Автор: Денис Аветисян
Новая модель MemoBrain предлагает принципиально новый подход к организации памяти для искусственного интеллекта, позволяя агентам последовательно и эффективно решать многоэтапные задачи.
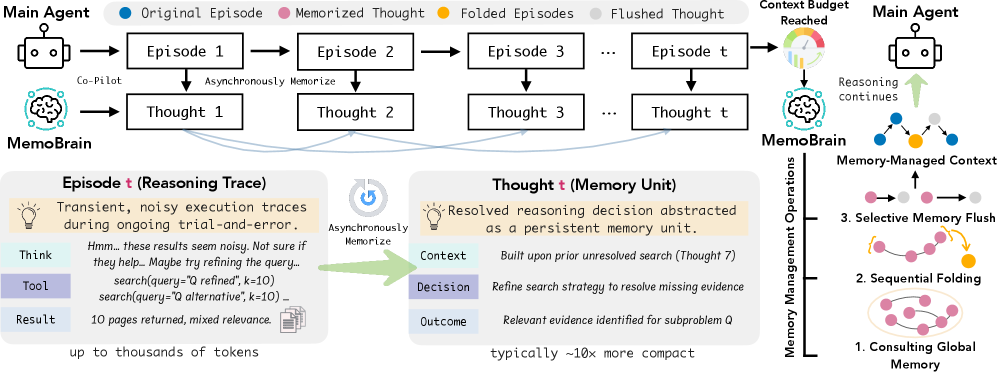
MemoBrain — это система исполнительной памяти, предназначенная для управления траекториями рассуждений и контекстом в инструментально-дополненных агентах, обеспечивая зависимость памяти от текущих задач.
В условиях возрастающей сложности задач, требующих долгосрочного планирования, стандартные архитектуры агентов, использующих инструменты, сталкиваются с проблемой накопления информации и поддержания когерентности рассуждений. В данной работе, ‘MemoBrain: Executive Memory as an Agentic Brain for Reasoning’, предлагается модель исполнительной памяти, позволяющая активно управлять траекториями рассуждений и контролировать контекст, обеспечивая тем самым последовательность и направленность действий. Ключевой особенностью MemoBrain является создание зависимой от контекста памяти, фиксирующей важные промежуточные состояния и логические связи. Способна ли подобная архитектура радикально улучшить производительность агентов в сложных, долгосрочных задачах и открыть новые горизонты в области искусственного интеллекта?
Пределы Контекста: Узкое Горлышко Рассуждений
Несмотря на впечатляющие успехи в решении разнообразных задач, современные большие языковые модели сталкиваются с серьезными ограничениями при выполнении сложных рассуждений, требующих учета информации на протяжении длительного времени. Это связано с так называемым «окном контекста» — фиксированным объемом информации, который модель способна обработать одновременно. Превышение этого лимита приводит к потере важных деталей и, как следствие, к снижению точности и последовательности рассуждений. Таким образом, способность модели к логическому выводу и решению проблем, требующих долгосрочного планирования, напрямую зависит от размера этого окна, которое, несмотря на постоянное увеличение, остается узким местом в архитектуре подобных систем. Поэтому, для достижения более сложных форм искусственного интеллекта, необходимо искать новые способы организации и использования информации, выходящие за рамки простого увеличения объема контекста.
Накопление контекстной информации представляет собой существенное ограничение для больших языковых моделей (LLM), негативно влияющее на их способность поддерживать связность в продолжительных взаимодействиях. По мере увеличения объема обрабатываемого текста, модели сталкиваются с экспоненциальным ростом вычислительной нагрузки, что приводит к снижению эффективности и ухудшению качества генерируемых ответов. Этот процесс подобен попытке удерживать в памяти слишком большое количество деталей — со временем информация начинает искажаться или вовсе забываться. В результате, LLM могут терять нить рассуждений, противоречить самим себе или игнорировать важные детали, представленные в начале разговора, что существенно ограничивает их применимость в задачах, требующих долгосрочного планирования и сложного анализа.
Несмотря на постоянное увеличение вычислительных мощностей и размеров языковых моделей, традиционные подходы к масштабированию оказываются недостаточными для преодоления фундаментального ограничения, связанного с объемом контекста. Простое увеличение числа параметров не решает проблему сохранения когерентности и логической связи в длинных последовательностях рассуждений. Это подталкивает исследователей к разработке принципиально новых архитектур памяти, которые позволят моделям эффективно хранить, извлекать и использовать информацию из более обширного контекста, имитируя механизмы долговременной памяти, присущие человеческому мозгу. В центре внимания оказываются методы сжатия информации, иерархические структуры памяти и механизмы внимания, позволяющие моделям фокусироваться на наиболее релевантных фрагментах контекста, что может значительно улучшить их способность к сложному, многоступенчатому рассуждению.
