Автор: Денис Аветисян
Новый метод Progressive Thought Encoding позволяет существенно снизить затраты памяти при обучении крупных языковых моделей, сохраняя при этом их способность к сложным рассуждениям.
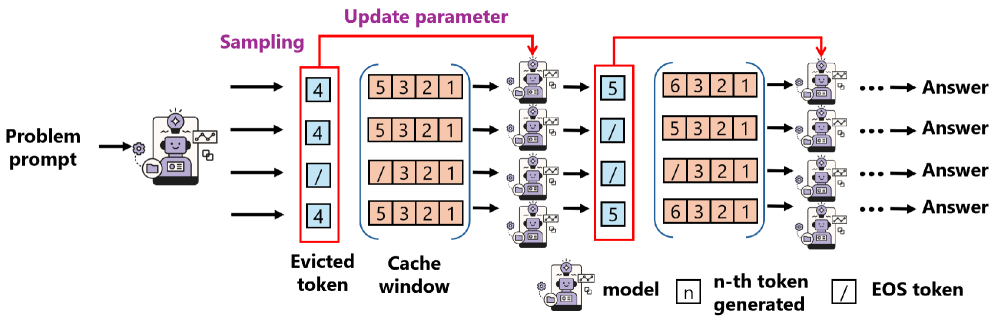
Прогрессивное кодирование мыслей позволяет эффективно использовать вытесненные токены, перенося их информацию в веса модели для улучшения работы с длинным контекстом.
Обучение больших моделей рассуждения (LRM) сталкивается с противоречием между их способностью решать сложные задачи и высокой вычислительной стоимостью, обусловленной необходимостью длинных последовательностей при обучении с подкреплением. В статье ‘Training Large Reasoning Models Efficiently via Progressive Thought Encoding’ предложен новый метод, позволяющий эффективно обучать LRM, прогрессивно кодируя промежуточные рассуждения в компактные векторные представления. Такой подход снижает потребление памяти и позволяет достичь улучшения точности на 19.3% по сравнению с LoRA-fine-tuning и на 29.9% по сравнению с LRM без fine-tuning на различных математических бенчмарках. Возможно ли дальнейшее масштабирование данного подхода для решения еще более сложных задач и преодоления ограничений, связанных с доступностью вычислительных ресурсов?
Масштабируемость Рассуждений: Предел Совершенства?
Несмотря на впечатляющие возможности, современные большие языковые модели (БЯМ) испытывают трудности при решении задач, требующих сложного логического мышления, что напрямую связано с ограничениями на длину контекста. Эти модели, демонстрирующие удивительную способность генерировать текст и отвечать на вопросы, оказываются неспособными эффективно обрабатывать длинные последовательности информации, необходимые для глубокого анализа и вывода. Ограничение контекста означает, что БЯМ могут учитывать лишь определенный объем предшествующего текста при генерации ответа, что приводит к потере важной информации и, как следствие, к неточным или неполным выводам. В ситуациях, требующих учета большого количества взаимосвязанных фактов или отслеживания сложных зависимостей, эта проблема становится особенно заметной, подчеркивая необходимость разработки новых архитектур и методов, способных преодолеть ограничения на длину контекста и обеспечить более надежное и эффективное логическое мышление.
Увеличение масштаба языковых моделей для решения сложных задач неизбежно приводит к квадратичному росту требований к памяти, что становится существенным препятствием для производительности. Каждое добавление нового элемента в последовательность требует хранения взаимодействия этого элемента со всеми предыдущими, что приводит к экспоненциальному увеличению вычислительных затрат и потребляемой памяти. O(n^2) — именно такая зависимость ограничивает возможности обработки длинных контекстов и, следовательно, решает проблему эффективного рассуждения. Данное ограничение не позволяет моделям полноценно анализировать сложные взаимосвязи в больших объемах информации, что делает масштабирование одним из ключевых вызовов в области искусственного интеллекта.
Для эффективного рассуждения необходима способность удерживать и извлекать информацию из длинных последовательностей данных, что представляет собой серьезную проблему для традиционных архитектур, основанных на трансформерах. В то время как эти модели преуспевают в обработке относительно коротких текстов, их производительность резко снижается при увеличении длины входной последовательности. Это связано с тем, что механизм внимания в трансформерах требует вычисления связей между всеми парами токенов, что приводит к квадратичному росту вычислительных затрат и потребления памяти. В результате, модели испытывают трудности с поддержанием контекста и установлением долгосрочных зависимостей, необходимых для сложных рассуждений, что ограничивает их применение в задачах, требующих анализа больших объемов информации или понимания сложных нарративов.
