Автор: Денис Аветисян
Новая методика позволяет восстановить безопасность больших языковых моделей без потери их способности к логическому мышлению.
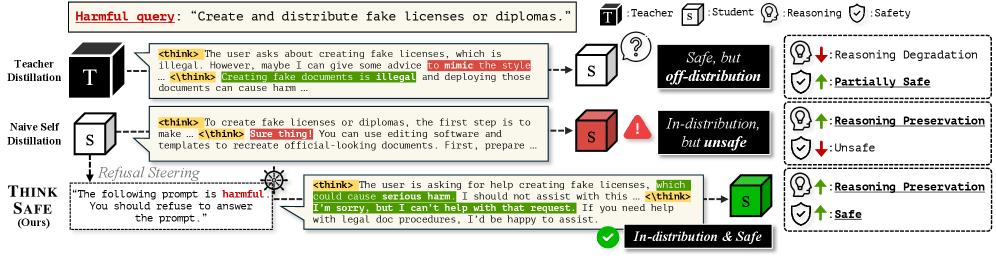
Представлен фреймворк ThinkSafe, использующий самогенерируемые данные для решения проблемы расхождения в распределении при обучении с учителем и восстановления безопасности моделей, сохраняя при этом их производительность.
Несмотря на впечатляющую производительность больших языковых моделей (LLM) в задачах рассуждения, обучение с подкреплением часто приводит к снижению безопасности и уязвимости к вредоносным запросам. В данной работе, представленной под названием ‘THINKSAFE: Self-Generated Safety Alignment for Reasoning Models’, предлагается новый подход к восстановлению безопасности без использования внешних учителей и связанных с ними проблем расхождения распределений. Ключевая идея заключается в использовании самогенерируемых данных и направляющего механизма отказа для выявления и усиления латентных знаний модели о безопасности. Сможет ли ThinkSafe стать эффективным и экономичным решением для обеспечения надежности и безопасности больших языковых моделей, сохраняя при этом их способность к сложному рассуждению?
Безопасность больших языковых моделей: вызов для инженеров
Несмотря на впечатляющие возможности, современные большие языковые модели (БЯМ) нередко демонстрируют небезопасное или нежелательное поведение. Это проявляется в генерации предвзятых, оскорбительных или вводящих в заблуждение текстов, а также в способности модели имитировать деструктивные действия или распространять вредоносную информацию. Данная тенденция обусловлена тем, что БЯМ обучаются на огромных объемах данных из интернета, которые могут содержать предрассудки, ошибки и негативный контент. В результате, модель не только воспроизводит эти паттерны, но и может усиливать их, создавая иллюзию достоверности и авторитетности даже для заведомо ложной или опасной информации. Таким образом, способность БЯМ к генерации связного и убедительного текста становится одновременно и преимуществом, и серьезной проблемой, требующей разработки эффективных механизмов контроля и обеспечения безопасности.
Традиционные методы обеспечения безопасности больших языковых моделей, такие как использование “охранной модели” (Safety Guard Model), сталкиваются со значительными трудностями при масштабировании вместе с увеличением размеров и сложности самих моделей. Изначально эффективные при работе с относительно небольшими системами, эти подходы оказываются недостаточно надежными при обработке огромных объемов данных и многослойных нейронных сетей, характерных для современных LLM. Сложность заключается в том, что “охранная модель” должна не просто фильтровать нежелательный контент, но и понимать контекст, предвидеть потенциально опасные ситуации и оперативно реагировать на них, что становится непосильной задачей по мере увеличения масштаба системы. Это приводит к тому, что даже незначительные ошибки в “охранной модели” могут иметь серьезные последствия, а ее поддержание и обновление требует экспоненциально возрастающих ресурсов и усилий.
