Автор: Денис Аветисян
Статья представляет концепцию децентрализованного обучения, перенося интеллект непосредственно на оконечные устройства и открывая путь к адаптивным и совместным системам искусственного интеллекта.
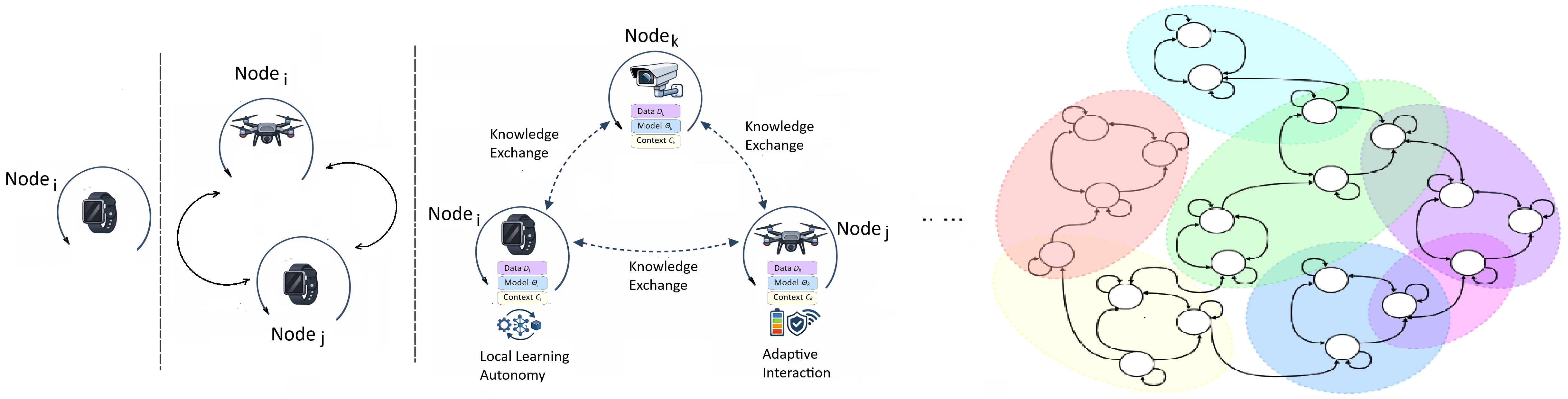
Предлагается фреймворк Node Learning для децентрализованного, адаптивного и совместного обучения на границе сети, учитывающий ограниченность ресурсов и контекстную осведомленность.
Централизованные подходы к искусственному интеллекту все чаще сталкиваются с ограничениями в условиях растущей гетерогенности и ограниченности ресурсов периферийных устройств. В данной работе представлена концепция ‘Node Learning: A Framework for Adaptive, Decentralised and Collaborative Network Edge AI‘, предлагающая парадигму децентрализованного обучения, при которой интеллект распределяется между отдельными узлами сети, способными к непрерывному обучению и оппортунистическому обмену знаниями. Этот подход позволяет преодолеть узкие места, связанные с передачей данных и зависимостью от централизованной инфраструктуры, объединяя автономность и кооперацию в единой архитектуре. Каковы перспективы масштабирования и применения Node Learning в реальных сценариях, требующих адаптивности, надежности и конфиденциальности?
Отход от Централизации: Рождение Нодовых Обучающих Сетей
Традиционные подходы к машинному обучению часто предполагают сбор и обработку данных в централизованных системах, что создает серьезные узкие места и вызывает обоснованные опасения по поводу конфиденциальности. Этот метод требует передачи больших объемов информации на центральный сервер, что не только замедляет процесс обучения, но и делает данные уязвимыми для несанкционированного доступа и злоупотреблений. Кроме того, централизованная обработка данных требует значительных вычислительных ресурсов и энергии, что делает ее неэффективной и дорогостоящей, особенно в контексте быстрорастущего объема генерируемых данных. Необходимость передачи данных также создает задержки, критичные для приложений, требующих мгновенного реагирования, таких как автономные системы и Интернет вещей. Поэтому, существующая модель ставит под вопрос масштабируемость и безопасность современных систем машинного обучения.
