Автор: Денис Аветисян
Исследователи представили APEX-SQL — систему, которая позволяет более эффективно преобразовывать текстовые запросы в SQL, используя активное исследование структуры базы данных.
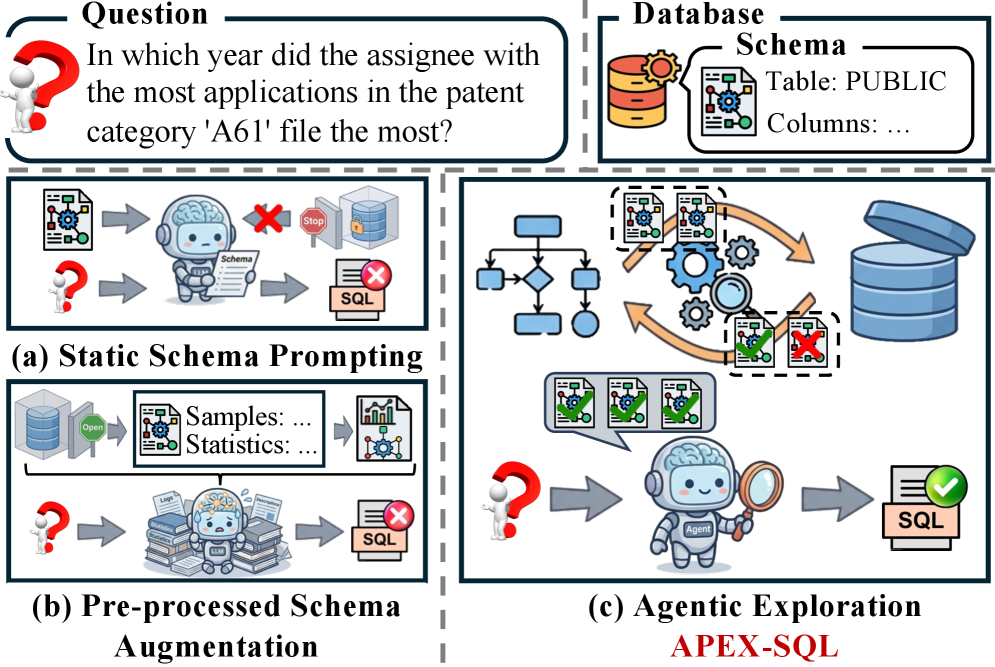
APEX-SQL использует агентное исследование для улучшения производительности Text-to-SQL за счет проверки предположений о схеме базы данных и адаптации стратегий генерации SQL-запросов на основе характеристик реальных данных.
Несмотря на успехи современных систем преобразования текста в SQL на академических бенчмарках, их применение в сложных корпоративных средах сталкивается с ограничениями, обусловленными статичным представлением схемы данных. В данной работе представлен APEX-SQL: Talking to the data via Agentic Exploration for Text-to-SQL — новый агентский фреймворк, который переходит от пассивного перевода к активному исследованию данных посредством верификации гипотез и адаптивного формирования запросов. Эксперименты на BIRD и Spider 2.0-Snow демонстрируют, что предложенный подход превосходит существующие решения при меньшем потреблении токенов, раскрывая скрытый потенциал базовых моделей в анализе корпоративных данных. Какие возможности открывает агентское исследование для повышения точности и эффективности систем Text-to-SQL в реальных условиях?
Преодоление Сложностей: Понимание Схем и Качество Данных
Традиционные системы преобразования естественного языка в SQL испытывают значительные трудности при работе со сложными схемами баз данных и неоднозначными запросами. Эти системы часто полагаются на поверхностное сопоставление шаблонов, что препятствует проведению надёжного логического анализа. Неспособность адекватно интерпретировать сложные взаимосвязи между таблицами и атрибутами приводит к ошибкам в генерации SQL-запросов, особенно когда запросы сформулированы неясно или требуют понимания контекста. Сложность схемы базы данных, включающая большое количество таблиц, связей и типов данных, значительно увеличивает пространство возможных интерпретаций запроса, что затрудняет выбор наиболее подходящего варианта. В результате, даже незначительные неточности в понимании запроса могут привести к возврату неверных или неполных результатов, снижая общую эффективность и надежность системы.
