Автор: Денис Аветисян
Новое исследование позволяет проследить, какие именно данные из обучающей выборки формируют внутренние механизмы больших языковых моделей.

Предложена методика (MDA) для атрибуции данных, влияющих на формирование ‘индукционных голов’ в больших языковых моделях и позволяющая проводить каузальные интервенции.
Несмотря на успехи в механической интерпретируемости больших языковых моделей (LLM), остаются неясными причины формирования конкретных интерпретируемых схем в процессе обучения. В работе ‘Mechanistic Data Attribution: Tracing the Training Origins of Interpretable LLM Units’ представлен новый фреймворк (MDA), позволяющий выявить образцы обучающих данных, ответственные за формирование определенных функциональных блоков, таких как «индуктивные головы». Эксперименты показали, что целенаправленное изменение небольшого процента наиболее влиятельных образцов данных существенно влияет на появление этих блоков, в то время как случайные изменения не оказывают эффекта, подтверждая связь между структурой данных (например, \LaTeX, XML) и формированием схем, а также их влиянием на возможности контекстного обучения. Каким образом можно использовать эти знания для целенаправленного ускорения развития LLM и повышения их надежности?
Раскрытие Скрытого Влияния в Обучающих Данных
Современные большие языковые модели (БЯМ) демонстрируют впечатляющую способность к распознаванию закономерностей, однако эта сила напрямую связана с огромными объемами данных, на которых они обучаются. В связи с этим возникает закономерная обеспокоенность: отдельные примеры из обучающего набора могут оказывать непропорционально большое влияние на поведение модели, определяя её склонности и предвзятости. По сути, некоторые текстовые фрагменты способны «перевесить» остальные, формируя нежелательные ответы или усиливая существующие стереотипы. Понимание того, какие именно примеры оказывают наибольшее влияние, становится критически важным для обеспечения надежности, справедливости и предсказуемости БЯМ.
Определение ключевых, оказывающих существенное влияние примеров в обучающих данных имеет первостепенное значение для понимания и потенциального смягчения нежелательного поведения больших языковых моделей. Эти примеры, даже составляя незначительную часть общего набора, могут непропорционально сильно влиять на выходные данные модели, формируя её предвзятости, усиливая стереотипы или приводя к генерации неточных или вводящих в заблуждение ответов. Выявление таких “влиятельных” образцов позволяет не только лучше понять внутреннюю работу модели, но и разработать стратегии для исправления её поведения — будь то удаление проблемных примеров, перевзвешивание данных или применение методов регуляризации, направленных на снижение влияния отдельных образцов. Таким образом, анализ влияния примеров — это важный шаг к созданию более надежных, безопасных и этичных языковых моделей.
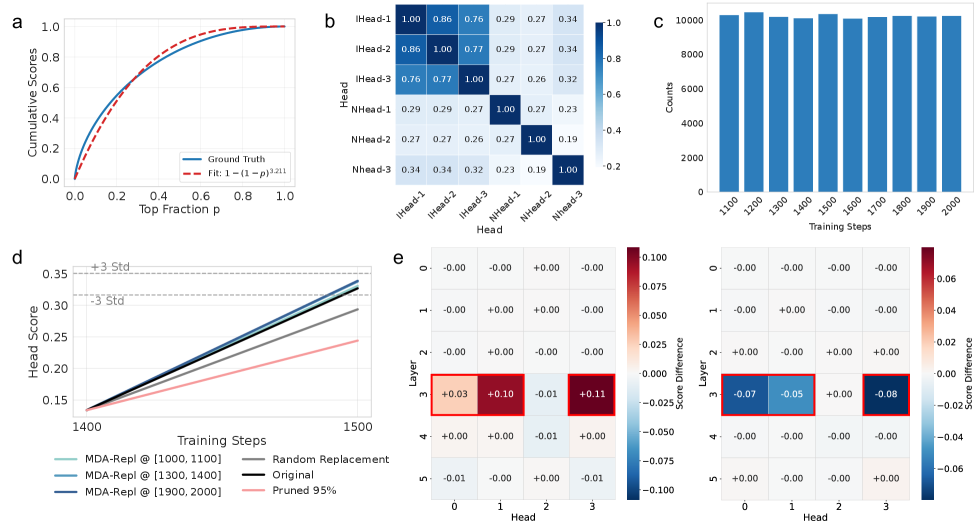
Анализ влияния отдельных примеров обучающей выборки на поведение больших языковых моделей (LLM) традиционно требует значительных вычислительных ресурсов, что делает его практически невозможным при работе с современными моделями. Исследование показало, что распределение оценок влияния подчиняется степенному закону с показателем, приблизительно равным 3. Этот закономерный характер распределения, устойчивый в моделях различного масштаба — от 14 миллионов до 160 миллионов параметров — позволяет разработать более эффективные алгоритмы выявления наиболее влиятельных примеров и, как следствие, более глубокое понимание и контроль над поведением LLM. Обнаруженная зависимость открывает перспективы для создания методов, позволяющих с меньшими затратами оценивать и корректировать влияние отдельных данных на работу языковых моделей.
