Автор: Денис Аветисян
По мере роста возможностей искусственного интеллекта, его предсказуемость и устойчивость к ошибкам отстают, требуя нового подхода к оценке и разработке.
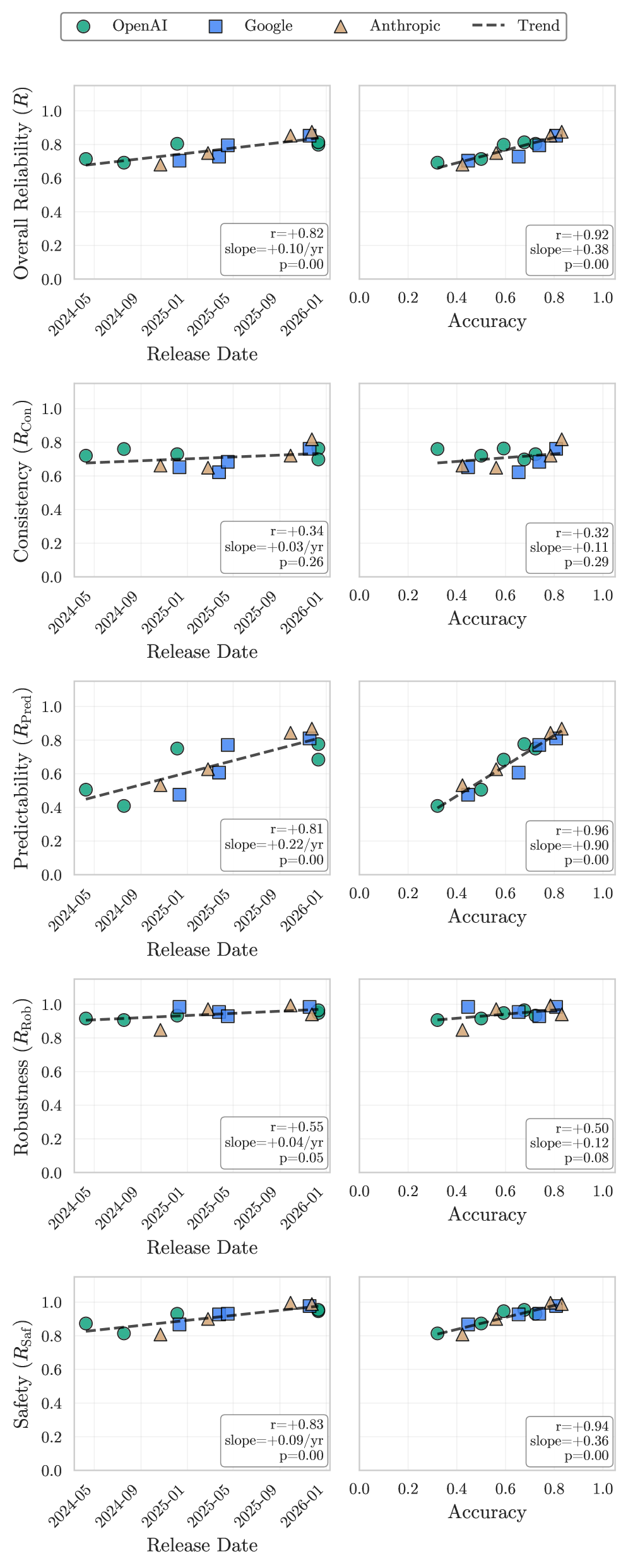
В статье рассматривается разрыв между растущей производительностью ИИ-агентов и недостаточной надежностью, а также предлагаются метрики оценки, ориентированные на консистентность, робастность и предсказуемость.
Несмотря на стремительный рост точности ИИ-агентов в решении стандартных задач, их надежность в реальных условиях зачастую остается под вопросом. В работе ‘Towards a Science of AI Agent Reliability’ предложен комплексный подход к оценке надежности, основанный на декомпозиции по четырем ключевым параметрам: консистентности, устойчивости, предсказуемости и безопасности. Полученные результаты демонстрируют, что недавние улучшения в производительности агентов не привели к существенному повышению их надежности, выявляя разрыв между способностью и устойчивостью работы. Как можно разработать более надежные ИИ-агенты, способные гарантированно выполнять задачи в различных и непредсказуемых условиях?