Традиционные системы преобразования текста в SQL зачастую полагаются на поверхностное сопоставление шаблонов, что ограничивает их способность к глубокому логическому выводу. В условиях некачественных данных, таких как пропущенные или противоречивые значения, эта проблема усугубляется. Вместо анализа семантики запроса и структуры базы данных, системы склонны к поиску простых соответствий между словами и полями, что приводит к неверным результатам при столкновении со сложными или неоднозначными запросами. Особенно заметно это проявляется при обработке временных данных, где отсутствие значений в ключевых полях препятствует построению корректных SQL-запросов и снижает общую надежность системы.
Распространенность проблем с качеством данных, таких как пропущенные или противоречивые значения, оказывает существенное негативное влияние на производительность и надежность систем обработки информации. Неполнота или некорректность данных затрудняет автоматический анализ и интерпретацию, приводя к неточным результатам и ошибкам в принятии решений. В частности, системы, работающие с большими объемами информации, становятся уязвимыми к искажениям, если значительная часть данных содержит неполные или противоречивые сведения. Это особенно актуально для приложений, требующих высокой точности и надежности, таких как финансовый анализ, медицинская диагностика или научные исследования, где даже незначительные погрешности могут привести к серьезным последствиям. Таким образом, обеспечение высокого качества данных является критически важной задачей для эффективной работы информационных систем и получения достоверных результатов.
Исследования показывают, что поля баз данных, предназначенные для хранения временной информации, такие как `UpstreamPublishedAt`, часто содержат пропущенные значения. Эта проблема существенно затрудняет процесс генерации корректных SQL-запросов, поскольку системы, неспособные обработать отсутствие данных, выдают неточные или неполные результаты. Отсутствие временных меток препятствует логическому сопоставлению запросов с соответствующими данными, особенно в ситуациях, когда требуется анализ временных рядов или фильтрация по дате публикации. В результате, надежность систем преобразования естественного языка в SQL снижается, что требует разработки более устойчивых к неполным данным алгоритмов и методов.
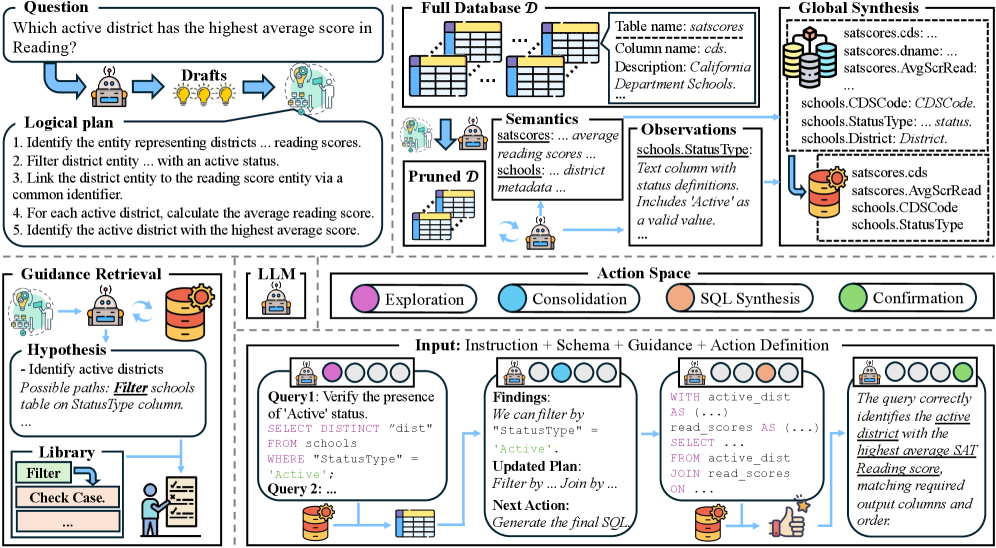
Агентное Исследование: Новый Подход к Анализу
В рамках Text-to-SQL подходу, `Агентное Исследование` представляет собой переход от пассивного восприятия запроса к активному исследованию структуры базы данных. Традиционные системы Text-to-SQL полагаются на прямое сопоставление естественного языка с существующей схемой. В отличие от них, `Агентное Исследование` подразумевает, что агент самостоятельно анализирует базу данных, формулирует гипотезы о ее содержимом и проверяет их посредством запросов. Этот проактивный подход позволяет преодолеть ограничения, связанные с неполной или неточной информацией о схеме, и повысить точность преобразования естественного языка в SQL-запросы.
