Автор: Денис Аветисян
В статье представлен подробный анализ разработки открытых языковых моделей Trinity, включая модель Trinity Large, и описаны ключевые стратегии для обеспечения стабильного обучения и эффективного масштабирования при экстремальной разреженности.
Исследование посвящено архитектуре Sparse Mixture-of-Experts, методам курирования данных, расширению контекста и повышению стабильности обучения больших языковых моделей.
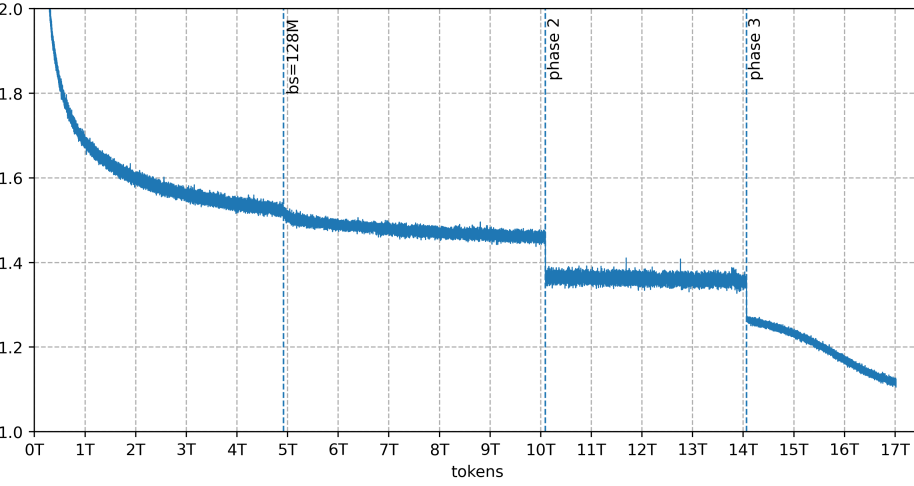
Обеспечение стабильности обучения и эффективного масштабирования больших языковых моделей остается сложной задачей, особенно при экстремальной разреженности. В настоящем техническом отчете ‘Arcee Trinity Large Technical Report’ представлена семейство моделей Trinity — Trinity Large (400B параметров, 13B активируемых), Trinity Nano и Trinity Mini — разработанных на основе разреженной архитектуры Mixture-of-Experts. Ключевым результатом является демонстрация стабильного обучения моделей на триллионах токенов с использованием нового алгоритма балансировки нагрузки Soft-clamped Momentum Expert Bias Updates (SMEBU) и оптимизатора Muon. Какие перспективы открывает данная архитектура для создания еще более эффективных и масштабируемых языковых моделей нового поколения?
Преодолевая Границы Масштабируемости: Вызов для Больших Языковых Моделей
Традиционные архитектуры трансформеров, несмотря на свою вычислительную мощь, сталкиваются с проблемой квадратичного масштабирования по отношению к длине последовательности обрабатываемого текста. Это означает, что с каждым увеличением количества токенов во входных данных, требуемые вычислительные ресурсы и время обработки растут экспоненциально. В частности, механизм внимания (attention), ключевой компонент трансформеров, требует вычисления взаимодействия между каждой парой токенов, что приводит к O(n^2) сложности, где n — длина последовательности. Такое масштабирование существенно ограничивает возможность эффективной обработки длинных текстов, таких как книги, научные статьи или стенограммы, что препятствует применению этих моделей в задачах, требующих глубокого понимания контекста и анализа больших объемов информации.
Ограничение, связанное с квадратичным увеличением вычислительной сложности, существенно влияет на эффективность больших языковых моделей при решении задач, требующих глубокого понимания контекста. В частности, сложные рассуждения и построение связных и информативных резюме длинных документов становятся затруднительными. Модели испытывают трудности с удержанием и обработкой информации, распределенной по всему тексту, что приводит к снижению точности и последовательности результатов. Это проявляется в неспособности улавливать тонкие взаимосвязи между отдаленными фрагментами текста, а также в склонности к генерации обобщений, не отражающих полного содержания исходного материала. Таким образом, преодоление этих ограничений является ключевым шагом к созданию языковых моделей, способных к полноценному анализу и обработке больших объемов информации.
