Автор: Денис Аветисян
Новый подход позволяет направлять логические рассуждения больших языковых моделей, повышая точность и эффективность их работы.

В статье представлена методика CREST, позволяющая управлять ‘когнитивными головами’ в механизмах внимания больших языковых моделей без дополнительного обучения.
Несмотря на впечатляющие возможности больших языковых моделей (LLM) в решении сложных задач, их рассуждения часто характеризуются избыточностью и нестабильностью. В работе ‘Understanding and Steering the Cognitive Behaviors of Reasoning Models at Test-Time’ исследуется структура этих траекторий рассуждений и выявлены специализированные «когнитивные головы» в механизмах внимания, коррелирующие с различными когнитивными стратегиями. Предложен метод CREST, позволяющий управлять процессом рассуждений без дополнительного обучения путем модуляции активности этих голов, что приводит к повышению точности и снижению вычислительных затрат. Возможно ли дальнейшее развитие этого подхода для создания более эффективных и надежных систем искусственного интеллекта, способных к гибкому и адаптивному мышлению?
Рассуждения в Больших Языковых Моделях: Узкое Место
Несмотря на впечатляющий масштаб и объём данных, используемых для обучения, большие языковые модели (БЯМ) зачастую демонстрируют трудности при решении сложных задач, требующих многоступенчатого рассуждения. Их способность к логическим выводам, в отличие от простого воспроизведения заученных паттернов, остаётся ограниченной. Даже при кажущейся убедительности ответов, БЯМ могут допускать ошибки в задачах, требующих последовательного применения логических правил или анализа взаимосвязей между различными фактами. Это особенно заметно в ситуациях, когда необходимо выполнить несколько шагов для достижения решения, или когда требуется учитывать контекст и делать обоснованные предположения.
Несмотря на впечатляющий прогресс в увеличении масштаба языковых моделей, попытки улучшить их способность к рассуждению путём простого наращивания количества параметров демонстрируют всё более слабую отдачу. Увеличение размера модели требует экспоненциального роста вычислительных ресурсов и энергопотребления, что делает этот подход не только экономически невыгодным, но и экологически проблематичным. Дальнейшее увеличение масштаба перестает приносить существенные улучшения в решении сложных задач, требующих последовательного логического мышления, и вместо этого приводит к ситуации, когда модель запоминает больше фактов, не улучшая при этом способность к обобщению и анализу информации. Таким образом, становится очевидным, что для достижения качественного прорыва в области искусственного интеллекта необходимо искать альтернативные подходы, фокусирующиеся не на объеме данных, а на эффективности алгоритмов и архитектуре моделей.
Суть проблемы больших языковых моделей заключается не столько в объеме накопленных знаний, сколько в способе их обработки для достижения логических выводов. Исследования показывают, что даже модели, обладающие огромным количеством информации, могут испытывать трудности с многоступенчатым рассуждением, поскольку их внутренняя архитектура не всегда способствует последовательному и структурированному анализу данных. Вместо простого запоминания фактов, необходим механизм, позволяющий модели выделять ключевые элементы, выстраивать причинно-следственные связи и делать обоснованные заключения, подобно тому, как это делает человеческий разум. Таким образом, ключевым направлением развития является не увеличение масштаба, а совершенствование алгоритмов обработки информации, что позволит моделям не просто отвечать на вопросы, а действительно понимать и рассуждать.

Цепочка Мыслей: Шаг к Структурированным Рассуждениям
Метод рассуждений “Цепочка мыслей” (Chain-of-Thought, CoT) представляет собой подход, при котором большие языковые модели (LLM) стимулируются к явной генерации промежуточных шагов рассуждений при решении задач. В отличие от прямого предсказания ответа, CoT побуждает модель последовательно излагать логические шаги, приводящие к конечному решению. Это достигается путем включения в запрос примеров, демонстрирующих не только входные данные и выходные результаты, но и промежуточные этапы логического вывода. Такая стратегия позволяет LLM использовать свои внутренние возможности для моделирования последовательного решения проблем, подобно тому, как это делает человек.