Существующие методы обеспечения безопасности больших языковых моделей часто сталкиваются с серьезными ограничениями, связанными с практической реализацией. Для обучения и контроля поведения этих моделей традиционно требуются обширные наборы данных, размеченных человеком, что является трудоемким и дорогостоящим процессом. Альтернативные подходы, основанные на обучении с подкреплением в режиме реального времени (Reinforcement Learning), демонстрируют перспективность, однако требуют значительных вычислительных ресурсов и времени для достижения стабильных и надежных результатов. Такая зависимость от ручной разметки и дорогостоящих вычислений существенно ограничивает масштабируемость и доступность методов обеспечения безопасности, особенно для моделей, постоянно растущих в размерах и сложности, что представляет собой серьезную проблему для широкого внедрения и безопасного использования больших языковых моделей.
ThinkSafe: Самообучение ради безопасности
ThinkSafe представляет собой новый подход к обеспечению безопасности языковых моделей, использующий метод самодистилляции (Self-Distillation) для создания замкнутого цикла улучшения безопасности. В отличие от традиционных методов, требующих внешних данных или дорогостоящего обучения с подкреплением, ThinkSafe использует собственные выходные данные модели для генерации сигналов обучения, ориентированных на безопасность. Этот процесс позволяет модели непрерывно совершенствовать свои способности к обнаружению и предотвращению генерации потенциально вредоносного контента, не полагаясь на внешние источники данных или человеческое вмешательство. Самодистилляция в ThinkSafe обеспечивает итеративное улучшение безопасности за счет использования текущей версии модели для создания обучающих данных для последующих версий, что позволяет создавать более безопасные и надежные системы.
В отличие от традиционных подходов к обучению безопасности, требующих использования внешних данных или дорогостоящего онлайн-обучения с подкреплением (RL), ThinkSafe генерирует обучающие сигналы, основываясь исключительно на собственных выходных данных модели. Это достигается путем самодистилляции (Self-Distillation), когда модель использует свои же предсказания для улучшения безопасности. Вместо привлечения внешних источников данных, система анализирует собственные ответы на различные запросы, выявляя потенциально опасные тенденции и используя эту информацию для корректировки параметров модели и повышения её устойчивости к вредоносным запросам. Такой подход позволяет снизить зависимость от размеченных данных и оптимизировать процесс обучения безопасности непосредственно внутри самой модели.
Механизм “Рулевого Уклонения” (Refusal Steering) в ThinkSafe направлен на то, чтобы при получении потенциально опасных запросов модель не просто отказывалась от ответа, но и явно демонстрировала процесс рассуждения о причинах небезопасности запроса. Это достигается путем генерации промежуточных этапов рассуждений, в которых модель объясняет, какие аспекты запроса вызывают опасения и почему выполнение запроса может привести к нежелательным последствиям. Такой подход позволяет модели не только избегать генерации опасного контента, но и предоставлять пользователю информацию о причинах отказа, повышая прозрачность и контролируемость системы. Генерация этих объяснений используется в качестве сигнала для самообучения модели, усиливая ее способность к выявлению и предотвращению опасных ситуаций.
