Автор: Денис Аветисян
Новый подход позволяет языковым моделям действовать более рационально, учитывая стоимость каждого шага и используя предварительные знания.
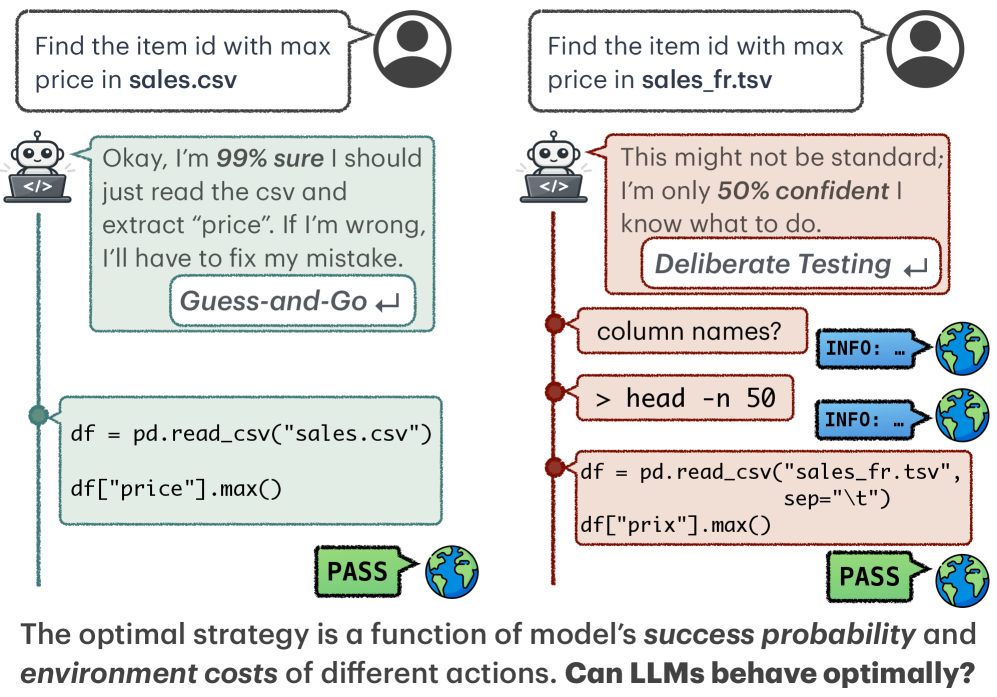
В статье представлена методика Calibrate-Then-Act (CTA) для повышения эффективности и снижения затрат при обучении и использовании ИИ-агентов, основанных на больших языковых моделях.
В условиях все более сложных задач, требующих взаимодействия с внешней средой, большие языковые модели (LLM) сталкиваются с необходимостью балансировать затраты и неопределенность при принятии решений. В данной работе, посвященной методу ‘Calibrate-Then-Act: Cost-Aware Exploration in LLM Agents’, предлагается фреймворк, позволяющий LLM явно учитывать компромисс между стоимостью действий и уровнем неопределенности, что приводит к более эффективному исследованию среды. Предложенный подход Calibrate-Then-Act (CTA) обеспечивает агентов дополнительным контекстом о априорных оценках, улучшая их способность к оптимальному принятию решений даже при обучении с подкреплением. Сможет ли явное моделирование затрат и неопределенности стать ключевым фактором в создании действительно разумных и эффективных LLM-агентов?
Неопределенность и Стоимость: Вызов для Разумных Агентов
Современные языковые агенты, функционирующие на основе больших языковых моделей, зачастую сталкиваются с ситуациями, когда доступ к полной информации об окружающей среде ограничен. Это означает, что агенты вынуждены принимать решения, основываясь на неполных данных и с учетом вероятности различных исходов. Неспособность учитывать неопределенность может приводить к неоптимальным действиям и снижению эффективности. Агенты, способные оценивать и учитывать степень своей осведомленности, а также прогнозировать возможные последствия своих действий в условиях неполной информации, демонстрируют значительно более высокую адаптивность и эффективность в сложных и динамичных средах. Именно способность функционировать в условиях неопределенности является ключевым фактором, определяющим успешность и надежность интеллектуальных агентов.