Инструментально-Расширенные Агенты: Выход за Пределы Контекста
Фреймворки агентов, дополненных инструментами, представляют собой перспективный подход к преодолению ограничений, связанных с объемом контекста, в задачах искусственного интеллекта. Вместо обработки больших объемов данных внутри модели, эти фреймворки предусматривают чередование этапов рассуждений с вызовами внешних инструментов, таких как поисковые системы, калькуляторы или API. Такая организация позволяет агенту динамически получать необходимую информацию по мере её потребности, значительно расширяя возможности обработки сложных задач, требующих доступа к внешним знаниям и ресурсам. В результате, агенты могут решать задачи, которые не помещаются в фиксированный контекст стандартных языковых моделей.
Эффективное использование инструментов для расширения возможностей агентов требует наличия надежной системы исполнительной памяти. Данная система необходима для управления потоком информации между агентом, инструментами и внешней памятью, обеспечивая когерентность выполняемой задачи. Она отвечает за отслеживание статуса выполнения, сохранение промежуточных результатов и контекста, а также за выбор оптимальных действий на основе текущей информации и долгосрочных целей. Без эффективной системы исполнительной памяти, агент может потерять ход мыслей, повторять одни и те же действия или принимать неверные решения, что существенно снижает его производительность и надежность.
Для эффективной работы агентов, использующих внешние инструменты, необходим механизм конструирования памяти, преобразующий эпизоды рассуждений в компактные, повторно используемые «Мысли». Этот процесс включает в себя абстрагирование ключевой информации из последовательности действий и наблюдений, создавая структурированное представление, пригодное для последующего извлечения и применения. Такие «Мысли» служат строительными блоками для более сложных рассуждений, позволяя агенту избегать повторного выполнения одних и тех же шагов и эффективно использовать накопленный опыт. Формат «Мыслей» должен включать в себя описание выполненного действия, полученный результат и контекст, необходимый для повторного применения этого знания в аналогичных ситуациях.
MemoBrain: Зависимостная Память для Рассуждающих Агентов
MemoBrain представляет собой новую модель исполнительной памяти, функционирующую как помощник-пилот для рассуждающих агентов. В отличие от пассивных систем хранения, MemoBrain активно конструирует воспоминания и управляет контекстом, необходимым для выполнения сложных задач. Эта модель не просто хранит информацию, но и организует её, позволяя агенту эффективно отслеживать ход рассуждений и принимать обоснованные решения в условиях ограниченных ресурсов и длительных последовательностей действий. Функционирование MemoBrain направлено на повышение эффективности и надежности агентов, требующих сохранения и использования контекста на протяжении всего процесса рассуждения.
В основе MemoBrain лежит использование отношений зависимости (Dependency Relations) между отдельными “мыслями” (Thoughts), представляющими собой логические шаги в процессе рассуждений. Каждая мысль связывается с другими, отражая их взаимосвязь — например, одна мысль может быть обоснованием другой или служить ее следствием. Такая организация позволяет эффективно извлекать релевантную информацию, поскольку система может проследить цепочку зависимостей от текущего вопроса к соответствующим доказательствам или промежуточным выводам. Это значительно повышает скорость и точность поиска нужных данных в памяти агента, особенно в задачах, требующих долгосрочного планирования и рассуждений.
