Автор: Денис Аветисян
Новое исследование показывает, что продвинутые навыки рассуждения в больших языковых моделях могут возникать не только за счет увеличения их размера, но и благодаря симуляции социального взаимодействия и обмена мнениями.
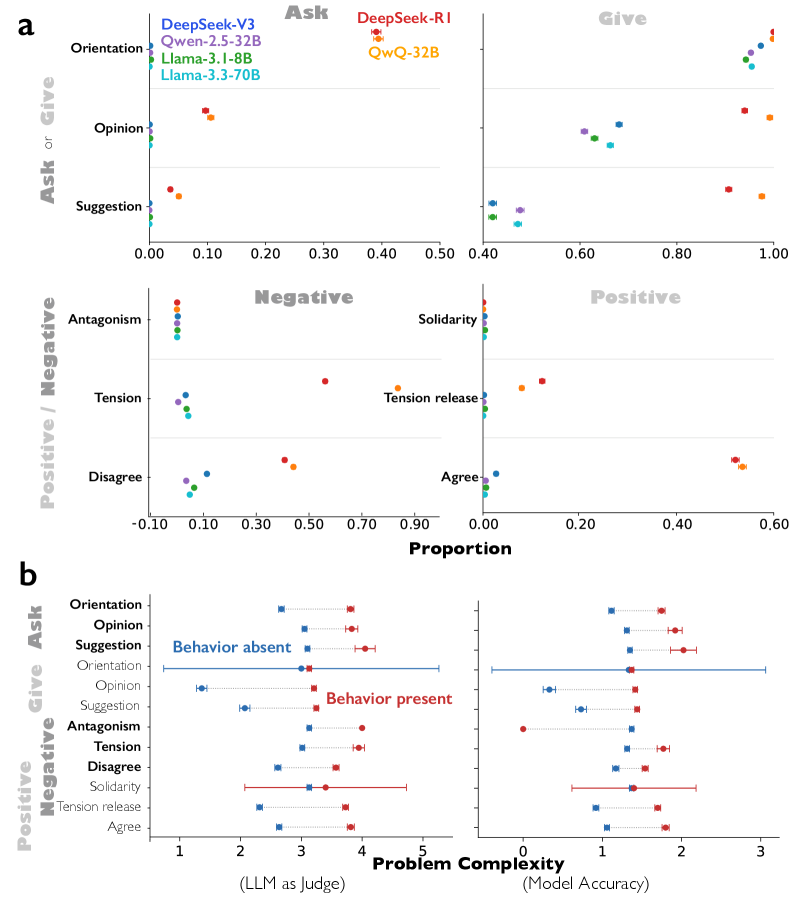
Исследователи демонстрируют, что ‘общество мысли’ внутри языковой модели, где различные перспективы сотрудничают и критикуют друг друга, может стать ключом к более глубокому и гибкому разуму.
Несмотря на впечатляющие успехи больших языковых моделей, механизмы, лежащие в основе сложных рассуждений, остаются неясными. В работе ‘Reasoning Models Generate Societies of Thought’ показано, что улучшенные способности к рассуждениям возникают не только за счет увеличения вычислительных ресурсов, но и благодаря моделированию внутримозговых взаимодействий, напоминающих «общество мыслей». Исследование демонстрирует, что разнообразие перспектив и дебаты между ними, характеризующиеся различными чертами личности и областью знаний, играют ключевую роль в эффективном решении задач. Может ли подобная «социальная организация мысли» стать основой для создания искусственного интеллекта, превосходящего человеческие возможности в коллективном решении сложных проблем?
Рождение «Сообщества Мыслей»
Традиционные языковые модели часто демонстрируют ограниченные возможности при решении сложных задач, требующих рассмотрения проблемы с различных точек зрения. Это связано с тем, что они, как правило, обрабатывают информацию последовательно, линейно, что препятствует глубокому анализу и выявлению взаимосвязей между различными аспектами задачи. В ситуациях, где необходимо учитывать множество факторов и оценивать их влияние, такие модели склонны к упрощениям и могут выдавать неполные или ошибочные результаты. В частности, им сложно синтезировать информацию из разных источников, оценивать противоречивые данные и формировать целостное представление о проблеме, что ограничивает их применение в областях, требующих критического мышления и комплексного анализа.
