Автор: Денис Аветисян
Новая работа представляет метод дистилляции знаний, позволяющий перенести сложные навыки рассуждения многоагентных систем в единую нейросетевую модель.
Представлен фреймворк AgentArk для дистилляции коллективного интеллекта многоагентных систем в единого LLM-агента с использованием модели вознаграждения за процесс.
Несмотря на впечатляющую способность многоагентных систем к сложному рассуждению, их практическое применение сдерживается высокой вычислительной стоимостью и риском накопления ошибок. В данной работе представлена система ‘AgentArk: Distilling Multi-Agent Intelligence into a Single LLM Agent’, новый подход к дистилляции динамики многоагентных систем в веса единой модели, эффективно преобразуя явные взаимодействия во время тестирования в неявные возможности модели. Это позволяет единому агенту обладать интеллектом многоагентной системы, сохраняя при этом вычислительную эффективность. Каким образом предложенный метод дистилляции может способствовать развитию более эффективных и надежных многоагентных систем для решения широкого спектра задач?
Пределы масштаба: Рассуждения в больших языковых моделях
Несмотря на впечатляющие достижения в генерации текста и переводе, большие языковые модели (БЯМ) часто сталкиваются с трудностями при решении задач, требующих сложного логического мышления, особенно если это предполагает последовательность нескольких шагов. Исследования показывают, что БЯМ могут успешно выполнять простые умозаключения, однако при увеличении числа необходимых логических операций точность значительно снижается. Эта проблема обусловлена тем, что модели, обученные на огромных объемах текстовых данных, зачастую выявляют статистические закономерности, а не истинное понимание причинно-следственных связей. В результате, даже незначительные ошибки на одном из этапов многоступенчатого умозаключения могут привести к неверному конечному результату, демонстрируя ограниченность текущих подходов к созданию искусственного интеллекта, способного к глубокому и надежному мышлению.
Несмотря на впечатляющие успехи больших языковых моделей, простое увеличение их размера не всегда приводит к улучшению способности к рассуждениям. Исследования показывают, что после определенного порога, дальнейшее наращивание параметров модели приносит всё меньше выгоды в решении сложных задач, требующих многоступенчатых логических выводов. Более того, увеличение масштаба влечет за собой экспоненциальный рост вычислительных затрат и энергопотребления, что делает использование таких моделей непрактичным и дорогостоящим. Таким образом, акцент смещается с простого увеличения размера в сторону разработки более эффективных архитектур и алгоритмов, способных обеспечить качественное рассуждение при разумных вычислительных ресурсах.
Современные большие языковые модели, несмотря на впечатляющие способности к генерации текста, подвержены проявлению систематических ошибок и галлюцинаций, что существенно снижает надежность цепочек рассуждений. Данные модели могут необоснованно выдавать ложную информацию, представляя её как факт, или демонстрировать предвзятость, основанную на данных, использованных при обучении. Это происходит из-за того, что модели учатся выявлять статистические закономерности в данных, а не понимать истинную суть вещей, что приводит к нелогичным или неверным выводам, особенно в сложных задачах, требующих критического мышления и проверки фактов. Вследствие этого, полагаться исключительно на рассуждения, сформированные такими моделями, без дополнительной проверки и анализа, представляется рискованным.
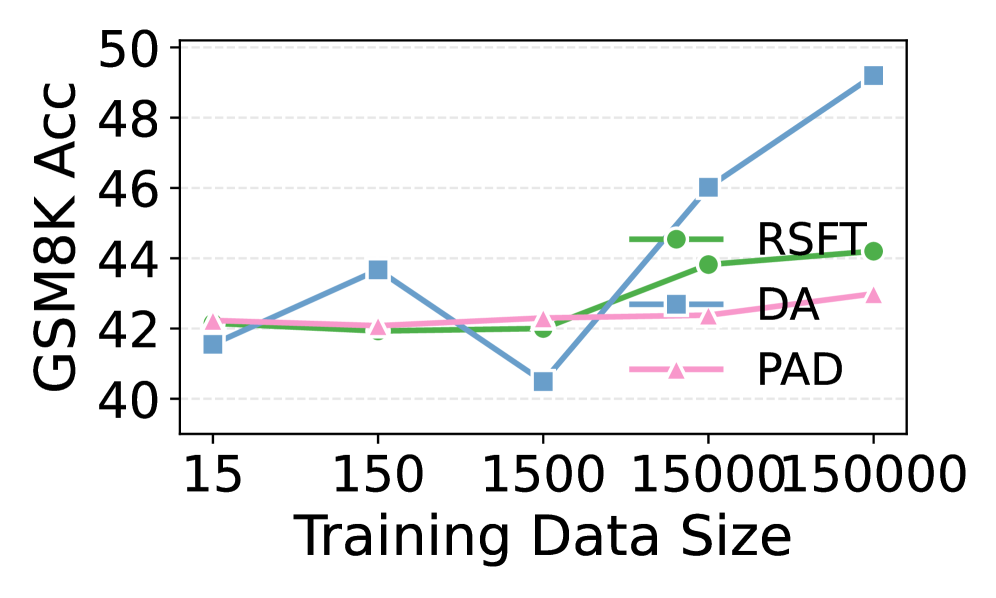
AgentArk: Дистилляция многоагентного рассуждения
AgentArk представляет собой новый фреймворк дистилляции, предназначенный для переноса динамики многоагентного рассуждения в единую, эффективную модель. В ходе тестирования, применение AgentArk позволило добиться прироста производительности до 4.8% в различных задачах, требующих рассуждений. Данный подход позволяет объединить сильные стороны нескольких агентов в одной модели, снижая вычислительные затраты и повышая общую эффективность решения задач, требующих сложного анализа и логических выводов.