В основе подхода `Agentic Exploration` лежит итеративный цикл «Формулировка гипотезы — Проверка», предназначенный для активного изучения схемы базы данных. Агент последовательно генерирует предположения о структуре данных, включая типы таблиц, столбцов и их взаимосвязи. Затем, посредством запросов к базе данных, эти гипотезы проверяются на соответствие действительности. В случае несоответствия, агент корректирует свои предположения и повторяет цикл, постепенно уточняя и расширяя свои знания о схеме. Этот процесс позволяет агенту эффективно справляться с неполной или неточной информацией о базе данных, динамически адаптируясь к её структуре и особенностям.
Ключевым этапом в процессе является логическое планирование, представляющее собой декомпозицию запроса, сформулированного на естественном языке, на последовательность абстрактных шагов перед взаимодействием с базой данных. Этот процесс включает в себя анализ запроса с целью определения необходимых действий, таких как извлечение конкретных данных, выполнение вычислений или фильтрация результатов. Логическое планирование позволяет агенту структурировать задачу, определить оптимальный порядок выполнения операций и сформировать запрос к базе данных, максимально соответствующий изначальному вопросу. В результате, система не просто сопоставляет слова в запросе с элементами схемы базы данных, а выстраивает логическую цепочку действий, направленных на получение необходимой информации.
Активное исследование схемы базы данных позволяет агенту обходить ограничения, вызванные неполнотой или неточностью данных. Вместо пассивного использования имеющейся информации, агент формирует и проверяет гипотезы о структуре базы данных, целенаправленно запрашивая недостающие сведения. Этот проактивный подход позволяет идентифицировать и разрешать неоднозначности, а также получать доступ к данным, которые изначально не были очевидны из исходного запроса на естественном языке. В результате повышается надежность и точность преобразования запросов в SQL, даже при наличии ошибок или пробелов в метаданных схемы.
Эффективное Сопоставление Схем с Двойным Отсечением
Для эффективной навигации по сложным схемам данных используется метод Dual-Pathway Pruning (двойной путь отсечения), который одновременно определяет как нерелевантные, так и релевантные элементы схемы. Этот подход позволяет сузить область поиска, исключая заведомо неполезные атрибуты и таблицы, и концентрируясь на потенциально полезных. Отсечение производится по двум направлениям: первое — исключение элементов, не соответствующих текущему запросу, и второе — выделение элементов, которые с высокой вероятностью содержат необходимую информацию. Данный механизм значительно ускоряет процесс идентификации требуемых таблиц и столбцов, повышая общую эффективность работы с базой данных.
Сокращение пространства поиска является ключевым фактором повышения эффективности процесса сопоставления схем (Schema Linking), который заключается в идентификации необходимых таблиц и столбцов. Уменьшение количества рассматриваемых элементов позволяет агенту быстрее находить релевантные данные и снижает вероятность ошибочного выбора, что напрямую влияет на точность и скорость установления связей между элементами различных схем. Оптимизация пространства поиска достигается за счет одновременного исключения нерелевантных элементов и фокусировки на потенциально полезных, что особенно важно при работе со сложными и масштабными базами данных.
