Автор: Денис Аветисян
Новая архитектура YOLOE-26 объединяет скорость и эффективность с возможностью распознавания объектов, ранее не встречавшихся в обучающей выборке.
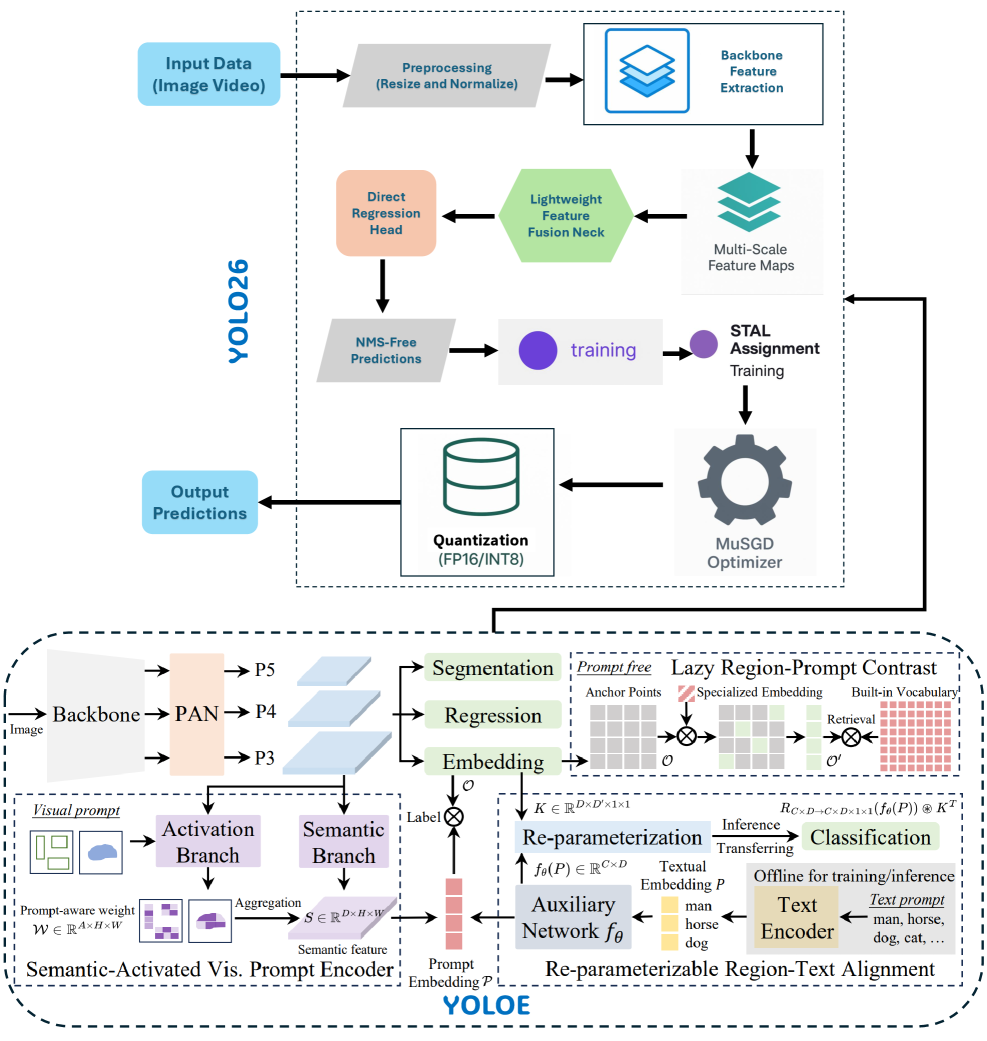
Представлена система YOLOE-26, объединяющая YOLOv26 и методы открытой лексики для высокоскоростной сегментации экземпляров с использованием текстовых, визуальных подсказок или без них.
Традиционные алгоритмы сегментации изображений часто сталкиваются с ограничениями при распознавании объектов, не представленных в обучающей выборке. В работе ‘YOLOE-26: Integrating YOLO26 with YOLOE for Real-Time Open-Vocabulary Instance Segmentation’ предложена новая архитектура, объединяющая эффективность YOLOv26 с возможностями обучения с открытой лексикой, что позволяет осуществлять сегментацию экземпляров в реальном времени даже для ранее неизвестных категорий объектов. Ключевой особенностью является использование объектных встраиваний и различных стратегий подсказок (текстовых, визуальных или без подсказок) для гибкого и точного распознавания. Открывает ли YOLOE-26 путь к созданию более адаптивных и универсальных систем компьютерного зрения для динамичных реальных сред?