Переход к распределённому интеллекту становится всё более необходимым для реализации потенциала повсеместных вычислений и граничных устройств. Традиционные модели, требующие централизованной обработки данных, создают узкие места и проблемы с конфиденциальностью, ограничивая возможности адаптации к динамически меняющимся условиям. Распределённый подход позволяет перенести вычислительные мощности непосредственно к источнику данных, будь то датчик, мобильное устройство или промышленный контроллер. Это значительно снижает задержки, повышает надежность и масштабируемость систем, а также открывает новые возможности для автономной работы и обработки данных в реальном времени. В результате, развитие технологий, основанных на распределённом интеллекте, является ключевым фактором для дальнейшего прогресса в области Интернета вещей, автономных транспортных средств и интеллектуальных производственных систем.
Предлагаемый подход, известный как «Обучение на узлах», представляет собой принципиальный сдвиг в парадигме машинного обучения. Вместо концентрации интеллекта в централизованных системах, он предполагает размещение вычислительных мощностей и адаптивных алгоритмов непосредственно на отдельных узлах сети — будь то датчики, мобильные устройства или периферийные серверы. Каждый узел самостоятельно анализирует локальные данные и принимает решения, при этом, при необходимости, взаимодействуя с другими узлами для решения более сложных задач. Такая децентрализованная архитектура не только снижает зависимость от центральной инфраструктуры и повышает устойчивость системы к отказам, но и значительно улучшает эффективность использования ресурсов, позволяя обрабатывать данные ближе к источнику и минимизировать задержки. В результате, появляется возможность реализовать более гибкие, масштабируемые и энергоэффективные системы искусственного интеллекта, способные адаптироваться к постоянно меняющимся условиям окружающей среды.
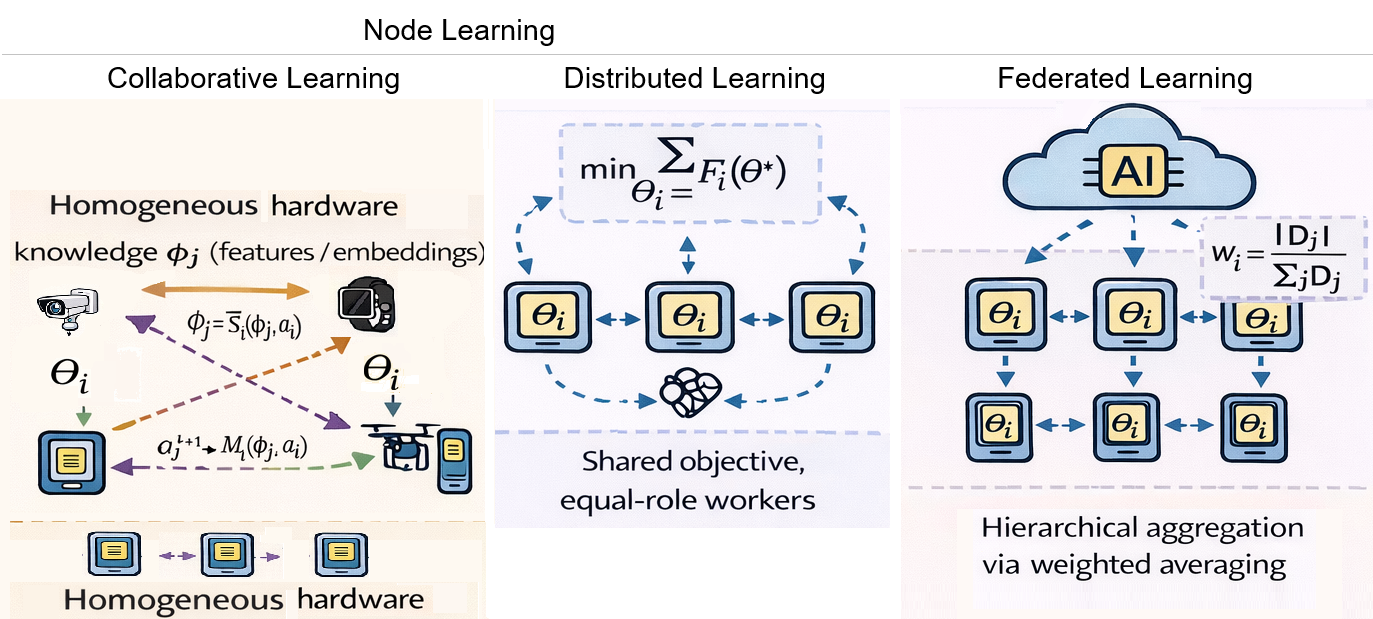
Децентрализованное Обучение: Методы и Механизмы
Федеративное обучение (Federated Learning) представляет собой подход к машинному обучению, позволяющий обучать модели на децентрализованных данных, хранящихся на различных устройствах или серверах. В отличие от традиционных централизованных методов, где данные собираются в одном месте, федеративное обучение сохраняет данные локально. Однако, несмотря на распределенный характер данных, процесс обучения все еще требует наличия центрального сервера для координации. Этот сервер отвечает за агрегацию обновлений моделей, полученных от отдельных участников, и распределение обновленной глобальной модели обратно участникам. Таким образом, хотя федеративное обучение снижает потребность в передаче сырых данных, оно сохраняет зависимость от центрального узла, что может стать точкой отказа или узким местом в масштабируемых системах.
