Автор: Денис Аветисян
Новый подход позволяет значительно улучшить диагностику на основе данных с датчиков, используя возможности больших языковых моделей и специализированных алгоритмов анализа временных рядов.

Представлен SenTSR-Bench — фреймворк для инъекции знаний, повышающий точность диагностического рассуждения при работе с данными временных рядов.
Диагностика временных рядов требует как глубокого понимания предметной области, так и способности к логическим рассуждениям, что представляет собой сложную задачу для современных систем. В работе ‘SenTSR-Bench: Thinking with Injected Knowledge for Time-Series Reasoning’ предложен гибридный подход, сочетающий в себе сильные стороны больших языковых моделей (LLM) в области рассуждений и специализированные модели временных рядов (TSLM) для инъекции экспертных знаний. Такой подход позволяет значительно повысить точность диагностики временных рядов, превосходя существующие решения на 7.9-26.1% на реальных промышленных данных, представленных в новом бенчмарке SenTSR-Bench. Сможем ли мы, используя подобные методы, создать интеллектуальные системы, способные эффективно анализировать сложные временные данные и принимать обоснованные решения в различных областях?
Пределы Общего Рассуждения во Временных Рядах
Несмотря на впечатляющие возможности в решении широкого спектра задач, современные языковые модели общего назначения (GRLM) часто демонстрируют недостаток детального понимания при анализе сложных временных рядов. Эти модели, обученные на обширных текстовых данных, могут успешно оперировать абстрактными понятиями, однако им свойственна сложность в интерпретации специфических закономерностей, присущих динамическим данным. В частности, GRLM испытывают трудности с выявлением тонких корреляций, сезонных колебаний и аномалий, которые требуют глубокого понимания контекста и предметной области. Это ограничивает их применимость в критически важных областях, таких как финансовый анализ, прогнозирование погоды и диагностика неисправностей, где точность и надежность прогнозов имеют первостепенное значение.
Основная сложность заключается в эффективной интеграции специализированных знаний в процесс рассуждений мощных, но агностических моделей. Эти модели, хоть и демонстрируют впечатляющие способности в решении общих задач, зачастую не обладают глубоким пониманием конкретных областей, таких как анализ временных рядов. В результате, без учета отраслевых особенностей и специфических закономерностей, их выводы могут оказаться неточными или даже ошибочными. Успешное внедрение доменных знаний требует разработки новых методов, позволяющих моделям не просто обрабатывать данные, но и интерпретировать их в контексте конкретной предметной области, учитывая причинно-следственные связи и потенциальные аномалии, характерные для данной области.
Отсутствие интеграции специализированных знаний в процесс рассуждений больших языковых моделей общего назначения (GRLM) приводит к трудностям в анализе временных рядов данных. Модели, не учитывающие специфику конкретной области, могут упускать из виду тонкие, но критически важные закономерности и взаимосвязи, присущие временным данным. Это, в свою очередь, ведет к неточным диагнозам, ошибочным прогнозам и, как следствие, к снижению эффективности принимаемых решений. Например, при анализе медицинских данных временных рядов, таких как ЭКГ или ЭЭГ, модели без соответствующей подготовки могут неправильно интерпретировать незначительные отклонения, что может привести к ложным тревогам или, что еще хуже, к упущению реальной патологии. Таким образом, учет предметной области становится необходимым условием для надежной работы GRLM с временными рядами.