Эффективный Расчет Влияния с Использованием Аппроксимированной Кривизны
Предлагаемый метод, Eigenvalue-corrected Kronecker-Factored Approximate Curvature (EK-FAC), обеспечивает эффективную оценку матрицы Фишера, являющейся ключевым компонентом для количественной оценки влияния данных на модель. EK-FAC использует аппроксимацию кривизны, основанную на факторизации Кронекера и коррекции собственных значений, что позволяет значительно снизить вычислительные затраты по сравнению с точным вычислением гессиана. Фактически, \hat{F} = \hat{J}^T\hat{J}, где \hat{J} — аппроксимация Якобиана, а \hat{F} — оценка матрицы Фишера. Такая аппроксимация позволяет оценить вклад отдельных обучающих примеров в параметры и поведение большой языковой модели, что необходимо для анализа влияния данных.
Метод Eigenvalue-corrected Kronecker-Factored Approximate Curvature (EK-FAC) обеспечивает существенное снижение вычислительных затрат по сравнению с вычислением точной матрицы Гессе, что критически важно для анализа влияния данных в контексте больших языковых моделей. Вычисление точной матрицы Гессе имеет сложность O(N^2), где N — количество параметров модели, что делает его непрактичным для LLM с миллиардами параметров. EK-FAC использует аппроксимацию на основе факторизации Кронекера и коррекции собственных значений, снижая вычислительную сложность до O(N) или даже меньше в некоторых реализациях. Это позволяет проводить анализ влияния на масштабе, недостижимом для точных методов, и идентифицировать наиболее влиятельные обучающие примеры без чрезмерных вычислительных ресурсов.
Предложенный метод позволяет выявлять обучающие примеры, оказывающие наибольшее влияние на параметры и поведение больших языковых моделей (LLM). Основываясь на оценке вклада каждого примера в изменение параметров модели, можно определить наиболее значимые образцы, которые существенно влияют на процесс обучения и конечные результаты. Это достигается путем анализа чувствительности параметров модели к изменениям в обучающих данных, что позволяет ранжировать примеры по степени их влияния и выявлять потенциальные источники смещения или нежелательного поведения модели. Идентификация таких примеров критически важна для улучшения качества модели, повышения её надежности и обеспечения соответствия заданным требованиям.
Долгосрочные Повторяющиеся Структуры как Индикаторы Влияния
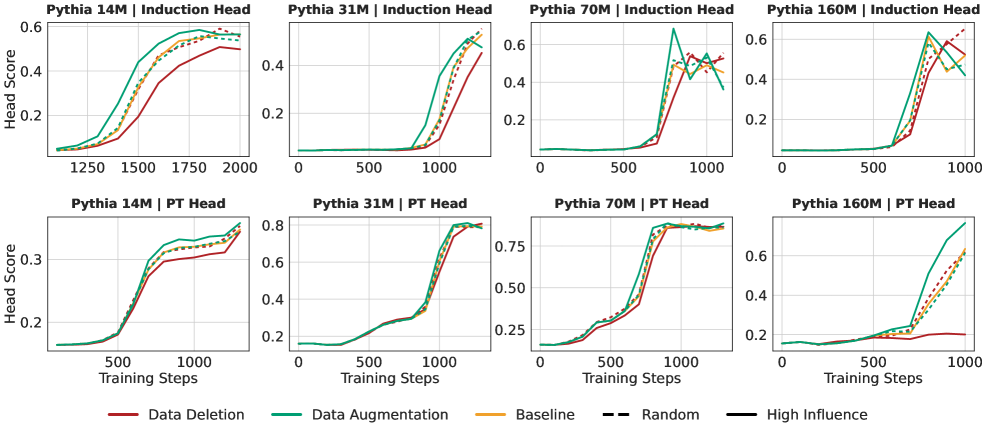
Анализ данных обучения показал, что образцы, оказывающие наибольшее влияние на поведение больших языковых моделей (LLM), часто характеризуются наличием длинных повторяющихся структур — закономерностей, состоящих из повторяющихся последовательностей элементов на значительном расстоянии друг от друга. Эти структуры не являются случайными; их частота и протяженность коррелируют с величиной влияния образца на итоговые результаты модели. Наблюдается, что такие повторяющиеся последовательности могут простираться на сотни и даже тысячи токенов, что существенно превышает типичную длину контекстного окна, рассматриваемую в более простых моделях обработки последовательностей. Выявление и количественная оценка этих структур позволяет оценить потенциальное влияние конкретного обучающего образца и оптимизировать процесс обучения LLM.