В основе AgentArk лежит симуляция многоагентного взаимодействия, включающая этапы дебатов, критики и достижения консенсуса. Данный подход позволяет генерировать разнообразные траектории рассуждений, поскольку каждый агент в процессе симуляции вносит свой вклад, оспаривая или подтверждая отдельные шаги логических цепочек. Использование нескольких агентов позволяет исследовать различные варианты решения задачи и повышает устойчивость к ошибкам, поскольку противоречивые мнения выявляются и разрешаются в процессе взаимодействия. В результате формируется более надежный и обоснованный процесс рассуждения, чем при использовании одноагентного подхода.
В основе AgentArk лежит создание расширенного набора данных для обучения дистиллированной модели посредством методов увеличения данных (Data Augmentation) и ProcessAwareDistillation. Data Augmentation позволяет генерировать дополнительные примеры путем модификации существующих данных, увеличивая разнообразие обучающей выборки. ProcessAwareDistillation, в свою очередь, фокусируется на сохранении не только финального результата рассуждений, но и процесса их получения, что позволяет дистиллированной модели воспроизводить логику многоагентного взаимодействия. Комбинация этих методов обеспечивает формирование более качественного и репрезентативного набора данных, способствующего повышению эффективности и обобщающей способности итоговой модели.
Интернализация критики: Дистилляция, ориентированная на процесс
Метод ProcessAwareDistillation использует Модель Награды за Процесс (Process Reward Model) для стимулирования дистиллированной модели к усвоению динамики критики и пересмотра, наблюдаемой в многоагентной системе. Данная модель награды оценивает не только конечное решение, но и промежуточные шаги рассуждений, поощряя дистиллированную модель имитировать процесс самокоррекции, характерный для более сложных систем. Это позволяет дистиллированной модели улучшать свои рассуждения на основе внутренней оценки качества процесса, а не только на основе внешней оценки правильности ответа. Такой подход позволяет перенести навыки рассуждений из сложной многоагентной системы в более компактную и эффективную модель.
Групповая относительная оптимизация политики (GroupRelativePolicyOptimization) усовершенствует процесс дистилляции, фокусируясь на обучении дистиллированной модели эффективно реагировать на обратную связь. В отличие от стандартной дистилляции, которая часто стремится к имитации абсолютного поведения учителя, данный метод оптимизирует политику дистиллированной модели относительно других агентов в системе. Это достигается путем определения относительных преимуществ действий, а не абсолютных значений вознаграждения, что позволяет дистиллированной модели лучше адаптироваться к динамике обратной связи и улучшить свою производительность в условиях многоагентного взаимодействия. Такой подход позволяет более эффективно передавать навыки реагирования на критику от учителя к дистиллированной модели.
Метод выбора траекторий с приоритетом корректности (CorrectnessFirstTrajectorySelection) направлен на повышение общей производительности модели и снижение вероятности возникновения галлюцинаций за счет приоритизации путей рассуждений, приводящих к точным решениям. Данный подход предполагает оценку и выбор траекторий, в которых промежуточные и конечные результаты соответствуют истинным значениям. Наиболее значительные улучшения, полученные при использовании данного метода, наблюдаются на наборе данных MetaMathQA, что указывает на его эффективность в задачах, требующих точного математического рассуждения и решения.