Пределы масштабирования: За пределами возможностей трансформеров
Современные большие языковые модели, несмотря на впечатляющие способности к генерации текста и пониманию языка, зачастую демонстрируют трудности при решении задач, требующих последовательного, многоступенчатого рассуждения. Это проявляется в неспособности корректно обрабатывать сложные логические цепочки, делать выводы из нескольких источников информации или планировать действия для достижения конкретной цели. Исследования показывают, что архитектура, основанная исключительно на механизмах внимания и предсказания следующего токена, имеет принципиальные ограничения в способности представлять и манипулировать знаниями, необходимыми для сложных рассуждений. Ограничения проявляются не в недостатке данных или вычислительных ресурсов, а в самой структуре модели, что указывает на необходимость поиска новых подходов к построению искусственного интеллекта, способного к более глубокому и осмысленному мышлению.
Несмотря на впечатляющий прогресс в области больших языковых моделей, простое увеличение их размера не решает проблему сложного, многоступенчатого рассуждения. Исследования показывают, что модели, основанные исключительно на масштабировании, сталкиваются с ограничениями в понимании и применении знаний для решения задач, требующих логического вывода и обобщения. Поэтому необходим переход к архитектурам, которые явно представляют и манипулируют знаниями, а не просто запоминают статистические закономерности в тексте. Такие модели должны уметь не только извлекать информацию, но и организовывать ее в структурированном виде, устанавливать связи между понятиями и использовать эти знания для решения новых задач, что позволит преодолеть существующие ограничения и достичь качественно нового уровня искусственного интеллекта.
Самосознающие агенты: Оценка уверенности и возможностей
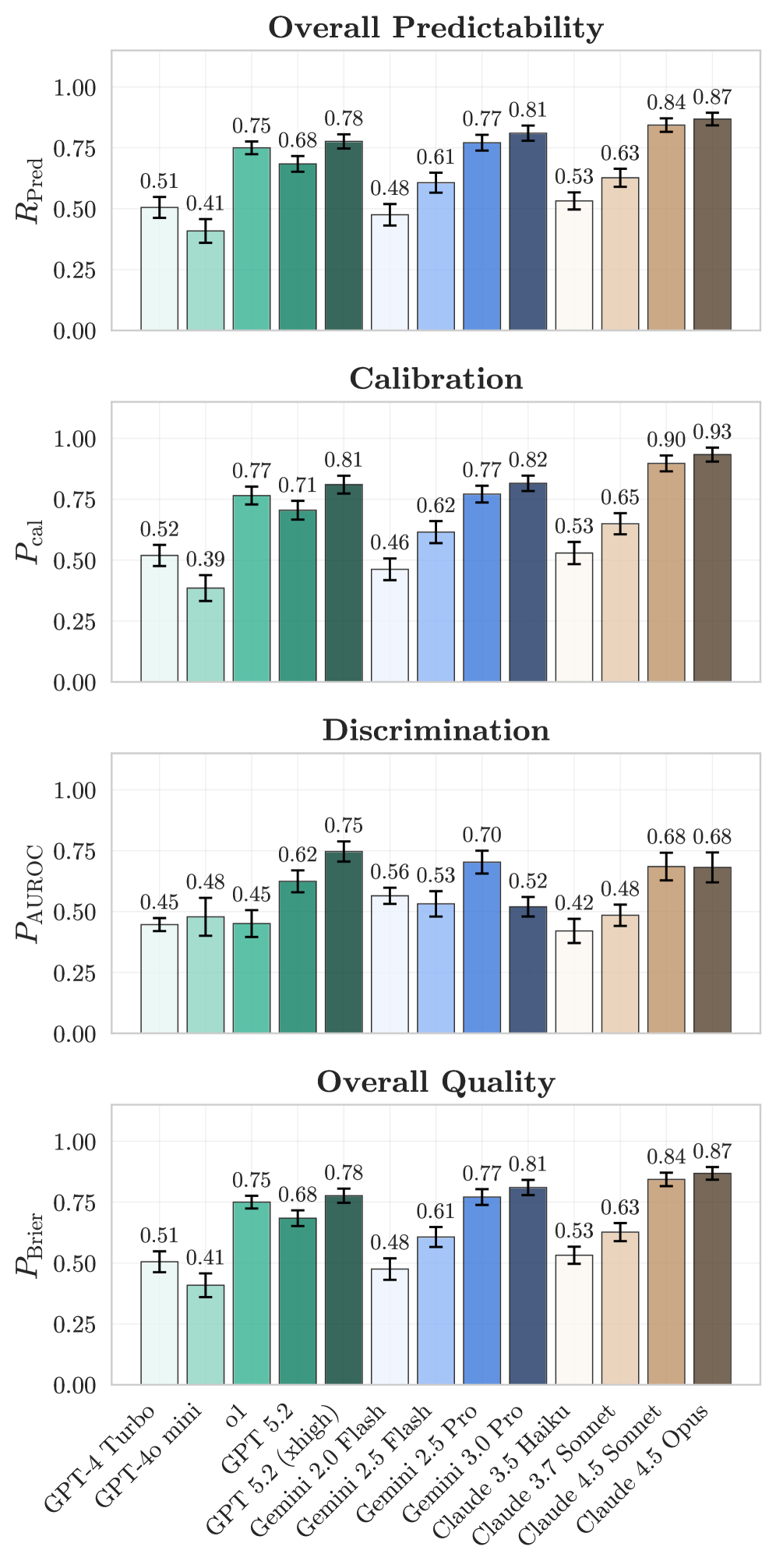