Метод «Цепочка рассуждений» (Chain-of-Thought, CoT) использует встроенные возможности больших языковых моделей (LLM) для имитации последовательного решения задач, подобного человеческому мышлению. Вместо прямого предоставления ответа, модель генерирует промежуточные шаги рассуждений, демонстрируя логическую цепочку, ведущую к конечному результату. Это достигается путем формулировки запроса, побуждающего модель явно излагать свои рассуждения, что позволяет ей задействовать знания, полученные в процессе обучения, и применять их к новым задачам в структурированном формате, приближенном к человеческому процессу анализа и принятия решений.
Несмотря на перспективность, методика “Chain-of-Thought” (CoT) имеет ряд ограничений. Эффективность CoT существенно зависит от качества и структуры промпта; незначительные изменения в формулировке запроса могут приводить к заметному снижению точности результатов. Кроме того, LLM, использующие CoT, могут генерировать избыточные или нерелевантные промежуточные шаги рассуждений, что увеличивает вычислительные затраты и не всегда способствует повышению качества конечного ответа. Анализ показывает, что модели склонны к повторению одних и тех же логических операций или включению информации, не влияющей на решение задачи.
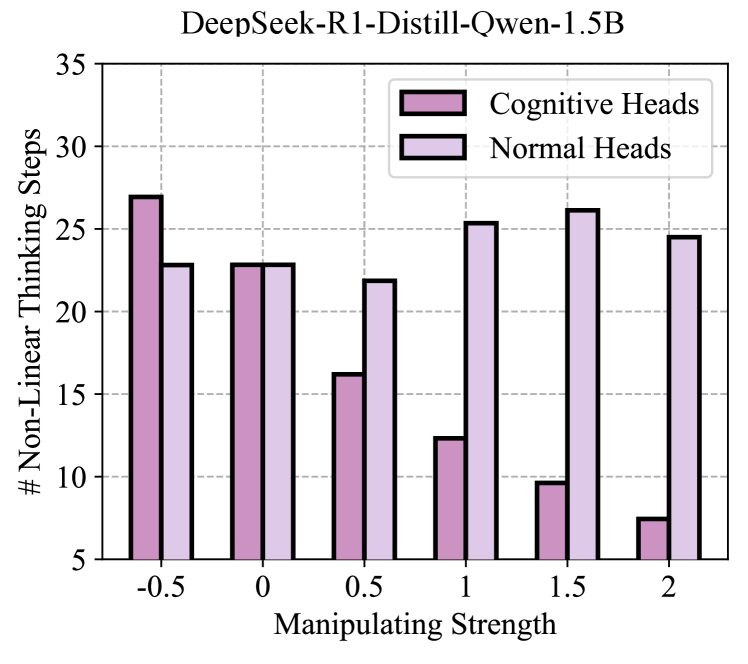
Когнитивные Головы: Декодирование Рассуждений в Нейронных Сетях
Недавние исследования выявили наличие специфических “Когнитивных Голов” внутри механизмов внимания (Attention Heads) в нейронных сетях. Эти головы демонстрируют высокую предсказуемость различных типов рассуждений, таких как логическое выведение, причинно-следственный анализ и пространственное мышление. Анализ активации этих голов показал, что отдельные из них специализируются на обработке информации, релевантной для конкретных когнитивных навыков. Например, определенные головы могут демонстрировать повышенную активность при решении задач, требующих понимания временных последовательностей, в то время как другие — при анализе логических противоречий. Это указывает на модульную организацию процессов рассуждения внутри модели, где различные аспекты когнитивной деятельности обрабатываются специализированными подкомпонентами.