Традиционные подходы к разработке агентов, основанные на языковых моделях, часто пренебрегают учетом затрат, связанных со сбором информации. Это приводит к неэффективным стратегиям исследования среды, когда агент тратит ресурсы на получение данных, которые не приносят существенной пользы для решения поставленной задачи. Например, агент может бесконечно запрашивать информацию, даже если полученные данные лишь незначительно улучшают его понимание ситуации, или же игнорировать более дешевые, но потенциально полезные источники информации. В результате, агент может быстро исчерпать доступные ресурсы, не достигнув оптимального решения или даже не сумев завершить задачу. Особенно остро эта проблема проявляется в сложных и динамичных средах, где стоимость получения информации может значительно варьироваться.
Эффективность интеллектуальных агентов, работающих в реальных условиях, напрямую зависит от умения находить баланс между стремлением к получению новой информации и ограниченностью доступных ресурсов. В ситуациях, когда сбор данных требует определенных затрат — будь то время, энергия или финансовые вложения — простое увеличение объема информации не является оптимальной стратегией. Исследования показывают, что агенты, способные оценивать стоимость получения каждого фрагмента данных и принимать решения на основе сопоставления потенциальной пользы и затрат, демонстрируют значительно более высокую производительность и эффективность в решении сложных задач. Такой подход, известный как “исследование с учетом затрат”, позволяет агентам избегать избыточного сбора ненужной информации и фокусироваться на наиболее релевантных данных, что особенно важно в условиях ограниченных ресурсов и динамично меняющейся обстановки.
Формализация Задачи: Последовательное Принятие Решений с Учетом Стоимости
Формализация исследования с учетом затрат осуществляется путем представления задачи как последовательного процесса принятия решений, опирающегося на математический аппарат Марковских процессов принятия решений (МППР). В рамках МППР, состояние системы описывает текущую ситуацию, действия — возможные варианты поведения агента, а функция перехода определяет вероятность перехода из одного состояния в другое после выполнения действия. Целью является определение оптимальной политики — стратегии выбора действий, максимизирующей суммарное вознаграждение с учетом затрат. Использование МППР позволяет строго определить понятия состояния, действия, вознаграждения и политики, а также применять известные алгоритмы для нахождения оптимального решения, такие как итерация по значениям или итерация по политикам. P(s'|s,a) обозначает вероятность перехода в состояние s' из состояния s после выполнения действия a.
Функция вознаграждения является ключевым элементом в формализации задачи исследования с учетом затрат. Она количественно оценивает ценность каждого действия, принимая во внимание как успех, так и связанные с ним издержки. Формально, функция вознаграждения R(s, a) определяет скалярное значение, полученное агентом после выполнения действия a в состоянии s. Положительное значение указывает на успех и/или снижение затрат, в то время как отрицательное значение может отражать неудачу или увеличение затрат. Важно, чтобы функция вознаграждения точно отражала цели задачи, учитывая баланс между достижением успеха и минимизацией издержек, чтобы обеспечить эффективное обучение агента.
Коэффициент дисконтирования γ (где 0 ≤ γ ≤ 1) определяет, насколько сильно будущие награды влияют на текущее принятие решений. Значение γ близкое к 1 означает, что будущие награды почти так же ценны, как и немедленные, стимулируя долгосрочное планирование. И наоборот, значение γ близкое к 0 придает гораздо больший вес немедленным наградам, делая акцент на краткосрочной выгоде и снижая важность долгосрочных последствий. Это позволяет моделировать ситуации, где предпочтение отдается немедленному вознаграждению, даже если это приводит к меньшей общей сумме наград в перспективе, или наоборот — когда агенты готовы инвестировать в будущее ради более высоких долгосрочных результатов. Практически, коэффициент дисконтирования является гиперпараметром, настраиваемым для достижения оптимального баланса между исследованием и использованием в конкретной задаче.