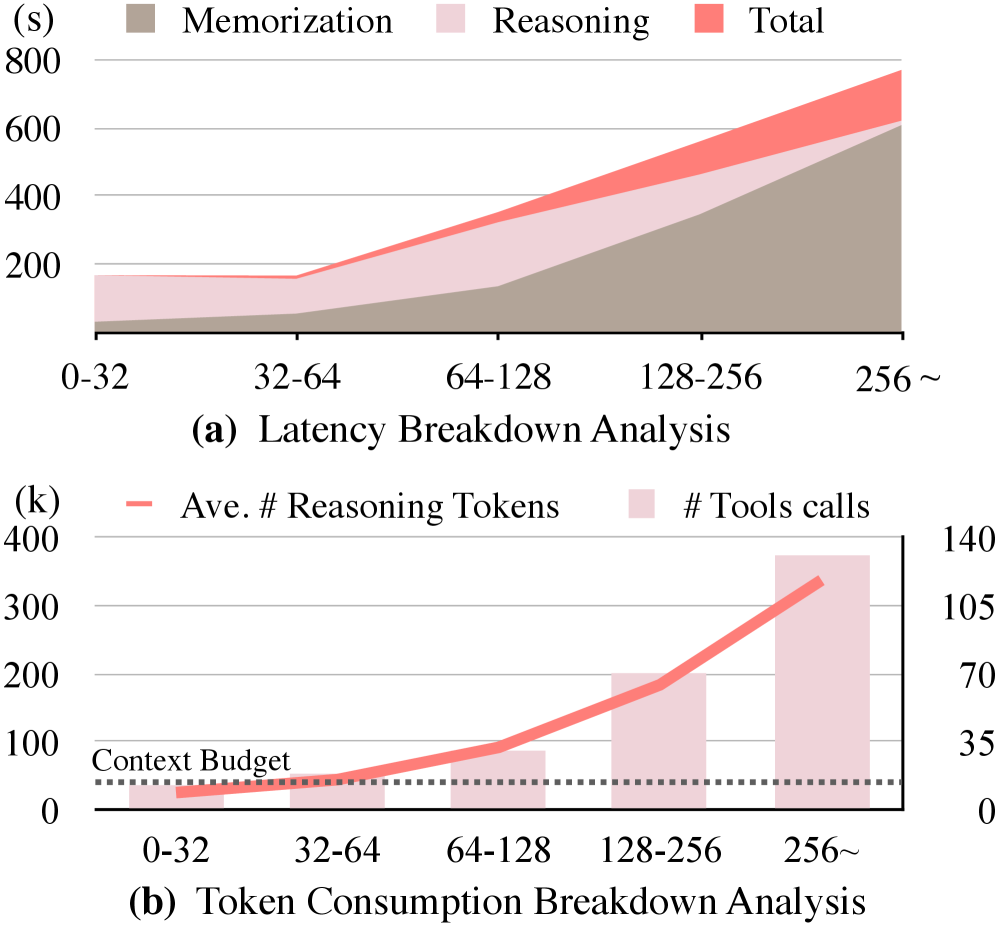
Для поддержания ограниченного контекста при работе с большими объемами информации, MemoBrain использует методы эффективного управления памятью, такие как “Sequential Trajectory Folding” (последовательное свертывание траектории) и “Selective Memory Flush” (селективная очистка памяти). “Sequential Trajectory Folding” позволяет компактно представлять последовательности рассуждений, сводя их к ключевым состояниям, что снижает требования к объему памяти. “Selective Memory Flush” динамически удаляет устаревшие или нерелевантные фрагменты памяти, основываясь на оценке их важности для текущего процесса рассуждения. Комбинация этих методов обеспечивает сохранение критически важной информации, необходимой для выполнения задач с длинным горизонтом планирования, и предотвращает переполнение памяти.
Эффективность предложенного подхода была подтверждена на сложных бенчмарках, включающих BrowseComp-Plus, GAIA и WebWalker, демонстрируя улучшенные результаты в задачах, требующих долгосрочного рассуждения. Детальные данные представлены на графике, показывающем превосходство модели в сравнении с существующими решениями. Интеграция MemoBrain-8B с агентами GLM-4.6 и DeepResearch-30B-A3B позволила достичь лучших в своем классе показателей Pass@1, что свидетельствует о значительном повышении надежности и точности ответов в сложных сценариях рассуждений.
К Адаптивному Рассуждению: Межзадачная Память и Долгосрочное Обучение
Расширение так называемой “рабочей памяти” агента за счет внедрения “межзадачной памяти” позволяет ему сохранять и эффективно использовать знания, полученные при решении различных задач. Этот подход значительно повышает способность агента к персонализации, поскольку он адаптируется к специфическим требованиям каждой новой задачи, опираясь на накопленный опыт. Вместо повторного изучения принципов и закономерностей, агент способен применять уже усвоенные знания, что существенно увеличивает скорость и эффективность его работы. Такая архитектура позволяет создавать интеллектуальные системы, которые не просто реагируют на текущий запрос, но и учатся на прошлом опыте, становясь все более компетентными и адаптивными.
Механизмы долговременной памяти, объединенные с эффективными методами суммирования, позволяют системе накапливать опыт и развивать все более сложные способности к рассуждению. Вместо того чтобы каждый раз начинать с нуля, система способна извлекать уроки из предыдущих взаимодействий и применять их к новым задачам. Эффективное суммирование играет ключевую роль, позволяя сжать большие объемы информации в компактные и полезные представления, которые можно быстро извлечь и использовать. Этот процесс напоминает формирование человеческой мудрости, где прошлый опыт служит основой для принятия более обоснованных решений и решения сложных проблем. Подобный подход открывает возможности для создания искусственного интеллекта, способного не просто выполнять задачи, но и учиться, адаптироваться и совершенствоваться с течением времени.
