Автор: Денис Аветисян
Новая разработка демонстрирует, что даже компактные языковые модели способны к сложным действиям и планированию, приближаясь по возможностям к своим более крупным аналогам.

В статье представлена Youtu-LLM — языковая модель с 1,96 миллиардами параметров, обученная с использованием данных о траекториях действий и демонстрирующая конкурентоспособные агентные возможности.
Несмотря на впечатляющий прогресс в области больших языковых моделей, создание эффективных и компактных систем, способных к сложному планированию и автономному принятию решений, остается сложной задачей. В настоящей работе представлена модель Youtu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models, демонстрирующая мощные агентские возможности при относительно небольшом размере (1.96B параметров). Ключевым нововведением является методика пре-обучения, основанная на формировании разнообразных траекторий данных и ориентированная на развитие как общих знаний, так и специализированных навыков в областях математики, программирования и использования инструментов. Способна ли эта модель открыть новую эру компактных, но интеллектуальных агентов, способных решать сложные задачи без необходимости использования огромных вычислительных ресурсов?
Раскрытие Агентного Потенциала: Новый Подход к Искусственному Интеллекту
Современные языковые модели, несмотря на впечатляющие успехи в генерации текста и понимании отдельных запросов, часто демонстрируют ограниченные возможности при решении сложных, многоступенчатых задач, требующих последовательного применения логики и планирования. Эта неспособность к сложному рассуждению существенно ограничивает их потенциал в качестве полноценных агентов, способных самостоятельно ставить цели и эффективно их достигать. Их работа, как правило, сводится к реакциям на текущий запрос, а не к проактивному формированию стратегии и выполнению последовательности действий для достижения поставленной цели. Таким образом, существующие модели зачастую не способны к глубокому анализу ситуации, предвидению последствий и адаптации к изменяющимся условиям, что является ключевым аспектом для реализации настоящих агентских возможностей.
Основная сложность в создании действительно автономных агентов заключается не просто в обработке больших объемов информации, но и в умении преобразовывать этот контекст в последовательные, целенаправленные действия. Исследования показывают, что современные языковые модели часто испытывают трудности с поддержанием долгосрочной когерентности и планированием шагов для достижения поставленной цели. Недостаточно лишь понимать контекст; необходимо активно использовать эту информацию для формулирования стратегии, предвидения последствий и адаптации к меняющимся обстоятельствам. Именно интеграция глубокого понимания контекста с проактивным, ориентированным на результат поведением является ключевым препятствием на пути к созданию искусственного интеллекта, способного к самостоятельным решениям и достижению сложных целей.

Youtu-LLM: Архитектура и Стратегия Обучения
Youtu-LLM представляет собой языковую модель, содержащую 1.96 миллиарда параметров и использующую архитектуру Dense Multi-Latent Attention (Dense MLA). Данная архитектура позволяет модели более эффективно захватывать и представлять сложные взаимосвязи в данных, повышая ее выразительность и способность к генерации связного и релевантного текста. Dense MLA отличается от традиционных механизмов внимания за счет использования нескольких латентных пространств, что обеспечивает более гранулярное и контекстуально-обогащенное представление входных данных и, как следствие, улучшает качество генерируемого вывода.
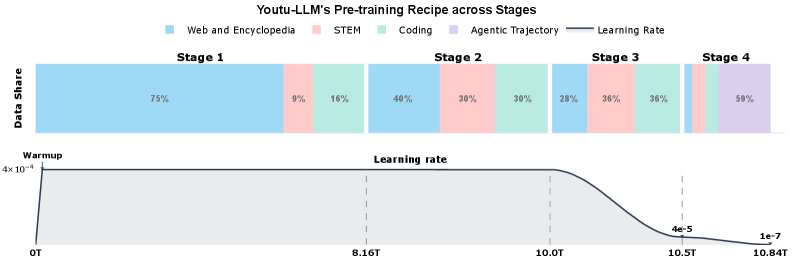
Обучение Youtu-LLM осуществляется в несколько этапов, начиная с этапа «Agentic Mid-Training». Данный этап направлен на внедрение сигналов, ориентированных на поведение агента, на промежуточной стадии обучения модели. Это позволяет сформировать у модели способность к целеполаганию и выполнению задач, имитируя действия интеллектуального агента. Внедрение этих сигналов на ранней стадии способствует более эффективному освоению последующих данных и улучшает общую производительность модели в задачах, требующих рассуждений и планирования.