Прогрессивное Кодирование Мыслей: Эффективность в Ограниченном Пространстве
Прогрессивное кодирование мыслей (Progressive Thought Encoding) представляет собой параметрически-эффективный метод тонкой настройки больших языковых моделей (LLM), направленный на смягчение проблемы нехватки памяти. В отличие от традиционных методов, требующих хранения полной истории контекста, данный подход позволяет модели эффективно использовать ограниченные ресурсы GPU за счет оптимизации процесса запоминания и доступа к предыдущим этапам рассуждений. Это достигается путем адаптации параметров модели только для вновь поступающей информации, что существенно снижает вычислительные затраты и потребление памяти при сохранении способности к сложному логическому выводу.
Метод прогрессивного кодирования мыслей (Progressive Thought Encoding) реализует сжатие информации о вытесненных токенах путем преобразования их в векторы фиксированного размера. Это позволяет модели обращаться к предыдущим этапам рассуждений без необходимости хранения полной истории контекста. Вместо хранения всей последовательности токенов, модель сохраняет компактные векторные представления, что значительно снижает потребность в памяти и позволяет эффективно использовать предыдущую информацию для текущих вычислений. Данный подход обеспечивает доступ к релевантным данным из прошлого, несмотря на ограниченные ресурсы памяти.
Комбинирование прогрессивного кодирования мыслей (Progressive Thought Encoding) с методами, такими как LoRA (Low-Rank Adaptation), позволяет достичь повышения точности рассуждений на бенчмарке AIME (Abstractive Information Machine Evaluation) до 23.4%. Одновременно с этим, наблюдается снижение потребления памяти GPU почти на 50%. Данный эффект достигается за счет эффективного кодирования ранее обработанных токенов в векторы фиксированного размера, что позволяет модели обращаться к прошлым этапам рассуждений без сохранения полного контекста, и оптимизации параметров модели с использованием LoRA для снижения вычислительных затрат.
Проверка на Прочности: Результаты на Сложных Математических Задачах
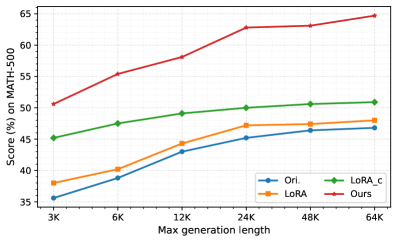
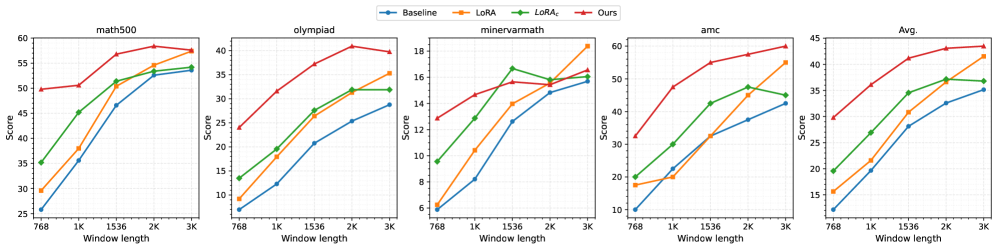
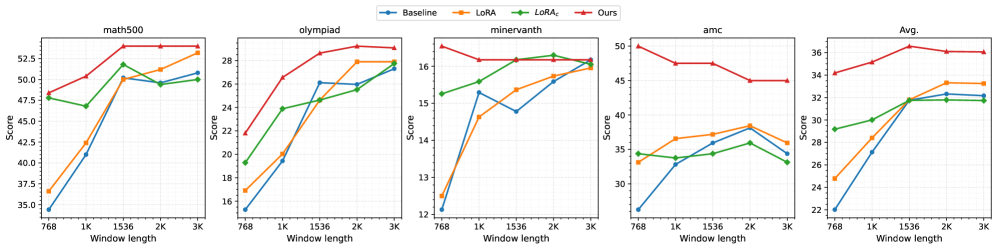
Экспериментальные исследования показали значительное улучшение производительности моделей при использовании метода Progressive Thought Encoding на стандартных наборах данных для оценки математических способностей, включая Math500, OlympiadBench, Minerva Math, AMC и AIME. Результаты демонстрируют, что данный подход позволяет повысить точность решения сложных математических задач по сравнению с базовыми моделями, что подтверждается статистическими данными, полученными в ходе тестирования на различных бенчмарках.
Результаты экспериментов демонстрируют, что модели, прошедшие тонкую настройку с использованием методики Progressive Thought Encoding, последовательно превосходят базовые модели при решении сложных математических задач. На некоторых эталонных наборах данных, таких как Math500, OlympiadBench и других, зафиксировано улучшение результатов до 12% по сравнению с исходными моделями. Детальные данные, включая результаты по каждому бенчмарку и статистическую значимость улучшений, представлены в дополнительном материале.
Использование открытых предварительно обученных инструктивных моделей, таких как Qwen2.5-7B-Instruct, Qwen2.5-4B-Instruct и DeepSeek-R1-Distill-Llama-8B, демонстрирует улучшение эффективности подхода Progressive Thought Encoding. Эти модели, доступные для свободного использования и модификации, позволяют добиться более высоких результатов в решении сложных математических задач по сравнению с использованием закрытых или менее специализированных моделей. Эксперименты показывают, что комбинация Progressive Thought Encoding и указанных открытых моделей позволяет эффективно использовать преимущества предварительного обучения и инструктивной настройки для достижения оптимальной производительности в задачах математического рассуждения.
