Автор: Денис Аветисян
Новое исследование показывает, что способность к сложным логическим выводам зависит не столько от размера модели, сколько от эффективности использования её ресурсов.
Масштабирование языковых моделей среднего размера показывает, что ключевым фактором является координация между агентами и активное использование параметров, а не просто увеличение их количества.
Несмотря на успехи больших языковых моделей, механизмы, определяющие их способность к сложному многошаговому логическому выводу, остаются недостаточно изученными. В работе ‘Scaling Trends for Multi-Hop Contextual Reasoning in Mid-Scale Language Models’ представлено контролируемое исследование, демонстрирующее, что эффективность многоагентных систем зависит не столько от общего размера модели, сколько от способности эффективно использовать доступные параметры и базового уровня рассуждений. Полученные результаты показывают, что ключевым фактором производительности является количество активных параметров, а не общее число, и что координация агентов наиболее эффективна для моделей с достаточными возможностями. Какие архитектурные и тренировочные стратегии позволят в дальнейшем максимально раскрыть потенциал языковых моделей в решении задач, требующих глубокого логического анализа?
Пределы масштабирования: За пределами сопоставления образов
Несмотря на впечатляющие способности больших языковых моделей к распознаванию закономерностей, задача истинного многоступенчатого контекстуального рассуждения остается сложной. Эти модели преуспевают в идентификации статистических корреляций в огромных объемах данных, однако сталкиваются с трудностями при обработке информации, требующей понимания сложных взаимосвязей и логических выводов, основанных на контексте. В отличие от простого сопоставления шаблонов, многоступенчатое рассуждение требует от модели не только обнаружения релевантной информации, но и ее последовательной интеграции и анализа для достижения конкретной цели, что выходит за рамки возможностей, обеспечиваемых одним лишь увеличением масштаба модели и объемом обучающих данных.
Традиционные методы искусственного интеллекта, такие как системы, основанные на жестких правилах, демонстрируют безупречную точность при решении структурированных задач, где каждое действие четко определено. Однако, когда дело доходит до контекстного рассуждения — способности понимать и применять информацию из сложного, неоднозначного окружения — их эффективность резко падает. Исследования показывают, что на подобных задачах, требующих не просто следования инструкциям, а понимания смысла и взаимосвязей, подобные системы достигают успеха лишь в 6,7% случаев. Это подчеркивает фундаментальное различие между способностью машины выполнять заранее запрограммированные действия и ее способностью к настоящему интеллектуальному анализу и адаптации к новым, непредсказуемым ситуациям.
Исследования показывают, что простое увеличение размера языковых моделей не приводит к пропорциональному улучшению их способности к рассуждениям. Наблюдается эффект убывающей отдачи: с ростом числа параметров прирост в качестве логических выводов становится всё менее значительным. Более того, увеличение масштаба часто приводит к неэффективному использованию ресурсов, поскольку большая часть параметров не участвует в процессе рассуждения, а лишь дублирует уже существующие знания. Это указывает на необходимость разработки новых архитектур и методов обучения, которые позволят более эффективно использовать вычислительные ресурсы и добиться существенного прогресса в области многоступенчатых логических выводов, а не полагаться исключительно на наращивание масштаба.

Оценка рассуждений: Синтетическая среда
Для строгой оценки многошагового рассуждения мы разработали Синтетическую Оценочную Среду, генерирующую структурированные задачи на основе заданных правил. Данная среда позволяет создавать контролируемые эксперименты, определяя способность моделей к сложному выводу, а не к простому сопоставлению шаблонов. Генерация задач осуществляется программно, что обеспечивает гибкость в настройке параметров, таких как глубина логической цепочки, сложность фактов и степень неоднозначности, позволяя точно контролировать аспекты, необходимые для оценки. В рамках данной среды создаются задачи, требующие последовательного применения логических правил для достижения решения, что позволяет оценить способность модели к выполнению многошагового вывода.
Данная платформа обеспечивает контролируемые эксперименты, позволяющие разграничить подлинное логическое мышление и поверхностное сопоставление шаблонов посредством двух типов задач: структурированных и контекстуальных. Структурированные задачи оперируют четко определенными отношениями между сущностями, требуя от модели применения логических правил для вывода новых фактов. Контекстуальные задачи, напротив, включают в себя неявные связи и требуют от модели извлечения релевантной информации из предоставленного контекста для выполнения логических операций. Комбинация этих двух типов задач позволяет более точно оценить способность модели к многоступенчатому логическому выводу, исключая возможность успешного решения задач за счет простой идентификации статистических закономерностей в данных.