Исследования показывают, что отдельные «когнитивные головы» внутри механизмов внимания нейронных сетей демонстрируют специализацию в обработке информации, необходимой для выполнения конкретных типов логических рассуждений. Это предполагает модульную организацию процессов рассуждения внутри модели, где различные подкомпоненты отвечают за отдельные когнитивные функции. Наблюдаемая специализация не является универсальной, а зависит от типа решаемой задачи, что указывает на динамическое распределение ресурсов в зависимости от контекста. Выделенные когнитивные головы, проявляя активность при решении задач определенного типа, демонстрируют более низкую активность при решении задач, требующих иного типа рассуждений.
Методы пониженного ранга проекции (Low-Rank Projection) позволяют эффективно фильтровать шум и усиливать сигналы от критически важных ‘Когнитивных Голов’ (Cognitive Heads) в нейронных сетях. Данные методы основаны на снижении размерности представления данных, сохраняя при этом наиболее значимые компоненты, отвечающие за определенные типы рассуждений. Применение пониженной ранга проекции позволяет выделить и усилить специфические паттерны активации, связанные с конкретными когнитивными способностями модели, что приводит к повышению точности и эффективности выполнения задач, требующих рассуждений, например, математических вычислений или логических умозаключений. Экспериментальные результаты демонстрируют, что такая фильтрация шума и усиление сигнала улучшают общую производительность модели в задачах, требующих сложных когнитивных процессов.

CREST: Динамическая Коррекция Рассуждений с Помощью Интервенции Активацией
CREST (Cognitive Reasoning Enhancement through Scaling and Targeting) представляет собой фреймворк, не требующий обучения, который динамически корректирует поведение модели при рассуждениях. В основе CREST лежит использование так называемых «Cognitive Heads» — дополнительных модулей, которые позволяют выборочно активировать или подавлять определенные аспекты процесса рассуждений. Это достигается путем масштабирования влияния отдельных Cognitive Heads в процессе инференса, позволяя модели фокусироваться на наиболее релевантных сигналах и избегать излишних вычислений. В отличие от традиционных подходов, требующих переобучения модели для каждой конкретной задачи, CREST функционирует без дополнительной настройки, обеспечивая адаптацию процесса рассуждений «на лету».
В рамках CREST (Cognitive Reasoning Enhancement through Scaling and Targeting) происходит динамическая корректировка процесса рассуждений посредством селективной активации или подавления отдельных «когнитивных голов» (Cognitive Heads) во время инференса. Данный механизм позволяет усилить сигналы, релевантные для текущей задачи, и одновременно снизить вычислительные затраты, связанные с неактуальными или избыточными операциями. По сути, CREST фокусирует вычислительные ресурсы на наиболее важных аспектах решения, игнорируя менее значимые, что повышает эффективность и скорость рассуждений без необходимости переобучения модели для каждой конкретной задачи.
Методика CREST демонстрирует существенное снижение потребления токенов и повышение эффективности рассуждений. В ходе экспериментов на наборе данных AMC23 с моделью R1-1.5B зафиксировано улучшение точности решения задач на 17.50% и сокращение использования токенов до 37.60%. Важно отметить, что данное повышение производительности достигается без какой-либо специализированной переподготовки модели для конкретных задач, что делает подход особенно привлекательным для практического применения.

За Пределами CREST: Исследуя Адаптивные и Эффективные Рассуждения
Для повышения эффективности и адаптивности языковых моделей применяются различные подходы, такие как стратегии раннего выхода, адаптивное управление вычислениями и прямое манипулирование трассировкой. Стратегии раннего выхода позволяют модели прекратить вычисления, как только достигнут достаточный уровень уверенности в ответе, избегая излишней траты ресурсов. Адаптивное управление вычислениями динамически регулирует объем вычислений в зависимости от сложности задачи, направляя ресурсы на наиболее важные этапы рассуждений. Прямое манипулирование трассировкой, в свою очередь, позволяет модели анализировать и корректировать ход своих рассуждений, повышая точность и надежность получаемых результатов. Сочетание этих методов открывает перспективы для создания более эффективных и гибких языковых моделей, способных решать сложные задачи с минимальными затратами ресурсов.