Оцени-Затем-Действуй: Разделение Неопределенности и Действия
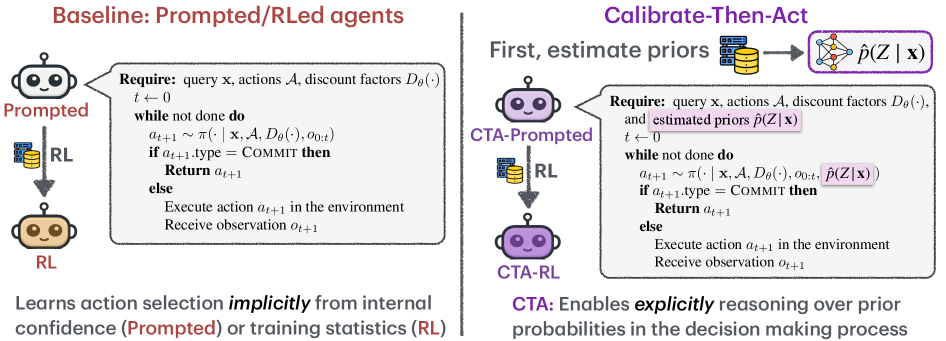
Методика “Оцени-Затем-Действуй” (CTA) представляет собой новый подход, отделяющий процесс калибровки неопределенности от выбора действия. Традиционно, в системах обучения с подкреплением, оценка уверенности в прогнозе и принятие решения о следующем шаге происходят совместно, что может приводить к неоптимальным результатам в средах, где каждое действие связано с определенными затратами. CTA позволяет агенту сначала оценить степень своей неуверенности в текущей ситуации, а затем, основываясь на этой оценке, выбрать наиболее целесообразное действие, минимизируя риски и затраты. Такое разделение позволяет более эффективно управлять исследованиями и эксплуатацией, особенно в задачах, требующих баланса между получением немедленной выгоды и сбором дополнительной информации.
Метод Calibrate-Then-Act (CTA) использует предварительную оценку (Prior Estimation) для формирования базового понимания окружающей среды, что повышает точность оценки неопределенности. Предварительная оценка позволяет агенту сформировать начальные представления о вероятностях различных исходов, основываясь на доступных данных или априорных знаниях. Это, в свою очередь, улучшает калибровку неопределенности, позволяя более эффективно различать достоверные и недостоверные прогнозы. Точная калибровка является ключевым фактором для принятия обоснованных решений о необходимости исследования (exploration) или использования (exploitation) имеющейся информации, что особенно важно в задачах, чувствительных к стоимости действий.
Точная калибровка неопределенности в рамках Calibrate-Then-Act (CTA) позволяет агентам принимать обоснованные решения о стратегии исследования (exploration) и использования (exploitation). Агент оценивает уровень своей уверенности в предсказаниях и, основываясь на этой оценке, выбирает, следует ли продолжать сбор дополнительной информации (исследование) для снижения неопределенности, или же использовать имеющиеся знания для достижения цели (эксплуатация). Такой подход позволяет минимизировать ненужные затраты, избегая излишнего исследования в ситуациях, когда текущие знания достаточны, и эффективно используя имеющиеся ресурсы для оптимизации результата.
