Автор: Денис Аветисян
Новый подход позволяет крупным языковым моделям эффективнее решать сложные задачи, разбивая их на последовательность более простых подвопросов.
Метод A2D, основанный на декомпозиции задач и использовании обучения с подкреплением с проверяемыми наградами, значительно улучшает возможности больших языковых моделей в области рассуждений и принятия решений.
Несмотря на значительный прогресс в обучении больших языковых моделей (LLM) с подкреплением на основе проверяемых наград (RLVR), их способность к решению сложных задач часто ограничивается недостатком информации в процессе обучения. В данной работе, посвященной ‘Adaptive Ability Decomposing for Unlocking Large Reasoning Model Effective Reinforcement Learning’, предложен метод A$^2$D, направленный на повышение эффективности RLVR за счет адаптивного разложения сложных вопросов на более простые подвопросы. Этот подход позволяет обогатить процесс обучения дополнительной информацией, улучшая исследование и эксплуатацию возможностей модели. Каким образом декомпозиция способностей может стать ключевым фактором в раскрытии полного потенциала LLM для решения задач, требующих глубокого рассуждения?
За гранью статистических закономерностей: узкое место логического мышления в больших языковых моделях
Несмотря на впечатляющую способность больших языковых моделей (БЯМ) распознавать закономерности в данных, сложные задачи, требующие многоступенчатого рассуждения, зачастую представляют для них значительную трудность. БЯМ преуспевают в выявлении статистических корреляций и прогнозировании на основе предыдущего опыта, однако испытывают проблемы при решении задач, требующих логического вывода, планирования и абстрактного мышления. В отличие от человеческого разума, способного к последовательному анализу и синтезу информации, БЯМ склонны к поверхностному восприятию данных и могут допускать ошибки в ситуациях, требующих глубокого понимания контекста и применения принципов дедукции. Данное ограничение является существенным препятствием на пути к созданию искусственного интеллекта, способного решать сложные проблемы и принимать обоснованные решения.
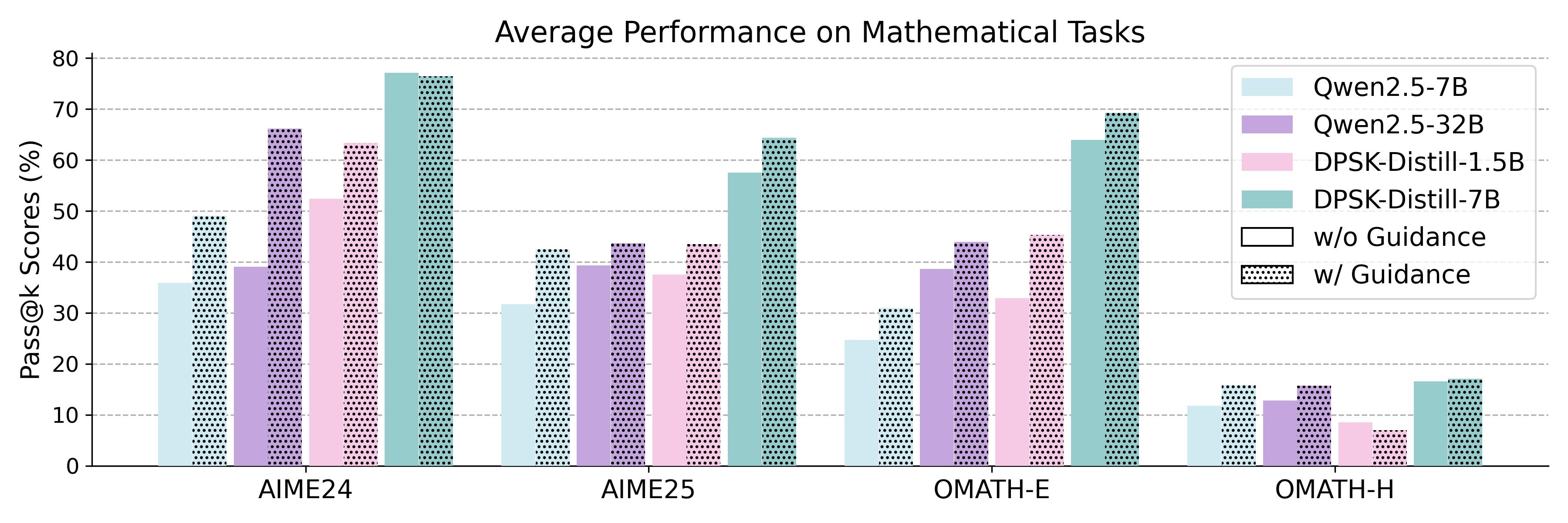
Несмотря на впечатляющий прогресс в области больших языковых моделей, простое увеличение их размера демонстрирует тенденцию к снижению эффективности при решении сложных задач, требующих многоступенчатого логического мышления. Текущие модели, даже самые мощные, показывают неудовлетворительные результаты на специализированных наборах данных, предназначенных для проверки математических способностей — показатель Pass@k составляет всего 25%. Это свидетельствует о том, что дальнейшее наращивание вычислительных ресурсов не является достаточным решением, и необходимы принципиально новые архитектурные подходы, способные значительно углубить и оптимизировать процесс логического вывода, чтобы преодолеть существующее ограничение и добиться существенного улучшения в решении сложных задач.