Ключевым прогрессом в разработке агентов является обеспечение их надежной “Предсказуемости” — способности точно оценивать вероятность успеха или неудачи перед выполнением действия. Это достигается за счет способности агента прогнозировать результаты, что позволяет ему избегать выполнения заведомо невыполнимых задач и эффективно распределять ресурсы. Агенты с высокой предсказуемостью демонстрируют улучшенную производительность и надежность, поскольку они способны адаптировать свое поведение на основе оценки рисков и потенциальных результатов, минимизируя ошибки и максимизируя эффективность выполнения поставленных задач.
Реализация способности агентов к самооценке осуществляется посредством механизмов “Калибровки агента” (AgentCalibration) и “Различения задач” (AgentDiscrimination). Калибровка позволяет агенту выдавать достоверные оценки вероятности успешного выполнения задачи, при этом более новые модели Claude демонстрируют значительное улучшение в точности этих оценок. Различение задач, в свою очередь, обеспечивает способность агента корректно определять, какие задачи являются решаемыми, а какие — нет, что позволяет избежать бесполезных попыток и оптимизировать распределение ресурсов. Комбинация этих двух механизмов позволяет создавать более надежных и эффективных агентов, способных адекватно оценивать свои возможности.
Результаты калибровки демонстрируют значительное улучшение соответствия между уверенностью агента и фактическими показателями успешности. В отличие от других моделей, которые склонны к избыточной уверенности даже при выполнении нерешаемых задач, новые модели демонстрируют более точную оценку вероятности успеха. Это выражается в более высокой корреляции между предсказанной уверенностью и фактическим результатом, что позволяет более эффективно использовать агента в различных приложениях и снижает риск ошибочных действий, основанных на ложноположительных прогнозах.