Использование синтетически сгенерированных задач позволяет избежать проблем, связанных с конфиденциальностью данных, которые часто возникают при работе с существующими наборами данных. Отказ от использования готовых датасетов гарантирует, что оценка способности к сложному логическому выводу не зависит от случайно содержащейся в них персональной информации или предвзятости. Это позволяет сосредоточиться исключительно на оценке способности модели к построению логических цепочек и решению многоступенчатых задач, а не на её способности запоминать и воспроизводить информацию из обучающего набора.

Многоагентные системы: Путь к глубине рассуждений
Многоагентные системы представляются перспективной архитектурой для улучшения многошагового контекстуального рассуждения. В отличие от традиционных монолитных моделей, данный подход предполагает декомпозицию задачи на несколько специализированных агентов, каждый из которых отвечает за определенный аспект процесса рассуждения. Такая модульная структура позволяет эффективно обрабатывать сложные запросы, требующие последовательного анализа информации и вывода новых знаний на основе контекста. Организация взаимодействия между агентами обеспечивает возможность более глубокого и точного понимания входных данных, что, в свою очередь, ведет к повышению качества генерируемых ответов и решений.
Система состоит из трех специализированных агентов, работающих совместно: Аналитика, Стратега и Генератора. Агент-Аналитик отвечает за извлечение релевантной информации из предоставленного контекста. Агент-Стратег, используя полученные данные, формулирует гипотезы и определяет оптимальный путь решения задачи. Наконец, агент-Генератор, опираясь на гипотезы и извлеченную информацию, генерирует итоговое решение или ответ. Взаимодействие между агентами происходит последовательно, обеспечивая глубокий анализ и многоступенчатое рассуждение для достижения более точных и обоснованных результатов.
Внедрение архитектуры Mixture-of-Experts (MoE) позволило значительно увеличить емкость модели и эффективно использовать активные параметры в системе. Эксперименты с LLaMA-3 8B показали прирост производительности до 46.7 процентных пунктов (p<0.001). MoE позволяет модели динамически активировать только часть своих параметров для каждого конкретного ввода, что снижает вычислительные затраты и повышает эффективность обучения и инференса, сохраняя при этом высокую выразительность модели.
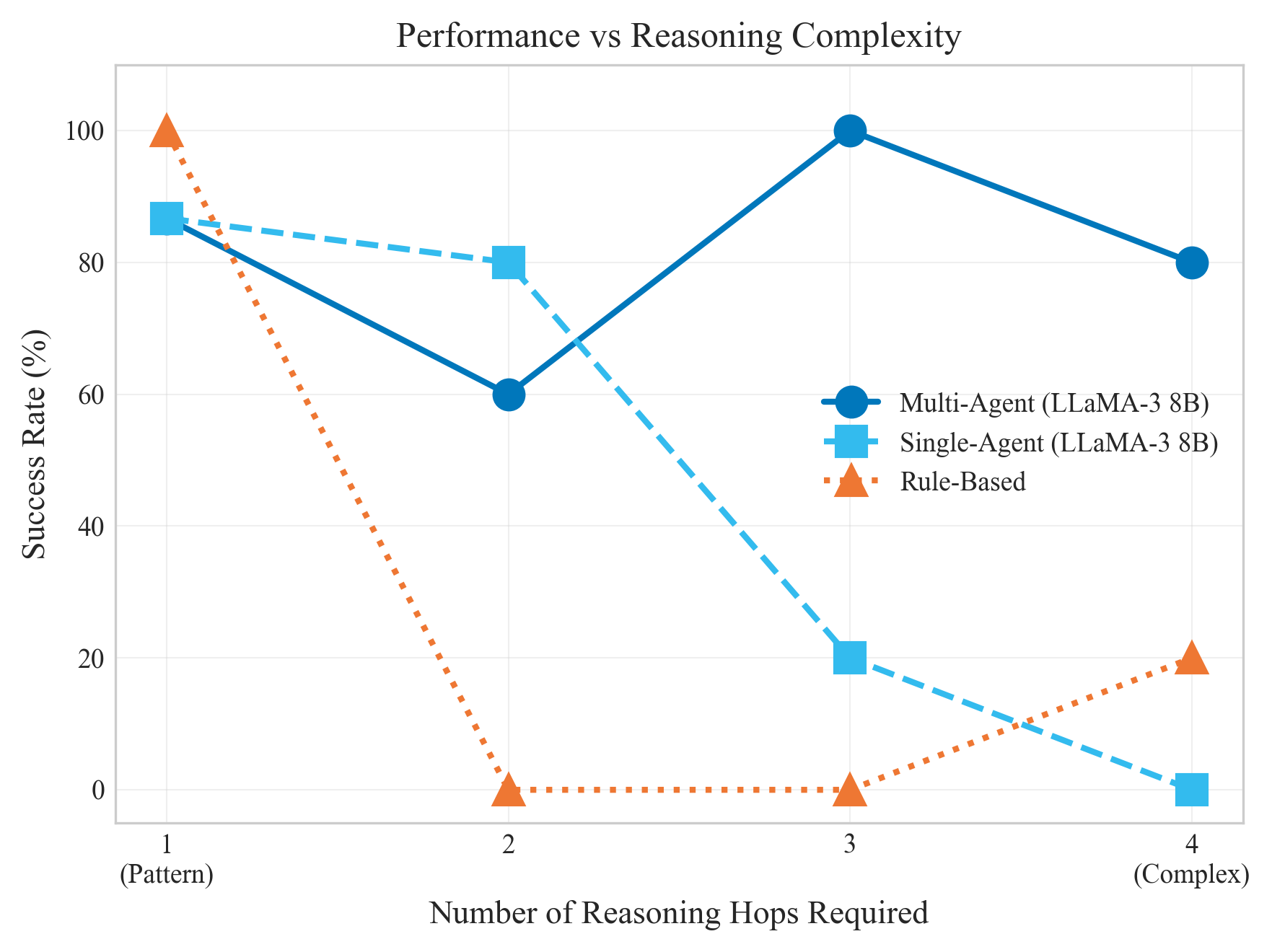
