Автор: Денис Аветисян
Исследователи предлагают метод, позволяющий достичь сопоставимой с обучением с подкреплением способности к рассуждениям у крупных языковых моделей, используя оптимизированный алгоритм выборки.
Эффективный вывод без дополнительного обучения достигается за счет оттачивания распределения вероятностей и масштабируемой выборки.
Несмотря на успехи обучения с подкреплением в повышении рассуждений больших языковых моделей (LLM), всё чаще возникает вопрос о том, действительно ли эти улучшения связаны с приобретением новых способностей или просто с уточнением распределения вероятностей. В работе ‘Scalable Power Sampling: Unlocking Efficient, Training-Free Reasoning for LLMs via Distribution Sharpening’ предложен новый подход, демонстрирующий, что сопоставимые результаты можно достичь путем эффективной выборки из заостренного распределения во время инференса, избегая дорогостоящего обучения с подкреплением. Авторы показали, что глобальное распределение вероятностей может быть эффективно аппроксимировано локальным масштабированным распределением низкой температуры, что позволяет снизить вычислительные затраты более чем в 10 раз по сравнению с методами на основе цепей Маркова Монте-Карло. Возможно ли дальнейшее повышение эффективности и обобщающей способности LLM за счет более тонкой настройки стратегий выборки и распределения вероятностей?
Пророчество о Глубине: За пределами Поверхностного Понимания
Несмотря на впечатляющий прогресс в области искусственного интеллекта, современные большие языковые модели часто демонстрируют затруднения при решении сложных задач, требующих глубокого логического мышления. Эта хрупкость проявляется в неожиданных ошибках и неспособности последовательно применять знания в различных контекстах. Модели могут генерировать грамматически правильный и даже правдоподобный текст, однако зачастую лишены истинного понимания смысла, оперируя лишь статистическими закономерностями в данных. Такая поверхностная обработка информации приводит к тому, что даже незначительные изменения в формулировке задачи могут вызвать существенные отклонения в ответах, подчеркивая отсутствие гибкости и адаптивности, свойственных человеческому интеллекту.
Традиционные методы авторегрессионной выборки, несмотря на свою эффективность в генерации связного текста, зачастую не способны адекватно отразить сложность логического мышления. Модели, использующие эти методы, склонны к непоследовательности и ошибкам при решении задач, требующих многоступенчатого рассуждения. Они оперируют вероятностями последовательностей слов, но не обладают механизмом для проверки логической корректности выводимых заключений. Это приводит к тому, что даже небольшие отклонения от логической цепочки могут привести к неверным ответам, демонстрируя хрупкость кажущегося интеллекта и подчеркивая необходимость разработки более совершенных методов, способных улавливать и воспроизводить нюансы логической аргументации.

Переосмысление Вероятности: Подход Распределения Степени
Предлагаемый метод основан на использовании “Распределения Степени” (p_{\alpha}(x)), которое преобразует вероятностный ландшафт языковой модели, усиливая наиболее вероятные пути рассуждений. В отличие от традиционных подходов, фокусирующихся на вероятности отдельного токена, данное распределение оценивает вероятность всей траектории мыслительного процесса. Это достигается путем модификации стандартного вероятностного распределения, что позволяет модели отдавать предпочтение последовательностям, которые с большей вероятностью приведут к логически обоснованному и когерентному ответу. Использование распределения степени позволяет эффективно сужать пространство поиска, сосредотачиваясь на наиболее перспективных вариантах рассуждений и снижая вероятность отклонения в менее вероятные или ошибочные направления.
В отличие от традиционных методов, которые сосредотачиваются на выборе наиболее вероятного токена на каждом шаге генерации, предлагаемый подход оценивает вероятность не отдельного токена, а всей последовательности рассуждений — траектории мысли. Это означает, что при формировании распределения вероятностей учитывается не только локальная правдоподобность следующего слова, но и согласованность всей сформированной цепочки рассуждений с поставленной задачей. Таким образом, вероятность траектории вычисляется как произведение вероятностей всех токенов, входящих в эту последовательность, что позволяет модели отдавать предпочтение более когерентным и логически связанным цепочкам рассуждений, даже если отдельные токены в них менее вероятны, чем в альтернативных траекториях.