Децентрализованное обучение и обучение на основе протокола «слухи» (Gossip-based Learning) устраняют зависимость от центрального сервера, характерную для федеративного обучения. Вместо этого, знания и обновления моделей распространяются непосредственно между участниками сети (peer-to-peer). В процессе обучения каждый участник обменивается информацией с небольшим, случайно выбранным подмножеством других участников. Этот процесс повторяется итеративно, позволяя модели агрегировать знания, распределенные по всей сети, без необходимости в централизованном координаторе. Механизм «слухов» обеспечивает устойчивость к отказам отдельных узлов и масштабируемость системы, поскольку каждый участник оперирует только локальной информацией и взаимодействует лишь с небольшим количеством соседей. Такой подход позволяет строить более отказоустойчивые и конфиденциальные системы машинного обучения.
Децентрализованный стохастический градиентный спуск (Decentralized Stochastic Gradient Descent, DSGD) представляет собой базовый метод машинного обучения, позволяющий осуществлять обучение модели без использования центрального сервера или координатора. В DSGD каждый узел сети (например, устройство или агент) вычисляет градиент функции потерь на основе локальных данных и обменивается им с соседними узлами. Затем каждый узел агрегирует полученные градиенты, формируя усредненное значение, которое используется для обновления локальной копии модели. Этот процесс повторяется итеративно, позволяя модели сходиться к оптимальным параметрам за счет коллективного обучения, распределенного между узлами сети. В отличие от централизованного стохастического градиентного спуска, DSGD устраняет единую точку отказа и повышает устойчивость системы к сбоям, а также обеспечивает возможность обучения на больших и распределенных наборах данных без необходимости централизованного хранения и обработки.
Методы Tiny Federated Learning (TFL) направлены на адаптацию алгоритмов федеративного обучения для устройств с ограниченными ресурсами, таких как датчики и мобильные устройства. Основная цель TFL — перенос процесса обучения на периферию сети (edge learning), что позволяет снизить задержки и повысить конфиденциальность данных. Ключевым показателем эффективности TFL является снижение энергопотребления на итерацию (Energy per Iteration, EPI) по сравнению с традиционными централизованными подходами. Достигается это за счет оптимизации моделей, уменьшения объема передаваемых данных и использования алгоритмов, требующих меньших вычислительных ресурсов, что особенно важно для работы от батарей.