Наблюдения показывают, что наличие длинных повторяющихся структур в обучающих примерах коррелирует с усилением определенных связей внутри языковой модели (LLM). Эти структуры, представляя собой последовательности, повторяющиеся на значительных расстояниях, способствуют укреплению весов синапсов, отвечающих за обработку этих последовательностей. В результате, при последующей генерации текста, модель демонстрирует повышенную склонность к воспроизведению или акцентированию элементов, соответствующих этим усиленным связям, что в конечном итоге влияет на ее поведение и выходные данные. Усиление связей, вызванное повторяющимися структурами, приводит к более выраженному вкладу соответствующих нейронов в процесс принятия решений моделью.
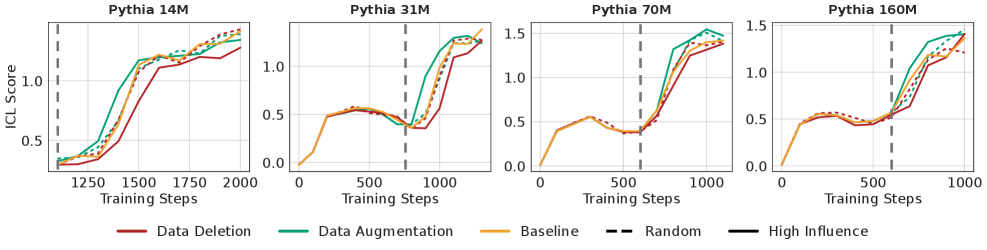
Внутренние механизмы внимания в больших языковых моделях (LLM), в частности так называемые «индукционные головы» (Induction Heads), демонстрируют высокую эффективность в захвате и воспроизведении длинных повторяющихся структур в обучающих данных. Эти головы специализируются на копировании и завершении закономерностей, что позволяет им эффективно обрабатывать последовательности с повторяющимися элементами на значительных расстояниях. Экспериментальные данные показывают, что целенаправленные изменения в топ-10% наиболее влиятельных обучающих примеров оказывают существенное влияние на формирование и функционирование индукционных голов, что указывает на их ключевую роль в усвоении и использовании информации, содержащей длинные повторяющиеся структуры.