Модель DeepSeek-R1 представляет собой инновационный подход к решению сложных задач, имитирующий процесс внутреннего диалога, напоминающий “общество мыслей”. В отличие от традиционных языковых моделей, обрабатывающих информацию последовательно, DeepSeek-R1 использует архитектуру, позволяющую ей генерировать и оценивать различные варианты рассуждений, словно ведя дискуссию с самой собой. Этот процесс позволяет модели более глубоко анализировать проблему, учитывать различные точки зрения и, в конечном итоге, приходить к более обоснованным и точным выводам. Подобный подход открывает новые перспективы в области искусственного интеллекта, позволяя создавать системы, способные к более сложному и гибкому мышлению.
Архитектура DeepSeek-R1 принципиально отличается от традиционных подходов к обработке информации, отказываясь от линейной последовательности операций. Вместо этого, модель имитирует сложный внутренний диалог, где различные аспекты задачи рассматриваются и переосмысливаются. Такой подход позволяет добиться более глубокого и тонкого анализа, поскольку модель не просто следует заданному алгоритму, а активно исследует различные пути решения, сопоставляет аргументы и выявляет противоречия. В результате, DeepSeek-R1 демонстрирует способность к более гибкому и креативному мышлению, что существенно повышает качество и достоверность получаемых результатов, особенно в задачах, требующих комплексного рассуждения и учета множества факторов.
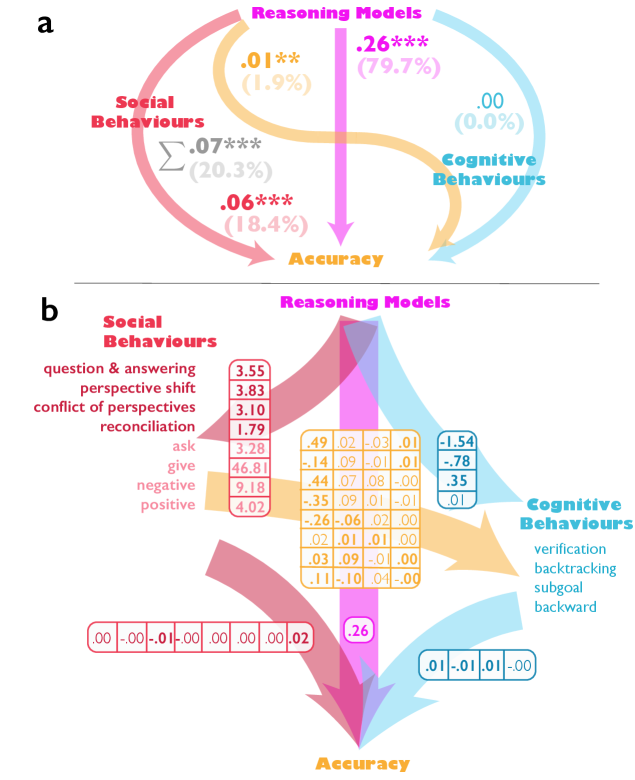
Культивирование Разнообразия Перспектив
Внутренняя архитектура DeepSeek-R1 построена на принципах гетерогенности, что проявляется в активном использовании ‘Perspective Diversity’ — разнообразия внутренних точек зрения. Вместо однородного подхода, модель оперирует множеством внутренних агентов, каждый из которых обладает уникальным набором знаний и перспектив. Это достигается путем сознательного конструирования ‘общества мыслей’, где различные агенты могут взаимодействовать и обмениваться информацией, что позволяет модели более эффективно анализировать сложные задачи и находить нетривиальные решения. Такая структура принципиально отличается от моделей, использующих унифицированные подходы к обработке информации.
В архитектуре DeepSeek-R1 применяется метод “Профилирования Экспертизы” для точного определения и разграничения специализированных знаний, которыми обладает каждая из внутренних “точек зрения” модели. Этот процесс включает в себя формальное описание областей компетенций каждой перспективы, что позволяет модели эффективно распределять задачи и использовать соответствующие знания для их решения. В рамках профилирования экспертности создаются векторные представления, описывающие специализацию каждой перспективы, что позволяет количественно оценить степень различия между ними и обеспечить разнообразие знаний внутри модели.