В Youtu-LLM реализован модифицированный токенизатор на основе byte-level BPE (Byte Pair Encoding). Этот подход обеспечивает повышенную эффективность токенизации как для общих текстовых данных, так и для данных, ориентированных на задачи рассуждений. В отличие от традиционных токенизаторов, byte-level BPE оперирует непосредственно с байтами, что позволяет избежать проблем с неизвестными символами и эффективно обрабатывать широкий спектр языков и форматов данных. Модификация токенизатора в Youtu-LLM направлена на оптимизацию размера словаря и снижение вычислительных затрат при обработке данных, что особенно важно для моделей с ограниченным количеством параметров.
Для дальнейшей оптимизации и расширения возможностей Youtu-LLM используется разнообразный набор данных, включающий в себя STEM-данные (наука, технологии, инженерия и математика), данные, относящиеся к программированию и коду, а также критически важные ‘Агентские данные’. STEM-данные обеспечивают модель знаниями в специализированных областях, данные о коде — способностью понимать и генерировать программный код, а ‘Агентские данные’ — навыками, необходимыми для реализации агент-ориентированного поведения и решения задач, требующих планирования и принятия решений. Комбинация этих наборов данных позволяет Youtu-LLM эффективно справляться с широким спектром задач и демонстрировать высокую производительность в различных областях применения.
Строгая Оценка: Бенчмаркинг Агентских Возможностей
Модель Youtu-LLM подверглась всестороннему тестированию с использованием набора бенчмарков, предназначенных для оценки агентских возможностей, включая APTBench. Данный бенчмарк позволяет оценить способность модели выполнять сложные задачи, требующие планирования, принятия решений и взаимодействия с окружением. Процесс оценки включал в себя запуск модели на различных сценариях APTBench и анализ результатов для определения ее эффективности в решении задач, типичных для агентских систем. Использование APTBench в качестве ключевого инструмента оценки позволило получить объективные данные о производительности Youtu-LLM в контексте агентских приложений.
Модель демонстрирует высокую эффективность при решении сложных задач из набора SWE-Bench-Verified, достигая показателя pass@1 в 17.7%. Это представляет собой относительное улучшение в 42.7% по сравнению с базовой моделью. Показатель pass@1 отражает долю успешно решенных задач из набора при одной попытке. Данный результат указывает на значительное повышение способности модели к автоматизированному решению задач программирования и выполнению верифицированных тестов.
Модель Youtu-LLM демонстрирует высокую эффективность при выполнении задач, оцениваемых бенчмарками глубоких исследований, такими как GAIA и xbench. Это свидетельствует о способности модели проводить сложные исследовательские изыскания, требующие анализа больших объемов информации и синтеза новых знаний. Успешное прохождение этих тестов подтверждает, что Youtu-LLM способна не только отвечать на вопросы, но и самостоятельно изучать предметную область, извлекать релевантные данные и формировать обоснованные выводы.
Использование данных о траекториях (Trajectory Data) в процессе промежуточного обучения (Agentic Mid-Training) позволило добиться подтвержденного улучшения производительности модели Youtu-LLM на бенчмарке APTBench на 6%. Данные о траекториях представляют собой записи последовательности действий, выполненных агентом при решении задач, и используются для корректировки стратегии обучения и повышения эффективности агента в выполнении сложных задач, оцениваемых в рамках APTBench. Это улучшение демонстрирует, что включение информации о предыдущих попытках решения задач в процесс обучения положительно влияет на способность модели к агентному взаимодействию.
Модель Youtu-LLM демонстрирует передовые результаты среди моделей с количеством параметров менее 2 миллиардов, превосходя по производительности более крупные модели, такие как Qwen3-4B. Среднее относительное улучшение по набору агентских бенчмарков составляет 14.4%, что подтверждает высокую эффективность Youtu-LLM в выполнении задач, требующих автономного планирования и выполнения действий. Данный показатель свидетельствует о robustных агентских возможностях модели и ее конкурентоспособности в сравнении с другими существующими решениями.