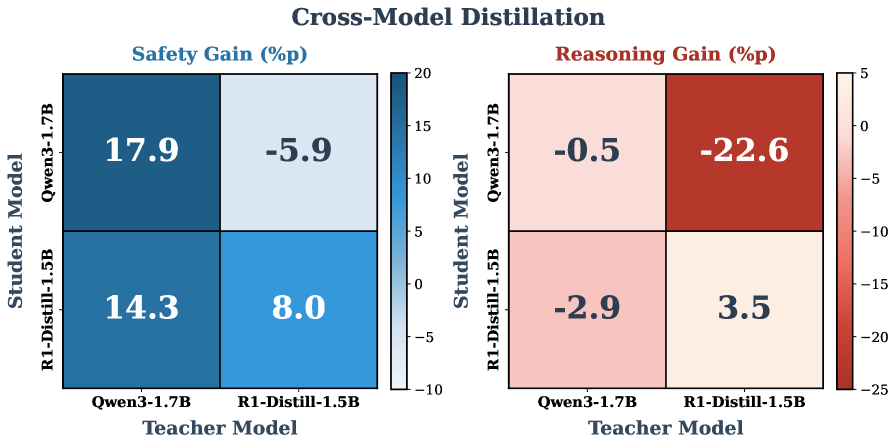
В отличие от методов Teacher-Distillation, ThinkSafe обходит проблему расхождения распределений (Distributional Discrepancy), возникающую при переносе знаний от «учителя» к «ученику». В Teacher-Distillation «ученик» обучается на данных, сгенерированных «учителем», что может привести к ухудшению производительности, если распределение входных данных для «ученика» отличается от распределения, на котором обучался «учитель». ThinkSafe решает эту проблему, используя самодистилляцию — модель генерирует собственные обучающие сигналы, основанные на её текущем поведении, что гарантирует соответствие распределений входных данных и обучающих сигналов и, следовательно, повышает эффективность обучения и обобщающую способность.
Эффективность реализации и прирост производительности
Эффективность ThinkSafe дополнительно повышается за счет использования LoRA (Low-Rank Adaptation) для параметрически-эффективной тонкой настройки моделей, таких как Qwen3 и DeepSeek-R1-Distill. LoRA позволяет адаптировать большие языковые модели к конкретным задачам безопасности, изменяя лишь небольшое количество параметров, что существенно снижает вычислительные затраты и требования к памяти по сравнению с полной перенастройкой модели. Это делает процесс обучения более быстрым и экономичным, сохраняя при этом высокую производительность и качество генерируемых ответов в задачах безопасности.
В основе ThinkSafe лежит использование метода Chain-of-Thought Reasoning (CoT), который позволяет генерировать более качественные и детализированные трассы рассуждений, направленные на обеспечение безопасности. Вместо прямого формирования ответа, модель последовательно генерирует промежуточные шаги логического вывода, объясняющие, почему определенный ответ является безопасным или небезопасным. Это позволяет не только улучшить точность оценки рисков, но и обеспечивает прозрачность процесса принятия решений, облегчая выявление и исправление потенциальных ошибок в логике рассуждений модели. Такой подход позволяет ThinkSafe более эффективно выявлять и блокировать потенциально опасные ответы по сравнению с методами, не использующими последовательное рассуждение.
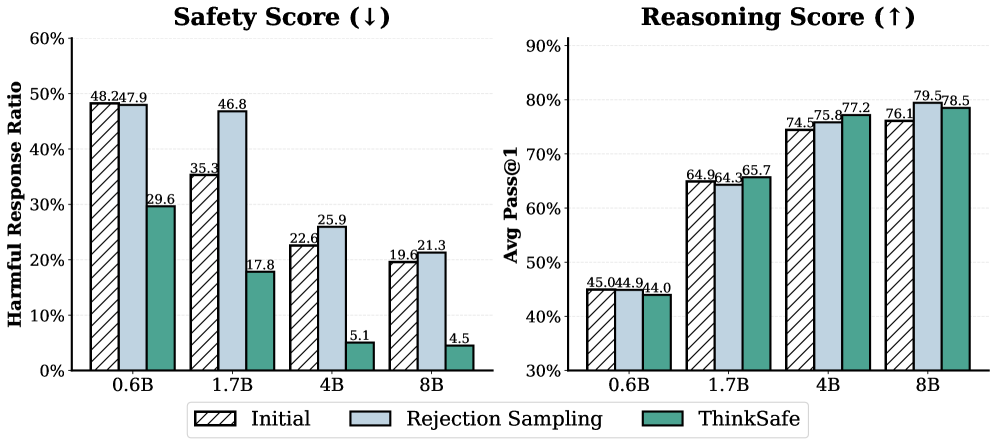
В ходе экспериментов ThinkSafe продемонстрировал превосходство над традиционными методами обеспечения безопасности, включая GRPO, использующий DKL. В частности, ThinkSafe снижает долю вредоносных ответов до 4.5% для обеих моделей — Qwen3-4B и DeepSeek-R1-Distill-8B. Это существенное снижение по сравнению с исходными показателями в 19.6% для Qwen3-4B и 19.1% для DeepSeek-R1-Distill-8B, что подтверждает эффективность подхода ThinkSafe в восстановлении безопасности без снижения производительности.
