Автор: Денис Аветисян
Исследователи разработали инновационный метод для анализа внутренних механизмов моделей машинного обучения, предназначенных для изучения белков, позволяющий понять, как эти модели принимают решения.
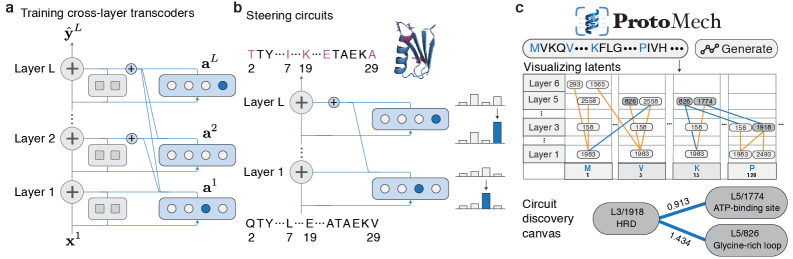
Представлен фреймворк ProtoMech, использующий кросс-слойные транскодеры для обнаружения и анализа вычислительных цепей внутри моделей языка белков, достигая передовых результатов в восстановлении поведения моделей и идентификации биологически релевантных мотивов.
Несмотря на впечатляющую способность предсказывать структуру и функцию белков, механизмы, лежащие в основе работы моделей языка белков, остаются малоизученными. В статье ‘Protein Circuit Tracing via Cross-layer Transcoders’ представлен новый подход — ProtoMech, позволяющий выявлять вычислительные цепи в этих моделях с помощью кросс-слойных транскодеров. Разработанный фреймворк демонстрирует высокую эффективность в восстановлении исходной производительности модели и выявлении ключевых мотивов, связанных со структурными и функциональными особенностями белков. Возможно ли с помощью ProtoMech разработать принципиально новые стратегии проектирования белков с заданными свойствами и предсказать их поведение в сложных биологических системах?
Разгадывая Интеллект Белка: Необходимость Открытия Схем
Языковые модели белков, такие как ESM2, демонстрируют впечатляющую способность предсказывать структуру и функцию белков, превосходя традиционные методы биоинформатики. Однако, несмотря на свою эффективность, эти модели остаются в значительной степени “черными ящиками”. Принцип их работы, внутренние механизмы принятия решений и логика, лежащая в основе предсказаний, остаются непрозрачными. Это затрудняет не только понимание биологических процессов, но и рациональное проектирование новых белков с заданными свойствами. Хотя ESM2 способна генерировать правдоподобные последовательности и структуры, отсутствие интерпретируемости ограничивает возможности использования её потенциала в фундаментальных исследованиях и прикладных задачах, таких как разработка лекарств и создание новых биоматериалов.
Понимание внутренних вычислений языковых моделей белков (PLM), таких как ESM2, имеет решающее значение для рационального дизайна белков и предсказания их функций. В отличие от традиционных методов, полагающихся на эмпирические наблюдения, глубокий анализ логики работы PLM позволяет не просто предсказывать свойства белков, но и целенаправленно конструировать новые белковые структуры с заданными характеристиками. Это открывает возможности для создания ферментов с повышенной активностью, лекарственных препаратов с улучшенной биодоступностью и материалов с уникальными свойствами. Способность деконструировать сложные взаимосвязи внутри PLM позволяет исследователям перейти от простого «угадывания» к осознанному проектированию белковых систем, значительно ускоряя процесс разработки новых биотехнологий и медицинских решений.
Современные методы анализа, применяемые к моделям языка белков (PLM), сталкиваются с серьезными трудностями в выделении дискретных, интерпретируемых компонентов, управляющих их функционированием. Несмотря на впечатляющие способности, такие как ESM2, внутренние вычисления этих моделей остаются непрозрачными, что препятствует рациональному проектированию белков и точному предсказанию их функций. Отсутствие возможности четко определить, какие элементы внутри PLM отвечают за конкретные аспекты обработки информации, ограничивает потенциал манипулирования этими моделями и использования их в полной мере для создания новых белков с заданными свойствами. Преодоление этой проблемы требует разработки принципиально новых подходов, позволяющих «разбирать» PLM на отдельные, понятные модули и понимать их взаимодействие.

ProtoMech: Разоблачение Вычислительной Сущности PLM
В основе ProtoMech лежит использование Cross-Layer Transcoders (CLTs) — механизмов, преобразующих скрытые состояния языковой модели (PLM) в пространство меньшей размерности — латентное пространство. CLTs осуществляют сопоставление между входными и выходными данными для каждого слоя PLM, позволяя снизить вычислительную сложность и объем данных, необходимых для представления информации. Данное преобразование позволяет сохранить ключевые характеристики исходных скрытых состояний, представляя их в более компактном виде, что необходимо для последующего анализа и построения упрощенной модели.