Применение активного исследования в сочетании с методом Dual-Pathway Pruning позволяет системе обходить проблемные поля, такие как `UpstreamPublishedAt`, которые могут содержать неточные или неполные данные. Вместо этого, система использует альтернативные источники информации, например, поле `VersionInfo:Ordinal`, для получения необходимых данных и повышения точности связывания схем. Это позволяет агенту динамически адаптироваться к особенностям каждой схемы и эффективно находить релевантные данные, даже если основные поля недоступны или ненадежны.
Агент использует итеративные запросы к базе данных, называемые “Раундами исследования” (Exploration Rounds), для последовательного сбора данных и уточнения понимания структуры схемы. Каждый раунд включает в себя выполнение запроса, анализ полученных результатов и корректировку стратегии дальнейшего исследования. Этот процесс позволяет агенту динамически адаптироваться к сложной структуре схемы, выявлять взаимосвязи между таблицами и столбцами, а также отбрасывать нерелевантные данные, что повышает эффективность процесса связывания схемы (Schema Linking) и точность идентификации необходимых элементов.
Надежная Генерация SQL: Подтвержденные Результаты
Система, использующая метод агентного исследования и сопутствующие техники, демонстрирует успешную генерацию SQL-запросов даже при работе с неполными или несовершенными данными. Данный подход позволяет значительно повысить точность выполнения запросов — зафиксировано абсолютное увеличение на 18.33% при тестировании на корпоративных наборах данных. Агентное исследование обеспечивает эффективное преодоление сложностей, возникающих из-за ошибок или неточностей в исходных данных, что особенно важно при анализе реальных бизнес-систем, где качество информации часто оставляет желать лучшего. Это позволяет системе генерировать корректные и работоспособные SQL-запросы в условиях, когда традиционные методы Text-to-SQL могут давать сбои.
В основе повышения эффективности и точности генерации SQL-запросов лежит метод детерминированного получения инструкций. Данный подход предполагает использование логического плана запроса для формирования целевых директив, направляющих процесс исследования. Вместо случайного перебора возможных вариантов, система получает четкие указания, что позволяет значительно сократить время поиска и повысить вероятность успешного формирования корректного SQL-запроса. Использование логического плана в качестве ориентира обеспечивает более целенаправленное и эффективное исследование пространства возможных решений, что в конечном итоге приводит к повышению надежности и точности всей системы.
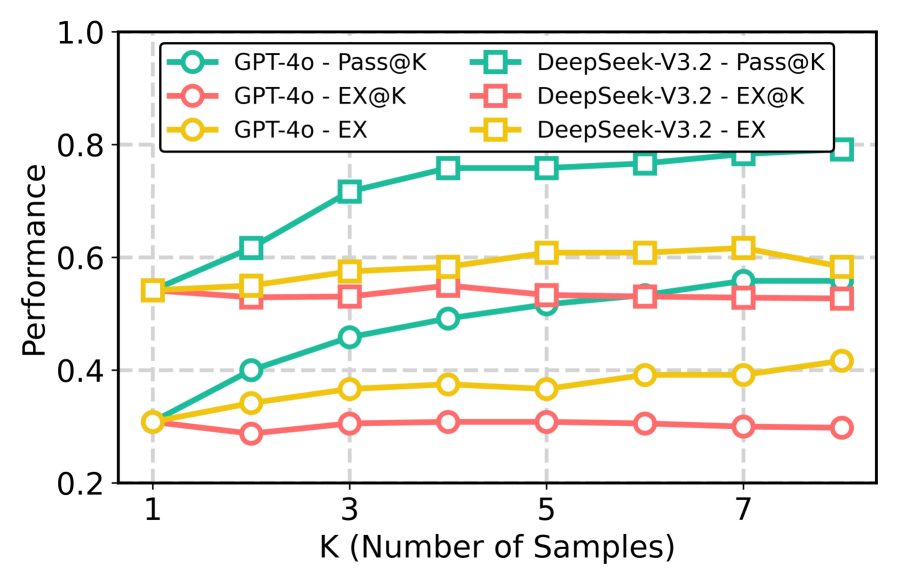
Результаты тестирования демонстрируют значительное превосходство разработанной системы в генерации SQL-запросов. На датасете BIRD-Dev достигнута точность выполнения в 70.7%, что превышает показатели OpenSearch-SQL (69.3%) и RSL-SQL (67.2%). Особенно заметно улучшение на более сложном датасете Spider 2.0-Snow, где точность выполнения составила 51.0%, существенно опережая результаты DSR-SQL (35.3%). Эти показатели подтверждают эффективность предложенного подхода в решении задач преобразования естественного языка в структурированные SQL-запросы, даже в условиях повышенной сложности и неоднозначности данных.
