Автор: Денис Аветисян
Новое исследование демонстрирует, что использование вероятностных вознаграждений значительно улучшает способность больших языковых моделей к последовательному рассуждению и делает процесс обучения более стабильным.
Вероятностные вознаграждения в обучении с подкреплением повышают эффективность логических цепочек в больших языковых моделях как в проверяемых, так и в непроверяемых областях.
Обучение больших языковых моделей (LLM) с подкреплением для решения задач рассуждения требует разработки специфических функций вознаграждения, часто бинарных, для каждой задачи. В работе ‘Likelihood-Based Reward Designs for General LLM Reasoning’ систематически исследуются функции вознаграждения, основанные на вероятности или логарифмической вероятности генерации эталонного ответа, что позволяет избежать необходимости в специализированных верификаторах и обеспечивает масштабируемость. Показано, что использование логарифмической вероятности эталонного ответа в качестве вознаграждения для обучения с цепочкой рассуждений (Chain-of-Thought) обеспечивает стабильные результаты как в задачах с возможностью верификации, так и в задачах с генерацией длинных ответов. Способны ли подобные подходы к функциям вознаграждения, основанные на вероятности, стать универсальным решением для тонкой настройки LLM в различных областях рассуждений?
Фундамент Разума: Большие Языковые Модели и Их Ограничения
Современные языковые модели, известные как LLM, стали краеугольным камнем в области обработки естественного языка. Эти модели демонстрируют впечатляющую способность генерировать связные и осмысленные тексты, а также понимать и интерпретировать сложный язык. Их применение охватывает широкий спектр задач — от автоматического перевода и написания текстов до создания чат-ботов и анализа тональности. Способность LLM к обучению на огромных объемах данных позволяет им улавливать тонкие нюансы языка и генерировать тексты, которые часто трудно отличить от созданных человеком. Благодаря этому, они стали незаменимым инструментом для решения задач, требующих понимания и генерации естественного языка, открывая новые возможности в различных сферах, от науки и образования до бизнеса и развлечений.
Стандартные большие языковые модели, несмотря на впечатляющие способности к генерации и пониманию текста, часто испытывают затруднения при решении задач, требующих сложного рассуждения. Эти ограничения проявляются особенно заметно в ситуациях, где необходим многоступенчатый вывод и понимание тонких нюансов логики. Вместо того, чтобы оперировать с абстрактными понятиями и выстраивать причинно-следственные связи, модели склонны к поверхностному анализу и воспроизведению шаблонов, что делает их уязвимыми в задачах, требующих глубокого понимания контекста и способности к критическому мышлению. Подобные недостатки подчеркивают необходимость разработки новых подходов к обучению и оценке языковых моделей, направленных на повышение их способности к логическому выводу и решению комплексных задач.
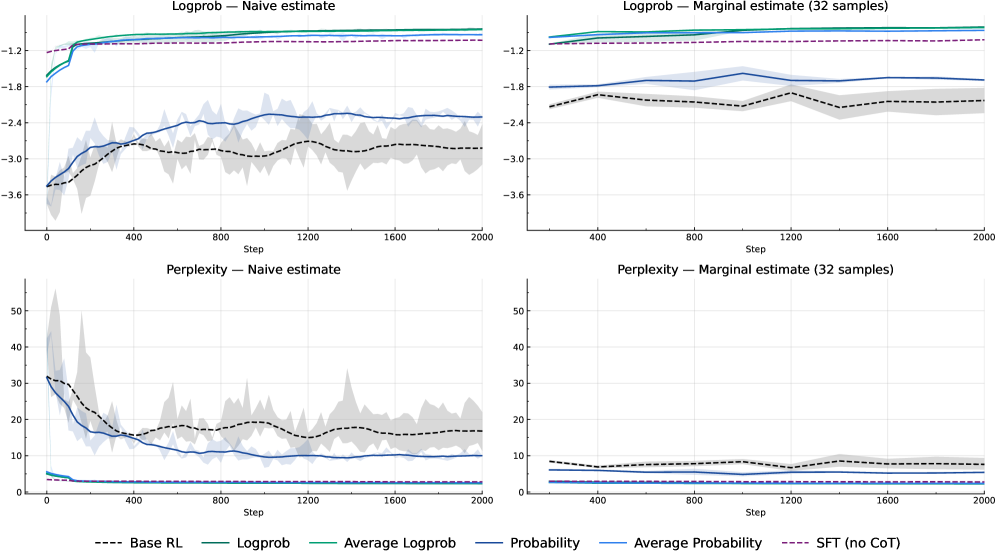
Оценка качества больших языковых моделей традиционно опирается на метрики, такие как перплексия, однако эти показатели не всегда адекватно отражают способность модели к сложному рассуждению. Проведенные исследования демонстрируют, что стандартные методы оценки часто оказываются недостаточными для выявления истинного потенциала моделей в задачах, требующих многоступенчатого логического вывода. В ходе работы удалось добиться значительного улучшения показателей перплексии, превзойдя результаты, полученные при использовании метода Supervised Fine-Tuning (SFT) в областях, где достоверность ответов может быть проверена. Данное достижение подчеркивает необходимость разработки более эффективных стратегий оценки и совершенствования больших языковых моделей, способных к более глубокому и надежному рассуждению.
