Автор: Денис Аветисян
Новая система OmniOCR обеспечивает высокое качество оптического распознавания символов для этнических языков, даже при ограниченных данных.
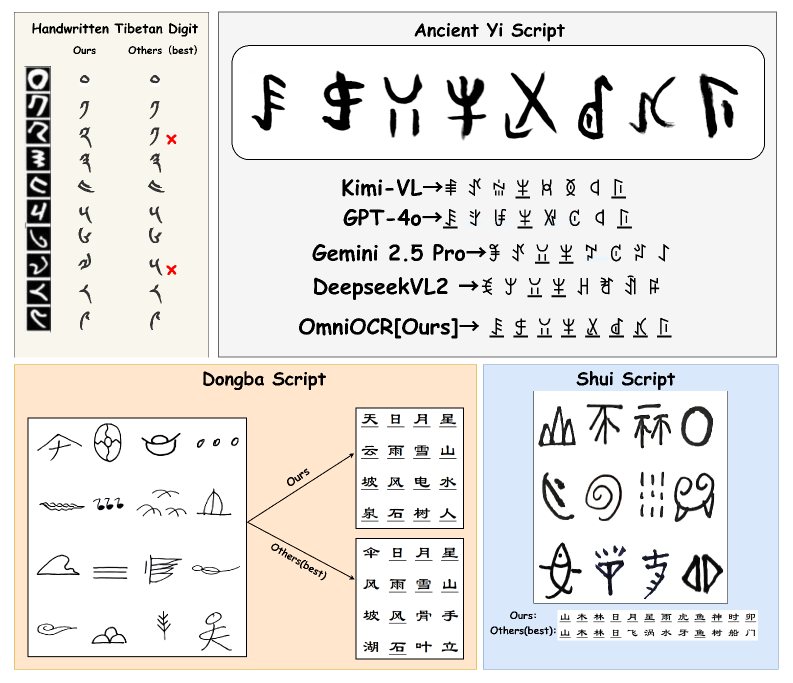
Исследователи разработали эффективный метод адаптации моделей распознавания текста с использованием Dynamic LoRA для языков с небольшим количеством ресурсов.
Несмотря на значительный прогресс в области оптического распознавания символов (OCR), большинство современных методов ориентированы преимущественно на широко распространенные языки, такие как латинский и китайский. В данной работе, представленной под названием ‘OmniOCR: Generalist OCR for Ethnic Minority Languages’, предлагается универсальный фреймворк для распознавания текстов на языках этнических меньшинств, использующий адаптацию Dynamic LoRA для эффективного перераспределения параметров модели. Достигнуты передовые результаты на наборах данных, включающих тибетский, шуйский, древний ии и донгба, демонстрируя значительное улучшение точности — до 66% — при высокой параметрической эффективности. Какие перспективы открывает OmniOCR для сохранения и оцифровки культурного наследия, представленного в малоресурсных языках?
Шёпот Утраченных Скриптов: Проблема Распознавания Редких Языков
Современные системы оптического распознавания символов (OCR) зачастую демонстрируют неудовлетворительные результаты при работе со скриптами, используемыми этническими меньшинствами и малораспространенными языками. Это связано с тем, что подавляющее большинство этих систем обучаются на больших объемах данных, представленных преимущественно распространенными языками, такими как английский, испанский или китайский. В результате, алгоритмы оказываются неспособными адекватно распознавать символы, имеющие отличные формы, структуры или контекст, что приводит к ошибкам и затрудняет оцифровку и сохранение ценного культурного наследия, зафиксированного на этих языках. Ограниченность обучающих данных для редких скриптов становится серьезным препятствием для обеспечения равного доступа к информации и цифровизации знаний для всех культурных групп.
Ограниченная эффективность систем оптического распознавания символов (OCR) в отношении нераспространенных письменностей создает ощутимые препятствия для цифровизации и сохранения культурного наследия. Многие этнолингвистические группы сталкиваются с тем, что их исторические документы, литературные произведения и личные архивы остаются недоступными в цифровом формате, что затрудняет их изучение, распространение и долгосрочное сохранение. Это не только препятствует доступу к информации для современных поколений, но и ставит под угрозу исчезновение уникальных культурных традиций, зафиксированных в письменной форме. Отсутствие адекватных инструментов оцифровки лишает возможность широкой общественности прикоснуться к богатству и разнообразию мирового культурного фонда, а также ограничивает возможности для научных исследований в области лингвистики, истории и антропологии.