Ключевым аспектом работы Cross-Layer Transcoders (CLT) является изучение отображения входных и выходных данных для каждого слоя модели PLM. Этот процесс позволяет CLT фиксировать прохождение информации по всей сети, определяя, как данные преобразуются и передаются между последовательными слоями. В результате, CLT создают представление о потоке данных, отражающее зависимости между различными частями модели и позволяющее реконструировать процесс вычислений, выполняемый PLM. Это отображение «вход-выход» для каждого слоя является основой для построения упрощенной модели, способной эмулировать поведение оригинальной PLM.
Модель-заменитель, построенная на основе кросс-слойных трансдусеров (CLT), представляет собой упрощенную и интерпретируемую аппроксимацию вычислений исходной языковой модели (PLM). Вместо выполнения полного набора операций PLM, модель-заменитель использует трансдусеры для отображения скрытых состояний каждого слоя в пониженноразмерное латентное пространство, эффективно реконструируя выходные данные. Такой подход позволяет снизить вычислительную сложность и обеспечить возможность анализа процесса принятия решений моделью, поскольку информация, проходящая через каждый слой, представлена в более компактной и понятной форме. Фактически, модель-заменитель позволяет приблизительно воспроизвести поведение PLM, сохраняя при этом ее основные функциональные возможности, но с повышенной прозрачностью и эффективностью.

Проверка Схем: Функциональные Анализы и Классификация
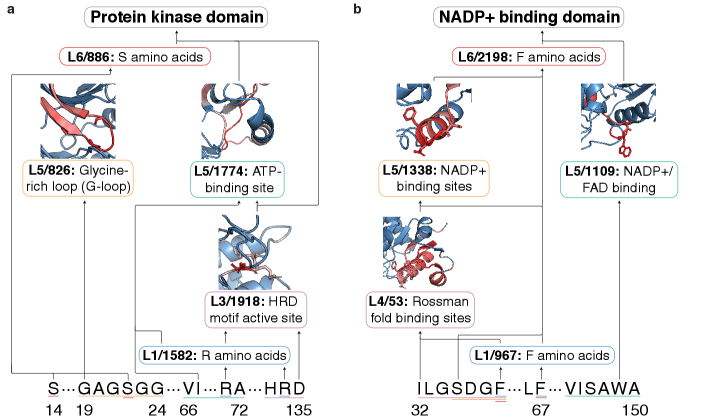
Валидация выявленных схем осуществляется посредством обучения с учителем, оценивающего их способность предсказывать принадлежность белков к определенным семействам. Этот подход предполагает использование наборов данных, содержащих информацию о структуре и функциях белков, которые используются для тренировки алгоритмов машинного обучения. Эффективность валидации определяется точностью предсказания семейства белков на основе активности выявленной схемы. Высокая точность указывает на то, что схема адекватно отражает биологические принципы, определяющие классификацию белков, и может быть использована для дальнейшего анализа и прогнозирования.
Для экспериментальной оценки влияния мутаций на пригодность (fitness) используются DMS-анализы (Deep Mutational Scanning). Данный подход позволяет оценить вклад каждой аминокислотной замены в функциональную активность белка. Полученные данные коррелируют с активностью выявленных схем (circuits), что позволяет установить связь между изменениями в структуре белка и наблюдаемыми фенотипическими эффектами. Сопоставление данных DMS-анализов и активности схем служит подтверждением валидности предложенного подхода к моделированию и пониманию сложных белковых вычислений.
В ходе валидации, методология ProtoMech демонстрирует передовые результаты в восстановлении исходной производительности моделей. Достигнута точность в 89% при классификации семейств белков и коэффициент корреляции Спирмена, равный 82%, при прогнозировании функций. Основой данного подхода является выявление минимальных наборов латентных переменных, определяющих поведение модели, что позволяет представить сложные вычислительные процессы в белках в виде упрощенной, редукционистской модели.
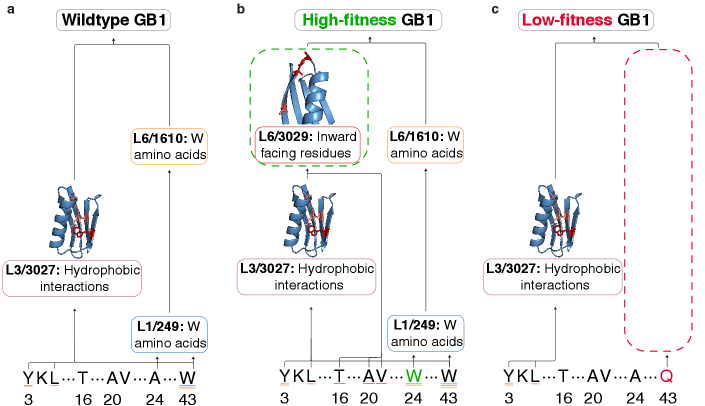
Функциональное Управление: Проектирование Белков с Точностью
Метод ProtoMech позволяет осуществлять функциональное управление белками за счет манипулирования выявленными цепями в латентном пространстве. В отличие от традиционных подходов, ProtoMech идентифицирует ключевые функциональные цепи, представляющие собой взаимосвязанные элементы в многомерном латентном пространстве белковых последовательностей. Вместо изменения всей последовательности, этот метод фокусируется исключительно на этих цепях, что позволяет целенаправленно изменять функциональные характеристики белка. Используя эту стратегию, исследователи могут эффективно «направлять» белки к желаемым свойствам, не затрагивая другие аспекты их структуры и функции. Таким образом, ProtoMech открывает новые возможности для рационального дизайна белков, предлагая точный и эффективный способ создания белков с заранее заданными характеристиками.