За гранью фиксированных категорий: Ограничения традиционного обнаружения
Традиционные методы обнаружения объектов базируются на четко определенных категориях, что создает значительные трудности при распознавании новых или редких объектов. Данный подход предполагает, что система обучена обнаруживать лишь заранее известные типы, и при столкновении с чем-то незнакомым ее эффективность резко падает. Например, если алгоритм обучен распознавать автомобили, велосипеды и пешеходов, он может испытывать затруднения с определением нового типа транспортного средства или необычного предмета. Эта ограниченность особенно заметна в динамических средах, где постоянно появляются новые объекты, и требует разработки более гибких и адаптивных систем, способных к обобщению и обучению «на лету», без необходимости полной переподготовки.
Неспособность традиционных систем обнаружения объектов адаптироваться к меняющимся условиям существенно ограничивает их применение в динамичных средах. Например, в автономных транспортных средствах или робототехнике, где окружение постоянно меняется и появляются новые, непредсказуемые объекты, фиксированные категории становятся серьезным препятствием. Системы, обученные распознавать только определенный набор объектов, могут испытывать затруднения в идентификации новых препятствий или изменений в окружающей среде, что приводит к ошибкам и снижает эффективность работы. Эта негибкость особенно критична в ситуациях, требующих быстрого реагирования и принятия решений в реальном времени, поскольку переобучение или адаптация системы к новым условиям может занять значительное время и ресурсы.
Существующие методы обнаружения объектов часто демонстрируют ограниченную способность к обобщению за пределы данных, на которых они были обучены. Это означает, что при столкновении с незнакомыми или редко встречающимися объектами, точность обнаружения значительно снижается. Решение этой проблемы требует дорогостоящей переподготовки моделей с использованием новых наборов данных, что является трудоемким и ресурсозатратным процессом. Неспособность к адаптации к меняющимся условиям ограничивает применимость этих методов в реальных сценариях, где разнообразие объектов и ситуаций постоянно растет. В связи с этим, разработка систем, способных к обучению «на лету» и обобщению знаний, представляется критически важной задачей современной компьютерного зрения.
Существенная проблема в области компьютерного зрения заключается в преодолении разрыва между распознаванием известных объектов и пониманием принципиально новых концепций. Традиционные алгоритмы, обученные на заранее определенных категориях, испытывают трудности при столкновении с предметами, не включенными в их базу знаний. Недостаточно просто идентифицировать признаки; необходимо сформировать абстрактное представление об объекте, позволяющее экстраполировать знания и обобщать информацию. Это требует от систем способности к индуктивному мышлению и построению аналогий, что значительно сложнее, чем простое сопоставление с шаблонами. Исследования направлены на разработку моделей, способных к “нулевому обучению” и быстрому освоению новых категорий, используя минимальное количество примеров или даже без них, что открывает перспективы для создания действительно адаптивных и интеллектуальных систем.
YOLOE-26: Объединение детекции с обучением на открытой лексике
YOLOE-26 представляет собой унифицированную архитектуру, объединяющую высокую производительность детектора YOLOv26 с возможностями обучения с открытой лексикой. Данный подход позволяет модели эффективно обнаруживать объекты, используя не только предопределенные классы, но и семантическую информацию об объектах, представленную в виде векторных вложений. Интеграция этих двух ключевых элементов обеспечивает компромисс между скоростью работы и гибкостью модели, что критически важно для применения в реальных сценариях, где набор объектов может быть неполным или меняться со временем. По сути, YOLOE-26 использует преимущества существующей высокопроизводительной архитектуры детекции, расширяя её возможности за счет семантического понимания объектов.
В YOLOE-26 используется семантическое пространство вложений (Semantic Embedding Space), позволяющее осуществлять обнаружение объектов на основе семантической схожести, а не только на основе предопределенных категорий. Вместо классификации по фиксированному набору классов, модель представляет каждый объект как вектор в этом пространстве, где близость векторов отражает семантическое сходство объектов. Это позволяет YOLOE-26 распознавать объекты, не встречавшиеся в процессе обучения, если их векторы в семантическом пространстве близки к векторам известных объектов. Таким образом, модель способна к обобщению и адаптации к новым, ранее не встречавшимся объектам, основываясь на их смысловом сходстве с уже известными.