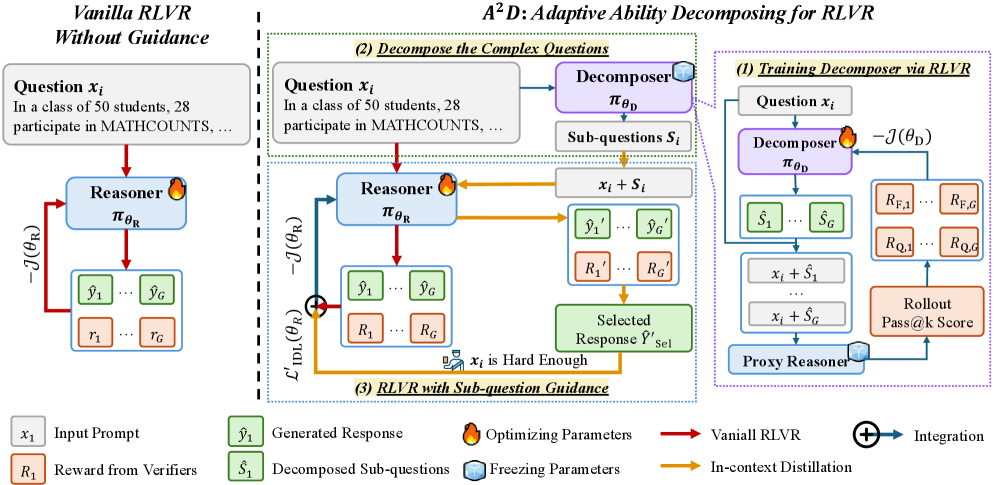
Деконструкция сложности: адаптивное разложение способностей (A2D)
Адаптивное разложение способностей (A2D) использует обученную модель ‘Декомпозер’ для разделения сложных вопросов на серию более простых, взаимосвязанных подвопросов. Этот процесс не является простым разделением, а предполагает структурирование исходной задачи таким образом, чтобы каждый подвопрос мог быть решен независимо, а результаты комбинированы для получения ответа на исходный вопрос. Обучение ‘Декомпозера’ направлено на выявление оптимальной стратегии декомпозиции, учитывающей сложность исходной задачи и взаимосвязи между ее компонентами. Эффективность декомпозиции оценивается по способности упростить процесс решения и повысить точность конечного ответа.
Разложение сложного вопроса на подвопросы осуществляется совместно с моделью ‘Reasoner’, прошедшей обучение для решения как этих подвопросов, так и исходной задачи. Такое совместное функционирование позволяет добиться синергетического эффекта, где решение подвопросов способствует более эффективному решению основной задачи, и наоборот. Модель ‘Reasoner’ не просто выполняет отдельные вычисления, а интегрирует результаты решения подвопросов для формирования итогового ответа, что повышает точность и надежность всей системы.
В A2D для оптимизации как компонента-декомпозитора, так и решателя используется обучение с подкреплением. В частности, применяется алгоритм GRPO (Generalized Reinforcement Learning with Policy Optimization), позволяющий одновременно улучшать способность декомпозитора разбивать сложные вопросы на более простые, и способность решателя находить корректные ответы на эти упрощенные подзадачи и исходную проблему. Обучение с подкреплением настраивает параметры обоих компонентов для достижения более высокой производительности и улучшения обобщающей способности модели на различных наборах данных, таких как AIME24, AIME25, MATH500 и Minerva.
