Автор: Денис Аветисян
Представлен PubMed-OCR — обширный набор данных, содержащий научные статьи с детализированными аннотациями, полученными с помощью оптического распознавания символов.
Датасет содержит аннотации на уровне параграфов, строк и слов, полученные непосредственно из изображений страниц научных статей PubMed, и предназначен для исследований в области понимания документов.
Несмотря на растущий объем научной литературы в открытом доступе, ее эффективная обработка и анализ остаются сложной задачей. В данной работе представлена база данных ‘PubMed-OCR: PMC Open Access OCR Annotations’ — крупномасштабный корпус научных статей, полученных из PDF-документов PubMed Central, с аннотациями на уровне слов, строк и абзацев, созданными с помощью оптического распознавания символов. Это обеспечивает надежный ресурс для исследований в области понимания документов и позволяет решать задачи, связанные с анализом макета и поиском ответов на вопросы, основанные на координатах текста. Какие новые возможности для автоматизированного извлечения знаний из научной литературы открывает использование детальных аннотаций, полученных с помощью OCR?
От PDF к Пикселям: Эволюция Наборов Данных для Оптического Распознавания
Традиционно понимание документов основывалось на разборе структурированных PDF-файлов и их сопоставлении с XML-представлениями. Методики, такие как PMCOA XML Alignment и PDF/XML Alignment, служили основой для извлечения информации, полагаясь на четкую структуру исходного документа. Этот подход предполагал наличие текстового слоя, позволяющего алгоритмам идентифицировать и интерпретировать различные элементы — заголовки, абзацы, таблицы и прочее. Однако, эффективность подобных систем напрямую зависела от качества разметки и структурированности PDF, что ограничивало их применимость к документам со сложной или отсутствующей структурой. Разработка и совершенствование этих методов требовало значительных усилий по поддержанию соответствия между визуальным представлением и текстовой информацией, что представляло собой существенную проблему при работе с большими объемами документов.
В последнее время наблюдается устойчивый рост объема научной литературы, доступной исключительно в виде отсканированных изображений. Это обстоятельство обуславливает необходимость перехода к методам, ориентированным на оптическое распознавание символов (OCR) и непосредственную обработку визуальной информации. Традиционные подходы, основанные на разборе структурированных PDF-файлов и сопоставлении их с XML-представлениями, оказываются неэффективными в отношении таких источников. В связи с этим, приоритет смещается в сторону разработки алгоритмов, способных извлекать значимую информацию непосредственно из визуального контента страниц, что требует новых подходов к построению обучающих наборов данных и оценке производительности систем анализа документов.
Переход к обработке научных документов, представленных в виде отсканированных изображений, требует принципиально новых подходов к созданию обучающих наборов данных. Традиционные методы, основанные на анализе структурированного текста, извлеченного из PDF-файлов, становятся неэффективными при работе с визуальным контентом. Возникает потребность в наборах данных, построенных непосредственно на основе изображений страниц, что стимулирует развитие алгоритмов, способных извлекать информацию непосредственно из визуальных представлений. Такой подход позволяет обрабатывать огромный объем научной литературы, существующей только в виде сканов, и открывает возможности для более точного и надежного анализа научных текстов, невзирая на качество исходного изображения или сложность его структуры.
Для преодоления ограничений, связанных с обработкой только структурированных PDF-документов, был создан набор данных PubMed-OCR, содержащий 1,5 миллиона страниц, полученных из статей PMCOA. Этот объем значительно превосходит существующий набор данных IIT-CDIP, включающий 825 тысяч страниц, обработанных методом оптического распознавания символов (OCR). Предоставление столь масштабного ресурса позволяет исследователям разрабатывать и обучать алгоритмы, способные извлекать информацию непосредственно из визуальных представлений научных статей, а не полагаться на предварительно структурированные текстовые данные. Набор данных PubMed-OCR открывает новые возможности для автоматизированного анализа научной литературы, особенно в случаях, когда исходные документы доступны лишь в виде сканированных изображений.

PubMed-OCR: Фундамент для Визуального Анализа Документов
PubMed-OCR разработан для преодоления ограничений существующих методов путем создания набора данных, основанного на изображениях страниц из PubMed Central Open Access. Использование открытого архива PubMed Central позволяет обеспечить доступность и масштабируемость данных для обучения моделей оптического распознавания символов (OCR). Набор данных формируется непосредственно из изображений научных статей, что обеспечивает соответствие реальным условиям использования и позволяет создавать более надежные и точные системы OCR, способные обрабатывать сложные научные публикации.