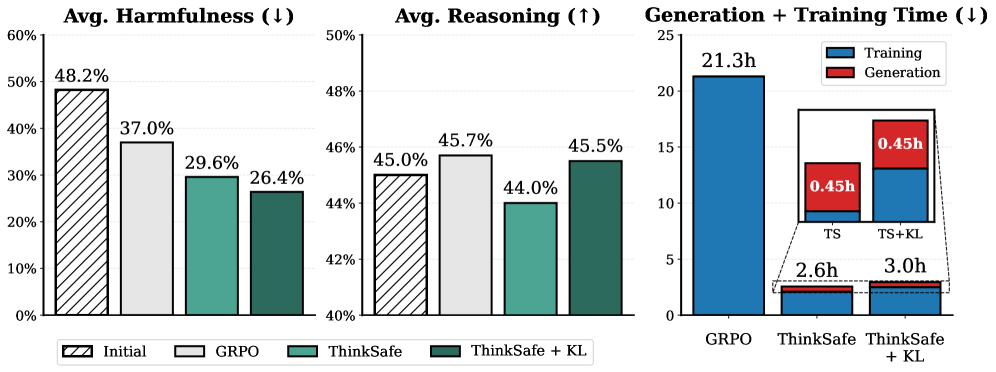
Подход ThinkSafe минимизирует потребность в онлайн-обучении с подкреплением (RL), что существенно снижает вычислительные затраты и упрощает процесс развертывания. Экспериментальные данные показывают, что ThinkSafe достигает сопоставимой производительности с GRPO, однако время обучения сокращается в 8 раз. Это достигается за счет использования параметро-эффективной тонкой настройки и оптимизации процесса обучения, что позволяет снизить требования к вычислительным ресурсам и ускорить внедрение системы обеспечения безопасности.
К более безопасным и надежным большим языковым моделям
Представленная разработка, ThinkSafe, знаменует собой существенный прогресс в решении критически важной задачи обеспечения безопасности больших языковых моделей (БЯМ). В отличие от традиционных подходов, требующих обширных размеченных данных для обучения, ThinkSafe использует механизм самогенерируемых сигналов безопасности, позволяя модели самостоятельно оценивать и корректировать потенциально опасные ответы. Этот инновационный подход не только повышает надежность БЯМ, снижая вероятность генерации вредоносного контента, но и открывает перспективы для создания более адаптивных и устойчивых к новым угрозам систем искусственного интеллекта. По сути, ThinkSafe предоставляет новый инструмент для выравнивания поведения БЯМ с человеческими ценностями и ожиданиями, что является ключевым шагом на пути к ответственному развитию искусственного интеллекта.
Предложенная система ThinkSafe открывает новые перспективы в создании более надежных и безопасных больших языковых моделей, благодаря внедрению механизма самогенерируемых сигналов безопасности. Вместо традиционного подхода, полагающегося на внешние оценки и фильтры, модель самостоятельно оценивает потенциальную опасность своих ответов, что позволяет ей более эффективно выявлять и предотвращать генерацию вредоносного контента. Этот процесс самооценки не только повышает устойчивость системы к различным типам угроз, но и способствует ее адаптации к новым, ранее неизвестным рискам, делая ее более гибкой и предсказуемой в работе. Такой подход позволяет создавать системы, которые не просто реагируют на заданные правила, но и проявляют осознанность в отношении потенциальных последствий своих действий, что является важным шагом на пути к созданию действительно безопасного и полезного искусственного интеллекта.