Современные методы оптимизации больших языковых моделей направлены на существенное сокращение вычислительных затрат за счет фокусировки ресурсов на наиболее важных этапах рассуждений. Вместо выполнения всех операций, алгоритмы, такие как стратегии раннего выхода и адаптивное управление вычислениями, позволяют модели динамически определять, когда достигнут достаточный уровень уверенности в ответе, и прекращать дальнейшую обработку. Это достигается путем анализа промежуточных результатов и оценки их значимости для конечного решения. Подобный подход не только снижает потребление энергии и время отклика, но и способствует повышению прозрачности процесса принятия решений, позволяя лучше понимать, какие аспекты задачи оказали наибольшее влияние на результат.
Исследования показали, что методика CREST демонстрирует значительные успехи в повышении эффективности и точности языковых моделей. На тестовом наборе AIME22-24 модель, использующая CREST с R1-7B, достигла точности в 63.0% при одновременном снижении использования токенов на 30.8%. Более того, при применении к LiveCodeBench с Qwen3-30B, CREST обеспечивает точность в 73.1%. Эти результаты указывают на перспективность объединения различных подходов к адаптивному рассуждению, что открывает путь к созданию языковых моделей, способных решать сложные задачи не только эффективно, но и прозрачно, что имеет огромный потенциал для применения в областях планирования и принятия решений.
Исследование, представленное в данной работе, демонстрирует изящную простоту в решении сложной задачи — управления когнитивными процессами больших языковых моделей. Авторы предлагают метод CREST, позволяющий направлять ход рассуждений модели, идентифицируя и модулируя так называемые ‘когнитивные головы’ во внимательных механизмах. Как заметил Роберт Тарьян: «Алгоритмы должны быть красивыми, а не сложными». Эта фраза отражает суть подхода, представленного в статье: вместо добавления сложности, авторы стремятся к очищению и оптимизации существующих механизмов, добиваясь повышения точности и снижения потребления токенов. Удаление избыточного, как подчеркивают исследователи, позволяет выявить истинный смысл и улучшить эффективность модели.
Куда же дальше?
Представленная работа, манипулируя вниманием моделей как сложным, но всё же механическим устройством, демонстрирует возможность направленного воздействия на процесс рассуждений. Однако, кажущаяся простота метода CREST — лишь маскировка более глубокой сложности. Поиск «когнитивных голов» — это, по сути, попытка навести порядок в хаосе параметров, но остаётся открытым вопрос о стабильности и обобщающей способности таких «настроек». Не является ли это лишь очередным примером тонкой настройки, привязанной к конкретному набору данных и задачам?
Будущие исследования должны сосредоточиться на преодолении этой хрупкости. Необходимо разработать метрики, позволяющие оценивать «когнитивный профиль» модели независимо от конкретной задачи, и методы, гарантирующие сохранение этого профиля при обучении и адаптации. Иначе, всё это рискует превратиться в бесконечную гонку за локальными улучшениями, игнорируя фундаментальные принципы когнитивной архитектуры.
В конечном счете, задача состоит не в том, чтобы заставить модель «думать» как человек, а в том, чтобы создать систему, способную эффективно решать задачи, минимизируя при этом избыточность и сложность. И в этом смысле, поиск «лишнего» — это, пожалуй, наиболее плодотворная линия исследований.
Оригинал статьи: https://arxiv.org/pdf/2512.24574.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Квантовые нейросети на службе нефтегазовых месторождений
- Квантовые симуляторы: точное вычисление энергии основного состояния
- Квантовые вычисления: от шифрования армагеддона до диверсантов космических лучей — что дальше?
- Функциональные поля и модули Дринфельда: новый взгляд на арифметику
- Миллиардные обещания, квантовые миражи и фотонные пончики: кто реально рулит новым золотым веком физики?
- Метаболический профиль СДВГ: новый взгляд на диагностику
- Квантовая криптография: от теории к практике
- Робот, который видит, понимает и действует: новая эра общего назначения
2026-01-05 01:33