Автор: Денис Аветисян
Исследователи разработали систему, динамически переключающуюся между различными способами рассуждений для повышения эффективности и точности больших языковых моделей.
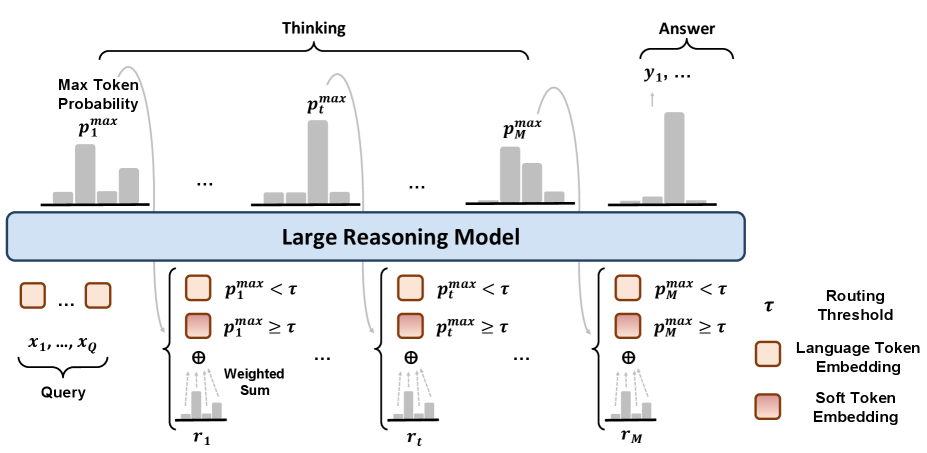
ThinkRouter — механизм уверенного выбора пути между скрытым и дискретным пространствами рассуждений, позволяющий оптимизировать процесс логического вывода.
Несмотря на успехи в области латентного рассуждения, эффективность больших языковых моделей (LLM) в сложных задачах остаётся переменчивой. В данной работе, представленной под названием ‘ThinkRouter: Efficient Reasoning via Routing Thinking between Latent and Discrete Spaces’, исследуется динамическое переключение между дискретным и латентным пространствами рассуждений, управляемое уверенностью модели. Предложенный механизм ThinkRouter позволяет повысить точность и эффективность LLM, избегая распространения шума и калибруя ошибки, возникающие при использовании как явного CoT, так и латентного рассуждения. Возможно ли дальнейшее совершенствование гибридных стратегий рассуждений для достижения ещё более высокой надежности и скорости работы LLM?
Пределы Дискретного Мышления
Современные большие языковые модели, такие как Qwen3 и gpt-oss, демонстрируют впечатляющие результаты в решении широкого спектра задач, однако их возможности ограничены при выполнении сложных, многоступенчатых рассуждений. Эта сложность обусловлена принципом дискретной обработки информации — модели оперируют отдельными токенами, что затрудняет удержание и анализ взаимосвязей между различными этапами логической цепочки. В отличие от человеческого мышления, способного к непрерывному и ассоциативному восприятию информации, модели вынуждены последовательно обрабатывать каждый токен, что приводит к потере контекста и увеличению вычислительных затрат при решении задач, требующих глубокого анализа и синтеза информации. Данное ограничение становится особенно заметным при работе с большими объемами данных и сложными логическими конструкциями, что подчеркивает необходимость поиска новых подходов к организации процесса рассуждений в искусственном интеллекте.
Несмотря на постоянное увеличение масштаба языковых моделей, таких как Qwen3 и gpt-oss, наблюдается закономерное снижение эффективности прироста производительности. Увеличение количества параметров и обучающих данных уже не приводит к пропорциональному улучшению способности к сложному многоступенчатому рассуждению. Это указывает на фундаментальные ограничения текущего подхода, основанного на дискретном представлении информации. В связи с этим, всё более актуальной становится необходимость разработки принципиально новых парадигм рассуждений, которые позволят достичь более высокой эффективности и преодолеть ограничения, связанные с масштабированием существующих моделей. Исследования направлены на поиск альтернативных методов, способных обеспечить более компактное и эффективное представление знаний, а также более гибкие и мощные механизмы логического вывода.