Усиление Рассуждений: Обучение с Подкреплением
Обучение с подкреплением (RL) представляет собой перспективный метод дообучения больших языковых моделей (LLM) в дополнение к обучению с учителем (SFT). В отличие от SFT, где модель обучается на размеченных данных, RL позволяет модели учиться на основе получаемых вознаграждений, что дает возможность оптимизировать ее для конкретных задач, требующих рассуждений. Этот подход позволяет модели не просто имитировать предоставленные примеры, а активно исследовать пространство решений и улучшать свои стратегии рассуждений, максимизируя получаемое вознаграждение. В результате, LLM, обученные с использованием RL, демонстрируют улучшенные показатели в задачах, требующих логического вывода, планирования и решения проблем.
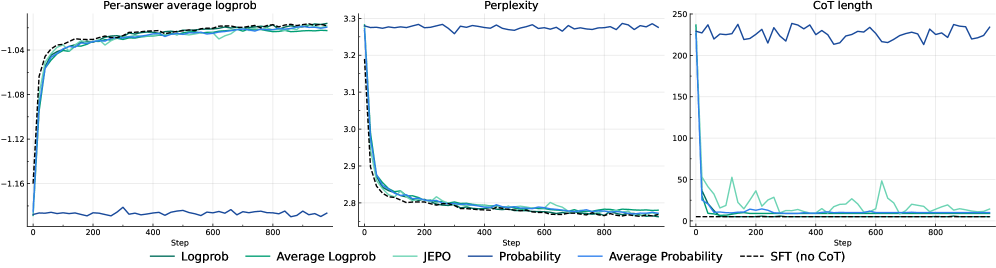
Для управления процессом обучения с подкреплением при дообучении больших языковых моделей (LLM) исследуются различные методы вознаграждения, включая LogProbReward и AverageLogProbReward. Эти методы стимулируют генерацию наиболее вероятных и связных цепочек рассуждений, оценивая вероятность сгенерированного текста. Полученные результаты демонстрируют, что использование вознаграждения на основе логарифмической вероятности (log(P(x))) выступает в качестве унифицирующего сигнала обучения, эффективно работающего как в задачах, где ответ может быть проверен (verifiable domains), так и в задачах, где верификация затруднена или невозможна (non-verifiable domains). Это позволяет оптимизировать модели для выполнения сложных рассуждений без необходимости предоставления внешних меток или экспертных оценок.
В процессе обучения с подкреплением (RL) расхождение Кулбака-Лейблера (KL Divergence) используется как метод регуляризации, предотвращающий катастрофическое забывание и сохраняющий общие языковые возможности модели. KL Divergence измеряет разницу между распределением вероятностей, генерируемым до и после тонкой настройки с использованием RL. Внедрение этого штрафа в функцию потерь способствует сохранению близости обновленной модели к ее исходному состоянию, ограничивая отклонение от первоначальных языковых закономерностей, усвоенных во время предварительного обучения. Таким образом, KL Divergence позволяет оптимизировать модель для конкретных задач рассуждения, не жертвуя ее способностью выполнять общие языковые задачи, что критически важно для поддержания универсальности и надежности.