Метод Power Distribution Sampling представляет собой расширение стандартной авторегрессионной выборки, используемой в языковых моделях. В отличие от традиционного подхода, где вероятность следующего токена определяет выбор, Power Distribution Sampling интегрирует переформированное распределение вероятностей p_{\alpha}(x), учитывающее вероятность всей траектории рассуждений. Это достигается путем модификации процесса выборки, что позволяет модели отдавать предпочтение более вероятным путям решения задачи, основываясь не только на локальной вероятности каждого токена, но и на общей правдоподобности последовательности токенов, формирующих ход мысли. Фактически, Power Distribution Sampling изменяет способ, которым модель исследует пространство возможных последовательностей, направляя ее к более когерентным и логичным решениям.
Параметр масштабирования (Scaling Factor) играет ключевую роль в формировании распределения вероятностей, определяя степень его заострения. Более высокие значения параметра приводят к более выраженному акценту на наиболее вероятных траекториях рассуждений, сужая диапазон рассматриваемых вариантов и повышая вероятность выбора доминирующих путей. Напротив, меньшие значения параметра приводят к более сглаженному распределению, позволяя модели исследовать более широкий спектр возможных рассуждений, но потенциально снижая точность выбора оптимальной траектории. Фактически, данный параметр регулирует баланс между исследованием (exploration) и использованием (exploitation) в процессе генерации, оказывая существенное влияние на качество и согласованность выходных данных. Регулировка параметра масштабирования позволяет адаптировать модель к различным задачам и требованиям, оптимизируя ее производительность в конкретных сценариях.

Эффективная Выборка и Снижение Смещения: Путь к Достоверности
Для эффективной выборки из распределения вероятностей используется метод Марковских цепей Монте-Карло (MCMC). Этот метод позволяет исследовать преобразованное вероятностное пространство путем построения последовательности состояний, где каждое следующее состояние зависит только от предыдущего. MCMC особенно полезен в случаях, когда прямое вычисление вероятностей затруднено или невозможно, позволяя приблизительно оценивать сложные интегралы и генерировать выборки, отражающие целевое распределение. Суть метода заключается в создании цепи, стационарное распределение которой совпадает с распределением, из которого требуется выполнить выборку, обеспечивая тем самым возможность исследования пространства вероятностей даже при высокой размерности.
Метод ‘Block-Level Lookahead’ повышает эффективность выборки за счет одновременного рассмотрения нескольких токенов, а не отдельных. Вместо последовательной оценки вероятностей для каждого токена, данный подход анализирует блоки токенов как единое целое, что позволяет снизить вычислительные затраты и ускорить процесс генерации. Рассмотрение блоков уменьшает необходимость повторных вычислений для соседних токенов, поскольку их вероятности оцениваются совместно. Это особенно эффективно при работе с большими языковыми моделями и длинными последовательностями, где вычислительная сложность может значительно возрастать.
Для снижения систематической погрешности, возникающей при оценке распределения вероятностей, используется оценка Джексона (Jackknife Estimator). Данный метод предполагает последовательное исключение каждого элемента из выборки, переоценку распределения на основе оставшихся данных и вычисление смещения оценки. Суммирование этих смещений позволяет получить более точную и несмещенную оценку параметров распределения, что критически важно для обеспечения надежности и объективности результатов моделирования. Оценка Джексона особенно эффективна при работе с небольшими выборками или в случаях, когда данные подвержены выбросам.
Перевзвешивание на уровне траекторий (Trajectory-Level Reweighting) представляет собой метод уточнения процесса генерации текста, при котором оценивается и приоритизируется полная последовательность токенов, а не отдельные элементы. Этот подход позволяет учитывать взаимосвязи между токенами и оценивать общее качество и связность сгенерированной последовательности. Оценка проводится на основе заданных критериев когерентности и качества, что позволяет присвоить каждой траектории (последовательности токенов) вес, определяющий её вклад в конечный результат. Траектории с более высоким весом, демонстрирующие большую когерентность и качество, получают приоритет, что способствует генерации более связного и логичного текста.

Эмпирическая Валидация: Измерение Глубины Рассуждений
Предложенный подход демонстрирует значительный прогресс в решении сложных задач, требующих логического мышления, что подтверждается результатами тестирования на бенчмарке ‘MATH500’, предназначенном для оценки способностей к математическому решению проблем. Улучшения, достигнутые в рамках данного исследования, позволяют модели более эффективно справляться с задачами, требующими последовательного применения математических принципов и логических умозаключений. Это выражается в повышенной точности и надежности получаемых ответов, что свидетельствует о потенциале данного подхода для автоматизации сложных вычислительных процессов и поддержки принятия решений в различных областях науки и техники. Успешное прохождение тестов на ‘MATH500’ подчеркивает способность модели к обобщению знаний и применению их в новых, ранее не встречавшихся ситуациях.