За пределами степенных законов: Сигмоидальное масштабирование рассуждений
Полученные результаты ставят под сомнение общепринятую зависимость, описываемую степенным законом, в масштабировании языковых моделей. Традиционно предполагалось, что увеличение размера модели линейно связано с улучшением её производительности, однако данное исследование демонстрирует, что эта зависимость не является универсальной. Наблюдаемые данные свидетельствуют об отклонении от степенной зависимости, указывая на то, что простым увеличением числа параметров модели невозможно добиться неограниченного прогресса. Этот вывод имеет важное значение для дальнейших исследований в области искусственного интеллекта, поскольку подчеркивает необходимость поиска альтернативных подходов к масштабированию моделей, выходящих за рамки простой оптимизации размера.
Исследование показало, что производительность многоагентной системы в задачах многошагового рассуждения описывается не степенным законом, как это часто наблюдается при масштабировании языковых моделей, а сигмоидальной функцией. Данная сигмоидальная модель более точно отражает зависимость между размером модели и её способностью к рассуждению. В отличие от степенного закона, предполагающего постоянный прирост производительности при увеличении параметров, сигмоидальная функция указывает на наличие насыщения. Это означает, что дальнейшее увеличение числа параметров модели после определенного порога не приводит к соразмерному улучшению результатов, а дальнейший прогресс достигается за счет усовершенствования архитектуры и алгоритмов рассуждения. σ(x) = 1 / (1 + e^{-x}) — такая функция демонстрирует, как производительность асимптотически приближается к максимальному значению.
Исследование демонстрирует, что существует пороговый эффект в масштабировании языковых моделей для выполнения сложных задач многошагового рассуждения. Приблизительно после достижения 24,2 миллиардов параметров, простое увеличение размера модели перестает приносить существенную прибавку в производительности. Наблюдается, что дальнейший прогресс в этой области достигается не за счет наращивания вычислительных ресурсов, а благодаря внедрению инновационных архитектурных решений. Это указывает на то, что эффективность системы больше не определяется исключительно масштабом, а требует качественно новых подходов к организации и обработке информации, что открывает перспективы для разработки более компактных и эффективных моделей.