Набор данных PubMed-OCR использует технологию оптического распознавания символов (OCR) Google Vision для автоматической генерации аннотаций на уровне слов, строк и абзацев. Эти аннотации предоставляют необходимую информацию для обучения моделей, способных понимать структуру визуальных документов, включая распознавание и интерпретацию взаимосвязей между текстовыми элементами. Автоматизированный процесс аннотирования обеспечивает масштабность и воспроизводимость, необходимые для создания надежного набора данных для обучения и оценки алгоритмов анализа визуальных документов.
В отличие от традиционных методов оптического распознавания символов (OCR), PubMed-OCR реализует концепцию «заземленного OCR» путем предоставления информации о ограничивающих прямоугольниках (bounding boxes) для каждого текстового элемента. Это позволяет сохранять пространственные взаимосвязи между словами, строками и абзацами на странице, что критически важно для обучения моделей, учитывающих структуру документа (Layout-Aware Modeling). Предоставление координат ограничивающих прямоугольников позволяет алгоритмам понимать визуальную организацию текста, например, расположение заголовков, списков и таблиц, что значительно повышает точность распознавания и извлечения информации.
Набор данных PubMed-OCR, состоящий из 1,5 миллиона страниц, обеспечивает значительно более детальную аннотацию по сравнению с OCR-IDL. Несмотря на меньшее количество документов и страниц, PubMed-OCR содержит в 4 раза больше аннотаций строк и в 10 раз больше аннотаций слов. Это существенное увеличение объема аннотаций предоставляет более широкие возможности для обучения моделей оптического распознавания символов (OCR) и анализа структуры визуальных документов.
Набор данных PubMed-OCR характеризуется значительным объемом текстовой информации на каждой единице документа. В среднем, каждый документ состоит из 7.4 страниц, на каждой из которых содержится приблизительно 39.5 абзацев. Каждая страница содержит в среднем 106.3 строки текста, что соответствует примерно 844 словам. Данные показатели демонстрируют высокую плотность текстовой информации и позволяют использовать набор данных для обучения моделей, способных эффективно анализировать и понимать сложные визуальные документы.

Качественная Оценка и Уточнение Разметки
Качественный анализ аннотаций разметки являлся критически важным этапом валидации и улучшения набора данных PubMed-OCR. Этот анализ включал в себя визуальную проверку и корректировку автоматически сгенерированных аннотаций, направленную на выявление и исправление ошибок в определении границ и классификации элементов макета документа, таких как текст, изображения, таблицы и заголовки. Процесс включал ручную верификацию репрезентативной выборки документов для оценки точности и согласованности аннотаций, что позволило определить области, требующие дальнейшей автоматической или ручной доработки для обеспечения высокого качества размеченных данных.
Для качественного анализа и уточнения разметки датасета PubMed-OCR использовался модуль PP-DocLayout, предназначенный для обнаружения макета документа. PP-DocLayout осуществляет разметку областей на страницах документов, классифицируя их по 20 различным классам, определяющим типы элементов, таких как текст, заголовки, таблицы, изображения и другие структурные компоненты. Такая детализированная классификация позволяет проводить более точную оценку качества разметки и выявлять потенциальные ошибки или несоответствия в аннотациях.
Для повышения качества и согласованности аннотаций в наборе данных PubMed-OCR была использована итерация PP-DocLayout_plus-L, являющаяся развитием базового модуля PP-DocLayout. PP-DocLayout_plus-L представлял собой усовершенствованную версию, предназначенную для более точной разметки регионов на страницах документов, классифицируя их по 20 различным категориям. Внедрение данной итерации позволило стандартизировать процесс аннотирования и минимизировать расхождения в разметке, что критически важно для последующего обучения и оценки моделей распознавания структуры документов.