Совершенствование Агентности: Обучение с Учителем и Обучение с Подкреплением
Супервизированное обучение, или дообучение с учителем, представляет собой процесс адаптации предварительно обученной языковой модели к конкретным задачам и форматам выходных данных. В рамках данного подхода модель обучается на размеченном наборе данных, состоящем из пар «инструкция — ожидаемый результат». Это позволяет модели точно сопоставлять входные запросы с соответствующими действиями и генерировать предсказуемые, релевантные ответы. Эффективность супервизированного обучения напрямую влияет на способность модели следовать инструкциям, повышая ее точность и надежность в выполнении поставленных задач, особенно в контексте сложных, многоэтапных запросов.
Интеграция обучения с подкреплением позволяет оптимизировать поведение Youtu-LLM в заданных средах, стимулируя проактивное выполнение задач. В процессе обучения модель получает вознаграждение или штраф в зависимости от совершаемых действий, что способствует формированию стратегии поведения, направленной на максимизацию кумулятивной награды. Это позволяет Youtu-LLM не просто реагировать на запросы, но и самостоятельно инициировать действия для достижения поставленных целей в рамках определенной среды, например, автоматическое решение задач или выполнение последовательности действий для достижения определенного результата.
Комбинирование методов контролируемой тонкой настройки и обучения с подкреплением позволяет добиться синергетического эффекта в работе Youtu-LLM. Контролируемая тонкая настройка обеспечивает соответствие модели желаемым результатам и инструкциям, что повышает ее отзывчивость. В свою очередь, обучение с подкреплением оптимизирует поведение модели в конкретных средах, способствуя автономному выполнению задач. В результате достигается создание агента, который не только оперативно реагирует на запросы, но и способен самостоятельно инициировать действия для достижения поставленных целей, демонстрируя высокую степень автономности.
Исследование демонстрирует, что даже относительно небольшие языковые модели, такие как Youtu-LLM, способны к проявлению агентности при правильном подходе к предварительному обучению. Использование данных о траекториях и обучение с подкреплением позволяет модели эффективно взаимодействовать с окружением и достигать поставленных целей. Как отмечал Марвин Минский: «Лучший способ предвидеть будущее — создать его». Этот принцип находит отражение в данной работе, где авторы не просто констатируют возможности больших языковых моделей, а активно формируют их, обучая Youtu-LLM демонстрировать конкурентоспособное поведение, несмотря на меньший размер. По сути, исследование показывает, что архитектура и процесс обучения играют решающую роль в определении поведения системы, подтверждая важность целостного подхода к разработке интеллектуальных систем.
Куда же дальше?
Представленная работа демонстрирует, что эмерджентные свойства агентности не обязательно требуют гигантских моделей. Youtu-LLM, с её скромными 1.96 миллиардами параметров, наводит на мысль: не размер сети определяет интеллект, а продуманность её предварительного обучения. Однако, стоит признать, что траектории данных, хоть и эффективны, — лишь один из возможных путей. Остаётся открытым вопрос: насколько универсальна эта методика? Применимы ли эти принципы к задачам, требующим более сложного планирования и адаптации к непредсказуемым условиям?
Настоящая сложность, вероятно, кроется не в масштабировании моделей, а в создании данных, отражающих истинную структуру взаимодействия. Документация фиксирует структуру, но не передаёт поведение — оно рождается во взаимодействии. Необходимо сместить акцент с пассивного накопления данных на активное моделирование среды и обучение агентов в ней. Иначе мы рискуем создать впечатляющие инструменты, лишенные глубокого понимания.
В конечном счёте, успех в области агентных моделей будет зависеть не от изобретения новых архитектур, а от способности уловить и воспроизвести принципы, лежащие в основе живых систем. Простота и ясность — вот что должно лежать в основе элегантного дизайна, способного к настоящей адаптации и обучению.
Оригинал статьи: https://arxiv.org/pdf/2512.24618.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Квантовая криптография: от теории к практике
- Робот, который видит, понимает и действует: новая эра общего назначения
2026-01-01 21:45