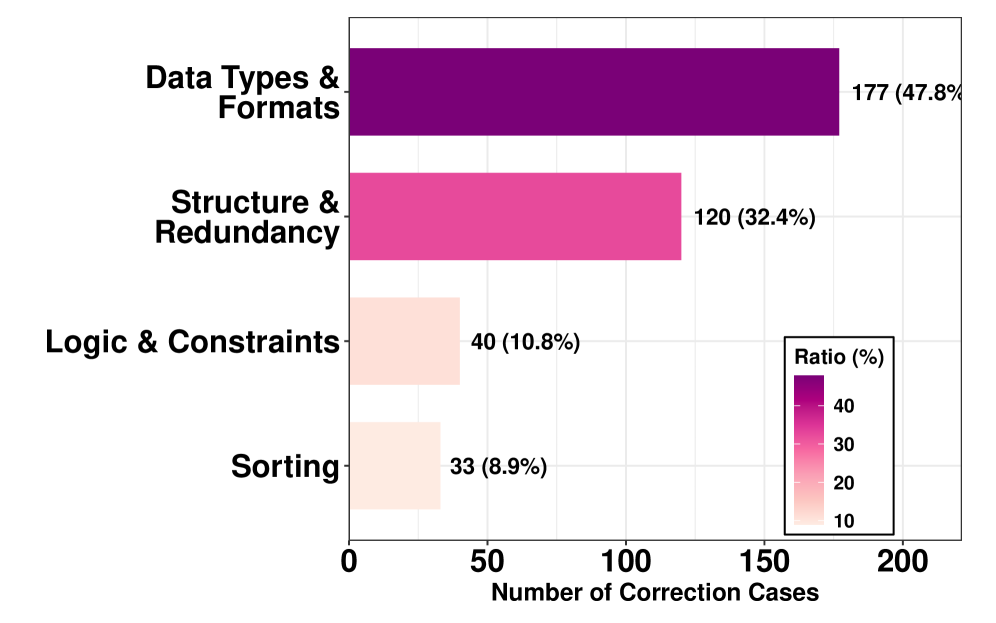
Предложенный фреймворк логического завершения (LCF) представляет собой перспективный подход к преодолению пробелов в знаниях и повышению точности систем преобразования естественного языка в SQL и Python. LCF эффективно дополняет скрытые знания предметной области, позволяя более корректно интерпретировать неоднозначные запросы и генерировать надежные инструкции. Это особенно важно в ситуациях, когда модели сталкиваются с информацией, отсутствующей в обучающих данных, или с задачами, требующими логических выводов, выходящих за рамки простого сопоставления шаблонов. Внедрение LCF позволяет значительно улучшить производительность языковых моделей, приближая их к уровню экспертных систем и открывая новые возможности для создания интуитивно понятных и эффективных интерфейсов взаимодействия человека и компьютера.
Предложенный фреймворк Logic Completion Framework (LCF) демонстрирует способность значительно повышать точность интерпретации неоднозначных запросов и генерации надёжных инструкций за счёт дополнения скрытых знаний в предметной области. В ходе исследований установлено, что применение LCF к модели Qwen3-7B позволило увеличить её производительность с 53.19% до 71.19%, а для Qwen3-Max наблюдалось улучшение приблизительно на 9 процентных пунктов. Такой подход позволяет системам более эффективно справляться с неполной или расплывчатой информацией, что особенно важно при создании интуитивно понятных и эффективных интерфейсов взаимодействия между человеком и компьютером.
Разработанный фреймворк демонстрирует значительный потенциал для развития исследований в области естественных языковых интерфейсов (NLI), открывая путь к более интуитивному и эффективному взаимодействию человека с компьютером. Примечательно, что применение фреймворка к модели Qwen3-32B позволило достичь точности в 72.49%, что сопоставимо с результатами, демонстрируемыми традиционными SQL-системами (72.75%). Данный показатель свидетельствует о перспективности подхода для создания систем, способных понимать и выполнять запросы на естественном языке с высокой точностью, что является ключевым шагом на пути к более удобным и доступным технологиям.