Для преодоления ограничений существующих систем оптического распознавания символов (OCR) необходимы гибкие платформы, способные к обобщению при работе с разнообразными наборами символов и стилями письма. Вместо жесткой привязки к конкретному языку, такие системы должны опираться на принципы машинного обучения, позволяющие им адаптироваться к новым, ранее не встречавшимся шрифтам и структурам текста. Это достигается за счет использования нейронных сетей, способных извлекать общие закономерности из визуальных данных, а не просто сопоставлять изображения с предопределенными шаблонами. Разработка таких адаптивных фреймворков открывает возможности для оцифровки и сохранения культурного наследия этнических меньшинств, обеспечивая доступ к информации, которая ранее была недоступна в цифровом формате, и способствуя сохранению языкового разнообразия.

OmniOCR: Фундамент Адаптивного Распознавания
Основой OmniOCR является использование мощного кросс-лингвистического представления, полученного в RolmOCR. Это обеспечивает надежную базу для адаптации к новым языкам и символам без необходимости переобучения модели с нуля. RolmOCR предварительно обучен на большом объеме многоязычных данных, что позволяет ему эффективно извлекать общие признаки символов, независимо от языка. OmniOCR использует это предварительное обучение как отправную точку, что значительно снижает требования к данным и вычислительным ресурсам при адаптации к новым задачам оптического распознавания символов.
В основе OmniOCR лежит подход постобучения, позволяющий эффективно адаптировать предварительно обученную модель к новым наборам символов. Вместо полной перенастройки всех параметров, система использует лишь небольшое количество дополнительных обучающих данных для конкретного набора символов, что значительно снижает вычислительные затраты и требования к объему памяти. Такой подход позволяет быстро и экономично расширять возможности распознавания текста, добавляя поддержку новых языков или специализированных шрифтов без необходимости повторного обучения всей модели с нуля. Это особенно важно при работе с редкими или нестандартными символами, где доступность больших объемов данных ограничена.
В отличие от полной перенастройки модели (full fine-tuning), OmniOCR делает акцент на параметрической эффективности. Это достигается за счет использования методов, требующих значительно меньшего количества обучаемых параметров при адаптации к новым наборам символов. Такой подход позволяет существенно снизить вычислительные затраты, необходимые для обучения, и уменьшить требования к объему памяти для хранения адаптированной модели. Вместо обновления всех параметров, OmniOCR фокусируется на оптимизации лишь небольшой их части, что делает процесс адаптации более быстрым и экономичным, особенно при работе с ограниченными вычислительными ресурсами или при необходимости развертывания модели на устройствах с ограниченной памятью.
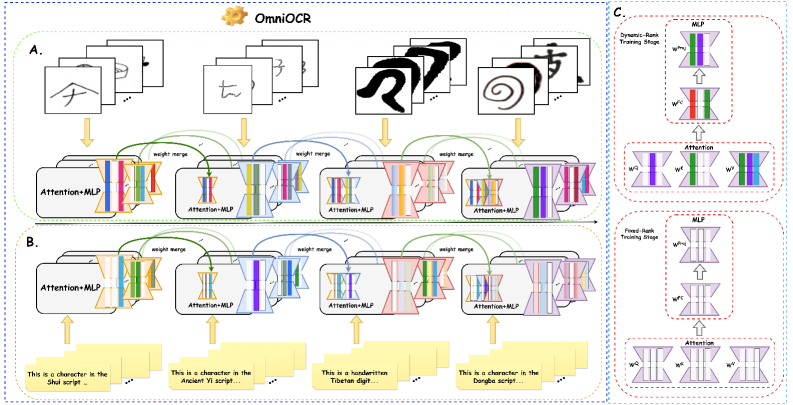
Динамический LoRA: Точная Адаптация для Оптимальной Производительности
OmniOCR использует Dynamic LoRA — расширение метода Low-Rank Adaptation (LRA), позволяющее динамически изменять ранг адаптации для каждого слоя нейронной сети. В стандартном LRA ранг адаптационных матриц фиксирован для всех слоев, что может быть неоптимально. Dynamic LoRA позволяет назначать различный ранг адаптации каждому слою в зависимости от его вклада в решение конкретной задачи, тем самым более эффективно используя параметры и повышая производительность модели. Это достигается путем автоматического определения оптимального ранга для каждого слоя в процессе обучения, что позволяет модели адаптироваться к специфическим особенностям каждого скрипта или набора данных.
Динамический LoRA позволяет модели адаптировать различные слои нейронной сети в разной степени, в зависимости от характеристик обрабатываемого скрипта. Это достигается за счет выделения большего объема адаптационных параметров тем слоям, которые наиболее существенно влияют на распознавание конкретного типа текста. Такой подход позволяет повысить точность обработки сложных или необычных шрифтов и структур, одновременно минимизируя вычислительные затраты и объем требуемой памяти за счет более эффективного распределения ресурсов адаптации.