Trinity: Архитектура Разреженных Экспертов для Новой Эры Масштабируемости
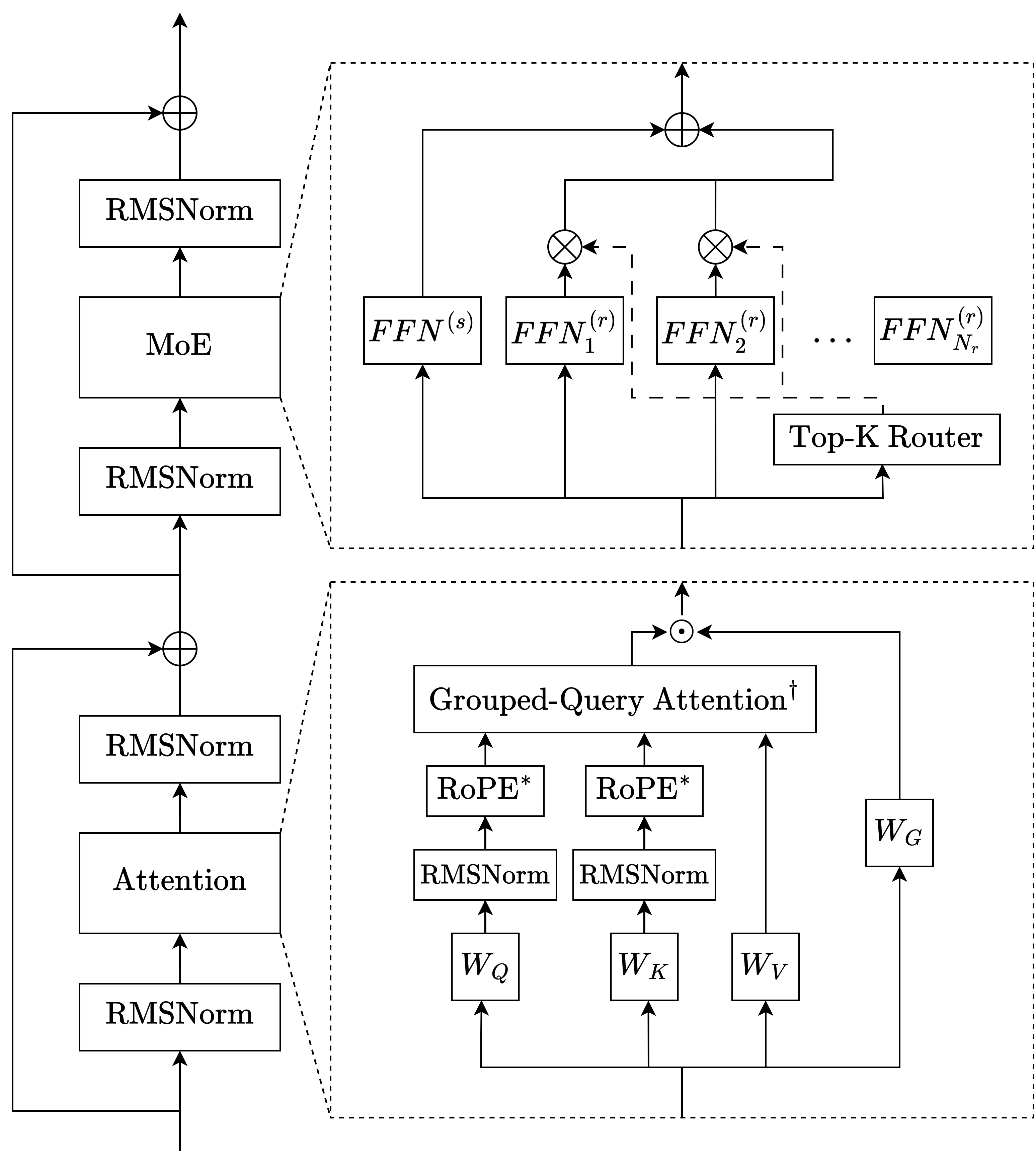
Архитектура Trinity использует разреженный слой Mixture-of-Experts (MoE) для существенного увеличения емкости модели без пропорционального увеличения вычислительных затрат. В отличие от традиционных плотных моделей, где каждый параметр участвует в каждой операции, MoE активирует лишь подмножество параметров (экспертов) для обработки каждого токена. Это позволяет модели иметь значительно большее количество параметров (например, 400 миллиардов в Trinity Large) при сохранении приемлемой скорости вычислений, поскольку обработка каждого токена выполняется только несколькими экспертами, а не всеми параметрами модели. Такой подход позволяет достичь большей специализации и эффективности, поскольку каждый эксперт может быть оптимизирован для определенного подмножества задач или типов данных.