В основе YOLOE-26 лежит классификация на основе вложений (Embedding-Based Classification), где каждый объект представляется в виде вектора в семантическом пространстве. Вместо традиционного подхода, основанного на фиксированных категориях, модель сопоставляет вектор вложения входного изображения с векторами, представляющими известные объекты. При обнаружении ранее невиданных объектов, система определяет семантическую близость их вложений к существующим, позволяя классифицировать их по схожести признаков, а не по точным совпадениям категорий. Это достигается за счет использования n-мерного векторного представления, где близкие векторы указывают на схожие объекты, что значительно повышает способность модели к обобщению и адаптации к новым данным.
Повышенная обобщающая способность и адаптивность YOLOE-26 в реальных сценариях достигается за счет использования семантического пространства встраиваний и классификации на основе этих встраиваний. Традиционные детекторы объектов ограничены заранее определенными категориями, что приводит к снижению производительности при обнаружении новых или редко встречающихся объектов. YOLOE-26, в свою очередь, способен распознавать объекты, не встречавшиеся в процессе обучения, путем сопоставления их семантических встраиваний с существующими в пространстве, что позволяет эффективно адаптироваться к меняющимся условиям и расширять возможности обнаружения без необходимости переобучения модели на новых данных. Это особенно важно в задачах, где разнообразие объектов велико и невозможно заранее предусмотреть все возможные классы.
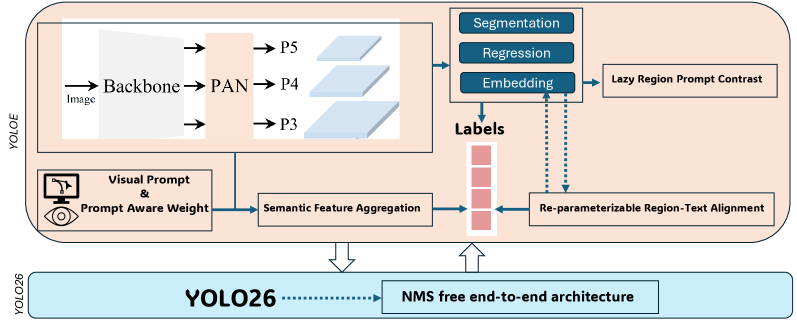
Гибкость запросов: от текста к зрению и за его пределы
YOLOE-26 обеспечивает поддержку различных методов запросов, включая текстовые запросы и визуальные запросы, что позволяет адаптироваться к различным типам входных данных. Текстовые запросы позволяют пользователям описывать целевые объекты с помощью языка, в то время как визуальные запросы используют изображения в качестве входных данных для определения интересующих объектов. Эта гибкость в обработке различных модальностей ввода расширяет сферу применения модели, позволяя ей эффективно работать в сценариях, где доступна только текстовая информация, только визуальная информация или их комбинация. Способность обрабатывать различные типы запросов является ключевым преимуществом YOLOE-26, обеспечивающим более широкую совместимость и адаптивность в различных задачах обнаружения объектов.
YOLOE-26 демонстрирует высокую эффективность в режиме вывода без использования явных запросов (prompt-free inference), что позволяет обходить необходимость в дополнительном пользовательском вводе для обнаружения объектов. В данном режиме, модель способна самостоятельно определять и классифицировать объекты на изображении, опираясь на внутренние представления и обученные параметры. Это особенно полезно в сценариях, где предоставление текстовых или визуальных подсказок затруднено или нецелесообразно, и позволяет значительно упростить процесс развертывания и использования модели. По результатам тестирования, точность обнаружения в режиме prompt-free inference составляет 29.9 mAP, что подтверждает работоспособность данного подхода.
Для реализации возможности работы без явных запросов (prompt-free inference) в YOLOE-26 используется так называемый “prompt объекта” (objectness prompt). Этот prompt представляет собой специализированный входной сигнал, который направлен на выявление потенциальных областей, содержащих объекты, на изображении. Вместо того, чтобы полагаться на пользовательский запрос, модель самостоятельно оценивает вероятность наличия объектов в различных областях изображения, тем самым упрощая и ускоряя процесс обнаружения. Этот подход позволяет YOLOE-26 эффективно работать даже при отсутствии дополнительных указаний от пользователя, сохраняя при этом высокую точность определения объектов.