Визуализация связей между элементами в латентном пространстве с помощью “виртуальных весов” предоставляет уникальную возможность понять, как информация циркулирует внутри белковой структуры и как организованы ключевые функциональные цепи. Этот метод позволяет наглядно представить сложные взаимосвязи, выявляя, какие участки белка оказывают наибольшее влияние на его свойства. Анализ “виртуальных весов” дает представление об архитектуре белка, позволяя исследователям определить, какие латенты формируют основные функциональные блоки и как они взаимодействуют друг с другом. Подобное понимание не только способствует более глубокому изучению принципов работы белков, но и открывает возможности для целенаправленного изменения их свойств путем модификации ключевых связей в латентном пространстве.
Исследования показали, что ProtoMech демонстрирует сопоставимую эффективность, используя лишь небольшую часть общего латентного пространства — приблизительно 0,8%, что соответствует около 96 латентам. В процессе управления этими схемами, ProtoMech превосходит PLT в 71% случаев, что указывает на значительную оптимизацию процесса генерации последовательностей белков. Такой подход открывает перспективные возможности для рационального дизайна белков, позволяя создавать последовательности с заданными функциональными характеристиками с высокой точностью и эффективностью. Данные результаты подчеркивают потенциал ProtoMech как мощного инструмента в области биоинженерии и протеомики, способного значительно ускорить разработку новых белков для различных применений.
Исследование, представленное в данной работе, демонстрирует стремление к пониманию сложных систем, в данном случае — моделей, работающих с белками. Разработчики ProtoMech, используя кросс-слойные транскодеры, пытаются не просто описать поведение модели, но и выявить внутренние вычислительные цепи, что соответствует философскому подходу к старению систем. Как однажды заметила Ада Лавлейс: «То, что может быть выражено в математической форме, может быть выражено и в других формах, но не наоборот.» Подобно тому, как математика является универсальным языком для описания систем, ProtoMech стремится к выявлению фундаментальных принципов работы моделей обработки белков, позволяя перевести их внутреннюю логику в понятные и интерпретируемые формы. Выявление биологически релевантных мотивов и восстановление поведения модели — это шаги к зрелости системы, к пониманию ее внутренней архитектуры и, следовательно, к ее более эффективному использованию.
Что же дальше?
Представленная работа, подобно тщательному логированию жизни системы, фиксирует мгновения функционирования сложных протеиновых моделей. Однако, подобно любой хронике, она лишь отражает текущее состояние, оставляя за кадром вопрос о траектории старения и эволюции этих систем. Возможность «развертывания» — выделения вычислительных цепей — пока остается фрагментарной, подобно попыткам реконструировать сложный механизм по отдельным шестерням.
Неизбежно возникает вопрос о масштабируемости. Сможет ли ProtoMech, подобно устойчивой архитектуре, выдержать нагрузку, возникающую при анализе моделей, чья сложность превосходит существующие аналоги? Очевидно, что поиск биологически релевантных мотивов — это не просто идентификация паттернов, но и понимание их роли в контексте более широкой системы. Это требует не только вычислительной мощности, но и глубокого понимания биологических принципов.
В конечном счете, ценность подобного рода исследований заключается не в достижении «окончательного» решения, а в углублении понимания принципов, лежащих в основе сложных систем. Как и любая система, протеиновые модели стареют, эволюционируют, и, возможно, в конечном итоге, угасают. И задача исследователя — не остановить этот процесс, а понять его, чтобы достойно зафиксировать историю их существования.
Оригинал статьи: https://arxiv.org/pdf/2602.12026.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: извлечение навыков из открытого кода
- Быстрый поиск по геному: Новые алгоритмы для spaced k-mers
- Квантовые Иллюзии и Практические Шаги
- Геном под контролем: Ускорение анализа данных для персонализированной медицины
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Юридический интеллект на турецком: Новые модели для понимания права
- Искусственный интеллект нового поколения: фокус на специализированные модели
- Геометрические квантовые гейты: на пути к устойчивости
- Гибкие нейросети: как динамическая выборка меняет правила игры
- Искусственный глаз: Как отличить реальное изображение от сгенерированного ИИ
2026-02-15 07:07