Расширение Данных с Использованием Синтетических Данных, Генерируемых LLM
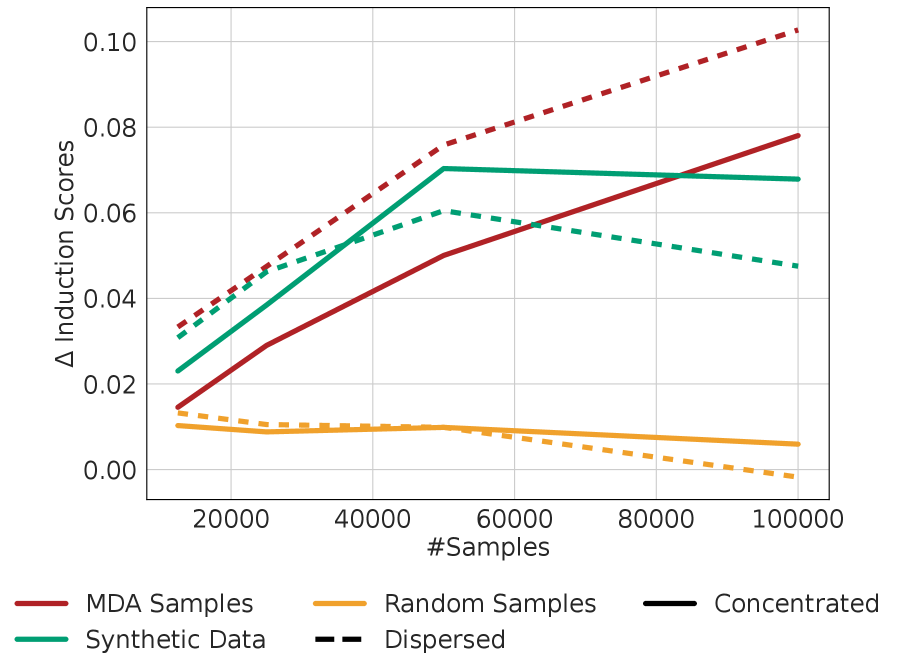
Исследование демонстрирует, что синтетические данные, генерируемые языковой моделью на основе выявленных закономерностей в наиболее значимых образцах обучающей выборки, способны существенно улучшить способность модели к обучению с подсказками (In-Context Learning, ICL). Создание искусственных данных, имитирующих ключевые признаки, позволяет усилить внутренние механизмы обработки информации, отвечающие за распознавание и завершение паттернов. В результате, модель не только эффективнее усваивает информацию из небольшого числа примеров, представленных в подсказке, но и демонстрирует повышенную обобщающую способность, что особенно важно при работе с новыми, ранее не встречавшимися задачами. Данный подход позволяет значительно повысить производительность языковой модели без необходимости увеличения объема исходных обучающих данных.
Исследования показали, что применение метода расширения данных посредством генерации синтетических примеров значительно укрепляет функциональные цепи, отвечающие за распознавание и завершение паттернов в больших языковых моделях. Данные цепи, формирующиеся в процессе обучения, становятся более устойчивыми к новым, ранее не встречавшимся данным, что существенно повышает обобщающую способность модели. Усиление этих функциональных цепей позволяет языковой модели не просто запоминать тренировочные примеры, но и экстраполировать полученные знания, эффективно применяя их к широкому спектру задач и контекстов. Этот процесс позволяет модели более надежно выявлять и использовать ключевые закономерности, что приводит к улучшению качества предсказаний и повышению общей производительности.
Исследование показало, что целенаправленное расширение обучающего набора с помощью синтетических примеров позволяет эффективно направлять процесс обучения языковой модели, акцентируя её внимание на ключевых закономерностях. Анализ влияния этих примеров выявил преобладание позитивных сигналов над негативными — сумма оценок положительного влияния превысила абсолютную сумму оценок отрицательного. Это свидетельствует о формировании функциональных схем, способных к эффективному распознаванию и завершению паттернов, что, в свою очередь, значительно повышает обобщающую способность модели и её способность к обучению в контексте (In-Context Learning). Таким образом, стратегическое добавление синтетических данных позволяет не просто увеличить объем обучающей выборки, а сформировать в модели приоритеты в отношении наиболее значимых признаков.
К Надежному и Эффективному Обучению LLM: Перспективы на Будущее
Исследования демонстрируют, что учет геометрических свойств так называемого «ландшафта потерь» играет ключевую роль в эффективной и устойчивой тренировке больших языковых моделей (LLM). Традиционные методы оптимизации, основанные на градиентном спуске, зачастую игнорируют кривизну этого ландшафта, что приводит к медленной сходимости и риску застревания в локальных минимумах. Вместо этого, разработанные подходы, такие как метод «натурального градиента», учитывают риманову метрику — математический инструмент, позволяющий измерять расстояния и углы на искривленных поверхностях. Применение метода «натурального градиента» позволяет более эффективно «навигировать» по ландшафту потерь, адаптируясь к его геометрии и ускоряя процесс обучения, что особенно важно для сложных моделей, требующих огромных вычислительных ресурсов. \nabla_{\Theta} L(f(\Theta)) — пример градиента потерь, который корректируется в рамках метода «натурального градиента».