Представленный подход продемонстрировал значительные успехи в решении математических задач, о чем свидетельствует достижение показателя Pass@1 в 0.492 на бенчмарке MATH500 при использовании модели Qwen2.5-Math-7B. Этот результат указывает на способность системы успешно решать почти половину задач из набора, требующих сложных математических рассуждений и вычислений. Достижение такого уровня производительности на MATH500 подчеркивает эффективность предложенного метода в области автоматизированного решения математических проблем и открывает перспективы для дальнейшего развития интеллектуальных систем, способных к глубокому логическому анализу и математическому моделированию.
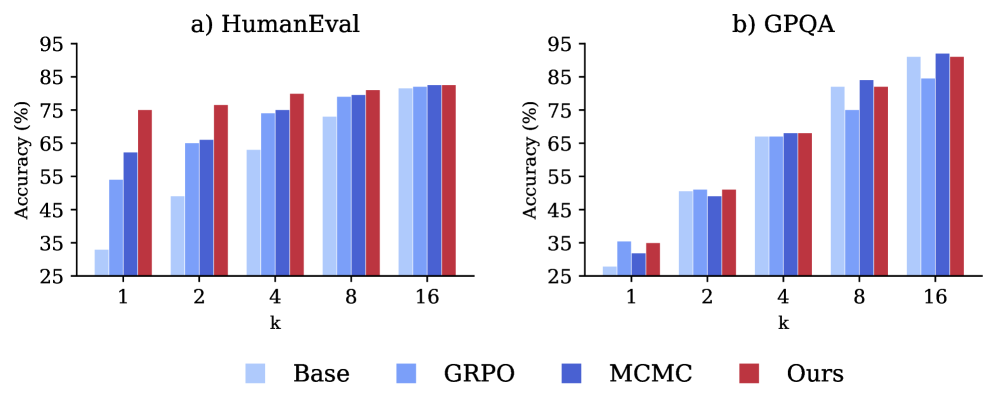
Исследования показали значительное улучшение результатов в задачах генерации кода, используя предложенный подход. На бенчмарке ‘HumanEval’, предназначенном для оценки способности моделей создавать функциональный код, достигнут показатель Pass@1 в 0.35. Это свидетельствует о повышенных возможностях логического мышления и программирования, позволяющих модели успешно решать сложные задачи кодирования и демонстрировать более высокую точность в генерации работоспособного программного обеспечения. Полученный результат подтверждает эффективность разработанного метода в контексте автоматизированного создания кода и представляет собой важный шаг к созданию интеллектуальных систем, способных самостоятельно решать задачи программирования.
В ходе тестирования разработанного подхода на бенчмарке ‘GPQA’, ориентированном на вопросы, требующие обширных знаний, достигнут показатель Pass@1 в 0.42. Это свидетельствует о значительном прогрессе в способности системы к логическому мышлению и эффективному использованию накопленных знаний для ответа на сложные вопросы. Бенчмарк ‘GPQA’ представляет собой сложную задачу для моделей искусственного интеллекта, требующую не просто распознавания закономерностей, но и глубокого понимания предметной области и способности к синтезу информации из различных источников. Достигнутый результат подтверждает эффективность предложенного метода в решении задач, связанных с поиском и применением знаний, и открывает перспективы для создания интеллектуальных систем, способных к более сложным и осмысленным взаимодействиям.
Предложенный подход демонстрирует значительное увеличение скорости получения результатов — до десятикратное, по сравнению с методами, основанными на выборке Монте-Карло (MCMC). Такое ускорение достигается за счет оптимизации процесса вычислений и отказа от ресурсоемких итеративных процедур, характерных для MCMC. Это позволяет существенно сократить время, необходимое для решения сложных задач, требующих логического вывода и анализа данных, открывая возможности для применения в реальном времени и обработки больших объемов информации. Ускорение вычислений не только повышает эффективность, но и снижает требования к вычислительным ресурсам, делая данный подход более доступным и практичным.

К Более Надежному и Понятному Искусственному Интеллекту: Пророчество о Растущей Системе
Вместо простого увеличения размеров моделей искусственного интеллекта, современные исследования сосредотачиваются на изменении формы вероятностных распределений, что открывает путь к созданию более эффективных и устойчивых систем. Такой подход позволяет не просто обрабатывать больше данных, но и оптимизировать сам процесс принятия решений моделью. Переосмысление вероятностных распределений дает возможность модели более четко фокусироваться на наиболее релевантных аспектах задачи, снижая чувствительность к шуму и повышая надежность прогнозов. В результате, достигается значительное повышение эффективности использования ресурсов и улучшение способности системы к обобщению, что особенно важно при работе со сложными и неоднозначными данными. Это направление исследований обещает фундаментальный сдвиг в развитии искусственного интеллекта, позволяющий создавать системы, которые не просто «больше», но и «умнее» в истинном смысле этого слова.