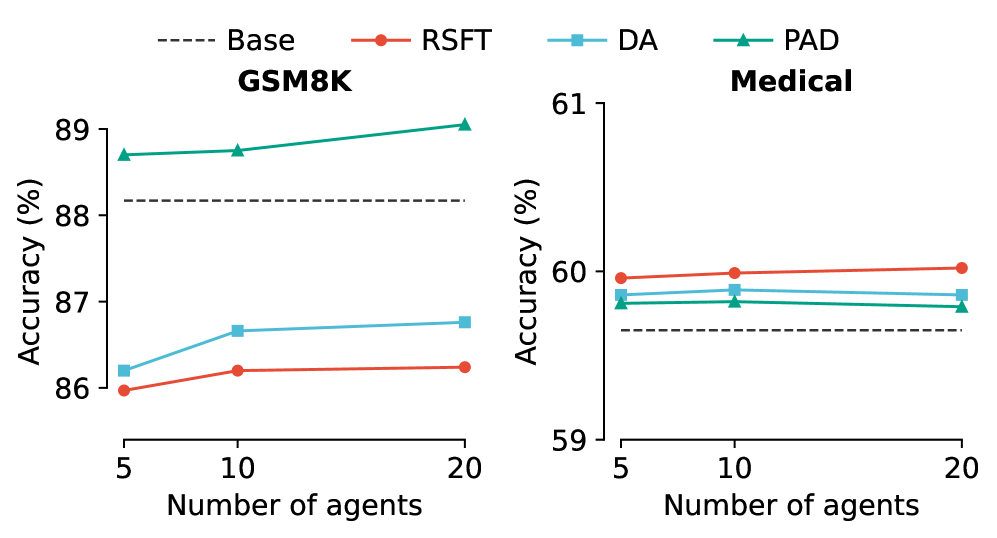
За пределами индивидуальных задач: Обобщение и устойчивость
Модели, полученные с помощью дистилляции AgentArk, демонстрируют заметно улучшенные способности к обобщению. Исследования показывают, что эти модели успешно справляются с данными, которые они ранее не видели, и адаптируются к новым, неожиданным задачам. В отличие от традиционных подходов, где производительность часто снижается при столкновении с незнакомыми условиями, AgentArk позволяет создавать системы, сохраняющие высокую эффективность даже в условиях неопределенности. Это достигается благодаря способности модели извлекать и применять общие принципы рассуждений, что позволяет ей эффективно решать широкий спектр задач, выходящих за рамки тренировочного набора данных. Такая адаптивность делает модели, обученные с использованием AgentArk, особенно ценными в реальных приложениях, где входные данные могут быть непредсказуемыми и разнообразными.
В основе повышения устойчивости моделей, созданных с помощью AgentArk, лежит симуляция разнообразных процессов рассуждения. Этот подход позволяет смягчить влияние предвзятостей и противостоять атакам, направленным на искажение результатов. Вместо того, чтобы полагаться на единый, фиксированный способ анализа данных, система генерирует множество альтернативных цепочек логических выводов. Такое разнообразие позволяет модели оценивать информацию с разных точек зрения, выявлять потенциальные ошибки и находить более надежные решения, даже если исходные данные содержат неточности или намеренные искажения. В результате, модель становится менее восприимчивой к манипуляциям и способна поддерживать высокую точность даже в сложных и непредсказуемых условиях.
Применение AgentArk к мультимодальным большим языковым моделям (MultimodalLLMs) открывает принципиально новые возможности для рассуждений, охватывающих различные типы данных. Данный подход позволяет моделям не просто обрабатывать текст и изображения, но и интегрировать информацию из этих источников для более глубокого понимания и принятия решений. Эксперименты показывают, что AgentArk значительно улучшает способность моделей к комплексному анализу, позволяя им успешно решать задачи, требующие сочетания визуальной и текстовой информации. Это, в свою очередь, расширяет сферу применения подобных моделей, делая их полезными в таких областях, как анализ медицинских изображений, автономное вождение и создание интеллектуальных помощников, способных понимать и реагировать на окружающий мир более естественно и эффективно.
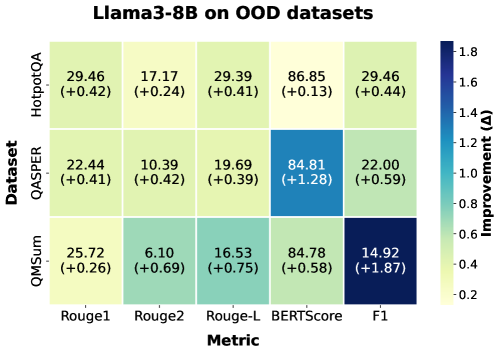
Будущее рассуждений: Масштабируемость и эффективность
Несмотря на то, что многоагентные системы по своей природе требуют значительных вычислительных ресурсов, разработанная в рамках AgentArk модель дистилляции демонстрирует существенное снижение затрат на проведение логических выводов по сравнению с работой полноценной многоагентной системы. Этот подход позволяет получить компактную модель, сохраняющую ключевые способности к рассуждению, но требующую значительно меньше вычислительной мощности для функционирования. Таким образом, AgentArk предлагает эффективный способ использования преимуществ коллективного интеллекта без существенного увеличения вычислительной нагрузки, открывая возможности для применения сложных систем рассуждений в средах с ограниченными ресурсами.