Исследования демонстрируют, что эффективность обучения больших языковых моделей (LLM) тесно связана со структурой обучающих данных и кривизной пространства параметров модели. Понимание этого взаимодействия позволяет разрабатывать стратегии обучения, которые не просто минимизируют функцию потерь, но и учитывают геометрию этого процесса. В частности, данные с определенной структурой могут требовать иных методов оптимизации, чем данные, распределенные более равномерно. Использование методов, учитывающих кривизну, таких как оптимизация на основе естественного градиента, позволяет адаптировать шаг обучения к локальным особенностям пространства параметров, что приводит к более быстрой сходимости и повышению устойчивости к переобучению. Таким образом, фокусировка на взаимосвязи между структурой данных и кривизной модели представляет собой перспективный путь к созданию более эффективных и надежных LLM.
Перспективные исследования направлены на расширение принципов, выявленных при обучении больших языковых моделей, на другие области глубокого обучения. Особое внимание уделяется возможности применения методов, учитывающих геометрические свойства пространства потерь, к задачам компьютерного зрения и обработки временных рядов. Предполагается, что учет кривизны и структуры данных позволит не только ускорить процесс обучения, но и повысить интерпретируемость полученных моделей, что особенно важно для критически важных приложений. Разработка алгоритмов, позволяющих контролировать траекторию обучения и избегать локальных минимумов, может привести к созданию более надежных и предсказуемых систем искусственного интеллекта, способных к более эффективному обобщению и адаптации к новым данным.
Представленное исследование демонстрирует стремление к выявлению фундаментальных принципов, лежащих в основе функционирования больших языковых моделей. Авторы, подобно математикам, ищут не просто эмпирически подтвержденные закономерности, а причинно-следственные связи, определяющие формирование внутренних механизмов, таких как ‘индукционные головы’. Как однажды заметил Роберт Тарьян: «Простота — это ключ к надежности». Эта фраза особенно актуальна в контексте механической интерпретируемости, где стремление к прозрачности и пониманию внутренних процессов модели позволяет не только контролировать ее поведение, но и гарантировать корректность принимаемых решений, выявляя влияние конкретных данных на формирование этих самых механизмов. Использование фреймворка MDA позволяет отследить эти связи, обеспечивая более глубокое понимание и контроль над сложными системами.
Куда же это всё ведёт?
Представленный подход к атрибуции данных, выявляющий конкретные примеры обучения, формирующие внутренние механизмы больших языковых моделей, обнажает фундаментальную проблему: недостаточно просто «заставить» сеть работать, необходимо понять, как она работает. Иначе, любые вмешательства, даже кажущиеся успешными, остаются эмпирическими трюками, а не доказательными манипуляциями. Разработка более строгих метрик для оценки «чистоты» формирующихся «голов индукции» представляется критически важной. Наблюдаемая зависимость от конкретных примеров обучения подразумевает, что архитектура сети, при всей её сложности, может быть удивительно хрупкой и подверженной нежелательным «побочным эффектам» от нерепрезентативных данных.
Очевидно, что текущий фокус на «поиске» причинно-следственных связей внутри модели — это лишь первый шаг. Будущие исследования должны стремиться к созданию моделей, построенных с учётом принципов причинности, где каждый внутренний механизм будет иметь чётко определённую и доказуемую связь с конкретным аспектом входных данных. Иначе, даже самые изящные методы атрибуции данных останутся лишь постфактумным анализом сложной, но всё же чёрной коробки. В хаосе данных спасает только математическая дисциплина.
Неизбежно возникает вопрос о масштабируемости. Применимо ли это к моделям, содержащим триллионы параметров? Вероятно, потребуются новые, более компактные архитектуры, или же, что более вероятно, принципиально иные подходы к интерпретации, позволяющие экстраполировать понимание, полученное на небольших моделях, на более крупные. В противном случае, мы рискуем остаться с огромными, непонятными системами, управляемыми лишь статистической случайностью.
Оригинал статьи: https://arxiv.org/pdf/2601.21996.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Кванты в Финансах: Не Шутка!
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый оптимизатор: Новый подход к сложным задачам
- Оптимизация Комбинаторных Задач: Новый Взгляд с Помощью Автокодировщиков
- Волны спинов для нейроморфных вычислений: новый подход к скорости и эффективности
2026-01-31 15:29