Традиционные большие языковые модели (LLM) часто сталкиваются с проблемой забывания информации и неспособностью эффективно использовать накопленный опыт в новых задачах. Данная архитектура, основанная на принципах долговременной памяти, призвана преодолеть это ограничение. Она позволяет агентам не просто обрабатывать информацию, но и сохранять её в структурированном виде, что обеспечивает возможность адаптации и улучшения производительности с течением времени. В отличие от моделей, которые начинают «с чистого листа» при решении каждой новой задачи, данная система способна извлекать и использовать знания, полученные ранее, повышая устойчивость и эффективность работы в различных условиях. Это создает основу для разработки более надежных и гибких систем искусственного интеллекта, способных к непрерывному обучению и адаптации к изменяющимся требованиям.
Дальнейшие исследования направлены на усовершенствование стратегий управления памятью, включая оптимизацию процессов хранения, извлечения и обновления информации в графе памяти. Особое внимание уделяется возможности самообучения внутри этого графа, где система самостоятельно выявляет закономерности и связи между различными фрагментами знаний, не требуя явного внешнего контроля. Предполагается, что такой подход позволит значительно повысить эффективность использования накопленного опыта, а также создать более гибкую и адаптивную систему искусственного интеллекта, способную к непрерывному обучению и самосовершенствованию на основе собственных данных и взаимодействий.
Исследование, представленное в данной работе, напоминает процесс деконструкции сложного механизма. MemoBrain, как система управления траекториями рассуждений, стремится не просто хранить информацию, но и активно ею манипулировать, контролируя контекст для обеспечения последовательности в долгосрочном планировании. Этот подход к управлению памятью, где зависимость от предыдущих шагов является ключевым фактором, перекликается с мыслью Дональда Кнута: «Преждевременная оптимизация — корень всех зол». Подобно тому, как преждевременная оптимизация может исказить структуру программы, попытка сразу создать идеальную систему долгосрочного планирования без глубокого понимания зависимостей и контекста приведет к неэффективности. MemoBrain, напротив, фокусируется на понимании внутренней логики процесса рассуждений, что позволяет создавать более гибкие и надежные системы.
Куда Ведет Дорога?
Представленная работа, конечно, не является ответом на вопрос о создании разума, но демонстрирует, что управление траекторией рассуждений — это не просто оптимизация поиска, а активное конструирование контекста. Очевидно, что нынешние реализации MemoBrain — лишь начальный этап. Зависимость от предопределенных инструментов и необходимость ручной настройки управления памятью — это ограничения, которые требуют пересмотра. Следующим шагом представляется разработка механизмов самообучения, позволяющих агенту самостоятельно расширять свой инструментарий и адаптировать стратегии управления памятью под конкретные задачи.
Интересно, что модель MemoBrain, по сути, воспроизводит некоторые аспекты человеческой рабочей памяти, но в формализованном виде. Возникает закономерный вопрос: насколько адекватно эта модель отражает истинные механизмы принятия решений в биологических системах? Или же это просто еще одна полезная абстракция, которая, как и все остальные, имеет свои пределы применимости? Вероятно, наиболее плодотворным подходом станет интеграция принципов MemoBrain с нейроморфными вычислениями, что позволит создать более эффективные и энергонезатратные системы.
В конечном итоге, успех подобных исследований будет зависеть не только от технических достижений, но и от готовности отказаться от упрощенных моделей разума. Иногда, чтобы понять систему, необходимо ее сломать. Именно в хаосе возникают новые закономерности, а не в аккуратно составленной документации. Возможно, истинный прорыв произойдет тогда, когда мы научимся создавать агентов, которые не просто решают задачи, а активно ищут новые способы их решения, даже если эти способы кажутся нам нелогичными или контрпродуктивными.
Оригинал статьи: https://arxiv.org/pdf/2601.08079.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовый Борьба: Китай и США на Передовой
- Квантовые симуляторы: проверка на прочность
- Квантовые нейросети на службе нефтегазовых месторождений
- Искусственный интеллект заимствует мудрость у природы: новые горизонты эффективности
- Интеллектуальная маршрутизация в коллаборации языковых моделей
2026-01-14 16:04