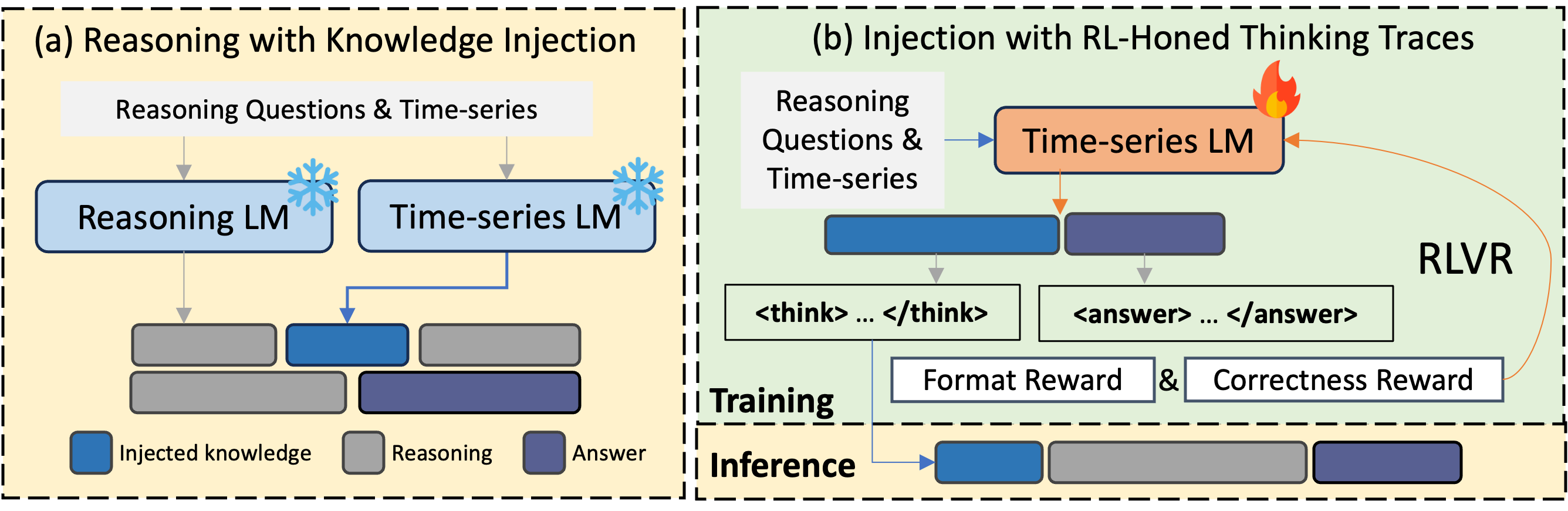
Объединение Знаний: Рассуждения с Инъекцией Экспертизы
Предложенный подход основывается на фреймворке “Рассуждения с Инъекцией Знаний”, объединяющем преимущества графовых языковых моделей (GRLM) и моделей временных рядов (TSLM). GRLM обеспечивают структурированное представление данных и возможность логических выводов, в то время как TSLM специализируются на анализе и прогнозировании временных зависимостей. Фреймворк позволяет использовать сильные стороны обеих моделей, эффективно интегрируя знания, полученные из TSLM, в процесс рассуждений GRLM для повышения точности и эффективности при решении задач, связанных с временными рядами. Интеграция осуществляется посредством механизмов, позволяющих адаптировать способ передачи знаний в зависимости от конкретных требований задачи.
Предлагаемый фреймворк обеспечивает гибкую интеграцию знаний посредством трех методов: раннее (Early), промежуточное (Intermediate) и позднее (Late) внедрение. Раннее внедрение предполагает передачу знаний в GRLM до начала процесса рассуждений, что может быть полезно для задач, требующих предварительной настройки контекста. Промежуточное внедрение происходит в процессе рассуждений, позволяя TSLM корректировать ход логических выводов GRLM на основе текущих данных. Позднее внедрение используется для постобработки результатов GRLM, корректируя окончательные выводы на основе экспертных знаний, полученных от TSLM. Выбор метода внедрения зависит от специфики задачи и необходимого уровня контроля над процессом рассуждений.
Стратегическое внедрение выводов, полученных от моделей временных рядов (TSLM), позволяет направлять процесс рассуждений больших языковых моделей (GRLM) при решении задач, связанных с временными рядами. Этот подход заключается в использовании информации, извлеченной из TSLM, для корректировки или дополнения логических шагов, выполняемых GRLM. Внедрение осуществляется на различных этапах рассуждений, что позволяет повысить точность и эффективность GRLM в задачах прогнозирования, классификации и анализа временных рядов. Оптимальное использование TSLM-инсайтов позволяет GRLM избегать ошибок, связанных с недостаточным пониманием временных зависимостей, и более эффективно использовать имеющиеся данные.