Появление рассуждений: К общему интеллекту
Наблюдаемая сигмоидальная зависимость масштабирования и улучшение способностей к рассуждению позволяют предположить, что в многоагентной системе спонтанно возникают новые функциональные возможности. По мере увеличения вычислительных ресурсов и сложности взаимодействий между агентами, система демонстрирует не просто линейный рост производительности, а качественный скачок в решении задач, требующих абстрактного мышления и логических выводов. Этот феномен указывает на то, что система не просто «запоминает» ответы, а формирует внутреннее представление о проблеме и активно использует его для генерации новых, ранее недоступных решений. Такое поведение является ключевым признаком развития интеллекта и открывает перспективы для создания систем, способных к адаптации и обучению в сложных, динамически меняющихся условиях.
В дальнейшем планируется использование модели LLaMA-3, что позволит значительно расширить возможности системы в области рассуждений. Особое внимание будет уделено исследованию методики Chain-of-Thought Prompting — подхода, стимулирующего модель к последовательному изложению цепочки рассуждений, что потенциально приведет к более надежным и обоснованным ответам. Эксперименты с этой техникой направлены на повышение способности системы к решению сложных задач, требующих многоступенчатого анализа и логических выводов, и позволят оценить, насколько эффективно она может воспроизводить человеческий процесс мышления.
Предлагаемый подход демонстрирует перспективное направление в создании интеллектуальных систем, отличающихся повышенной устойчивостью и обобщающей способностью для решения сложных задач. Вместо традиционного программирования конкретных решений, система, основанная на взаимодействии агентов, способна к самостоятельному освоению новых навыков и адаптации к различным условиям. Это позволяет ей не только эффективно решать текущие задачи, но и успешно применять полученный опыт для решения принципиально новых проблем, приближая нас к созданию действительно общего искусственного интеллекта, способного к гибкому и креативному мышлению. Перспективы данного подхода заключаются в возможности создания систем, которые будут не просто выполнять заданные инструкции, но и самостоятельно анализировать ситуации, формулировать гипотезы и находить оптимальные решения.
Исследование масштабирования языковых моделей выявляет любопытную закономерность: важна не столько абсолютная величина модели, сколько эффективность использования её ресурсов. Подобно тому, как опытный садовник взращивает крепкое растение, а не просто увеличивает размер семени, так и в задачах многоступенчатого логического вывода ключевым становится умение модели задействовать необходимые параметры. Как однажды заметил Эдсгер Дейкстра: «Программирование — это не столько искусство организации, сколько искусство предвидения». Это высказывание особенно актуально в контексте данной работы, где подчеркивается, что архитектурный выбор определяет будущее поведение системы и, следовательно, её способность к решению сложных задач. Координация нескольких агентов, описанная в статье, лишь усиливает эту идею, демонстрируя, что слаженная работа небольших, но эффективных компонентов превосходит хаотичное использование огромных ресурсов.
Что ждет впереди?
Исследование показывает, что масштаб не является абсолютным мерилом разума, а лишь инструментом. Гораздо важнее — как эффективно используются доступные ресурсы, как организована внутренняя координация. Модели растут, но проблема не в наращивании параметров, а в их осмысленном применении. Архитектура — это не структура, а компромисс, застывший во времени. Каждый выбор — это пророчество о будущей ошибке, о точке, где система неизбежно споткнется.
Синтетические оценки, как и любая упрощенная модель реальности, неизбежно далеки от истины. Они дают лишь приблизительное представление о возможностях, но не раскрывают всей сложности многоступенчатого рассуждения в условиях неполноты и неоднозначности данных. Технологии сменяются, зависимости остаются — и в будущем, вероятно, придется столкнуться с проблемой масштабирования не моделей, а систем координации агентов, с их неизбежными накладными расходами и ограничениями.
В конечном счете, поиск оптимального решения — это вечный танец между наращиванием вычислительных ресурсов и разработкой более эффективных алгоритмов. Системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить. И в этом процессе всегда будет место для неожиданных мутаций и непредсказуемых сбоев.
Оригинал статьи: https://arxiv.org/pdf/2601.04254.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовый скачок: от лаборатории к рынку
2026-01-11 17:28