В настоящее время проводятся исследования, направленные на усовершенствование процесса дистилляции знаний, используемого в AgentArk, с целью дальнейшего снижения вычислительных затрат. Ученые изучают новые алгоритмы и методы, позволяющие более эффективно переносить знания от сложной многоагентной системы к компактной, дистиллированной модели. Особое внимание уделяется оптимизации процесса обучения и поиску компромисса между точностью и скоростью работы. Предполагается, что дальнейшая работа в этом направлении позволит значительно расширить область применения AgentArk, сделав его доступным для использования на устройствах с ограниченными ресурсами и в задачах, требующих высокой производительности.
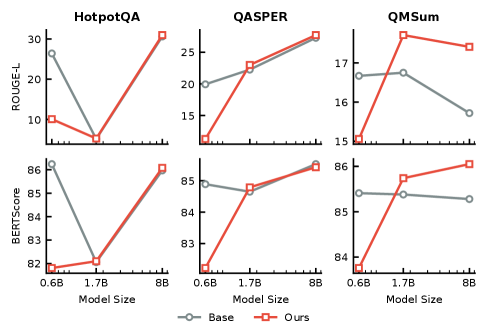
Исследования демонстрируют, что применение последовательного подхода к формированию представлений (PAD) обеспечивает значительное повышение производительности и стабильности модели. В отличие от других методов, склонных к колебаниям результатов, PAD гарантирует воспроизводимость и надежность. Более того, установлено, что увеличение размера предварительно обученной модели (PRM) приводит к еще более существенным улучшениям даже при использовании относительно небольших целевых моделей. Это указывает на то, что более обширные знания, заложенные в PRM, эффективно передаются в процессе дистилляции, обеспечивая значительный прирост эффективности и точности.
Наблюдая за развитием AgentArk, становится ясно, что стремление к концентрации интеллекта в единой модели — это не просто техническая задача, но и отражение глубокой закономерности. Системы, как и живые организмы, эволюционируют, стремясь к оптимальному использованию ресурсов. Идея дистилляции, перенос знаний от множества агентов в единого, напоминает процесс обучения, где опыт коллектива преломляется в индивидуальном понимании. Как однажды заметил Клод Шеннон: «Информация — это не просто данные, а способ организации этих данных». AgentArk, в сущности, демонстрирует, как можно организовать сложный коллективный разум, чтобы он уместился в рамках одного агента, повышая эффективность решения задач, требующих глубокого рассуждения.
Что же дальше?
Представленная работа, стремясь вместить рой разума в единый сосуд, неизбежно обнажает старую истину: архитектура — это лишь способ откладывать хаос. AgentArk, подобно любому другому инструменту, не устраняет сложность, а лишь перераспределяет её. Перенос знаний из многоагентной системы в единую модель — это не решение, а переформулировка проблемы. Неизбежно возникнет вопрос о потерях при дистилляции, о границах применимости, о тех случаях, когда коллективный разум все же необходим.
Нет лучших практик, есть лишь выжившие. Успех AgentArk, если таковой будет достигнут, не станет универсальным рецептом. Задачей останется понимание того, когда дистилляция уместна, а когда необходимо сохранять распределенный характер интеллекта. Важно помнить, что порядок — это лишь кэш между двумя сбоями. Следующим шагом представляется не столько улучшение процесса дистилляции, сколько разработка методов диагностики тех случаев, когда единая модель неизбежно потерпит неудачу.
В конечном счете, AgentArk — это еще один шаг в бесконечном поиске эффективных способов управления сложностью. Остается надеяться, что этот шаг подтолкнет исследователей к более глубокому пониманию природы интеллекта — как коллективного, так и индивидуального — и к признанию того, что идеальных решений просто не существует.
Оригинал статьи: https://arxiv.org/pdf/2602.03955.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Самообучающиеся агенты: новый подход к автономным системам
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Третья Разновидность ИИ: Как модели, думающие «про себя», оставят позади GPT и CoT
- BOOM: Визуальный перевод лекций: новый уровень доступности
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Охота на уязвимости: как большие языковые модели учатся на ошибках прошлого
- Диффузия против Квантов: Новый Взгляд на Факторизацию
- Генерация изображений: Новый взгляд на скорость и детализацию
- Многокритериальная оптимизация: взгляд на народные методы
2026-02-06 02:51