Метод Adaptive Ability Decomposing (A2D) повышает эффективность решения задач за счет структурирования процесса рассуждений. В отличие от традиционных подходов, A2D позволяет более полно исследовать пространство возможных решений, что способствует улучшению обобщающей способности модели при решении сложных задач. Экспериментальные результаты на различных наборах данных, включая AIME24, AIME25, MATH500 и Minerva, демонстрируют устойчивое повышение производительности по сравнению с существующими методами, подтверждая эффективность предложенного подхода к решению задач, требующих комплексного анализа и синтеза информации.

Вознаграждение за декомпозицию: обучение декомпозера с помощью RLVR
Обучение декомпозитора осуществляется с использованием комбинации сигналов вознаграждения, ключевым из которых является метрика ‘Pass@k Reward’. Данная метрика оценивает долю успешно решенных подвопросов, на которые декомпозитор разбил исходную задачу. Значение ‘k’ определяет количество подвопросов, которые рассматриваются для оценки. Более высокая доля успешно решенных подвопросов, рассчитанная как отношение количества правильно отвеченных подвопросов к общему числу рассмотренных (k), приводит к большему вознаграждению и, следовательно, к оптимизации процесса декомпозиции. Метрика ‘Pass@k Reward’ служит прямым индикатором эффективности декомпозитора в разбиении сложных задач на более простые и решаемые компоненты.
Для обеспечения единообразия и повышения читабельности генерируемых подвопросов используется ‘Format Reward’ — награда за соблюдение структурированного формата. Эта награда оценивает соответствие выходных данных предопределенным шаблонам, включающим, например, корректное использование вопросительных слов, грамматическую правильность и логическую последовательность. Внедрение ‘Format Reward’ позволяет добиться более предсказуемых и интерпретируемых результатов, что упрощает последующую обработку и анализ подвопросов, а также повышает эффективность работы всей системы разложения задачи.
Обучение декомпозитора осуществляется посредством обучения с подкреплением с использованием проверяемых наград (RLVR), что обеспечивает надежную структуру оптимизации на основе сигналов вознаграждения. RLVR позволяет итеративно улучшать процесс декомпозиции, максимизируя суммарное вознаграждение, полученное от успешного решения подзадач (измеряемого, например, метрикой Pass@k) и соблюдения заданного формата выходных данных. Этот подход отличается от традиционных методов обучения с подкреплением за счет возможности верификации и точной оценки каждой награды, что повышает стабильность и эффективность обучения декомпозитора.
Генерация направляющих подвопросов (Sub-question Guidance) декомпозитором значительно повышает способность к исследованию пространства решений. Экспериментальные данные, полученные на различных наборах данных, демонстрируют улучшение метрики Pass@k, что свидетельствует о более успешном решении исходной задачи посредством декомпозиции и последовательного ответа на сгенерированные подвопросы. Улучшение Pass@k указывает на повышение вероятности нахождения верных ответов на подвопросы, что, в свою очередь, способствует более эффективному решению сложной задачи в целом.

Потери контекстной дистилляции: направление процесса рассуждений
Метод потерь контекстной дистилляции (IDL) направляет процесс рассуждений модели, предоставляя ей подсказки, полученные на основе декомпозированных подвопросов. Этот подход использует структурированные подвопросы, сгенерированные декомпозером, как своего рода «мягкие метки», указывающие модели наиболее вероятные шаги в решении сложной задачи. По сути, IDL позволяет модели учиться рассуждать, имитируя логику, заложенную в процессе декомпозиции, что способствует более эффективному использованию информации, содержащейся в подвопросах, и повышает точность и скорость решения поставленной проблемы. Таким образом, IDL формирует процесс рассуждений, направляя модель к более оптимальному решению, основываясь на подсказках, полученных из структурированного анализа исходной задачи.
Потеря дистрилляции в контексте (IDL) направлена на согласование процесса рассуждений модели с четкой структурой, предоставляемой подвопросами. Этот механизм способствует тому, чтобы модель не просто отвечала на исходный вопрос, а последовательно анализировала проблему, руководствуясь логикой, заложенной в декомпозиции. Фактически, IDL побуждает модель имитировать способ мышления, который был бы естественен для человека, решающего задачу путем разбиения её на более мелкие, управляемые этапы. Такое согласование с подвопросами позволяет модели более эффективно использовать предоставленную информацию и избегать распространенных ошибок, связанных с поверхностным пониманием задачи, что в конечном итоге приводит к повышению точности и эффективности решения.