Архитектура Trinity использует механизм интеллектуальной маршрутизации токенов к подмножеству специализированных “экспертных” сетей. Вместо активации всех параметров модели для каждого токена, система динамически определяет, какие эксперты наиболее релевантны для обработки конкретного входного токена. Это позволяет модели эффективно распределять вычислительные ресурсы, концентрируясь на наиболее значимых параметрах для каждого токена, и достигать большей специализации в обработке различных типов данных. В результате, достигается повышение эффективности и снижение вычислительных затрат по сравнению с традиционными плотными моделями.
Архитектура Trinity реализует подход Mixture-of-Experts (MoE) в трех различных моделях: Trinity Large, Trinity Nano и Trinity Mini. Это позволяет проводить масштабируемые эксперименты и валидацию различных конфигураций и размеров модели. Наиболее крупная из них, Trinity Large, содержит 400 миллиардов параметров, что обеспечивает значительную емкость модели при сохранении эффективности благодаря разреженной активации экспертов. Использование различных размеров моделей (Large, Nano, Mini) позволяет оценить компромисс между производительностью и вычислительными затратами, а также оптимизировать модель для конкретных задач и аппаратных ресурсов.
Оптимизация Обучения для Эффективности MoE: Баланс и Стабильность
Обучение моделей Trinity использует регуляризацию ‘z-loss’ для стабилизации процесса и предотвращения коллапса экспертов. Данная техника заключается в добавлении к общей функции потерь компонента, штрафующего чрезмерную специализацию отдельных экспертов. z-loss вычисляется на основе скрытых представлений (z) выходных токенов каждого эксперта, стимулируя равномерное использование всех экспертов и предотвращая ситуацию, когда небольшое подмножество экспертов обрабатывает подавляющее большинство запросов, что приводит к снижению производительности и обобщающей способности модели. Эффективность z-loss заключается в минимизации дисперсии в использовании экспертов, способствуя более устойчивому и сбалансированному обучению.
В процессе обучения Mixture-of-Experts (MoE) моделей, использование Sequence-wise Auxiliary Loss (SAL) направлено на обеспечение равномерной загрузки экспертов и предотвращение их перегрузки. SAL вычисляет дополнительную функцию потерь, основанную на распределении входных последовательностей между экспертами. Это позволяет модели штрафовать ситуации, когда определенные эксперты получают непропорционально большое количество последовательностей, стимулируя более сбалансированное использование всех доступных экспертов и, как следствие, повышая эффективность и стабильность обучения. Фактически, SAL действует как регуляризатор, способствующий более равномерному распределению нагрузки между экспертами на протяжении всего процесса обучения.
Для обеспечения эффективного параллелизма при обучении моделей, используется комбинация технологий Hybrid Sharded Data Parallel (HSDP) и Expert Parallelism (EP). HSDP разбивает данные и параметры модели между GPU, минимизируя объем памяти, необходимый каждой карте. Expert Parallelism (EP) распределяет различные эксперты (части модели Mixture-of-Experts) по разным GPU, что позволяет одновременно обрабатывать разные части входных данных. Такое сочетание позволяет значительно ускорить процесс обучения за счет параллельной обработки данных и параметров, а также эффективно использовать ресурсы множества GPU.
Эффективность Развертывания и Вывода: Ключ к Практическому Применению
Модели Trinity разработаны с акцентом на эффективность инференса, что достигается благодаря применению квантизации FP8 и смешанной точности BF16. Эти технологии позволяют значительно уменьшить объем занимаемой памяти и ускорить вычисления без существенной потери точности. Квантизация FP8, в частности, снижает требования к пропускной способности памяти, что особенно важно при работе с большими языковыми моделями. Использование BF16, в свою очередь, обеспечивает баланс между скоростью вычислений и точностью, позволяя эффективно обрабатывать данные и сохранять качество результатов. Такой подход к оптимизации позволяет Trinity демонстрировать высокую производительность даже на ограниченных аппаратных ресурсах.