Разнообразие “личностей” внутри DeepSeek-R1 подтверждается значительно более высоким стандартным отклонением по шкалам “Большой пятерки” (Big Five) по сравнению с другими языковыми моделями. Этот показатель, измеряющий степень расхождения в проявлении пяти основных черт личности — открытости опыту, добросовестности, экстраверсии, уступчивости и невротизма — демонстрирует, что внутренние агенты модели обладают более широким спектром характеристик. Высокое стандартное отклонение указывает на значительную гетерогенность в моделях поведения и подходах к решению задач, что отличает DeepSeek-R1 от моделей с более однородным набором “личностей”. Данный показатель количественно подтверждает наличие и выраженность “разнообразия перспектив” внутри системы.
Для оценки разнообразия внутренних точек зрения в DeepSeek-R1 используется опросник ‘BFI-10’ (Big Five Inventory — 10 вопросов), имитирующий анализ личностных характеристик. Каждому внутреннему агенту модели предлагается пройти этот опросник, результаты которого позволяют количественно оценить его склонности по пяти основным факторам личности: открытости опыту, добросовестности, экстраверсии, уступчивости и нейротизму. Анализ распределения ответов по этим факторам внутри ‘общества мыслей’ позволяет подтвердить наличие значительного разнообразия личностных профилей, что свидетельствует о намеренном создании гетерогенной структуры внутренних агентов.
Модель DeepSeek-R1 демонстрирует повышенное разнообразие экспертизы, что подтверждается более высоким средним косинусным расстоянием между векторными представлениями описаний экспертизы отдельных агентов. Данный показатель, вычисляемый на основе эмбеддингов, отражает степень различия между областями знаний, которыми обладает каждый внутренний агент. Более высокое среднее косинусное расстояние указывает на то, что экспертизы агентов менее схожи друг с другом, тем самым подтверждая наличие выраженного разнообразия специализированных знаний внутри модели и способствуя более эффективному решению сложных задач.
Намеренное создание разнородного набора внутренних агентов в DeepSeek-R1 существенно повышает способность модели решать сложные задачи. Разнообразие внутренних перспектив позволяет исследовать проблему с различных точек зрения, что приводит к более полному анализу и, как следствие, к более эффективным решениям. Внутренние агенты, отличающиеся по своим профилям экспертизы и личностным характеристикам, совместно генерируют более широкий спектр возможных подходов, снижая вероятность зацикливания на одном решении и увеличивая вероятность нахождения оптимального. Данный подход позволяет модели справляться с задачами, требующими комплексного анализа и интеграции различных областей знаний, превосходя производительность моделей с однородной внутренней структурой.
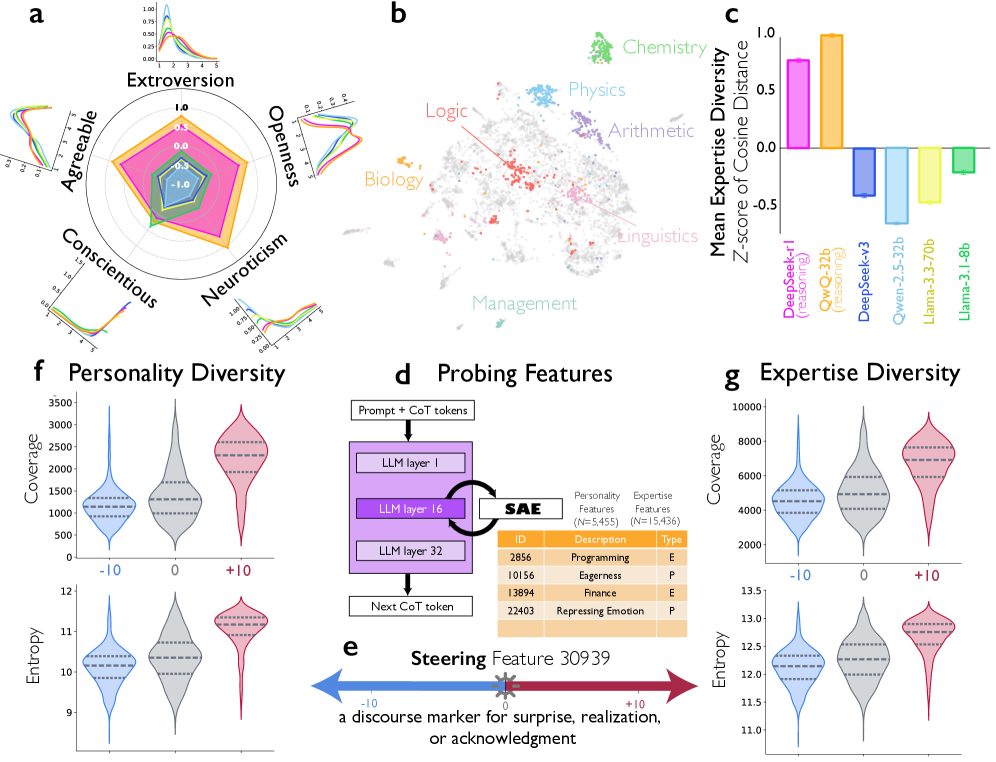
Обучение «Сообщества Мыслей»