Обучение Моделей Временных Рядов для Эффективного Рассуждения
Мы представляем подход ‘Обучение с подкреплением для передачи рассуждений’ (RL-based Thinking Transfer), основанный на обучении языковых моделей временных рядов (TSLM) с использованием методов обучения с подкреплением. Этот подход направлен на проактивную генерацию TSLM следов рассуждений, то есть последовательностей логических шагов, ведущих к решению задачи. В процессе обучения модель получает сигналы подкрепления, которые формируют её способность предвидеть и генерировать полезные шаги рассуждений, а не просто предоставлять данные. Данный метод позволяет TSLM активно участвовать в процессе решения задачи, формируя последовательность рассуждений, прежде чем предоставить окончательный ответ.
В рамках используемой методики, обучение языковой модели временных рядов (TSLM) осуществляется посредством системы вознаграждений, основанных на верифицируемых данных. Вознаграждение начисляется за генерацию анализа, предшествующего фактическому ответу, что стимулирует модель к формированию логической цепочки рассуждений. Такая система позволяет оптимизировать вклад TSLM в общий процесс рассуждений, направляя ее на активное участие в анализе данных и предоставлении обоснованных выводов, а не просто на выдачу информации. Ключевым аспектом является проверка каждого этапа анализа, что обеспечивает достоверность и надежность генерируемых рассуждений.
Предварительное обучение языковой модели временных рядов (TSLM) направлено на обеспечение её активного участия в процессе рассуждений, а не просто предоставления данных. Этот подход позволяет TSLM формировать и предлагать промежуточные шаги анализа, что оптимизирует её вклад в общую логическую цепочку. В результате, повышается эффективность всей системы рассуждений, поскольку TSLM становится не пассивным источником информации, а активным участником, способствующим более глубокому и обоснованному анализу.
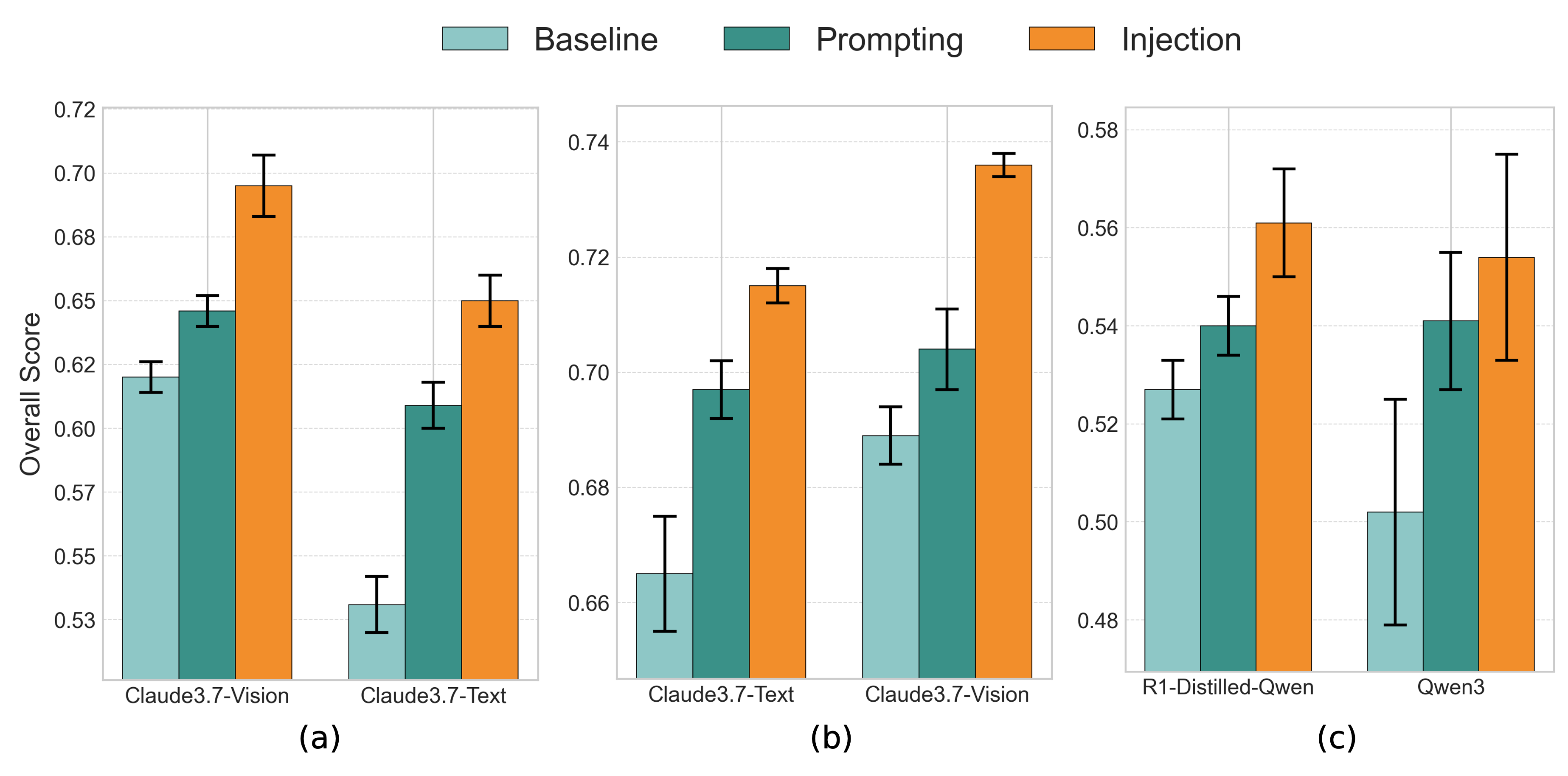
Валидация и Влияние: Бенчмарк SenTSR-Bench
Представлен SenTSR-Bench — новый эталон для оценки систем диагностического рассуждения на основе временных рядов. Этот эталон состоит из реальных многомерных данных, полученных от различных датчиков, и тщательно проверенных вручную аннотаций, что обеспечивает высокую достоверность и надежность оценки. SenTSR-Bench специально разработан для того, чтобы стать серьезным испытанием для существующих и будущих систем, выявляя их сильные и слабые стороны в решении сложных задач диагностирования. В отличие от синтетических данных, используемых в большинстве существующих эталонов, SenTSR-Bench отражает реальные условия эксплуатации и предоставляет более реалистичную картину производительности систем в практических приложениях. Он позволяет исследователям не только сравнивать различные подходы, но и стимулировать разработку более robustных и эффективных алгоритмов диагностического рассуждения.