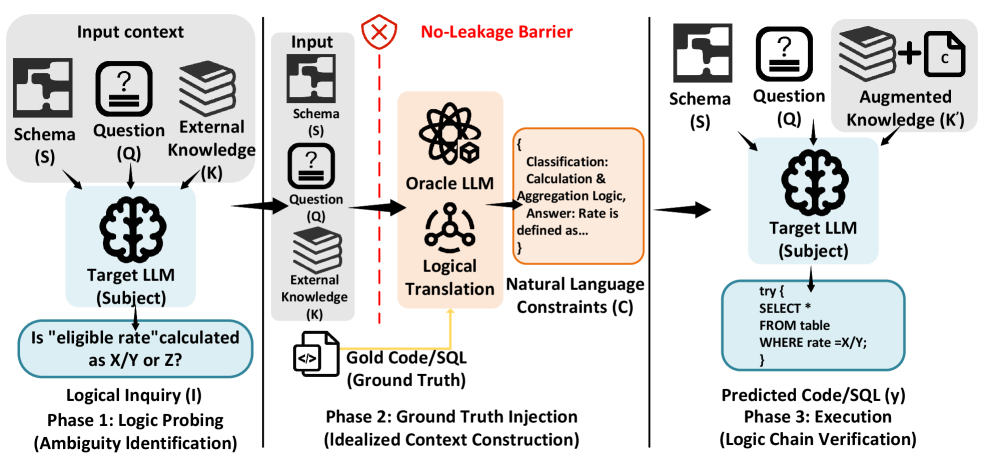
Исследование демонстрирует, что переход от обработки естественного языка к конкретным языкам программирования, таким как Python, требует от моделей не только понимания синтаксиса, но и способности к логическому завершению. Отсутствие явной информации в запросе становится критическим препятствием, поскольку система, в отличие от человека, не способна к интуитивным догадкам. Как отмечал Алан Тьюринг: «Иногда люди, которые кажутся сумасшедшими, просто видят вещи, которые другие не видят.». В контексте данной работы это можно интерпретировать как необходимость для моделей «видеть» скрытые логические связи и завершать недостающую информацию, чтобы успешно переводить запросы в работающий код. Устойчивость системы, как показало исследование, напрямую зависит от способности к контекстному завершению и разрешению неоднозначности.
Куда дальше?
Представленная работа выявила любопытную закономерность: способность больших языковых моделей генерировать код на Python, хоть и сопоставима с их умением формировать SQL-запросы, оказывается более уязвима к неполноте исходных данных. Эта чувствительность — не просто техническая деталь, а отражение фундаментального принципа: элегантная система, требующая явного логического завершения, становится заложницей недостающих элементов. Можно построить мост, но без понимания течения реки он обречен на разрушение.
Дальнейшие исследования должны сосредоточиться не столько на улучшении отдельных алгоритмов, сколько на создании механизмов, способных самостоятельно восполнять пробелы в информации. Недостаточно научить модель писать код; необходимо научить ее понимать контекст, предполагать намерения и, возможно, даже задавать уточняющие вопросы. Иначе мы получим лишь изящные, но хрупкие конструкции.
Перспективы лежат в области развития систем, способных к логическому завершению не только кода, но и самой задачи. Это требует выхода за рамки простого сопоставления текста и кода и перехода к пониманию глубинного смысла запроса. Иначе говоря, необходимо научить машину не просто выполнять команды, а мыслить.
Оригинал статьи: https://arxiv.org/pdf/2601.15728.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Кванты в Финансах: Не Шутка!
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Кватернионы в машинном обучении: новый взгляд на обработку данных
- Квантовые сети для моделирования молекул: новый подход
- Ускорение оптимального управления: параллельные вычисления в QPALM-OCP
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
2026-01-24 23:30