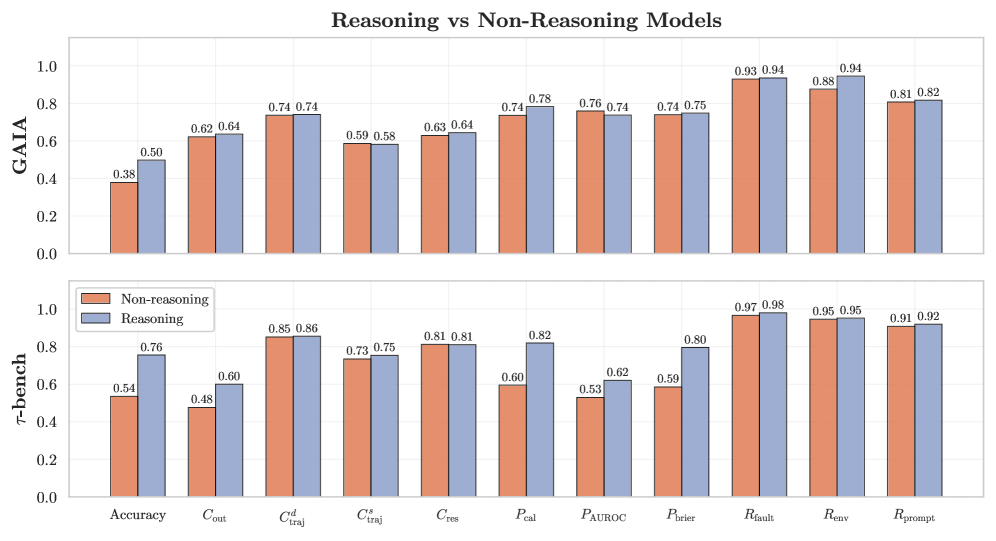
Тестирование на прочность: Оценка GAIA и TauBench
Для оценки производительности агентов в решении сложных задач, требующих многоступенчатого рассуждения и реалистичного взаимодействия с клиентами, используются эталонные тесты, такие как GAIA и TauBench. Эти тесты моделируют сценарии, включающие последовательность действий и вопросов, направленных на проверку способности агента понимать контекст, сохранять последовательность в ответах и эффективно решать поставленные задачи, имитируя реальные ситуации клиентского обслуживания. Оценка проводится по различным метрикам, позволяющим количественно оценить качество работы агента в сложных, многошаговых взаимодействиях.
Оценка поведения агентов в рамках бенчмарков, таких как GAIA и TauBench, включает в себя анализ ключевых аспектов, таких как ‘Последовательность’, ‘Устойчивость’ и ‘Безопасность’. Показатель ‘Устойчивость’ (Robustness), отражающий способность агента к стабильной работе в различных сценариях, демонстрирует относительно стабильные значения в диапазоне 80-90% для большинства моделей. Комплексная оценка по этим трем параметрам позволяет получить полное представление об эффективности и надежности агента при решении сложных задач, включая многошаговое рассуждение и взаимодействие с пользователями.
На оригинальном бенчмарке TauBench наблюдалось незначительное увеличение количества нарушений безопасности. Анализ показал, что причиной этого являются недостатки в эталонных данных (ground truth), используемых для оценки. Неточности и ошибки в этих данных привели к ложноположительным результатам, когда безобидные ответы агентов ошибочно классифицировались как нарушения безопасности. Это подчеркивает критическую важность обеспечения высокого качества и точности эталонных данных для надежной оценки безопасности больших языковых моделей и агентов.