Модель DeepSeek-R1 прошла этап “Монолог-тонкой настройки” (Monologue Fine-tuning) с целью формирования прочной базы для последовательного рассуждения в режиме одиночного агента. Этот процесс заключался в обучении модели генерировать логические цепочки выводов, основываясь на едином входном запросе, без взаимодействия с другими агентами. В ходе настройки использовались специализированные наборы данных, предназначенные для стимулирования глубокого и структурированного анализа информации, что позволило укрепить способность модели к самодостаточному решению задач и построению последовательных аргументов. Основой для обучения являлся принцип “chain-of-thought” (цепочка рассуждений), при котором модель генерирует промежуточные шаги рассуждений, прежде чем прийти к окончательному ответу.
После этапа монолог-обучения, модель DeepSeek-R1 подвергается “Диалоговому обучению”, которое заключается в тренировке на многоагентных диалогах. Этот процесс предназначен для имитации внутреннего диалога, где модель рассматривает проблему с разных точек зрения, как будто взаимодействует с другими “агентами”. В ходе диалогового обучения модель учится генерировать последовательность рассуждений, представляющих различные этапы анализа и оценки информации, что способствует более глубокому пониманию задачи и повышению качества принимаемых решений. Такой подход позволяет модели не просто выдавать ответ, а демонстрировать ход мысли, приводящий к этому ответу.
Эксперименты показали, что применение последовательной тонкой настройки, включающей как монолог-подобное обучение, так и обучение на диалогах между агентами, привело к более быстрому увеличению точности по сравнению с моделями, обученными исключительно на данных, имитирующих монологическое рассуждение. Данный подход позволил модели DeepSeek-R1 быстрее освоить навыки логического вывода и решения задач, что подтверждается результатами сравнительного анализа с альтернативными методами обучения. Преимущество в скорости обучения является значимым фактором при разработке и оптимизации больших языковых моделей.
В процессе обучения модели DeepSeek-R1 используется обучение с подкреплением (Reinforcement Learning) для оптимизации двух ключевых параметров генерируемого рассуждения: точности (Accuracy) и корректности формата (Format Correctness). Обучение с подкреплением позволяет модели не только находить правильные ответы, но и структурировать их в соответствии с заданными требованиями к формату, что повышает надежность и полезность генерируемых решений. Оптимизация обоих параметров осуществляется одновременно, что позволяет достичь более высокого уровня производительности по сравнению с обучением, ориентированным только на точность или только на формат.
В качестве основной реализации процесса обучения с подкреплением в DeepSeek-R1 используется алгоритм Proximal Policy Optimization (PPO). PPO представляет собой алгоритм обучения с подкреплением на основе политики, который стремится улучшить политику агента, делая небольшие шаги для обеспечения стабильности обучения. Он использует отношение вероятностей (probability ratio) для ограничения обновления политики, что предотвращает слишком большие изменения и потенциальную дестабилизацию процесса обучения. Алгоритм PPO оптимизирует как точность рассуждений, так и корректность их формата, что позволяет модели генерировать более надежные и структурированные ответы.