Модели Trinity демонстрируют впечатляющую способность к обработке расширенных последовательностей данных благодаря инновационному сочетанию возможностей расширения контекста и механизма скользящего окна внимания. В отличие от традиционных подходов, которые испытывают затруднения при работе с длинными текстами из-за экспоненциального роста вычислительных затрат, Trinity эффективно управляет информацией, фокусируясь на наиболее релевантных частях входной последовательности. Механизм скользящего окна внимания позволяет модели динамически адаптироваться к различным длинам текста, сохраняя при этом высокую производительность и минимизируя потребление памяти. Это позволяет Trinity успешно справляться с задачами, требующими анализа обширных документов, таких как суммирование текста, ответы на вопросы и машинный перевод, даже при ограниченных вычислительных ресурсах.
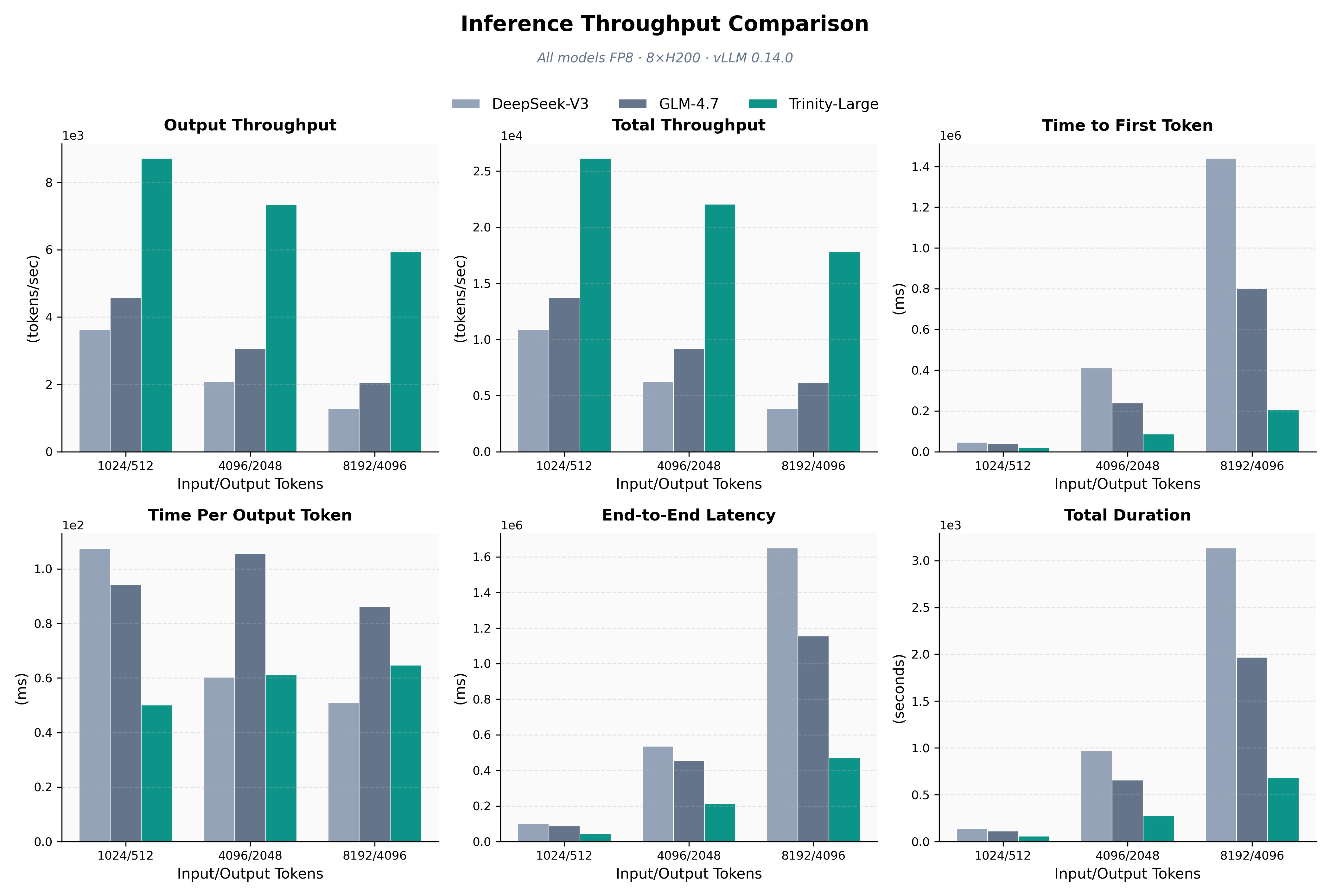
Для эффективного развертывания и обслуживания моделей Trinity, включая Trinity Large, используется высокопроизводительная платформа вывода vLLM. Эта платформа позволяет значительно увеличить пропускную способность и минимизировать задержку при обработке запросов. В частности, Trinity Large демонстрирует впечатляющую пропускную способность при использовании кластера из восьми графических ускорителей H200, что подтверждает эффективность выбранного подхода к оптимизации и масштабированию. Благодаря vLLM, модели Trinity способны обрабатывать большое количество запросов одновременно, обеспечивая высокую скорость отклика и стабильную производительность даже при высоких нагрузках.