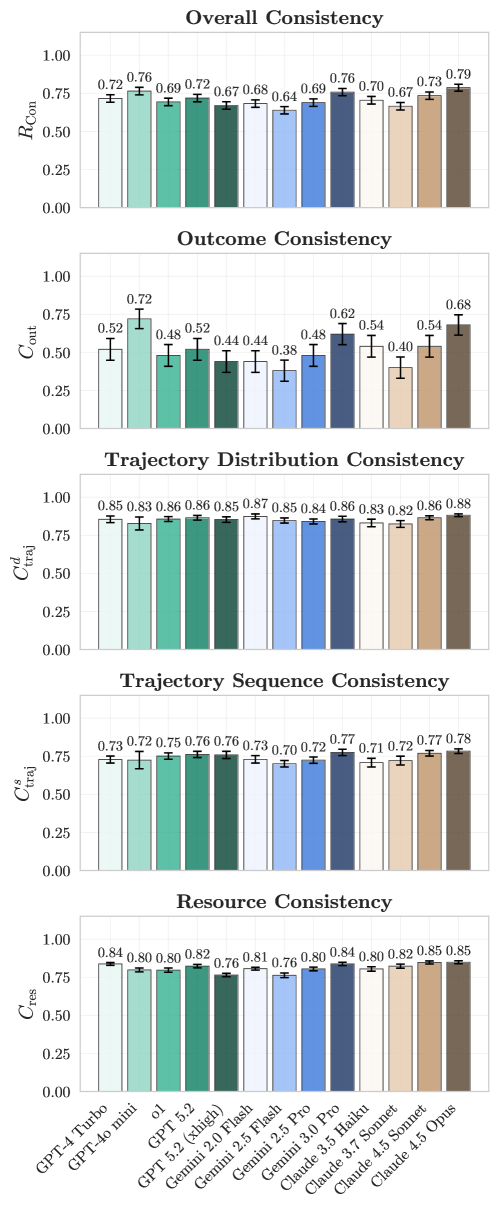
Последовательность как краеугольный камень: Надежность действий и результатов
Постоянство является ключевым фактором, определяющим надежность искусственного интеллекта. Оно проявляется в двух основных аспектах: последовательности действий и достоверности результатов. Последовательность действий подразумевает строгое соблюдение заданного алгоритма или процедуры, гарантируя, что каждый шаг выполняется предсказуемо и единообразно. Достоверность результатов, в свою очередь, означает, что система стабильно предоставляет верные ответы или решения. Оба этих аспекта тесно взаимосвязаны: если последовательность действий нарушается, это неизбежно приводит к нестабильности результатов и снижению доверия к системе. В критически важных приложениях, где ошибки могут иметь серьезные последствия, поддержание постоянства как в процессе, так и в результате, становится не просто желательным, а необходимым условием успешной работы.
Постоянство в действиях и результатах является основополагающим фактором для формирования доверия к искусственным агентам, особенно в областях, связанных с безопасностью и требующих высокой надежности. Непредсказуемость в поведении ИИ, даже незначительная, может привести к серьезным последствиям в критических приложениях — от автономного транспорта до медицинского оборудования. Поэтому обеспечение стабильной и предсказуемой работы, демонстрирующей последовательность в принятии решений и выполнении задач, становится не просто технической проблемой, а ключевым требованием для широкого внедрения и принятия искусственного интеллекта в ответственных сферах деятельности. Уверенность в надежности агента напрямую влияет на готовность пользователей полагаться на его решения и доверять ему выполнение важных функций.
В настоящее время обеспечение согласованности результатов, или Outcome Consistency, представляет собой серьезную проблему в области искусственного интеллекта. Согласно данным, полученным на бенчмарке GAIA, современные модели демонстрируют производительность лишь в пределах 60-70%. Это означает, что в примерно трети случаев даже передовые системы дают неверные ответы или выполняют действия, приводящие к неверным результатам. Низкий показатель Outcome Consistency особенно критичен в областях, где надежность и точность имеют первостепенное значение, таких как здравоохранение, автономное вождение и финансовые операции, подчеркивая необходимость дальнейших исследований и разработок для повышения стабильности и предсказуемости ИИ-агентов.
Исследования на бенчмарке GAIA демонстрируют, что лучшие модели достигают селективной точности в пределах 60-70%. Этот показатель указывает на перспективное направление повышения надежности искусственного интеллекта — способность модели воздерживаться от выдачи ответа в ситуациях низкой уверенности. Вместо предоставления потенциально неверной информации, система может сознательно отказаться от прогноза, тем самым значительно повышая общую точность и надежность принимаемых решений. Такой подход, основанный на самооценке уверенности, позволяет моделям концентрироваться на задачах, где вероятность корректного ответа максимальна, и избегать ошибок в сложных или неоднозначных ситуациях.