Метод “заострения распределения” позволяет добиться большей фокусировки и связности в процессе генерации, что существенно улучшает понимание и контроль над результатами работы искусственного интеллекта. Вместо простого увеличения размера модели, данный подход направлен на более точную настройку вероятностных распределений, определяющих выбор каждого следующего элемента генерируемого контента. Это приводит к созданию более логичных, последовательных и предсказуемых текстов, где каждое слово или фраза имеет четкую связь с предыдущими. В результате, становится проще отследить, почему модель пришла к определенному выводу, и, при необходимости, скорректировать ее поведение, что открывает возможности для создания более надежных и прозрачных систем искусственного интеллекта.
Исследования демонстрируют, что перенаправление усилий на формирование вероятностных распределений открывает новые горизонты для языковых моделей, позволяя им справляться с задачами, требующими сложного логического мышления. Вместо простого увеличения размеров модели, данный подход позволяет углубить понимание и анализ информации, что особенно важно при решении проблем, требующих не только знания фактов, но и способности к дедукции и абстракции. Это позволяет моделям не просто генерировать текст, а выстраивать последовательные и обоснованные аргументы, а также находить решения в условиях неопределенности и неполноты данных. В перспективе, такая способность к сложному мышлению может стать ключевым фактором в создании искусственного интеллекта, способного к самостоятельным открытиям и инновациям в различных областях знаний.
Предстоит расширение области применения разработанных методов за пределы обработки естественного языка. Исследователи планируют изучить возможности использования “заострения распределений” в процессах научных открытий, где необходимо выявлять закономерности в сложных данных и генерировать гипотезы. Не менее перспективным представляется применение этих техник в сфере креативного письма, где требуется контролируемое создание оригинального контента, сохраняющего логическую связность и стилистическую целостность. Ожидается, что подобный подход позволит создавать более правдоподобные и содержательные тексты, а также автоматизировать некоторые аспекты творческого процесса, открывая новые горизонты для взаимодействия человека и искусственного интеллекта.
Исследование демонстрирует, что для достижения сравнимой с обучением с подкреплением способности к рассуждениям, достаточно эффективной выборки распределения во время инференса. Подобный подход позволяет значительно снизить вычислительные затраты, избегая дорогостоящего этапа обучения. Как однажды заметил Тим Бернерс-Ли: «Данные — это не просто информация, а основа для построения взаимосвязанного мира». Эта фраза отражает суть представленной работы: оптимизация процесса получения знаний, а не наращивание объемов данных, является ключом к созданию эффективных и доступных систем искусственного интеллекта. Система, лишенная гибкости и адаптации к изменяющимся условиям, обречена на стагнацию, а предлагаемый метод выборки распределения обеспечивает необходимую динамичность.
Что дальше?
Представленная работа демонстрирует, что искусственное усиление рассуждений в больших языковых моделях возможно не только через обучение с подкреплением, но и через манипуляции с распределением вероятностей на этапе вывода. Однако, не стоит обольщаться иллюзией полного контроля. За каждым архитектурным выбором, за каждым алгоритмом “заострения” распределения скрывается пророчество о будущей точке отказа. В конечном итоге, сложность систем не уменьшается, она лишь перемещается из фазы обучения в фазу инференса.
Вместо бесконечной гонки за более «умными» моделями, возможно, стоит обратить внимание на природу самих задач. Если рассуждения модели хрупки и подвержены влиянию незначительных изменений в распределении, не является ли это признаком фундаментальной неясности в самих вопросах? Технологии сменяются, зависимости остаются — и эта зависимость от неявно заданных предположений о мире, вероятно, является наиболее сложной проблемой.
Будущие исследования, вероятно, будут сосредоточены на разработке методов, позволяющих оценивать и смягчать эту хрупкость. Или, что более вероятно, на создании систем, способных изящно справляться с неизбежной неопределенностью, не пытаясь её полностью устранить. Ведь системы — это не инструменты, а экосистемы. Их нельзя построить, только взрастить.
Оригинал статьи: https://arxiv.org/pdf/2601.21590.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Кванты в Финансах: Не Шутка!
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый оптимизатор: Новый подход к сложным задачам
- Оптимизация Комбинаторных Задач: Новый Взгляд с Помощью Автокодировщиков
- Волны спинов для нейроморфных вычислений: новый подход к скорости и эффективности
2026-01-31 05:25