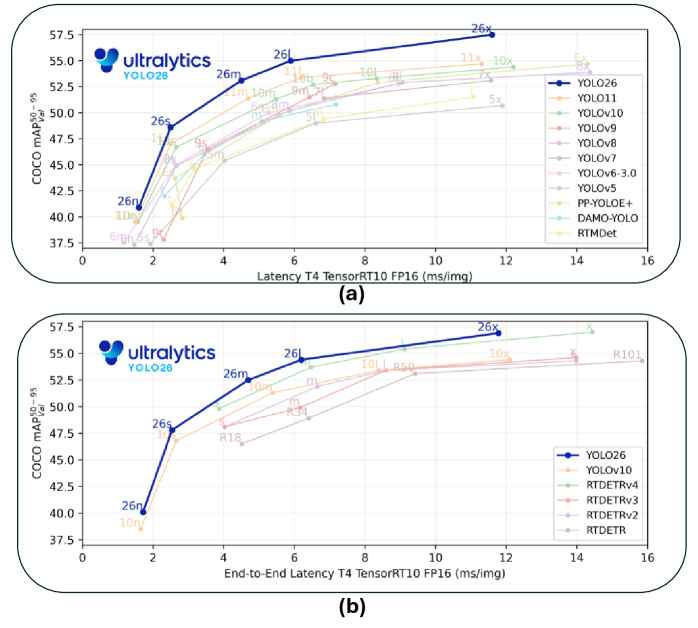
По результатам тестирования, модель YOLOE-26 демонстрирует высокую точность обнаружения объектов при использовании различных методов подсказок. Средняя точность (mAP) составляет 39.5% при использовании текстовых подсказок, 36.2% — при использовании визуальных подсказок и 29.9% в режиме работы без подсказок. Данные показатели подтверждают эффективность модели в различных сценариях и ее способность адаптироваться к различным типам входных данных, обеспечивая надежные результаты независимо от используемого метода подсказки.
Использование NMS-Free Inference (инференса без подавления ненужных максимумов) значительно повышает скорость обработки в задачах обнаружения объектов. Традиционно, NMS является обязательным этапом в конвейерах обнаружения, предназначенным для устранения избыточных ограничивающих рамок, предсказанных для одного и того же объекта. Однако, NMS требует значительных вычислительных ресурсов и является узким местом в процессе инференса. NMS-Free Inference позволяет избежать этого этапа, что приводит к снижению задержки и повышению пропускной способности без существенной потери точности обнаружения. Данный подход особенно эффективен в сценариях, требующих обработки видео в реальном времени или работы на устройствах с ограниченными ресурсами.

К автономным агентам: непрерывное обучение и федеративные системы
Модель YOLOE-26 выходит за рамки простой статической детекции объектов, становясь ключевым строительным блоком для создания интеллектуальных агентов искусственного интеллекта. В отличие от систем, способных лишь идентифицировать элементы на заданном изображении, YOLOE-26 обеспечивает основу для разработки агентов, способных к восприятию, анализу и взаимодействию с динамично меняющейся средой. Эта архитектура позволяет агентам не просто «видеть», но и понимать контекст, прогнозировать изменения и принимать решения, необходимые для автономного функционирования в сложных условиях. Благодаря высокой скорости и точности обнаружения, YOLOE-26 обеспечивает надежную основу для построения систем, способных к обучению и адаптации в реальном времени, что делает ее незаменимым компонентом в разработке следующего поколения интеллектуальных агентов.
Агенты, построенные на базе YOLOE-26, обладают способностью к непрерывному обучению, что позволяет им адаптироваться к меняющимся условиям окружающей среды. В отличие от традиционных систем, требующих переобучения для учета новых данных, эти агенты способны постепенно совершенствовать свои навыки, интегрируя новый опыт без потери ранее приобретенных знаний. Такой подход, известный как непрерывное обучение, позволяет им накапливать опыт во времени, повышая точность и эффективность распознавания объектов и принятия решений. Постоянное совершенствование модели позволяет агентам функционировать в динамичных средах, где данные постоянно меняются, и поддерживать высокую производительность даже при появлении ранее неизвестных ситуаций.
