Автор: Денис Аветисян
Исследование выявляет пробелы в способности современных моделей понимать и комбинировать информацию из разных источников, таких как текст и изображения.

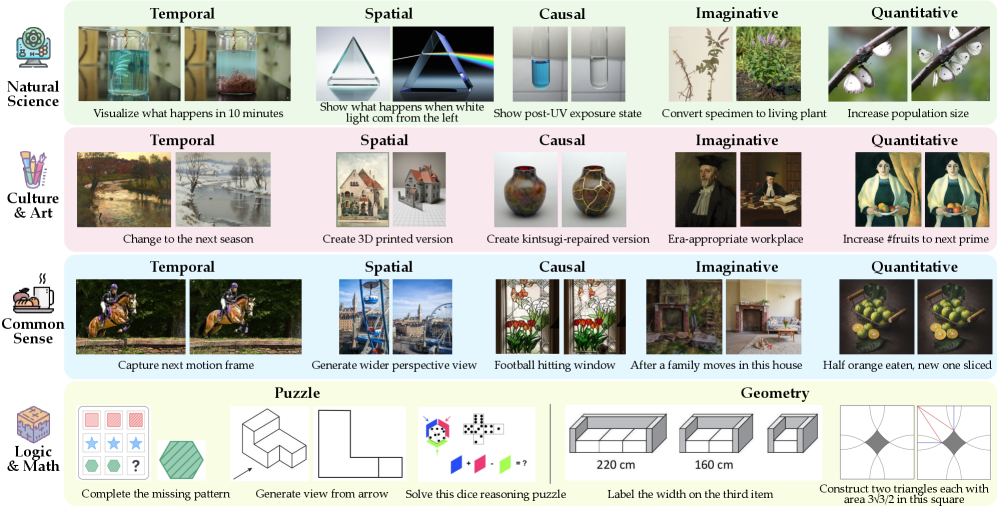
Представлен ROVER, эталонный набор данных для оценки взаимного кросс-модального рассуждения в унифицированных мультимодальных моделях.
Несмотря на успехи унифицированных мультимодальных моделей, существующие оценки часто игнорируют способность к взаимному кросс-модальному рассуждению. В данной работе представлена новая методика оценки, ‘ROVER: Benchmarking Reciprocal Cross-Modal Reasoning for Omnimodal Generation’, предназначенная для измерения способности моделей использовать одну модальность для улучшения или проверки результатов в другой. Эксперименты с семнадцатью моделями показали, что именно кросс-модальное рассуждение определяет качество генерации изображений, а также выявили разрыв между способностью к интерпретации физических и символических концепций. Сможем ли мы создать действительно универсальные мультимодальные модели, способные к комплексному и взаимному рассуждению?
За гранью поверхностного восприятия: истинное мультимодальное рассуждение
Современные мультимодальные модели часто демонстрируют поверхностную интеграцию данных, не обладая подлинными возможностями межмодального рассуждения. Вместо глубокого понимания, они склонны к простому сопоставлению признаков, ограничивая их способность решать сложные задачи. Подлинное рассуждение требует не только обработки информации из разных модальностей, но и верификации и уточнения выходных данных на основе их согласованности. Это предполагает выявление противоречий, разрешение неоднозначностей и построение логически обоснованных выводов.
Подобно тому, как в физической системе энергия переходит между различными формами, обеспечивая её стабильность, истинное мультимодальное понимание требует постоянной перекрестной проверки и уточнения информации.
Оценка реципрокного рассуждения: строгие критерии и автоматизация
Бенчмарк предоставляет строгую основу для оценки реципрокного кросс-модального рассуждения. Он использует как аннотации, выполненные людьми, так и подход ‘VLM-as-Judge’, задействующий мощную визуально-языковую модель (‘GPT-4.1’) для автоматизации оценки. Показана высокая корреляция между автоматической и экспертной оценками.