Представленный SenTSR-Bench выступает в роли унифицированной платформы для оценки эффективности различных подходов к диагностике временных рядов. Этот инструмент позволяет проводить объективные сопоставления между различными методами, предоставляя исследователям возможность точно измерить прогресс и выявить наиболее перспективные направления развития. Стандартизация процесса оценки, обеспечиваемая SenTSR-Bench, способствует ускорению инноваций в области анализа сенсорных данных, поскольку позволяет четко определять преимущества и недостатки каждой стратегии, стимулируя разработку более совершенных и надежных систем диагностики. Благодаря унифицированному формату данных и четким критериям оценки, SenTSR-Bench значительно упрощает процесс сравнения и валидации новых алгоритмов, способствуя более быстрому внедрению передовых технологий в практические приложения.
Представленная система, в сочетании с методом передачи рассуждений на основе обучения с подкреплением (RL), демонстрирует значительное превосходство над существующими подходами при тестировании на SenTSR-Bench. Достигнуты улучшения в точности от 7.9% до 26.1%, что подтверждает потенциал разработки практических приложений в области диагностики на основе данных с датчиков. Кроме того, усовершенствованный метод внедрения, использующий обучение с подкреплением, обеспечивает прирост производительности в диапазоне от 1.66x до 2.92x по сравнению с методами, основанными на обучении с учителем (SFT), что свидетельствует о высокой эффективности предложенного подхода к решению задач диагностического анализа.
Масштабирование к Длинным Временным Рядам: Роль RoPE
Для эффективной обработки временных рядов, характеризующихся зависимостями на больших расстояниях, в архитектуре GRLM используется масштабирование RoPE (Rotary Positional Embedding). Данная техника позволяет расширить контекстное окно модели, обеспечивая возможность анализа значительно более длинных последовательностей данных без существенной потери производительности. RoPE Scaling, изменяя способ кодирования позиционной информации, позволяет модели лучше улавливать взаимосвязи между отдаленными точками во времени, что критически важно для задач, требующих понимания долгосрочных трендов и закономерностей. В результате, модель способна более точно прогнозировать будущие значения и выявлять аномалии даже в сложных и зашумленных временных рядах.