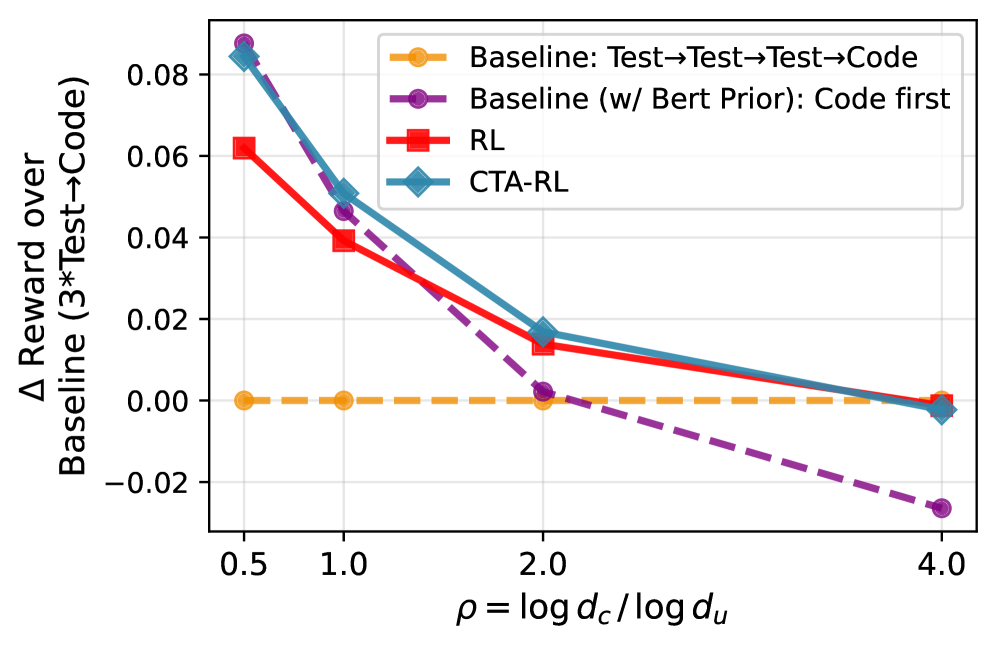
Внедрение фреймворка Calibrate-Then-Act (CTA) позволяет добиться улучшения результатов в задачах программирования по сравнению с традиционными методами обучения с подкреплением (RL). Эксперименты показали, что CTA обеспечивает прирост вознаграждения до 3.5%, достигая итогового значения 0.268, в то время как базовый RL демонстрирует результат 0.259. Данное улучшение указывает на эффективность CTA в оптимизации процесса принятия решений и повышения производительности агента при решении задач кодирования.
Подтверждение Эффективности CTA: От Абстрактных Задач к Реальным Применениям
Исследование продемонстрировало эффективность подхода CTA (Cost-aware Task Allocation) на задаче “Ящик Пандоры” — абстрактной модели, специально разработанной для оценки стратегий исследования с учетом затрат. В рамках данной задачи, CTA успешно оптимизирует процесс поиска решений, балансируя между необходимостью получения новой информации и связанными с этим издержками. Результаты показывают, что CTA способен эффективно определять, когда целесообразно продолжить исследование, а когда — остановиться, тем самым повышая общую эффективность решения задачи. Этот подход позволяет достичь высокой производительности даже в условиях ограниченных ресурсов и высокой стоимости получения информации, что делает его перспективным для применения в более сложных сценариях.