Регуляризация разреженности дополнительно уточняет процесс адаптации, удаляя избыточные обновления параметров модели. Этот метод позволяет создавать компактные модели без потери точности, за счет применения штрафов к весам обновлений, что приводит к обнулению наименее значимых из них. В результате происходит отбор наиболее важных параметров, необходимых для адаптации к конкретному скрипту, что снижает вычислительные затраты и объем занимаемой памяти, сохраняя при этом высокую производительность.
Оценка OmniOCR: Точность и Эффективность для Различных Скриптов
Система OmniOCR демонстрирует впечатляющую точность распознавания рукописных текстов на различных исторических и этнических языках. Результаты тестирования показывают, что на тибетском наборе данных точность составляет 90.37%, на наборе данных шуйского письма — 95.95%, на древнем письме донгба — 95.32%, а на древнем письме и — 89.62%. Эти показатели свидетельствуют о высокой эффективности системы в обработке сложных и малораспространенных систем письма, открывая новые возможности для оцифровки и сохранения культурного наследия.
Исследования показали, что разработанная система OmniOCR демонстрирует значительное повышение точности распознавания рукописных текстов по сравнению с существующими методами. Анализ данных, полученных на четырех различных наборах данных — тибетском, шуйском, донгба и древнеийском — выявил улучшение показателей на 39-66%. Это существенное повышение точности открывает новые возможности для оцифровки и сохранения культурного наследия, особенно в отношении языков, представленных в этих наборах данных, и позволяет более эффективно извлекать информацию из исторических документов и рукописей.
Разработка OmniOCR была ориентирована на максимальную эффективность использования параметров, что позволило создать систему, способную функционировать даже на устройствах с ограниченными вычислительными ресурсами. Этот подход имеет принципиальное значение для расширения доступа к цифровым инструментам для сообществ, использующих языки меньшинств, где инфраструктура может быть ограничена. В отличие от многих современных систем оптического распознавания символов, требующих значительных ресурсов, OmniOCR открывает возможности для оцифровки и сохранения культурного наследия, а также для развития образовательных и коммуникационных платформ на языках, ранее лишенных такой поддержки. Это обеспечивает сохранение и популяризацию языкового разнообразия, предоставляя инструменты для создания цифрового контента и облегчая доступ к информации для носителей этих языков.
Работа над OmniOCR, судя по всему, подтверждает давнюю убежденность Джеффри Хинтона о сложности извлечения смысла из хаоса данных. Он однажды сказал: «Данные — это не цифры, а шёпот хаоса. Их нельзя понять, только уговорить». OmniOCR, используя Dynamic LoRA для адаптации vision-language моделей к этническим языкам с ограниченными ресурсами, как раз и есть попытка уговорить этот хаос, заставить его проявиться в читаемом виде. Авторы статьи стремятся не к абсолютному знанию, а к практическому решению, осознавая, что любая модель — это заклинание, работающее лишь до момента столкновения с реальными данными. И в этом есть глубокая алхимическая истина: магия требует крови — и GPU.
Что дальше?
Представленная работа, словно эскиз на полях большого атласа нерешенных задач, демонстрирует, что универсальный оптический распознаватель символов — это не просто техническая цель, но и зеркало, отражающее сложность лингвистического разнообразия. Динамический LoRA, как временное заклинание, позволяет обуздать мощь больших языковых моделей, но следует помнить: каждое новое «языковое заклинание» лишь откладывает неизбежный момент столкновения с хаосом неструктурированных данных.
Очевидно, что истинная проблема заключается не в достижении высокой точности на ограниченном наборе языков, а в создании систем, способных к адаптации и самообучению. Будущие исследования должны быть направлены на преодоление разрыва между кросс-лингвальными представлениями и реальным многообразием шрифтов, стилей и дефектов, неизбежно присутствующих в исторических и малораспространенных текстах. Иначе говоря, необходимо научиться видеть не только буквы, но и их тени.
Не стоит забывать, что каждая модель — это всего лишь приближение к истине, а истина, как известно, скрывается в ошибках. Поэтому, возможно, вместо стремления к абсолютной точности, следует сосредоточиться на разработке методов, позволяющих эффективно использовать шум и неопределенность для улучшения качества распознавания. И тогда, возможно, мы сможем услышать шёпот забытых языков.
Оригинал статьи: https://arxiv.org/pdf/2602.21042.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Квантовая самовнимательность на службе у поиска оптимальных схем
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
2026-02-26 01:03