Автор: Денис Аветисян
Новый подход позволяет большим языковым моделям не просто имитировать поведение, а активно планировать свои действия в скрытом пространстве, повышая точность и эффективность.
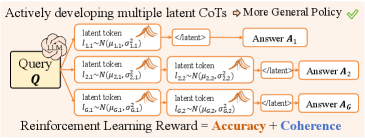
В статье представлена методика ATP-Latent, оптимизирующая скрытое рассуждение в больших языковых моделях с использованием вариационного автоэнкодера и награды за согласованность.
Пассивное имитирование дискретных языковых меток ограничивает потенциал латентного планирования в больших языковых моделях. В работе ‘Beyond Imitation: Reinforcement Learning for Active Latent Planning’ предложен метод ATP-Latent, активно планирующий в сглаженном латентном пространстве с использованием вариационного автокодировщика и награды за когерентность. Это позволяет оптимизировать латентное рассуждение, повышая точность и эффективность моделей на 4.1% и сокращая количество токенов на 3.3% по сравнению с современными подходами. Сможет ли активное планирование в латентном пространстве открыть новые горизонты для развития искусственного интеллекта, способного к более гибкому и эффективному решению сложных задач?
Погружение за Грань Языка: Открытие Скрытого Разума
Традиционные языковые модели, несмотря на впечатляющие успехи в обработке текста, сталкиваются с существенными трудностями при решении задач, требующих сложного логического мышления. Эти модели оперируют дискретными токенами — отдельными словами или частями слов — что ограничивает их способность эффективно представлять и манипулировать абстрактными понятиями и взаимосвязями. По сути, процесс рассуждения вынужденно кодируется в последовательности этих токенов, создавая “узкое место”, препятствующее масштабированию и усложнению логических цепочек. В результате, даже небольшие изменения в формулировке задачи могут существенно повлиять на результат, поскольку модель вынуждена пересчитывать все шаги рассуждений, представленные в виде последовательности токенов, а не оперировать с более общими и абстрактными представлениями.
Отделение процесса рассуждений от непосредственной обработки языка открывает путь к повышению эффективности и масштабируемости логических выводов. Традиционные модели, оперирующие дискретными языковыми единицами, часто сталкиваются с ограничениями при решении сложных задач, требующих многоступенчатого анализа. Вместо того, чтобы кодировать рассуждения непосредственно в лингвистической форме, предлагается создать промежуточное, скрытое пространство, где логические шаги могут быть представлены и обработаны более компактно и эффективно. Такой подход позволяет моделировать сложные взаимосвязи и зависимости без необходимости генерировать и анализировать длинные последовательности текста, что существенно снижает вычислительные затраты и повышает скорость получения результатов. Это особенно важно для задач, требующих обработки больших объемов информации и принятия решений в режиме реального времени.
Концепция скрытого рассуждения предполагает создание особого, невидимого пространства, где шаги логических умозаключений представлены и обрабатываются независимо от языковых конструкций. Этот подход позволяет обойти ограничения, связанные с дискретностью и линейностью обработки текстовых данных, которые часто становятся «узким местом» для традиционных языковых моделей. Вместо последовательного анализа слов и фраз, система оперирует абстрактными представлениями, кодирующими суть рассуждений, что потенциально обеспечивает более эффективное и масштабируемое решение сложных задач. Такой метод позволяет моделировать логические связи и выводы, не привязываясь к конкретному языку, что открывает возможности для решения проблем, требующих глубокого понимания и анализа информации, даже при наличии неполных или неоднозначных данных.

Кодирование Мысли: Сила Скрытых Токенов
Латентные токены представляют собой непрерывное представление шагов рассуждений, что позволяет применять градиентную оптимизацию и исследование пространства решений. В отличие от дискретных представлений, непрерывность латентных токенов обеспечивает возможность вычисления градиентов относительно каждого шага рассуждения, что критически важно для обучения моделей с помощью обратного распространения ошибки. Это позволяет моделям не только находить оптимальные решения, но и адаптировать процесс рассуждения на основе полученной обратной связи, улучшая свою способность к решению сложных задач. Использование градиентной оптимизации в пространстве латентных токенов открывает возможности для более эффективного исследования различных стратегий рассуждений и повышения общей производительности модели.
Принципы скрытого рассуждения (Latent Reasoning) лежат в основе представления латентными токенами сложных мыслительных процессов. Данный подход предполагает кодирование промежуточных этапов рассуждений не в виде дискретных символов или слов, а в виде непрерывных векторов в скрытом пространстве. Это позволяет моделировать логические связи и зависимости между элементами рассуждений как математические операции над этими векторами. В отличие от традиционных методов, где каждый шаг рассуждений явно определен, латентные токены позволяют модели выводить логические шаги, опираясь на статистические закономерности, обнаруженные в данных обучения, и эффективно представлять сложные, многоступенчатые рассуждения в компактной форме. Такой подход позволяет обойти ограничения, связанные с представлением знаний в виде символов, и обеспечивает большую гибкость и выразительность в моделировании когнитивных процессов.
Использование скрытого пространства представления, обеспечиваемого латентными токенами, позволяет моделям потенциально достигать большей глубины рассуждений и повышать эффективность обработки информации. В отличие от дискретных представлений, непрерывное скрытое пространство позволяет применять методы градиентной оптимизации непосредственно к процессу рассуждения, что облегчает поиск оптимальных путей решения задач. Такой подход снижает вычислительные затраты, связанные с перебором различных вариантов, и позволяет модели исследовать более сложные и многоступенчатые логические цепочки, что особенно важно при решении задач, требующих глубокого анализа и синтеза информации. Повышенная эффективность достигается за счет более компактного представления промежуточных шагов рассуждений и возможности параллельной обработки информации в скрытом пространстве.