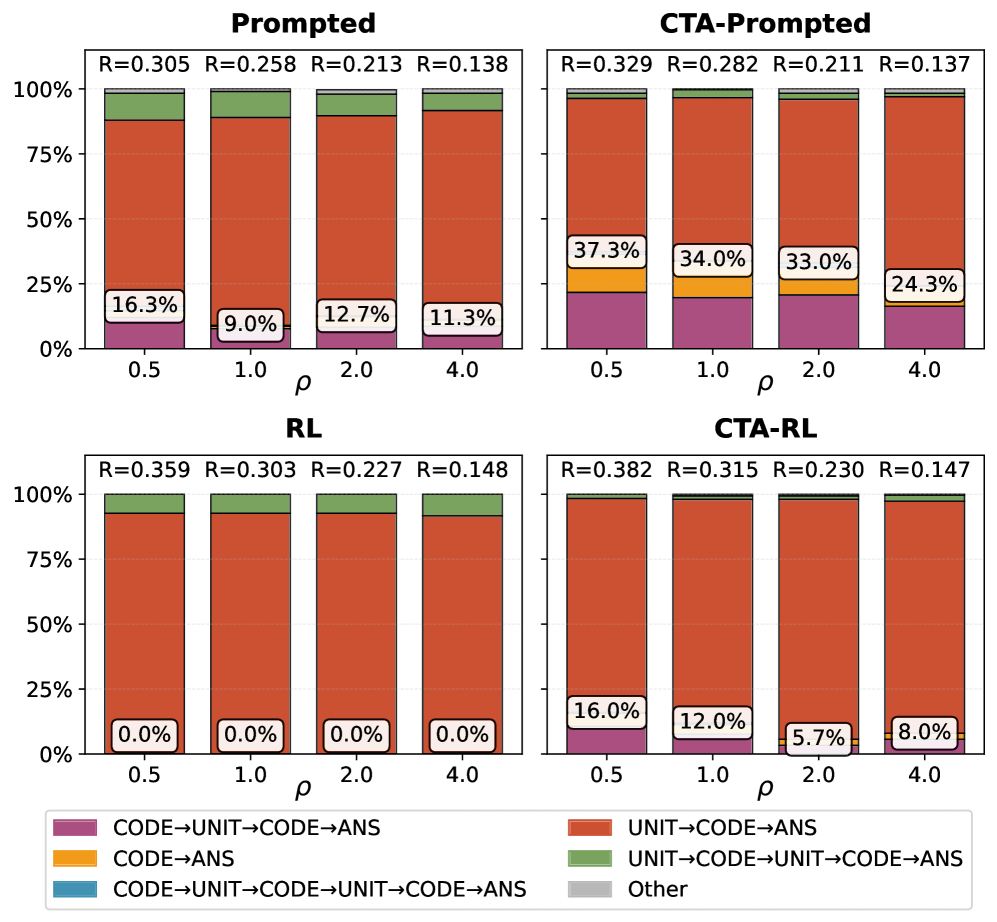
Исследования показали, что разработанный подход — Cost-Aware Task Allocation (CTA) — успешно применяется не только в абстрактных задачах, но и в более сложных сценариях, таких как ответы на вопросы, требующие поиска знаний, и задачи кодирования с выборочным тестированием. В этих приложениях CTA демонстрирует способность оптимизировать распределение ресурсов и улучшать процесс принятия решений в ситуациях, где сбор информации сопряжен с определенными затратами. Способность адаптироваться к различным задачам подтверждает универсальность подхода и открывает перспективы для его использования в широком спектре приложений, где необходимо эффективно управлять ресурсами и добиваться оптимальных результатов.
Исследования демонстрируют способность алгоритма CTA к оптимизации распределения ресурсов и повышению качества принимаемых решений в ситуациях, когда сбор информации сопряжен с затратами. В ходе экспериментов на задаче «Ящик Пандоры», предназначенной для оценки стратегий исследования с учетом стоимости, CTA достиг 94,0% совпадений с оптимальным решением. Кроме того, применительно к более сложным задачам, таким как ответы на вопросы с использованием базы знаний и задачи кодирования с выборочным тестированием, алгоритм показал высокую эффективность в прогнозировании формата априорных оценок, достигнув точности в 67%. Этот результат подтверждает качество процесса оценки априорных вероятностей и свидетельствует о потенциале CTA для широкого спектра приложений, где необходимо эффективно использовать ограниченные ресурсы для получения необходимой информации.