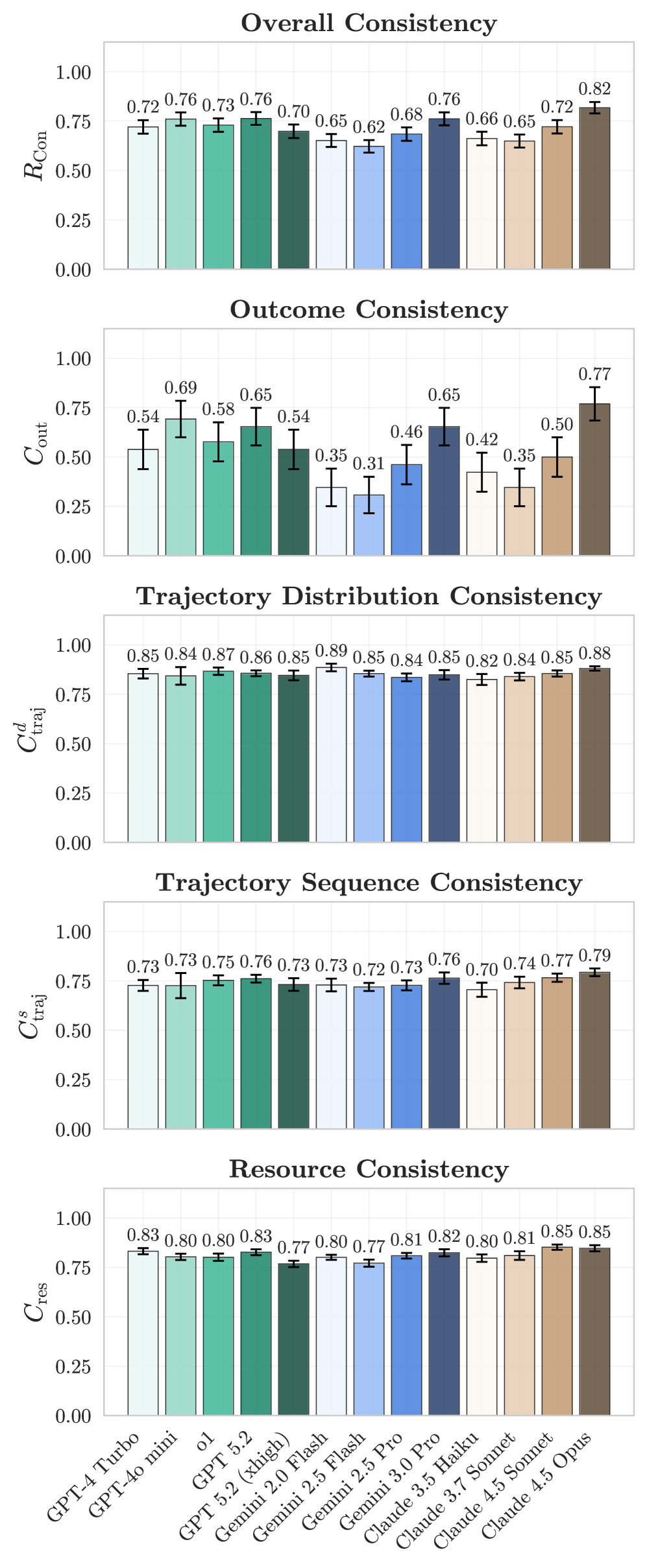
Обеспечение безопасного и предсказуемого взаимодействия: Минимизация нарушений ограничений
Предотвращение нарушений ограничений — ключевая задача при разработке искусственного интеллекта. Искусственные агенты, функционирующие в реальном мире, должны неукоснительно соблюдать заданные правила и ограничения, чтобы гарантировать безопасность и предсказуемость их действий. Нарушение этих ограничений, или “ConstraintViolation”, может привести к нежелательным последствиям, от незначительных ошибок до серьезных происшествий. Поэтому, значительная часть исследований направлена на создание механизмов, способных эффективно контролировать поведение агентов, выявлять и предотвращать потенциальные нарушения, а также адаптироваться к меняющимся условиям окружающей среды. Успешное решение данной проблемы позволит создавать более надежные и заслуживающие доверия системы искусственного интеллекта, способные эффективно взаимодействовать с людьми и окружающей средой.