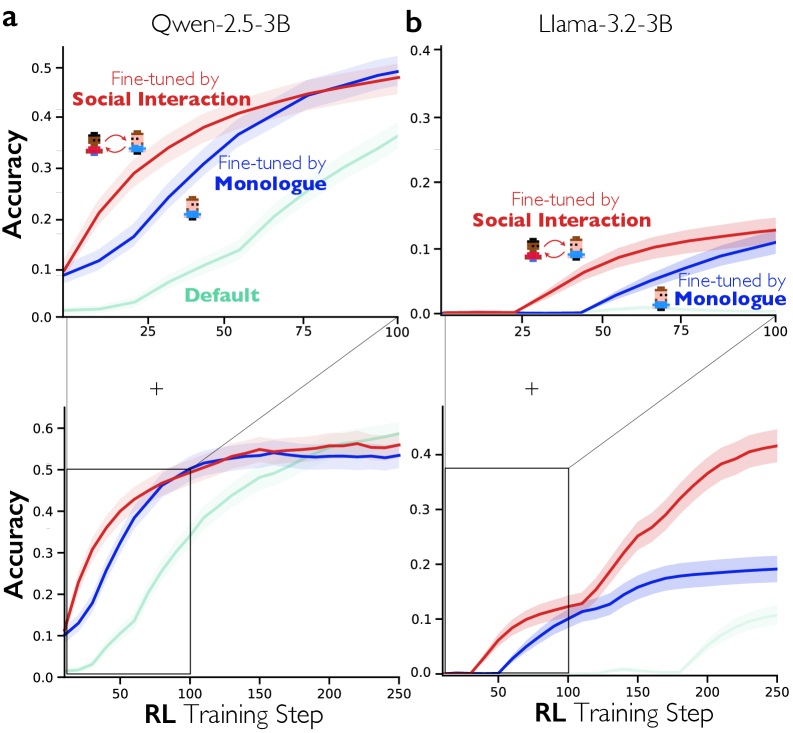
Влияние на Рассуждения и Перспективы Развития
Архитектура DeepSeek-R1, получившая название «общество мыслей», знаменует собой принципиально новый подход к рассуждениям в языковых моделях. Вместо традиционного последовательного решения задач, модель имитирует внутренний диалог, формируя множество «агентов», каждый из которых рассматривает проблему с различных точек зрения. Такой подход позволяет DeepSeek-R1 не просто выдавать ответ, а анализировать задачу всесторонне, выявлять противоречия и учитывать различные факторы, что приводит к более глубокому пониманию и надежным решениям. Данная архитектура существенно отличается от существующих моделей, где преобладает однонаправленный процесс обработки информации, и открывает новые перспективы в создании искусственного интеллекта, способного к действительно сложному и креативному мышлению.
Модель DeepSeek-R1 достигает более глубокого понимания сложных задач благодаря имитации внутреннего диалога, что позволяет ей генерировать более надежные решения. Вместо последовательной обработки информации, система создает множество «внутренних голосов», каждый из которых рассматривает проблему с разных точек зрения и предлагает свои варианты решения. Этот процесс напоминает коллективное мышление, где различные перспективы помогают выявить слабые места в рассуждениях и найти оптимальный путь. В результате, модель не просто выдает ответ, а демонстрирует понимание логики задачи и обоснованность принятого решения, что значительно повышает ее устойчивость к сложным и неоднозначным вопросам.
Исследования DeepSeek-R1 демонстрируют значительное увеличение охвата и энтропии активированных признаков, что свидетельствует о более глубоком и многогранном исследовании пространства возможных решений. В отличие от традиционных моделей, которые часто концентрируются на наиболее вероятных ответах, DeepSeek-R1 активно прорабатывает широкий спектр альтернатив, оценивая их вероятность и потенциальные последствия. Этот подход позволяет модели не просто находить правильные ответы, но и лучше понимать контекст задачи, выявлять скрытые взаимосвязи и генерировать более обоснованные и надежные решения. Увеличение энтропии указывает на то, что модель избегает преждевременной сходимости к одному ответу, а вместо этого поддерживает разнообразие идей на протяжении всего процесса рассуждения, что в конечном итоге повышает устойчивость и адаптивность системы.