Оценка априорных вероятностей, выполненная в рамках данной работы, демонстрирует высокую точность — 67%. Этот результат свидетельствует о качественной работе процесса оценки, позволяющего эффективно определять начальные предположения о стоимости информации. Достижение такой точности является ключевым фактором успеха стратегии CTA, поскольку позволяет ей более эффективно планировать процесс исследования и избегать нерационального использования ресурсов. По сути, достоверная оценка априорных вероятностей создает прочную основу для принятия обоснованных решений в ситуациях, где получение информации связано с затратами, оптимизируя баланс между исследованием и использованием уже имеющихся знаний.
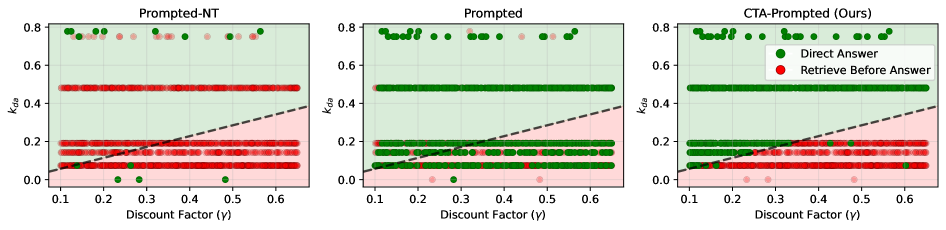
Исследование, представленное в статье, акцентирует внимание на необходимости рационального подхода к исследованию пространства действий для LLM-агентов. Этот подход, названный Calibrate-Then-Act, стремится к оптимизации процесса принятия решений, основываясь на априорных знаниях о неопределенности и стоимости. В этом контексте особенно примечательны слова Карла Фридриха Гаусса: «Если бы я мог, я бы лишил математику всякой эмпирической науки». Эта фраза отражает стремление к строгости и доказательности, что находит параллель в предложенном методе CTA — алгоритм, который не просто «работает на тестах», но и стремится к формальному обоснованию эффективности и экономичности своих действий. Акцент на априорных знаниях и формализации позволяет LLM-агентам принимать более взвешенные решения, избегая слепого перебора вариантов.
Что Дальше?
Представленный подход, безусловно, вносит ясность в вопрос о рациональном исследовании для агентов на базе больших языковых моделей. Однако, если решение кажется магией — значит, не раскрыт инвариант. Здесь, как и во многих областях, кажущаяся «эффективность» часто является лишь маскировкой недостаточного понимания лежащих в основе принципов. Необходимо признать, что явное кодирование априорных знаний — задача нетривиальная, и её успешность напрямую зависит от точности и полноты этих самых знаний. Попытки автоматизировать процесс получения априорных знаний, возможно, окажутся более плодотворными, чем попытки их ручной настройки.
Следующим шагом представляется углублённое исследование влияния различных типов априорных распределений на процесс обучения и, что более важно, на гарантии сходимости алгоритма. Устойчивость к шуму и неполноте данных — краеугольный камень любой практической системы. В противном случае, мы рискуем создать агента, блестяще работающего в лабораторных условиях, но беспомощно терпящего крах в реальном мире.
В конечном счете, истинный прогресс заключается не в создании более сложных алгоритмов, а в разработке более элегантных и доказуемо корректных решений. Алгоритм должен быть понятен, а не просто «работать на тестах». Иначе, мы обречены на бесконечную гонку за производительностью, не понимая, куда именно движемся.
Оригинал статьи: https://arxiv.org/pdf/2602.16699.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Предел возможностей: где большие языковые модели теряют разум?
- Временная запутанность: от хаоса к порядку
- Улучшение точности квантовых сенсоров: новый подход к подавлению шумов
- Квантовое программирование: Карта развивающегося мира
- ЭКГ-анализ будущего: От данных к цифровым биомаркерам
- Резонансы в тандеме: Управление светом в микрорезонаторах
- Сердце музыки: открытые модели для создания композиций
- Моделирование спектроскопии электронного пучка: новый подход
- За пределами стандартной точности: новая структура эффективной теории
- Тандем топ-кварков и бозона Хиггса: новые горизонты точности
2026-02-21 08:07