Проверка на Прочность: Сложные Наборы Данных для Оценки Рассуждений
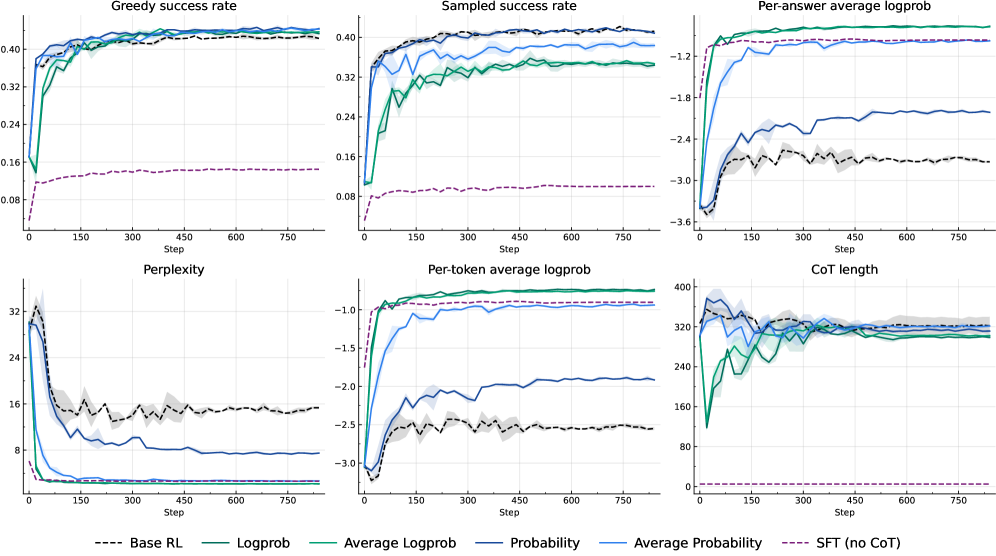
Для оценки эффективности моделей, обученных с использованием обучения с подкреплением (RL), необходимы сложные наборы данных, такие как MATH, DeepScaleR и NuminaProof. MATH предназначен для оценки навыков решения математических задач, DeepScaleR — для проверки способности к масштабируемому рассуждению, а NuminaProof — для проверки навыков доказательства теорем. Результаты тестирования показали, что достигнутые показатели успешности на этих наборах данных сопоставимы с результатами, полученными при использовании задач с вознаграждением 0/1, что свидетельствует о сравнимой эффективности предложенного подхода к обучению.
Набор данных Alpaca предоставляет примеры вопросов и ответов в развернутом формате, предназначенные для обучения и оценки способности больших языковых моделей (LLM) генерировать расширенные цепочки рассуждений. Этот набор состоит из инструкций и соответствующих ответов, демонстрирующих многоступенчатые процессы решения задач. Использование Alpaca позволяет оценить, насколько эффективно LLM могут не только давать конечный ответ, но и последовательно излагать логические шаги, приводящие к этому ответу, что является ключевым аспектом развития способностей к сложному рассуждению.
Интеграция промптинга “Цепочка рассуждений” (Chain-of-Thought, CoT) с обучением с подкреплением (RL) позволяет моделям явно формулировать промежуточные шаги решения задач, повышая их способность к рассуждениям. В областях, где результаты рассуждений могут быть проверены (verifiable domains), наблюдалось первоначальное сокращение длины цепочки CoT, за которым следовало восстановление. В областях, где проверка невозможна (non-verifiable domains), длина цепочки CoT значительно уменьшилась и стабилизировалась на низком уровне, что свидетельствует о коллапсе длины цепочки рассуждений и, как следствие, о снижении способности модели к развернутым рассуждениям.