Традиционные методы решения сложных задач, основанные на последовательной обработке дискретных данных, зачастую оказываются чрезмерно затратными с точки зрения вычислительных ресурсов. Несмотря на значительное увеличение мощности современных вычислительных систем, способность алгоритмов имитировать гибкость и интуицию человеческого мышления остаётся ограниченной. Существующие подходы, как правило, испытывают трудности с улавливанием тонких связей и контекстуальных нюансов, необходимых для эффективного решения многоступенчатых задач. В связи с этим, исследователи активно изучают альтернативные парадигмы, направленные на разработку более экономичных и приближенных к человеческому разуму методов рассуждений, включая нейро-символьные системы и подходы, основанные на непрерывном представлении знаний.
Латентные Рассуждения: Новый Взгляд на Мышление
Латентное рассуждение представляет собой перспективное решение, отходящее от представления мыслей в виде дискретных токенов. Вместо этого, оно использует непрерывные, сжатые векторы для кодирования мыслительных процессов. Такой подход позволяет существенно повысить эффективность обработки информации, поскольку уменьшается объем данных, необходимых для представления и манипулирования мыслями. Более того, представление мыслей в виде непрерывных векторов открывает возможности для более глубокого анализа и выявления взаимосвязей, недоступных при работе с дискретными символами, что потенциально приводит к более сложным и эффективным алгоритмам рассуждений.
Методы, такие как Coconut, CCoT (Chain-of-Thought with Compression) и LightThinker, реализуют различные подходы к построению латентных представлений из дискретных цепочек рассуждений. Coconut использует механизм “коко-кодирования” для сжатия промежуточных мыслей в векторное пространство, позволяя модели более эффективно использовать информацию из предыдущих шагов. CCoT фокусируется на сжатии длинных цепочек рассуждений путем выделения наиболее важных шагов и их представления в более компактной форме. LightThinker, в свою очередь, использует итеративный процесс “легкого мышления”, где модель постепенно уточняет свое понимание задачи, создавая латентное представление, которое затем используется для генерации ответа. Все эти методы стремятся преобразовать последовательность дискретных токенов, представляющих ход мыслей, в непрерывный вектор, который можно более эффективно обрабатывать и использовать в процессе рассуждений.
Целью методов, таких как Coconut, CCoT и LightThinker, является дистилляция существенной информации из развернутых цепочек рассуждений (chain-of-thought) в более компактный и управляемый формат для больших языковых моделей (LRM). Процесс включает в себя сжатие последовательности дискретных токенов, представляющих этапы логического вывода, в непрерывные векторные представления. Это позволяет снизить вычислительную нагрузку, ускорить обработку и потенциально улучшить способность модели к обобщению и решению сложных задач, требующих многоэтапных рассуждений. Компактное представление также способствует уменьшению объема памяти, необходимого для хранения и обработки информации.
Динамическая Маршрутизация Рассуждений: ThinkRouter
ThinkRouter использует механизм динамической маршрутизации рассуждений во время инференса, переключаясь между дискретным и латентным пространствами. Основой для принятия решения о переключении служит уверенность языковой модели (LLM), определяемая как максимальная вероятность следующего токена (Maximum Next-Token Probability). При высокой уверенности LRM в предсказуемости следующего шага рассуждений, ThinkRouter функционирует в дискретном режиме. В противном случае, когда уверенность LRM низкая, происходит переход в латентное пространство, что позволяет модели исследовать более широкий спектр возможных решений и повысить надежность ответа.
ThinkRouter оптимизирует скорость и точность выполнения сложных задач, требующих рассуждений, за счет динамического переключения между дискретным и латентным режимами работы. В дискретном режиме модель оперирует с четко определенными шагами логических выводов, обеспечивая высокую точность, но потенциально снижая скорость. Латентный режим, напротив, позволяет модели выполнять более быстрые, но менее детализированные рассуждения. Интеллектуальное переключение между этими режимами, основанное на уверенности модели (измеряемой максимальной вероятностью следующего токена), позволяет ThinkRouter эффективно использовать преимущества обоих подходов и повышать общую производительность.