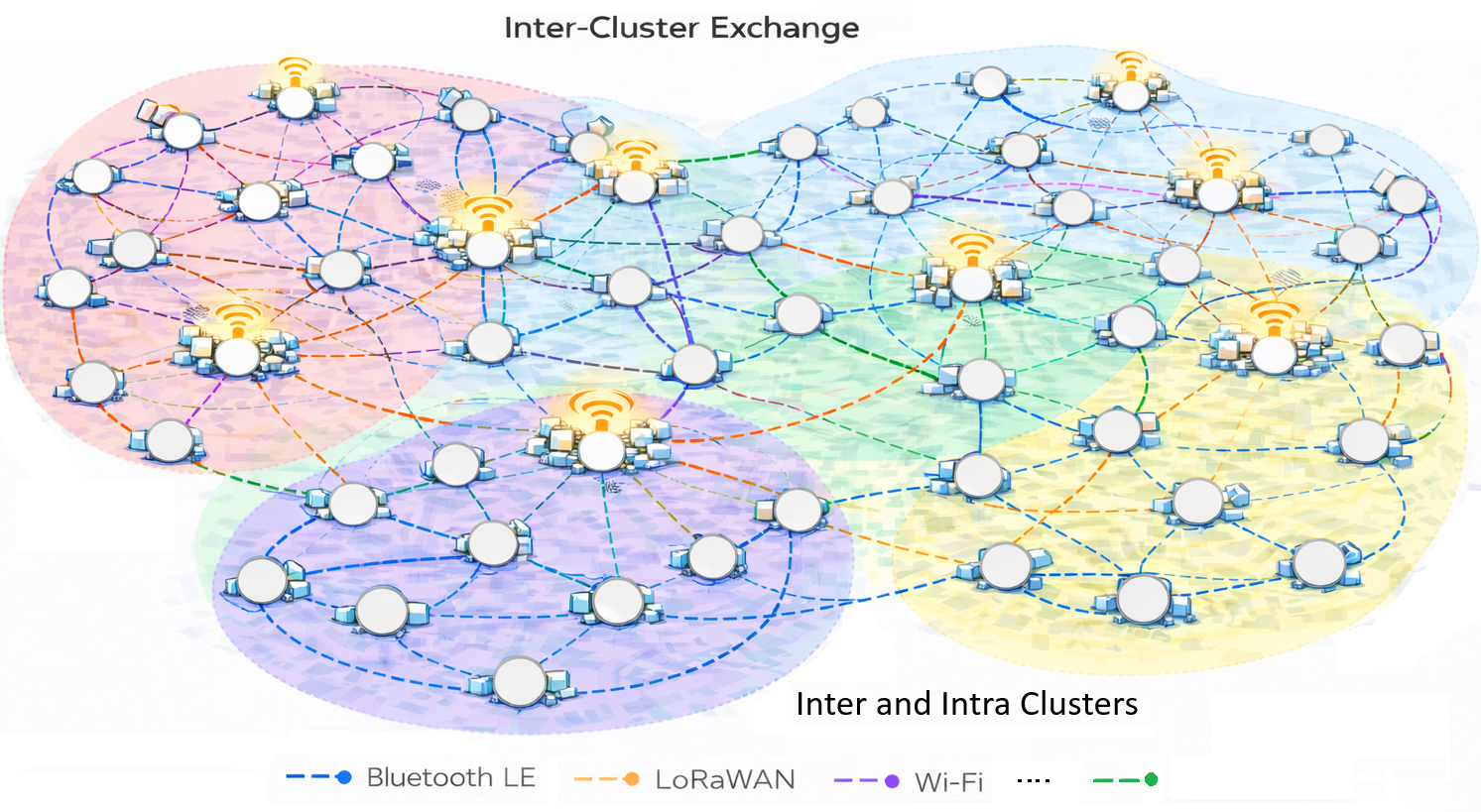
Усиление Узлов: Локальные Рассуждения и Адаптация
Языковые модели, развернутые непосредственно на каждом узле сети (Node Language Models), обеспечивают локальную семантическую интерпретацию и логический вывод без необходимости передачи данных на централизованный сервер. Это позволяет каждому узлу самостоятельно понимать смысл получаемой информации и выполнять базовые рассуждения, что существенно снижает задержки и повышает общую производительность системы. Локальная обработка данных позволяет узлам адаптироваться к специфическим контекстам и извлекать релевантную информацию из входных данных, используя встроенные знания и возможности логического вывода. Такой подход позволяет эффективно обрабатывать данные, даже при ограниченной пропускной способности сети или в условиях нестабильного соединения.