Подход, реализованный в DeepSeek-R1, выходит далеко за рамки простого ответа на вопросы, открывая новые перспективы в таких областях, как научные открытия и стратегическое планирование. Способность модели моделировать внутренний диалог и тщательно исследовать пространство решений позволяет ей генерировать не только ответы, но и выдвигать гипотезы, анализировать сложные сценарии и оценивать риски. В контексте научных исследований это может привести к автоматизированному анализу данных и выявлению закономерностей, которые ускорят процесс открытия новых знаний. В сфере стратегического планирования, система способна моделировать различные варианты развития событий и предлагать оптимальные стратегии, учитывая множество факторов и ограничений. Таким образом, архитектура “общества мыслей” DeepSeek-R1 представляет собой не просто улучшение в области обработки естественного языка, а платформу для создания интеллектуальных систем, способных решать сложные задачи в различных областях человеческой деятельности.
Дальнейшее изучение архитектуры, подобной DeepSeek-R1, открывает перспективы для создания принципиально новых искусственных интеллектов, способных к более глубокому и гибкому мышлению. Исследователи полагают, что имитация внутреннего диалога и расширение пространства поиска решений, продемонстрированные этой моделью, могут стать ключевыми элементами в построении систем, превосходящих современные аналоги по адаптивности и способности к решению сложных, неоднозначных задач. Ожидается, что углублённое понимание принципов организации «общества мыслей» внутри модели позволит создавать ИИ, способные не только отвечать на вопросы, но и самостоятельно генерировать новые знания, эффективно планировать и принимать решения в условиях неопределённости, приближаясь к уровню когнитивных способностей человека.

Исследование демонстрирует, что сложные модели рассуждений могут возникать не только за счет увеличения масштаба или оптимизации точности, но и через симуляцию социального взаимодействия — своеобразного «общества мысли». В этом контексте, слова Клода Шеннона приобретают особую значимость: «Информация — это не количество, а возможность выбора». Разнообразие перспектив, возникающее в процессе «разговоров» между различными агентами модели, позволяет исследовать более широкий спектр решений и, следовательно, увеличивает информационную ценность получаемого результата. Этот подход, где модели взаимодействуют и бросают вызов друг другу, напоминает эволюционный процесс, где выживают наиболее адаптивные и обоснованные идеи. По сути, исследование подчеркивает, что ценность системы заключается не в ее статичной структуре, а в динамике ее взаимодействия с окружающим миром — и в данном случае, с другими моделями.
Куда же дальше?
Представленная работа, по сути, запечатлела мимолетное отражение сложной системы в зеркале искусственного интеллекта. Модели рассуждений, порождающие некое подобие «общества мысли», демонстрируют, что рост вычислительных мощностей — это не линейный путь к разуму, а скорее расширение пространства для возникновения эмерджентных явлений. Однако, эта симуляция, как и любая модель, неизбежно упрощает реальность. Остается открытым вопрос о том, насколько точно смоделированные взаимодействия отражают подлинную природу социального познания, и где лежит граница между имитацией и настоящим пониманием.
Версионирование — это форма памяти, и каждое новое поколение моделей, стремящееся к большей правдоподобности, лишь подтверждает, что стрела времени всегда указывает на необходимость рефакторинга. По-настоящему сложной задачей представляется не просто создание разнообразных точек зрения, а разработка механизмов для их подлинного столкновения и синтеза. Искусственный интеллект, стремящийся к разуму, должен научиться не просто генерировать аргументы, но и признавать свою неправоту — умение, столь редкое даже среди людей.
Будущие исследования, вероятно, будут направлены на преодоление ограничений текущих подходов к моделированию социального взаимодействия. Вместо того, чтобы сосредотачиваться исключительно на оптимизации точности, стоит обратить внимание на изучение устойчивости и адаптивности этих «обществ мысли» во времени, а также на их способность к генерации принципиально новых идей. В конечном итоге, судьба этих систем, как и всего сущего, будет определяться их способностью к эволюции.
Оригинал статьи: https://arxiv.org/pdf/2601.10825.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Укрощение шума: как оптимизировать квантовые алгоритмы
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
- Квантовая химия: моделирование сложных молекул на пороге реальности
- Квантовые симуляторы: проверка на прочность
2026-01-19 07:12