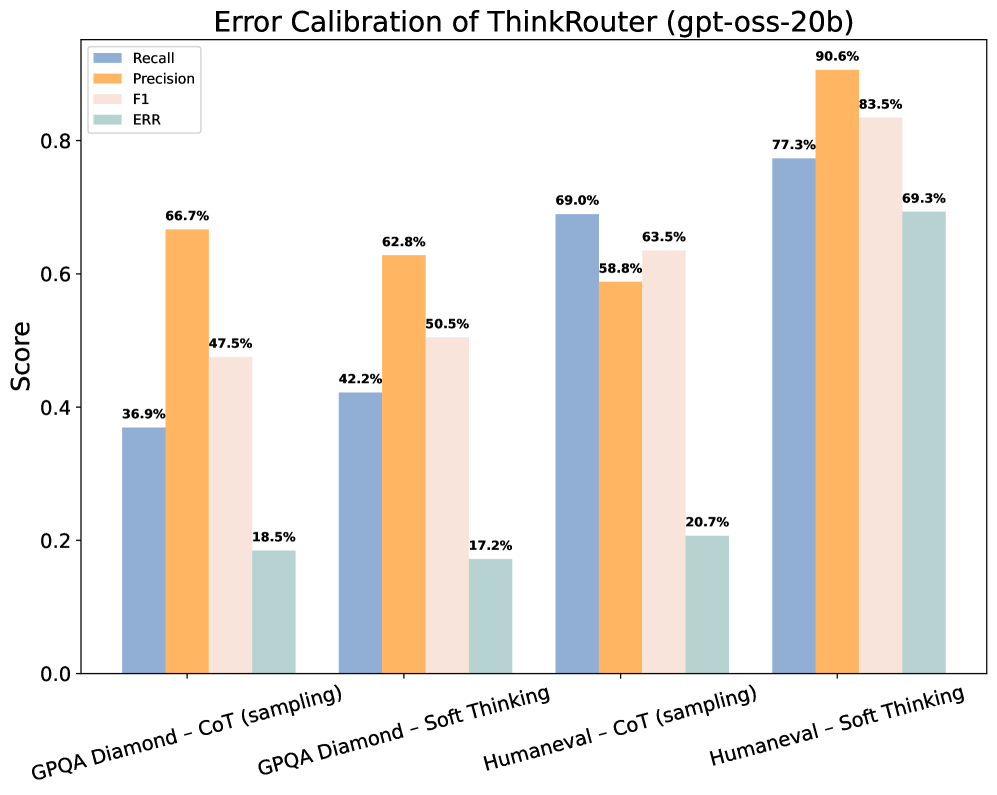
Применение ThinkRouter демонстрирует среднее повышение производительности на 19.70% (Pass@1) при решении сложных задач, оцениваемых на бенчмарках AIME, GPQA Diamond и HumanEval. Данный прирост достигается за счет комбинирования преимуществ дискретного и латентного рассуждений. На различных моделях наблюдается вариация улучшения: от 5.63% для Qwen3-32B до 13.80% для gpt-oss-20b, что подтверждает эффективность подхода для различных архитектур и масштабов языковых моделей.