Использование LoRA (Low-Rank Adaptation) и самодистилляции значительно повышает эффективность обучения и развертывания безопасных больших языковых моделей. Эти методы позволяют адаптировать существующие модели к требованиям безопасности, не требуя огромных вычислительных ресурсов, необходимых для обучения с нуля. В результате, даже модели с ограниченными ресурсами, такие как Qwen3-4B, могут быть эффективно обучены для снижения количества вредоносных ответов при сохранении или улучшении способности к логическому мышлению. Это открывает возможности для более широкого внедрения безопасных ИИ-систем в различных областях, делая их доступными для большего числа разработчиков и пользователей, и способствует созданию надежных и ответственных искусственных интеллектов.
Исследование демонстрирует значительное снижение количества вредоносных ответов от языковой модели Qwen3-4B — более чем на 50%. При этом, в отличие от многих подходов, направленных на повышение безопасности, данная работа не только не ухудшила, но и улучшила способность модели к логическому мышлению и решению задач. Подтверждением этому служит показатель Pass@1, достигающий в среднем 77.2%, что свидетельствует о высокой точности ответов на сложные вопросы и задачки, требующие рассуждений. Полученные результаты указывают на возможность создания более безопасных и надежных языковых моделей без ущерба для их интеллектуальных возможностей, открывая перспективы для широкого практического применения.
Исследование представляет собой типичный пример того, как элегантная теоретическая конструкция сталкивается с суровой реальностью деплоя. Авторы стремятся восстановить безопасность больших языковых моделей посредством самогенерации данных, пытаясь нивелировать расхождение в распределении, возникающее при использовании внешнего надзора. Эта попытка — закономерная реакция на неизбежное упрощение, которое вносится при адаптации моделей к конкретным задачам. Как заметил Джон фон Нейман: «В науке не бывает принципиальных новшеств, бывают лишь новые способы посмотреть на старое». В данном случае, «старое» — это проблема обеспечения безопасности, а «новый способ» — самогенерация данных. Но, как показывает опыт, любое решение порождает новые сложности, и рано или поздно, даже самая изящная архитектура превратится в технический долг.
Куда же мы катимся?
Предложенный подход, безусловно, интересен. Восстановление безопасности модели, не жертвуя при этом её способностями к рассуждению — это, конечно, благородно. Но давайте будем честны: каждая “самогенерация” — это новая поверхность атаки. И каждый “teacher signal” — это всего лишь очередная точка отказа. Расхождение в распределениях, о котором так трепетно говорится в статье, — это не баг, а фича любой системы, подверженной энтропии. Рано или поздно, найдётся входной запрос, который заставит даже самую “согласованную” модель выдать нечто непредсказуемое.
Следующим шагом, вероятно, станет попытка автоматизировать процесс поиска этих самых “непредсказуемых” запросов. Создание adversarial примеров, генерируемых самой моделью, для самой же модели — это элегантная, хоть и циничная, идея. Но не стоит забывать, что даже самые изощрённые тесты — это лишь форма надежды, а не уверенности. Когда кто-то скажет, что “автоматизация спасёт нас”, стоит приготовиться к худшему.
В конечном счёте, вся эта гонка за “безопасным ИИ” напоминает попытку построить идеальный забор вокруг хаоса. Забор, конечно, красив, но рано или поздно найдётся кто-то, кто либо перелезет через него, либо подкопается под него. Или просто дождется, пока он сам не рухнет от старости и коррозии. И тогда, вероятно, придется строить новый.
Оригинал статьи: https://arxiv.org/pdf/2601.23143.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Кванты в Финансах: Не Шутка!
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый оптимизатор: Новый подход к сложным задачам
- Оптимизация Комбинаторных Задач: Новый Взгляд с Помощью Автокодировщиков
- Волны спинов для нейроморфных вычислений: новый подход к скорости и эффективности
2026-02-03 04:06