Контекстная адаптация позволяет узлам корректировать процесс обучения на основе локальных условий и факторов окружающей среды. Этот механизм направлен на минимизацию задержки адаптации (Adaptation Latency — AL), определяемой как время, необходимое узлу для изменения своей модели поведения в ответ на изменения в локальной среде. Реализация контекстной адаптации включает в себя мониторинг ключевых параметров окружающей среды, таких как частота запросов, тип данных, вычислительные ресурсы и сетевая пропускная способность. На основе этих данных узел динамически регулирует параметры обучения, включая скорость обучения, размер пакета и архитектуру модели, для оптимизации производительности и снижения AL. Эффективная контекстная адаптация критически важна для обеспечения стабильной и надежной работы узлов в динамически меняющихся условиях.
Возможность выборочного взаимодействия между узлами, известная как Opportunistic Collaboration, позволяет максимизировать эффективность и надежность системы. В рамках этого подхода узлы не обмениваются данными постоянно, а лишь при наличии взаимной выгоды и необходимости в повышении точности. Эффективность совместной работы (Collaboration Efficiency, CE) измеряется как повышение точности при одновременном снижении объема передаваемых байт данных. Это достигается за счет интеллектуального отбора информации для обмена и применения алгоритмов сжатия данных, что позволяет минимизировать задержки и потребление ресурсов сети. Выборочное взаимодействие способствует повышению устойчивости системы к отказам отдельных узлов, поскольку информация может быть получена из нескольких источников.
Локальные адаптации, обеспечиваемые Node Language Models, позволяют реализовать Edge AI — обработку данных непосредственно на устройствах, близких к источнику их генерации. Такой подход значительно снижает задержки (latency) по сравнению с традиционной облачной обработкой, поскольку исключает необходимость передачи больших объемов данных по сети. Это критически важно для приложений, требующих оперативного реагирования, таких как автономные системы, промышленная автоматизация и анализ данных в реальном времени. Обработка на периферии также снижает нагрузку на сеть и повышает конфиденциальность данных, поскольку чувствительная информация не покидает локальное устройство.
Архитектура Будущего: Аппаратное и Системное Обеспечение
Вычислительные системы, работающие с данными непосредственно в памяти, представляют собой перспективное направление для снижения энергопотребления и повышения производительности, особенно в устройствах с ограниченными ресурсами. Традиционные архитектуры требуют постоянного перемещения данных между процессором и памятью, что является узким местом и потребляет значительную энергию. В отличие от них, вычисления в памяти позволяют выполнять операции непосредственно над данными, хранящимися в ячейках памяти, минимизируя необходимость в перемещении данных. Это достигается за счет интеграции вычислительных элементов непосредственно в структуру памяти, что позволяет значительно сократить задержки и энергозатраты, открывая новые возможности для создания энергоэффективных и компактных систем, пригодных для применения в мобильных устройствах, носимой электронике и других ресурсоограниченных приложениях.
Нейроморфные вычисления, вдохновленные принципами работы человеческого мозга, представляют собой перспективный подход к созданию энергоэффективных и устойчивых систем обучения. В отличие от традиционных компьютеров, использующих разделенные блоки для обработки и памяти, нейроморфные системы имитируют параллельную обработку информации, характерную для биологических нейронных сетей. Это достигается за счет использования искусственных нейронов и синапсов, позволяющих осуществлять вычисления непосредственно в памяти, значительно снижая энергопотребление и задержки. Такой подход особенно актуален для задач, требующих обработки больших объемов данных в условиях ограниченных ресурсов, например, в мобильных устройствах или сенсорных сетях. Кроме того, архитектура нейроморфных систем обеспечивает повышенную устойчивость к ошибкам и шумам, что делает их надежными в сложных и непредсказуемых условиях эксплуатации.