Уверенность и Контроль: Новый Уровень Мышления
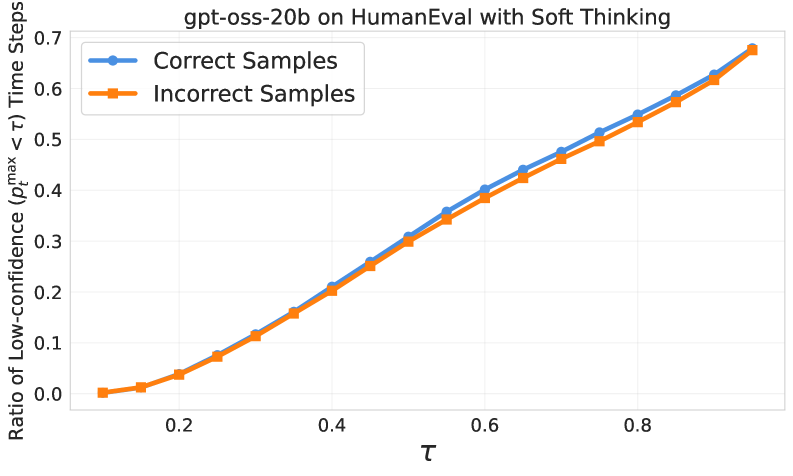
Анализ динамики уверенности, в сочетании с использованием таких метрик, как энтропия, позволяет выявить закономерности в подходах больших языковых моделей (LLM) к решению задач, требующих рассуждений. Исследования показывают, что LLM демонстрируют различные уровни уверенности на разных этапах решения, и эти изменения коррелируют с успехом или неудачей в достижении правильного ответа. В частности, применение системы ThinkRouter оказывает существенное влияние на эти паттерны: она способна модулировать уверенность модели, стимулируя более взвешенный подход к рассуждениям и предотвращая преждевременные, но ошибочные выводы. Изменение динамики уверенности под воздействием ThinkRouter указывает на возможность целенаправленного управления процессом рассуждений, что, в свою очередь, открывает новые перспективы для повышения надежности и эффективности LLM в решении сложных задач.
Механизм «холодной остановки», интегрированный с системой ThinkRouter, позволяет прерывать процесс рассуждений, когда языковая модель демонстрирует чрезмерную уверенность в своих ответах. Эта функция особенно важна для предотвращения бесконечных циклов и неэффективных повторений, которые часто возникают при решении сложных задач. Вместо того чтобы позволить модели неуклонно следовать ошибочному пути с высокой степенью уверенности, «холодная остановка» инициирует переоценку, позволяя ThinkRouter направить модель к более продуктивному направлению. Таким образом, данный механизм не только повышает эффективность решения задач, но и способствует более рациональному и контролируемому процессу рассуждений, приближая поведение модели к человеческому мышлению.
Эффективное управление процессом рассуждений в больших языковых моделях (LLM) открывает не только возможности для повышения их производительности, но и позволяет глубже понять внутренние механизмы, лежащие в основе их способностей. Изучение того, как контролировать этапы логических построений, позволяет выявить закономерности в формировании ответов, а также определить, какие факторы влияют на точность и надежность получаемых результатов. По сути, это приближает исследователей к пониманию “мышления” этих сложных систем, позволяя не просто использовать их, но и создавать более интеллектуальные и предсказуемые модели, способные к более сложному и обоснованному анализу информации. В конечном итоге, контроль над процессом рассуждений становится ключом к раскрытию потенциала LLM и разработке принципиально новых подходов к искусственному интеллекту.
Будущее Эффективных Рассуждений: За Горизонтом
Механизм HRPO развивает концепцию динамического рассуждения, используя обучение с подкреплением (RL) для тренировки управляющего звена, которое определяет, когда переключаться между непрерывным (латентным) и дискретным пространствами. Этот подход позволяет системе адаптировать стратегию рассуждения в зависимости от конкретной задачи, оптимизируя процесс перехода между различными форматами представления информации. В отличие от статических методов, RL позволяет механизму обучения самостоятельно находить оптимальные моменты для активации латентного пространства, что способствует более эффективному обобщению и решению сложных задач, требующих как абстрактного мышления, так и точного анализа данных. Такой адаптивный подход к управлению потоком информации открывает новые возможности для создания более интеллектуальных и гибких систем рассуждения.
Сочетание латентного рассуждения и механизмов управления, обученных с помощью обучения с подкреплением, открывает перспективные возможности для создания более эффективных и устойчивых систем рассуждений. Традиционные подходы часто сталкиваются с трудностями при обработке сложных задач, требующих как обобщения, так и точного анализа. Латентное рассуждение позволяет модели представлять информацию в сжатом, абстрактном виде, что снижает вычислительные затраты и улучшает обобщающую способность. В то же время, обучение с подкреплением оптимизирует процесс переключения между латентным и дискретным представлениями, позволяя системе динамически адаптироваться к различным типам задач и выбирать наиболее подходящий способ рассуждения. Такой симбиоз позволяет преодолеть ограничения каждого из подходов по отдельности, создавая системы, способные решать сложные задачи с высокой точностью и эффективностью, приближая искусственный интеллект к более гибкому и надежному рассуждению.