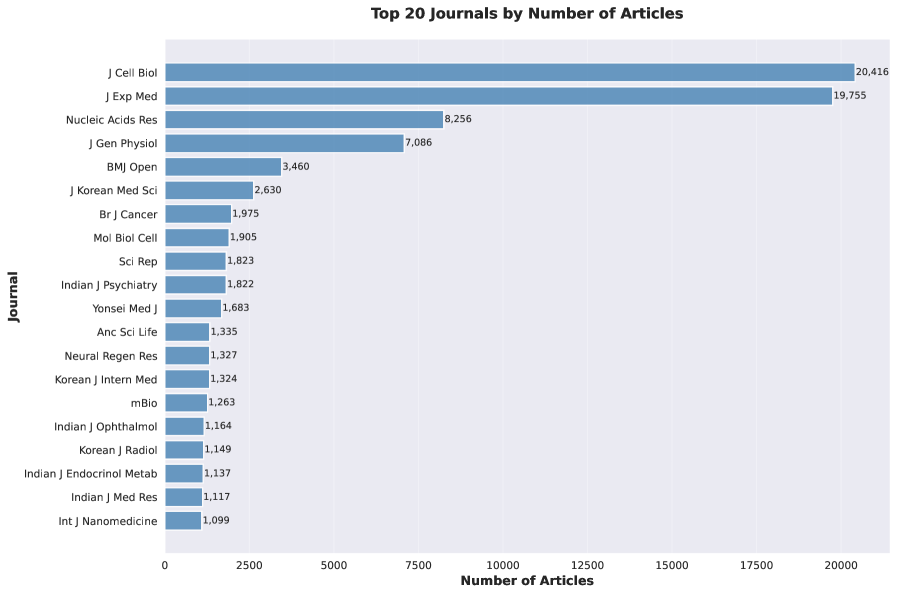
Анализ состава набора данных PubMed-OCR показал, что на три ведущих журнала приходится приблизительно 23% всех документов. При этом, несмотря на то, что одиночные журналы (встречающиеся лишь единожды) составляют 25,7% от общего числа журналов, они представлены лишь 0,3% от общего количества документов. Данное распределение указывает на значительную концентрацию данных вокруг небольшого числа наиболее часто встречающихся журналов и преобладание уникальных источников в меньшей степени.

Представленная работа демонстрирует стремление к созданию гармоничной системы обработки научных текстов. Авторы, подобно архитекторам, выстраивают фундамент для более глубокого понимания структуры документов. Как заметил Дэвид Марр: «Интеллект — это не волшебство, а расчет». Этот принцип находит отражение в подходе к созданию PubMed-OCR, где точные аннотации на уровне параграфов, строк и слов, полученные посредством OCR, позволяют машинам “рассчитывать” и понимать содержание научных статей. Наличие размеченных данных, особенно на уровне отдельных слов, является ключевым элементом для развития систем, способных к анализу и извлечению информации из сложных научных текстов, что соответствует идее о важности четкой структуры и функциональности в любой сложной системе.
Куда Ведет Эта Дорога?
Представленный набор данных PubMed-OCR, бесспорно, — шаг вперёд. Однако, эхо несовершенства OCR неизбежно. Не стоит обманываться кажущейся полнотой аннотаций; каждая неверно распознанная буква, каждая неверная граница абзаца — это диссонанс в симфонии понимания документов. Важно помнить, что совершенство — не цель, а скорее, асимптотическое приближение. Следующий этап не в увеличении масштаба, а в создании систем, способных не просто видеть текст, но и слышать его смысл, даже сквозь шум ошибок.
Проблема не ограничивается точностью распознавания. Научная литература — это не просто последовательность слов, но и сложная архитектура знаний. Следует задуматься о методах, способных улавливать тонкие связи между элементами страницы, распознавать логическую структуру аргументации, и понимать, что именно является ключевым утверждением, а что — лишь контекстом. Интерфейс, способный это сделать, действительно зазвучит гармонично.
И, наконец, стоит признать, что даже самая совершенная система не заменит вдумчивого читателя. Данные — это лишь материал, из которого создаётся понимание. Важно не просто автоматизировать процесс извлечения информации, но и создать инструменты, которые помогут человеку лучше ориентироваться в море научных публикаций. Иначе, все усилия по созданию идеальных аннотаций рискуют оказаться лишь красивой, но бесполезной мелодией.
Оригинал статьи: https://arxiv.org/pdf/2601.11425.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовый Переход: Пора Заботиться о Криптографии
- Сохраняя геометрию: Квантование для эффективных 3D-моделей
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовая обработка данных: новый подход к повышению точности моделей
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая криптография: от теории к практике
- Лунный гелий-3: Охлаждение квантового будущего
2026-01-20 21:58