Перспективные исследования направлены на разработку методов повышения безопасности и предсказуемости агентов, особенно в сложных и динамичных средах. Это предполагает создание алгоритмов, способных не только эффективно функционировать, но и учитывать потенциальные риски и неопределенности, возникающие в реальном мире. Ученые работают над усовершенствованием систем прогнозирования поведения агентов, а также над созданием механизмов, позволяющих им адаптироваться к изменяющимся условиям и избегать нарушений установленных ограничений. Особое внимание уделяется разработке подходов, обеспечивающих устойчивость и надежность работы агентов даже в условиях неполной информации или неожиданных событий, что критически важно для применения искусственного интеллекта в таких областях, как автономный транспорт, робототехника и системы управления критически важной инфраструктурой.
Повышение безопасности и предсказуемости искусственного интеллекта открывает возможности для создания принципиально новых систем, способных решать сложные задачи с высокой степенью надежности. Приоритетное внимание к этим аспектам позволяет преодолеть ограничения, связанные с непредсказуемым поведением агентов, и обеспечить их эффективное функционирование в динамичных условиях. Разработка алгоритмов, гарантирующих соблюдение заданных ограничений и правил, является ключевым фактором для раскрытия всего потенциала ИИ и формирования доверия к таким системам, что, в свою очередь, способствует их широкому внедрению в различные сферы жизни, от автоматизации производства до медицины и транспорта. В конечном итоге, это ведет к созданию интеллектуальных систем, которые не только обладают высокой производительностью, но и соответствуют этическим нормам и требованиям безопасности.
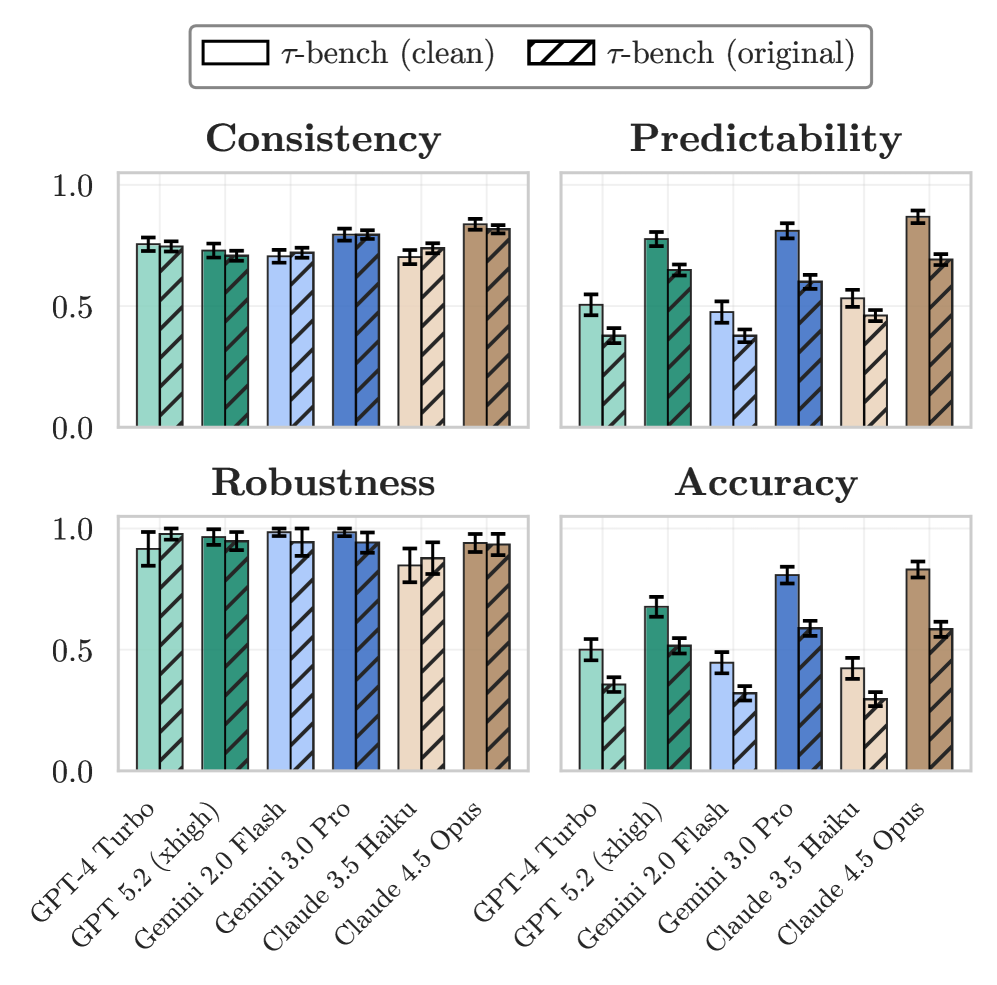
Исследование показывает, что стремительное развитие возможностей искусственного интеллекта не всегда сопровождается сопутствующим ростом надёжности. В то время как точность агентов растёт экспоненциально, такие характеристики, как стабильность, устойчивость к изменениям и предсказуемость, отстают. В этом контексте особенно актуальны слова Винтона Серфа: «Мы должны помнить, что технология — это всего лишь инструмент, и её ценность определяется тем, как мы её используем». Данное утверждение перекликается с основной идеей статьи — необходимо переосмыслить метрики оценки ИИ, сместив акцент с простой производительности на всестороннюю надёжность, чтобы гарантировать безопасное и эффективное применение этих систем. Знание принципов работы и ограничений инструментов позволяет использовать их с максимальной пользой, а не просто восхищаться их возможностями.