Система демонстрирует впечатляющий показатель успешности в 70.20% при оценке Pass@8, что свидетельствует о значительном повышении надежности и устойчивости по сравнению с традиционными системами преобразования текста в SQL-запросы. Этот показатель означает, что в 70.20% случаев система способна сгенерировать корректный SQL-запрос хотя бы из восьми предпринятых попыток, что особенно важно при работе со сложными и неоднозначными запросами на естественном языке. Достигнутое улучшение в надежности позволяет системе более эффективно справляться с вариативностью формулировок запросов и неточностями в данных, обеспечивая стабильно высокие результаты даже в сложных условиях, что открывает новые возможности для автоматизации работы с базами данных.
Представленная работа демонстрирует подход к построению систем, где понимание целостной картины базы данных является ключевым. APEX-SQL, активно проверяя предположения о схеме и адаптируя стратегии генерации запросов на основе реальных характеристик данных, подтверждает важность холистического взгляда на архитектуру. Как однажды заметил Дональд Дэвис: «Простота — это высшая степень изысканности». Эта фраза особенно точно отражает суть разработки эффективных систем взаимодействия с данными, где ясность структуры и логика взаимодействия определяют успешность решения поставленной задачи. APEX-SQL, стремясь к точности и адаптивности, воплощает этот принцип в своей архитектуре.
Что дальше?
Представленная работа, безусловно, демонстрирует элегантность подхода к решению задачи Text-to-SQL через активное исследование структуры данных. Однако, не стоит забывать, что сама схема базы данных — лишь статичное отражение динамичного мира информации. Система, стремящаяся к истинному пониманию, должна учитывать не только формальное описание, но и фактическое распределение данных, их взаимосвязи, а также скрытые закономерности, которые не всегда очевидны из метаданных. Иллюзия понимания часто возникает из-за упрощённых моделей, и APEX-SQL, несмотря на свои достоинства, не свободна от этого.
Дальнейшее развитие, вероятно, потребует смещения фокуса с генерации SQL-запросов как таковых на построение более глубокой семантической модели данных. Необходимо исследовать возможности интеграции методов активного обучения и нечёткой логики, позволяющих системе адаптироваться к неполной или противоречивой информации. Важным направлением представляется разработка механизмов самопроверки и исправления ошибок, основанных на анализе результатов выполнения запросов и сопоставлении их с ожиданиями. По сути, речь идёт о создании системы, способной к саморефлексии и постоянному совершенствованию.
В конечном счёте, истинный прогресс в области Text-to-SQL будет достигнут не тогда, когда система научится генерировать синтаксически верные запросы, а когда она сможет понять, что она спрашивает, и зачем. Иначе, это будет всего лишь ещё одна форма автоматизации, лишенная интеллекта и способности к истинному познанию.
Оригинал статьи: https://arxiv.org/pdf/2602.16720.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Предел возможностей: где большие языковые модели теряют разум?
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Квантовый шум: за пределами стандартных моделей
- Виртуальная примерка без границ: EVTAR учится у образов
- Искусственный разум и квантовые данные: новый подход к синтезу табличных данных
- Моделирование спектроскопии электронного пучка: новый подход
- Квантовое программирование: Карта развивающегося мира
- За пределами стандартной точности: новая структура эффективной теории
- Сердце музыки: открытые модели для создания композиций
2026-02-21 13:07