Процессоры нейронных сетей (NPU) на базе архитектуры RISC-V представляют собой перспективное решение для задач искусственного интеллекта, предлагая возможность программной настройки и оптимизации вычислений. В отличие от специализированных аппаратных решений, NPU на RISC-V позволяют разработчикам адаптировать архитектуру под конкретные потребности приложения, что особенно важно для устройств с ограниченными ресурсами. Такая гибкость позволяет добиться значительного повышения энергоэффективности и производительности при обработке нейронных сетей, а открытый стандарт RISC-V способствует развитию инноваций и снижению стоимости разработки. Возможность программирования позволяет оптимизировать операции для конкретных моделей и задач, что обеспечивает более эффективное использование вычислительных ресурсов и позволяет развертывать сложные алгоритмы машинного обучения на различных платформах, от мобильных устройств до серверов.
Коллективное обучение представляет собой перспективный подход к повышению общей интеллектуальности системы, основанный на избирательном взаимодействии между отдельными узлами. Вместо обработки информации каждым узлом независимо, система активно определяет, с какими узлами следует обмениваться данными, что позволяет значительно снизить вычислительную нагрузку и энергопотребление. Этот процесс не только оптимизирует производительность, но и существенно повышает коэффициент устойчивости RR (Resilience Ratio) системы. В случае выхода из строя отдельных узлов или потери связи, система продолжает функционировать, используя информацию, полученную от других узлов, что делает её более надежной и отказоустойчивой. Такой подход к обучению позволяет создавать интеллектуальные системы, способные адаптироваться к изменяющимся условиям и сохранять работоспособность даже при частичной потере функциональности.
Представленная работа демонстрирует стремление к элегантности в организации распределенных вычислений на периферии сети. Концепция Node Learning, с ее акцентом на непрерывное обучение и оппортунистическое сотрудничество, находит отклик в математической строгости, необходимой для построения надежных систем. Как однажды заметил Г.Х. Харди: «Математика — это наука о том, что можно доказать». В данном контексте, возможность доказать корректность и предсказуемость поведения каждого узла в сети, особенно в условиях ограниченных ресурсов, является ключевым аспектом, определяющим устойчивость и эффективность всей системы. Авторы подчеркивают важность контекстной осведомленности, что напрямую связано с необходимостью точного и формального описания условий, в которых функционирует каждый узел, что, в свою очередь, требует математической точности.
Куда Ведет Этот Путь?
Представленная работа, касающаяся концепции «Node Learning», закономерно ставит вопрос о пределах применимости и неизбежных компромиссах. Несмотря на элегантность идеи распределенного обучения на периферии сети, доказательство ее устойчивости к непредсказуемым изменениям в топологии сети и гетерогенности ресурсов остается открытой проблемой. Слишком часто алгоритмы демонстрируют работоспособность на тщательно подобранных данных, но терпят неудачу при столкновении с реальной неопределенностью. Доказательство корректности, а не просто демонстрация эффективности, должно стать краеугольным камнем дальнейших исследований.
Особое внимание следует уделить вопросам верификации и валидации моделей, обученных в децентрализованной среде. Как гарантировать, что знания, усвоенные отдельными узлами, согласованы и не приводят к противоречивым выводам? Иными словами, как обеспечить когерентность коллективного разума, состоящего из множества несовершенных индивидуумов? Решение этой задачи требует не только разработки новых алгоритмов, но и переосмысления фундаментальных принципов теории обучения.
Необходимо признать, что концепция «Node Learning» не является панацеей. В определенных сценариях централизованные подходы, несмотря на свою ресурсоемкость, могут оказаться более эффективными и надежными. Поэтому, вместо слепого следования за модой на децентрализацию, следует руководствоваться принципом математической чистоты: любое решение должно быть обосновано строгими доказательствами, а не просто эмпирическими наблюдениями.
Оригинал статьи: https://arxiv.org/pdf/2602.16814.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Реальность и Кванты: Где Встречаются Теория и Эксперимент
- Сердце музыки: открытые модели для создания композиций
- Квантовый скачок: от лаборатории к рынку
- Виртуальная примерка без границ: EVTAR учится у образов
2026-02-23 02:01