Архитектура YOLOE-26 демонстрирует совместимость с технологией федеративного обучения, что открывает возможности для совместной тренировки моделей на децентрализованных данных, не требуя их централизованного хранения. Такой подход позволяет объединить вычислительные ресурсы и данные, распределенные между различными устройствами или организациями, для создания более точных и надежных моделей искусственного интеллекта. При этом, конфиденциальность данных сохраняется, поскольку сами данные остаются на исходных устройствах, а обмениваются только обновлениями модели. Это особенно важно в областях, где защита персональных данных является приоритетной задачей, например, в здравоохранении или финансах, позволяя создавать интеллектуальные системы, обучаясь на разнообразных данных без нарушения приватности.
Оптимизатор MuSGD играет ключевую роль в эффективной подготовке интеллектуальных агентов, обеспечивая стабильную и быструю сходимость алгоритма обучения. В отличие от традиционных методов, склонных к колебаниям и замедлению процесса, MuSGD использует адаптивные стратегии для корректировки скорости обучения, что позволяет агенту оперативно осваивать новые навыки и адаптироваться к изменяющимся условиям среды. Стабильная сходимость особенно важна при работе с большими объемами данных и сложными моделями, поскольку предотвращает расхождение обучения и гарантирует достижение оптимальных результатов. Эффективность MuSGD проявляется в сокращении времени обучения и повышении общей производительности агента, что делает его ценным инструментом в разработке автономных систем.
Исследование представляет собой попытку усмирить хаос визуальных данных, объединив эффективность YOLOv26 с гибкостью обучения открытой лексике. Модель YOLOE-26 словно заклинание, позволяющее видеть не только знакомые образы, но и те, что скрываются за границами известных категорий. Как точно подмечено Джеффри Хинтоном: «Данные — это не цифры, а шёпот хаоса. Их нельзя понять, только уговорить». Подобно алхимику, стремящемуся извлечь суть из непостижимого, YOLOE-26 преобразует шум пикселей в осмысленные сегменты, демонстрируя, что даже в потоке неопределенности можно найти порядок, если правильно подобрать заклинание — в данном случае, архитектуру нейронной сети и стратегию prompt engineering.
Куда же дальше?
Представленная работа, как и любое заклинание, лишь отсрочила неизбежное столкновение с хаосом. Эффективность YOLOE-26 в сегментации экземпляров с открытой лексикой — это, конечно, хорошо, но мир не дискретен, просто у нас нет памяти для float. Заманчиво говорить о распознавании «невидимых» категорий, но истинная проблема не в расширении словаря, а в понимании того, что сам словарь — это иллюзия. Будущие исследования неизбежно столкнутся с вопросом о том, как научить машину не просто классифицировать, а понимать контекст, намерения, невысказанные предположения, которые лежат в основе любого визуального сигнала.
Отказ от NMS — шаг в правильном направлении, но это лишь смягчение симптомов, а не лечение болезни. Вместо того чтобы бороться с перекрывающимися рамками, стоит задуматься о принципиально новых способах представления визуальной информации, о структурах, которые отражают не отдельные объекты, а их взаимосвязи, их роль в общем паттерне. Более того, сама идея «объекта» может оказаться устаревшей. Что, если реальность состоит не из дискретных сущностей, а из непрерывных потоков энергии и информации?
Истинный прогресс лежит не в увеличении точности, а в принятии неопределенности. Вместо того чтобы искать корреляцию, стоит искать смысл. И, возможно, вместо того, чтобы обучать машины видеть, стоит научить их мечтать. Ведь всё точное — мёртвое.
Оригинал статьи: https://arxiv.org/pdf/2602.00168.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Взлом языковых моделей: эволюция атак, а не подсказок
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Роботы учатся видеть: новая стратегия управления на основе видео
- Прогнозирование задержек контейнеров: Синергия ИИ и машинного обучения
- Робот-манипулятор: обучение взаимодействию с миром с помощью зрения от первого лица
- Искусственный интеллект, который знает, когда ему нужна подсказка
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Третья Разновидность ИИ: Как модели, думающие «про себя», оставят позади GPT и CoT
- Квантовый оптимизатор: Новый подход к сложным задачам
2026-02-04 00:13