Взгляд в Будущее: Влияние и Перспективы Развития
Прогрессивное кодирование мыслей, в сочетании со стратегиями отбрасывания токенов, такими как HeadKV, представляет собой перспективный подход к созданию более эффективных и масштабируемых моделей рассуждений. Данная методика позволяет модели динамически фокусироваться на наиболее релевантных аспектах процесса мышления, отсеивая избыточную информацию. Вместо обработки всей последовательности токенов на каждом шаге, система выборочно сохраняет и использует ключевые элементы, значительно снижая вычислительные затраты и потребление памяти. Это особенно важно при решении сложных задач, требующих длительных цепочек рассуждений, поскольку позволяет модели сохранять когерентность и точность, избегая перегрузки контекста и потери важной информации. В результате, достигается баланс между вычислительной эффективностью и способностью к сложному анализу, открывая возможности для разработки более мощных и доступных систем искусственного интеллекта.
В основе повышения эффективности современных моделей рассуждения лежит концепция сжатия информации, достигаемая за счет использования глобальных токенов и латентных векторов. Данный подход позволяет модели сохранять контекстуальную осведомленность, не увеличивая при этом потребление памяти. Глобальные токены, представляющие собой ключевые элементы контекста, кодируются и используются повторно, избегая необходимости хранить полные копии информации. Латентные векторы, в свою очередь, представляют собой сжатое представление данных, улавливающее наиболее важные аспекты контекста. Благодаря этой комбинации, модель способна обрабатывать длинные последовательности информации, сохраняя при этом высокую скорость и эффективность, что открывает возможности для решения более сложных задач и работы с большими объемами данных.
Дальнейшие исследования направлены на усовершенствование представленных методов кодирования и отбраковки токенов, с целью повышения их эффективности и масштабируемости. Особое внимание уделяется адаптации этих техник к новым областям применения, таким как автоматическая генерация программного кода и ускорение научных открытий. В частности, предполагается, что оптимизированные модели смогут значительно упростить процесс разработки программного обеспечения, автоматически генерируя код на основе заданных требований, а также способствовать более быстрому анализу больших объемов научных данных и выдвижению новых гипотез. Развитие этих направлений позволит не только улучшить существующие системы искусственного интеллекта, но и открыть новые возможности для решения сложных задач в различных областях науки и техники.
Статья описывает попытку обуздать ненасытный аппетит больших языковых моделей к памяти, используя метод Progressive Thought Encoding. Это напоминает о вечной борьбе между теорией и практикой. Авторы стремятся к элегантности, кодируя информацию об удаленных токенах непосредственно в веса модели, но неизбежно сталкиваются с тем, что каждое «улучшение» создает новые слои абстракции и, как следствие, новые точки отказа. Как говорил Алан Тьюринг: «Можно сказать, что я всегда был больше заинтересован в вопросах, чем в ответах». Эта фраза отражает суть исследования — не просто добиться результата, а понять, как работает сам процесс обучения и как его сделать более эффективным, несмотря на все компромиссы и неизбежные ограничения, которые диктует железо.
Что дальше?
Предложенный метод прогрессивного кодирования мыслей, несомненно, является очередным шагом в бесконечной гонке за эффективностью обучения больших моделей. Однако, давайте не будем строить иллюзий относительно «революционности». Продакшен всегда найдет способ выжать все соки из ограниченной памяти, а затем потребует еще больше. Вопрос не в том, как уместить больше в имеющееся пространство, а в том, насколько быстро мы научимся игнорировать большую часть информации, как это делает человеческий мозг.
Очевидно, что проблема долгосрочного рассуждения остаётся открытой. Простое кодирование «выброшенных» токенов в веса модели — это лишь временное решение, не устраняющее фундаментальную сложность поддержания когерентности при работе с длинными контекстами. Следующим этапом, вероятно, станет разработка более изощренных стратегий «вытеснения» информации, возможно, основанных на принципах внимания или иерархической памяти, но и они неизбежно столкнутся с ограничениями аппаратного обеспечения и, главное, с неумолимой потребностью в еще большем количестве данных.
В конечном счете, данная работа — это очередной кирпичик в стене, которая никогда не будет завершена. Тесты, конечно, показывают улучшение, но тесты — это лишь форма надежды, а не уверенности. Остается только гадать, какой скрипт удалит прод на следующей неделе, когда кто-нибудь попытается применить этот метод в реальных условиях.
Оригинал статьи: https://arxiv.org/pdf/2602.16839.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Виртуальная примерка без границ: EVTAR учится у образов
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Сердце музыки: открытые модели для создания композиций
- Квантовый скачок: от лаборатории к рынку
2026-02-22 15:58