Совершенствование Подхода: Алгоритмы и Выбор Модели
Для повышения способности больших языковых моделей (LLM) к логическому мышлению применяются алгоритмы обучения с подкреплением (RL), в частности, RLOO. Исследования показывают, что использование этих алгоритмов позволяет оптимизировать процесс рассуждений LLM, что подтверждается улучшением результатов на стандартных наборах данных для оценки производительности. В ходе экспериментов было установлено, что RLOO эффективно направляет LLM к более точным и обоснованным ответам, что свидетельствует о перспективности данного подхода для совершенствования когнитивных способностей искусственного интеллекта и повышения надежности принимаемых решений.
Ключевую роль в обучении языковых моделей с подкреплением играет функция вознаграждения, определяющая, насколько «правильным» является тот или иной шаг в процессе рассуждения. Методики, подобные VeriFree, используют вероятности эталонных ответов для формирования этой функции, что позволяет модели не просто генерировать текст, а стремиться к логически обоснованным и корректным выводам. Вместо простой оценки совпадения слов, VeriFree оценивает вероятность того, что сгенерированный ответ соответствует логике, заложенной в правильных ответах, тем самым стимулируя модель к более глубокому пониманию задачи и формированию обоснованных рассуждений. Этот подход позволяет эффективно направлять процесс обучения, избегая слепого копирования и поощряя развитие навыков логического мышления у языковой модели.
Исследования, проведенные с использованием больших языковых моделей, таких как Llama-3.2 и Qwen-2.5, продемонстрировали применимость разработанных алгоритмов оптимизации рассуждений к различным архитектурам нейронных сетей. Этот факт указывает на то, что методы, направленные на улучшение логического мышления и способности к решению задач, не ограничены конкретной моделью и могут быть успешно интегрированы в широкий спектр LLM. Полученные результаты свидетельствуют о значительном потенциале для повышения общей способности языковых моделей к более сложным формам анализа и генерации информации, открывая перспективы для создания более интеллектуальных и надежных систем искусственного интеллекта.
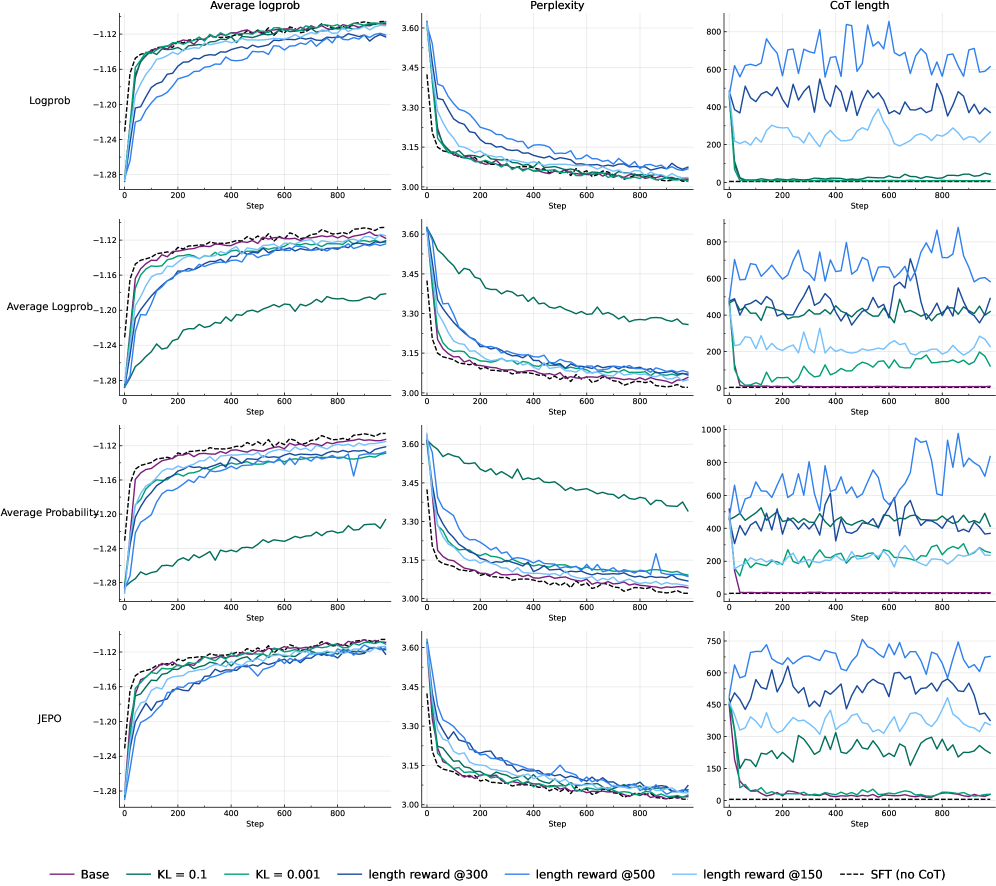
Представленное исследование демонстрирует, что использование вероятностных наград в процессе обучения с подкреплением последовательно улучшает производительность и стабилизирует цепочку рассуждений в больших языковых моделях, как в проверяемых, так и в непроверяемых задачах. Это согласуется с принципом, что структура определяет поведение системы. Как отмечал Дональд Дэвис: «Сложность всегда можно