В архитектуре GRLM применяется метод масштабирования RoPE, позволяющий значительно расширить длину контекста обработки временных рядов. Данная техника эффективно решает проблему обработки длинных последовательностей данных без ухудшения производительности модели. Традиционно, увеличение длины контекста приводит к экспоненциальному росту вычислительных затрат и снижению точности, однако RoPE Scaling позволяет избежать этого, сохраняя эффективность даже при анализе очень протяженных временных рядов. Это открывает возможности для применения модели к задачам, требующим учета долгосрочных зависимостей в данных, таким как прогнозирование и выявление аномалий в сложных системах.
Возможность масштабирования архитектуры позволяет применять разработанный подход к решению сложных задач анализа временных рядов, в частности, к задачам предиктивной аналитики технического обслуживания и обнаружению аномалий. Проведенные исследования показали значительное повышение точности по сравнению со специализированными моделями: на наборе данных TSEvol достигнута прирост точности в диапазоне от 5.2% до 10.4%, а на TS&Language Benchmark — от 2.7% до 10.4%. Эти результаты демонстрируют потенциал системы для эффективной обработки и анализа длительных временных рядов, открывая новые возможности для прогнозирования и выявления критических изменений в различных областях применения.

Представленное исследование демонстрирует стремление к математической чистоте в области анализа временных рядов. Авторы, подобно опытным архитекторам, интегрируют мощь больших языковых моделей с узкоспециализированными экспертными системами, что позволяет достичь более высокой точности диагностического рассуждения на реальных данных с датчиков. Как отметил Винтон Серф: «Интернет — это не только технология, но и способ мышления». В данном контексте, предложенный фреймворк можно рассматривать как способ структурирования знаний и применения их для решения сложных задач, что соответствует стремлению к доказуемости и надежности алгоритмов. Оптимизация, основанная на анализе и интеграции различных подходов, представляется единственным путем к созданию действительно элегантных и эффективных решений в области анализа временных рядов.
Куда же дальше?
Представленная работа, несомненно, демонстрирует потенциал симбиоза больших языковых моделей и специализированных алгоритмов анализа временных рядов. Однако, следует признать, что внедрение знаний — процесс нетривиальный. Текущие подходы, зачастую, полагаются на эвристические методы для представления и интеграции экспертных знаний, что неизбежно вносит погрешности и ограничивает обобщающую способность системы. Истинная элегантность кроется в формализации этих знаний, в их представлении в виде доказуемых утверждений, а не просто «работающих» правил.
Очевидным направлением для дальнейших исследований является разработка методов автоматической верификации внедрённых знаний. Система должна не просто выдавать диагноз, но и предоставлять формальное обоснование своего решения, демонстрируя, каким образом экспертные знания были использованы для получения результата. В противном случае, мы имеем дело с очередной «чёрной коробкой», чьи решения основаны на непрозрачных механизмах.
Кроме того, необходимо исследовать возможность использования более строгих математических моделей для представления временных зависимостей. Полагаться исключительно на статистические корреляции — значит упускать из виду фундаментальные причинно-следственные связи. В конечном счёте, задача анализа временных рядов — это не просто предсказание будущего, но и понимание лежащих в его основе принципов.
Оригинал статьи: https://arxiv.org/pdf/2602.19455.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, планирующий путешествия: новый подход к сложным задачам
- Серебро и медь: новый взгляд на наноаллои
- Разделяй и Властвуй: Новый Подход к Развёртке 3D-Моделей
- Самосознание в обучении: Модель вознаграждения, основанная на самоанализе
- Оживший аватар: Генерация видео в реальном времени по голосу
- Искусственный интеллект: проверка на изобретательность
- Управление языком: новый подход к долгосрочному планированию
- Единый язык материи: как научные модели учатся понимать мир
- Искусственный интеллект: курс для жизни и общества
- Конфиденциальный анализ больших данных: новый подход к быстрым ответам
2026-02-24 11:59