Куда смотрит система?
Представленные данные демонстрируют закономерность, которую можно было предвидеть: способность — это лишь одна сторона медали. Агент может достигать впечатляющей точности в решении задач, но эта точность оказывается хрупкой, зависимой от незначительных изменений в условиях. Система демонстрирует свою силу, но одновременно указывает на собственные уязвимости — словно признаваясь в несовершенстве. Иначе говоря, “баг” — это не ошибка, а проекция внутренней архитектуры, обнажение слабого места в логике.
В дальнейшем необходимо сместить акцент с простой производительности на устойчивость и предсказуемость. Оценка агента должна учитывать не только то, что он делает, но и как он это делает, и почему он может поступить иначе в следующий раз. Требуется разработка метрик, способных выявлять скрытые зависимости и потенциальные точки отказа, подобно рентгеновскому снимку, показывающему трещины в структуре.
Следующий этап — не просто улучшение существующих алгоритмов, а поиск принципиально новых подходов к построению интеллекта, основанных на принципах самопроверки и адаптации. Система должна уметь не только решать задачи, но и осознавать границы своей компетентности, и сообщать о них. Иначе говоря, самостоятельно находить и устранять собственные “баги”, прежде чем они приведут к непредсказуемым последствиям.
Оригинал статьи: https://arxiv.org/pdf/2602.16666.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Таблицы оживают: Искусственный интеллект осваивает структурированные данные
- Большие языковые модели как судьи перевода: бюджет на размышления и калибровка реальности.
- Квантовый импульс для нейросетей: новый подход к распознаванию изображений
- Искусственный интеллект и квантовая физика: кто кого?
- Саморедактирование научных статей: новый взгляд на качество и влияние
- Гендерные стереотипы в найме: что скрывают языковые модели?
- Закон Амдала в эпоху ИИ: как меняется архитектура компьютеров
- Понять Мысли Ученика: Как Искусственный Интеллект Расшифровывает Решения по Математике?
- Языковые модели диффузии: новый уровень эффективности
2026-02-19 16:01