уменьшить, если смотреть на систему с правильной точки зрения». Данная работа подчеркивает важность проектирования системы вознаграждений, поскольку именно она формирует траекторию рассуждений модели, а не просто оптимизирует её для конкретной задачи. Оптимизация без учета целостной картины может создавать новые узлы напряжения, что подтверждает важность комплексного подхода к разработке систем искусственного интеллекта.
Что Дальше?
Представленная работа демонстрирует, что использование вознаграждений, основанных на логарифмической вероятности, действительно стабилизирует процесс рассуждений в больших языковых моделях. Однако, кажущаяся элегантность этого подхода не должна заслонять фундаментальный вопрос: что именно мы вознаграждаем? Просто высокую вероятность токена или истинное понимание? Если система кажется сложной, она, вероятно, хрупка. Необходимо признать, что оптимизация вероятности не равнозначна оптимизации интеллекта, и дальнейшие исследования должны сосредоточиться на разработке более тонких и содержательных сигналов вознаграждения.
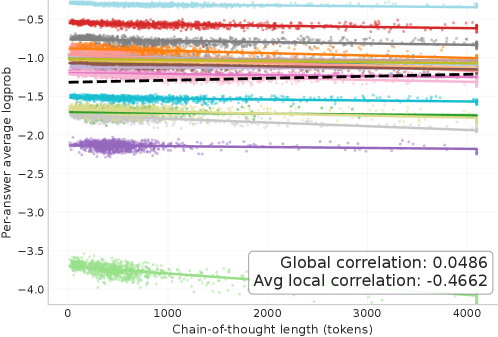
Особенно важно углубиться в понимание влияния длины цепочки рассуждений (CoT). Увеличение длины CoT часто приводит к повышению производительности, но за счет вычислительных затрат и потенциального усиления галлюцинаций. Архитектура — это искусство выбора того, чем пожертвовать. Необходимо разработать методы, позволяющие динамически адаптировать длину CoT в зависимости от сложности задачи и вычислительных ресурсов.
В конечном итоге, успех данного направления исследований зависит от способности выйти за рамки простого увеличения вероятности правильного ответа. Следующим шагом должно стать изучение способов интеграции знаний о предметной области и здравого смысла в процесс обучения, чтобы создать системы, способные не только генерировать правдоподобные тексты, но и демонстрировать истинное понимание.
Оригинал статьи: https://arxiv.org/pdf/2602.03979.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Укрощение Бесконечности: Алгебраические Инструменты для Кватернионов и За их Пределами
- Самообучающиеся агенты: новый подход к автономным системам
- Графы и действия: новый подход к планированию для роботов
- Поймут ли машины нюансы человеческих ценностей?
- Охота на уязвимости: как большие языковые модели учатся на ошибках прошлого
- Искусственный интеллект на производстве: иллюзии автономии
- Искусственный разум: Нет доказательств самосознания в современных языковых моделях
- Квантовые Загадки: От «Призрачного Действия на Расстоянии» к Суперкомпьютерам
- Генерация изображений: Новый взгляд на скорость и детализацию
2026-02-05 11:30