Перспективы дальнейших исследований сосредоточены на масштабировании представленных методов и их применении к задачам рассуждения, требующим всё большей сложности. Ученые стремятся расширить возможности больших языковых моделей, позволяя им эффективно решать более сложные проблемы и демонстрировать более глубокое понимание. Это предполагает не только увеличение объемов данных для обучения, но и разработку более совершенных алгоритмов, способных адаптироваться к новым задачам и извлекать уроки из ограниченного количества примеров. Особое внимание уделяется созданию систем, способных к самообучению и генерации новых знаний, что позволит им не только решать текущие задачи, но и предвидеть и предотвращать потенциальные проблемы. В конечном итоге, успешное масштабирование этих технологий может привести к созданию искусственного интеллекта, способного к действительно разумному и гибкому рассуждению.
Представленная работа демонстрирует, что эффективность систем искусственного интеллекта не определяется исключительно скоростью вычислений, но и способностью адаптироваться к различным условиям. ThinkRouter, переключаясь между дискретным и латентным пространствами рассуждений, подтверждает идею о том, что архитектура, учитывающая историю и контекст, обладает большей устойчивостью. Как заметил Г.Х. Харди: «Математика — это не просто набор фактов, а гибкий и мощный инструмент для понимания мира». Подобно тому, как математик выбирает наиболее подходящий метод решения задачи, ThinkRouter динамически выбирает пространство рассуждений, оптимизируя процесс и повышая точность. Это подчеркивает важность адаптивности и контекстуальности в построении надежных и эффективных систем.
Что дальше?
Представленный механизм ThinkRouter, безусловно, является очередным коммитом в летопись поиска эффективных стратегий рассуждений для больших языковых моделей. Однако, подобно любой архитектурной инновации, он лишь отодвигает горизонт нерешенных задач. Вопрос не в том, насколько быстро модель переключается между латентным и дискретным пространством, а в том, насколько адекватно она оценивает необходимость этого переключения. Задержка в исправлении этой оценки — неизбежный налог на амбиции создания действительно гибкого интеллекта.
Будущие исследования, вероятно, сосредоточатся на разработке более точных метрик уверенности, способных предсказывать не только вероятность ошибки, но и тип этой ошибки. Потребуется детальное изучение взаимодействия между латентным представлением и дискретными шагами рассуждений, чтобы понять, как избежать «зацикливания» или «потери контекста». Каждая версия ThinkRouter — это глава, но вся книга еще далека от завершения.
В конечном счете, ценность подобных подходов измеряется не только в повышении эффективности, но и в приближении к пониманию того, как вообще возможно наделение машины способностью к достоинному старению — то есть к адаптации к меняющимся условиям и коррекции собственных ошибок. Время — не метрика, а среда, в которой функционируют эти системы, и лишь время покажет, какие коммиты окажутся по-настоящему значимыми.
Оригинал статьи: https://arxiv.org/pdf/2602.11683.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Самообучающиеся агенты: извлечение навыков из открытого кода
- Разумные языковые модели: новый подход к логическому мышлению
- Понимание ориентации объектов: новый взгляд на 3D-пространство
- Визуализация науки: новый виток сотрудничества человека и ИИ
- Быстрая оценка эффективности клинических испытаний: новый подход
- Как заставить языковые модели говорить правду?
- Быстрый поиск по геному: Новые алгоритмы для spaced k-mers
- Искусственный интеллект на службе правосудия: моделируя вопросы в судебных дебатах
- Взрыв скорости: Оптимизация внимания для современных GPU
- Ребусы для ИИ: новый масштабный тест на сообразительность
2026-02-13 20:07