Данный подход значительно повышает способность решателя эффективно использовать направляющие подсказки, формируемые на основе декомпозиции задачи на подвопросы. Вместо прямого решения сложной проблемы, решатель получает возможность последовательно анализировать и отвечать на более простые, структурированные вопросы, что способствует более точному и эффективному поиску решения. Такая стратегия позволяет избегать ошибок, возникающих при попытке сразу охватить всю сложность задачи, и оптимизировать процесс рассуждений, что, в конечном итоге, ведет к повышению общей производительности и точности получаемых результатов. Эффективное использование подвопросов не только упрощает задачу для решателя, но и позволяет ему лучше понимать логику и взаимосвязи внутри проблемы, что особенно важно для сложных и многогранных задач.
Исследование демонстрирует существенное повышение способности больших языковых моделей (LLM) к обобщению при решении сложных задач, благодаря сочетанию подхода Answer-Driven Decomposition (A2D) и функции потерь In-Context Distillation Loss (IDL). В ходе экспериментов данная комбинация последовательно превосходит альтернативные методы, основанные на Supervised Fine-Tuning (SFT) и Reinforcement Learning from Verbal Rewards (RLVR). Результаты показывают, что A2D, направляя процесс рассуждений, в сочетании с IDL, корректирующим поведение модели на основе промежуточных вопросов, позволяет LLM более эффективно решать новые, ранее не встречавшиеся задачи, требующие комбинирования различных навыков и знаний. Такой подход открывает перспективы для создания более надежных и универсальных систем искусственного интеллекта, способных к адаптации и обучению в динамичной среде.
Предложенный подход к декомпозиции сложных задач на подвопросы, как в A2D, не является чем-то принципиально новым. История знает множество попыток упростить сложные системы. Однако, здесь акцент сделан на обучение модели разбивать проблему, а не на заранее заданные правила. Это напоминает известную фразу Линуса Торвальдса: «Плохой код подобен раку, он развивается и захватывает систему». Если не контролировать процесс декомпозиции, можно получить множество мелких, слабо связанных частей, которые в итоге окажутся сложнее исходного монолита. Авторы, по сути, пытаются создать механизм, который позволит модели самостоятельно «вырезать рак» прежде, чем он распространится, используя обучение с подкреплением и проверяемые награды для направления процесса.
Что Дальше?
Предложенный подход к декомпозиции задач, безусловно, добавляет ещё один уровень сложности в и без того непростой процесс обучения больших языковых моделей с подкреплением. Однако, стоит помнить, что каждая элегантная схема рано или поздно встретится с реальностью — с неструктурированными данными, с противоречивыми сигналами и с неизбежным желанием продакшена сломать всё, что работает в лаборатории. Очевидно, что декомпозиция — это не панацея, а лишь ещё один способ отложить неизбежный технический долг.
Вопрос в том, как сделать эту декомпозицию устойчивой к «шуму» реального мира. Будет ли достаточно тонкой настройки под конкретные задачи, или потребуется принципиально новый подход к представлению знаний, способный адаптироваться к непредсказуемым ситуациям? Вероятно, следующая волна исследований будет направлена на разработку систем, способных не только разбивать задачу на подзадачи, но и оценивать их качество и при необходимости перестраивать процесс декомпозиции «на лету».
И, конечно, нельзя забывать о вечном вопросе масштабируемости. Эффективность A2D может быть ограничена вычислительными ресурсами, необходимыми для обучения и развертывания. Поэтому, параллельно с разработкой новых алгоритмов, необходимо искать способы оптимизации существующих и снижения требований к аппаратному обеспечению. В конце концов, даже самая гениальная идея бесполезна, если её невозможно реализовать на практике.
Оригинал статьи: https://arxiv.org/pdf/2602.00759.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовый оптимизатор: Новый подход к сложным задачам
- Кванты в Финансах: Не Шутка!
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый скачок из Андхра-Прадеш: что это значит?
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Искусственный интеллект на допросе: как объяснить решения в цифровой криминалистике?
2026-02-03 10:53