Обеспечение Стабильности и Сбалансированного Обучения: Мониторинг и Регулировка
В процессе обучения сложных языковых моделей, таких как Trinity, пристальное внимание уделяется мониторингу метрик MaxVio и гетерогенности пакета. Эти показатели позволяют оценить баланс нагрузки между экспертами в модели и распределение данных внутри обучающей выборки. Высокие значения MaxVio свидетельствуют о неравномерной загрузке экспертов, когда некоторые из них перегружены, а другие недостаточно используются, что приводит к снижению эффективности обучения. Анализ гетерогенности пакета, в свою очередь, помогает выявить дисбаланс в представленности различных типов данных, что может привести к предвзятости модели. Регулярный мониторинг этих метрик и корректировка параметров обучения позволяют обеспечить стабильность процесса и оптимальное использование вычислительных ресурсов, способствуя повышению качества и надежности модели.
В процессе обучения моделей, работающих с множеством документов, возникает проблема так называемого «утечки внимания» — когда модель, анализируя один документ, невольно использует информацию из других, искажая контекст и снижая точность. Для предотвращения этого явления используется метод внутридокументной маскировки. Он заключается в том, что модель намеренно блокирует доступ к информации из других документов при обработке конкретного текста, фокусируясь исключительно на его внутреннем содержании. Это позволяет модели лучше понимать контекст каждого отдельного документа и существенно повышает производительность в задачах, требующих анализа больших объемов информации, например, при поиске ответов на вопросы или составлении обзоров.
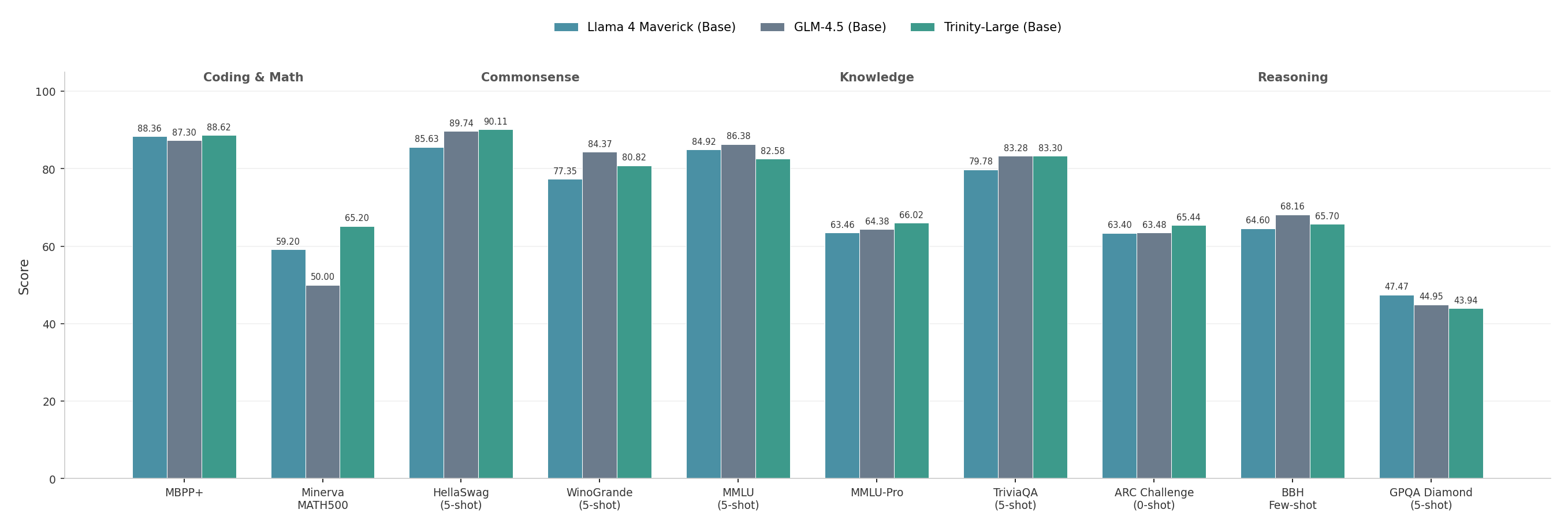
Архитектура Trinity Large демонстрирует конкурентоспособные результаты, сопоставимые с моделью GLM 4.5 Base, при этом использует в 2.5 раза меньше активных параметров — всего 13 миллиардов. Достижение такой эффективности стало возможным благодаря сочетанию продвинутых методов мониторинга и оптимизации. В частности, применение оптимизаторов Muon и AdamW в связке с метриками, отслеживающими баланс нагрузки экспертов и распределение данных, позволило существенно улучшить процесс обучения и масштабируемость модели. Это открывает перспективы для дальнейшего развития архитектуры Trinity, позволяя создавать более компактные и производительные языковые модели без потери качества.