Оценка фокусируется на анализе логической структуры (‘Оценка процесса рассуждения’) и подтверждении визуальной согласованности генерируемых результатов (‘Визуальная оценка рассуждения’), измеряемой с помощью ‘Метрик качества изображения’. Модели с переплетенной генерацией демонстрируют улучшение производительности на 38.1% в ‘Визуальной оценке рассуждения’.
Задачи, требующие взаимного рассуждения: визуальное и вербальное усиление
Подход ‘Visually-Augmented Reasoning’ требует от моделей генерации текста на основе визуальных данных, что обуславливает необходимость надежной ‘Мировой модели’. Эксперименты показали, что производительность в задачах, требующих визуального рассуждения, значительно улучшается при использовании визуальной аргументации. Аналогично, ‘Verbally-Augmented Reasoning’ ставит перед моделями задачу создания изображений на основе лингвистических инструкций, что требует тонкого понимания обеих модальностей. Успех в данной области напрямую зависит от способности модели корректно переводить языковые концепции в визуальные представления.

Фундаментальными компонентами являются ‘Задачи визуального восприятия’, тестирующие способность модели анализировать визуальную информацию, и ‘Логическое и математическое рассуждение’. Наблюдалась сильная корреляция между способностью к временному и пространственному рассуждению.
Архитектурные подходы к унифицированной мультимодальности: от диффузии к авторегрессии
В настоящее время унифицированные мультимодальные модели находятся на передовой исследований в области генерации изображений, используя такие методы, как диффузионные модели и сопоставление потоков. Особенностью подхода является стремление к генерации контента, логически связанного с входными данными. Альтернативой являются визуальные авторегрессионные модели, предсказывающие многомасштабные целевые признаки для обеспечения согласованности и когерентности. Эти модели ориентированы не только на визуальное качество, но и на демонстрацию способности к рассуждениям.

На текущий момент закрытые модели превосходят открытые в задачах, оценивающих процесс рассуждений и соответствие требованиям. Однако, постоянное развитие открытых моделей позволяет надеяться на сокращение этого разрыва. Визуальные данные, подобно отражению сложной системы, требуют внимательного анализа и интерпретации.
Исследование, представленное в данной работе, акцентирует внимание на важности перекрестных модальных рассуждений в унифицированных мультимодальных моделях. Это созвучно высказыванию Джеффри Хинтона: «Понимание данных – это не просто распознавание паттернов, но и умение строить логические связи между различными источниками информации». Подобно тому, как ROVER оценивает способность моделей к взаимным рассуждениям между текстом и изображениями, Хинтон подчеркивает необходимость интегрированного подхода к пониманию информации. Недостатки, выявленные в текущих моделях при решении задач, требующих сложного перекрестного анализа, подтверждают, что способность к построению таких логических связей остается ключевой проблемой в области искусственного интеллекта и требует дальнейших исследований.
Что дальше?
Представленный анализ выявляет, что текущие унифицированные мультимодальные модели, несмотря на впечатляющий прогресс в генерации изображений и текста, демонстрируют заметные ограничения в области взаимного перекрестного рассуждения. Неспособность адекватно интегрировать и логически связывать информацию из различных модальностей – это не просто техническая деталь, а фундаментальная проблема, обнажающая поверхностность «понимания» со стороны этих систем. Каждое отклонение в результатах, каждая ошибка в логической цепочке – это возможность выявить скрытые зависимости, которые ускользают от внимания при поверхностном анализе.
Будущие исследования должны быть сосредоточены не только на увеличении масштаба моделей и объёма данных, но и на разработке принципиально новых архитектур и алгоритмов, способных к более глубокому и осмысленному перекрестному рассуждению. Необходимо уделить внимание созданию более строгих и всесторонних метрик оценки, способных выявлять не только поверхностные соответствия, но и истинную логическую связность между модальностями.
Ирония заключается в том, что стремление к созданию «интеллектуальных» систем часто приводит к повторению человеческих ошибок – игнорированию противоречий, упрощению сложных взаимосвязей и переоценке собственной способности к рассуждению. Понимание системы – это исследование её закономерностей, и в этом исследовании, возможно, самое ценное – это обнаружение тех мест, где система дает сбой.
Оригинал статьи: https://arxiv.org/pdf/2511.01163.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2025-11-04 22:47