Исследование, представленное в данной работе, демонстрирует, что успешное масштабирование разреженных моделей, таких как Trinity Large, требует не просто увеличения вычислительных ресурсов, но и тщательной проработки стратегий обучения и управления данными. Подобно тому, как историческая хроника системы требует постоянного логирования, стабильность обучения этих моделей напрямую зависит от качества и разнообразия данных, используемых для их создания. Как однажды заметил Винтон Серф: «Интернет — это не технология, а способ организации информации». Эта фраза отражает суть подхода, описанного в статье: создание эффективной системы требует не только мощных инструментов, но и продуманной организации и управления информацией, чтобы обеспечить её долговечность и надежность.
Что дальше?
Разработка семейства моделей Trinity, и особенно Trinity Large, демонстрирует, что разреженность — не просто технический прием для снижения вычислительных затрат, но и потенциальный путь к созданию систем, более устойчивых к энтропии. Однако, стабильность обучения, достигнутая в данной работе, следует воспринимать не как конечное состояние, а как временное равновесие в сложной системе. Проблемы, связанные с курацией данных и масштабированием разреженных моделей, остаются актуальными, напоминая о том, что любая оптимизация несет в себе новые источники ошибок.
Следующим этапом представляется не просто увеличение размера моделей или совершенствование алгоритмов обучения, а поиск принципиально новых подходов к представлению знаний. Попытки расширить контекстное окно — это, по сути, борьба со временем, попытка удержать больше информации в краткосрочной памяти системы. В конечном итоге, задача заключается не в увеличении объема памяти, а в создании систем, способных к самообучению и адаптации в меняющейся среде, подобно биологическим организмам.
Вероятно, будущее разреженных моделей связано с разработкой механизмов, позволяющих им самостоятельно обнаруживать и исправлять ошибки, не требуя постоянного вмешательства человека. Инциденты, возникающие в процессе обучения, следует рассматривать не как провалы, а как шаги системы на пути к зрелости. В конечном счете, время — это не метрика, а среда, в которой существуют системы, и их способность адаптироваться к этой среде — главный критерий успеха.
Оригинал статьи: https://arxiv.org/pdf/2602.17004.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Эмоциональный отпечаток: Как мы научили ИИ читать душу (и почему рейтинги вам врут)
- Магнитные туннельные переходы: новый путь к квантовым вычислениям?
- Ускорение нейросетей: новый подход для процессоров AMD
- Музыка, созданная ИИ: кто мы есть, когда слушаем?
- Грань Разума и Вычислений: Анализ Эффективности Больших Языковых Моделей
- Ускорение обучения языковых моделей: новый подход к передаче знаний
- Квантовые Заметки: От Прорывов к Реальности
- Серебро и медь: новый взгляд на наноаллои
- Оптимизация без квантов: новый алгоритм превосходит QAOA
- Взгляд в будущее нейрорадиологии: тандем человека и искусственного интеллекта
2026-02-20 11:50