ATP-Latent: Оптимизация Стратегий Рассуждений
ATP-Latent представляет собой структуру обучения с подкреплением, предназначенную для активной оптимизации скрытых (latent) политик рассуждений в заданном скрытом пространстве. Данный подход позволяет динамически настраивать процесс рассуждений, используя механизм обучения для поиска наиболее эффективных стратегий в рамках определенного набора параметров. Оптимизация происходит путем итеративного улучшения политики на основе получаемых сигналов обратной связи, что позволяет системе адаптироваться к различным задачам и улучшать качество генерируемых рассуждений в пределах заданного латентного пространства.
Метод ATP-Latent использует несколько ключевых компонентов, среди которых Stop Head — модуль, предназначенный для управления длиной генерируемой последовательности и поддержания гладкости латентного пространства. Stop Head функционирует как механизм ранней остановки генерации, предотвращая избыточное или бессвязное продолжение рассуждений. Он оценивает вероятность завершения процесса генерации на каждом шаге, позволяя модели динамически регулировать длину ответа и избегать ненужных токенов. Поддержание гладкости латентного пространства достигается за счет регуляризации, применяемой к латентным векторам, что способствует стабильности и предсказуемости процесса генерации.
В рамках ATP-Latent, оптимизация латентных политик рассуждений осуществляется посредством использования двух типов сигналов вознаграждения: точности (Accuracy Reward) и связности (Coherence Reward). Сигнал точности оценивает корректность полученного ответа, в то время как сигнал связности оценивает логическую последовательность и согласованность рассуждений. Комбинация этих сигналов позволяет направлять процесс обучения к генерации ответов, которые одновременно являются и верными, и логически обоснованными. Экспериментальные результаты демонстрируют, что применение данной методики позволяет достичь средней точности в 47.7% при средней длине сгенерированных ответов в 8.4 токена.

Усиление Исследования с Помощью Гауссовского Шума
Добавление гауссовского шума к латентным токенам стимулирует исследование в процессе обучения с подкреплением, предотвращая преждевременную сходимость. Включение случайного фактора в представление латентного пространства позволяет модели отклоняться от наиболее вероятных, но потенциально неоптимальных путей, и рассматривать более широкий спектр возможных решений. Это особенно важно в сложных задачах, где локальные оптимумы могут препятствовать поиску глобально оптимальной стратегии. В результате, алгоритм способен более эффективно исследовать пространство состояний и находить более устойчивые и эффективные решения, избегая застревания в субоптимальных конфигурациях.
Внедрение гауссовского шума в латентные токены позволяет модели исследовать более широкий спектр возможных путей рассуждений, что положительно влияет на общую производительность. Добавление случайности способствует отклонению от детерминированных траекторий, позволяя алгоритму оценить альтернативные решения, которые могли бы быть пропущены при строгом следовании наиболее вероятному пути. Это особенно важно в задачах, требующих исследования большого пространства состояний, где субоптимальные решения могут быть локально привлекательными, но глобально неэффективными. Расширение диапазона исследуемых путей увеличивает вероятность обнаружения более надежных и эффективных стратегий, приводя к улучшению показателей в процессе обучения с подкреплением.
Стратегическое введение случайности в процесс обучения модели ATP-Latent позволяет преодолевать локальные оптимумы и находить более устойчивые решения. Локальные оптимумы представляют собой точки в пространстве параметров, где алгоритм обучения может застрять, полагая, что достиг оптимального решения, хотя глобальный оптимум может быть значительно лучше. Добавление гауссовского шума к латентным токенам создает небольшие возмущения, которые позволяют модели «выскакивать» из этих локальных оптимумов и исследовать более широкую область пространства параметров. Это способствует обнаружению решений, которые обладают большей обобщающей способностью и устойчивостью к изменениям входных данных, что критически важно для повышения общей производительности модели и надежности ее работы в различных условиях.

К Надежности: Расширения SIM-CoT и Coconut
Проект Coconut заложил прочный фундамент для скрытого рассуждения, используя подход последовательного обучения, или curriculum learning. Данный метод предполагает постепенное усложнение задач, представленных модели, начиная с простых примеров и переходя к более сложным. Такой подход позволяет нейронной сети более эффективно осваивать навыки рассуждения, поскольку она последовательно формирует и укрепляет необходимые связи. Изначально модель обучается на задачах, требующих минимальных когнитивных усилий, что облегчает процесс обучения и предотвращает перегрузку. По мере прогресса сложность задач увеличивается, заставляя модель адаптироваться и развивать более сложные стратегии решения. В результате, Coconut продемонстрировал способность к эффективному скрытому рассуждению, создав перспективную платформу для дальнейших исследований в этой области.
Метод SIM-CoT является развитием подхода Coconut и направлен на повышение устойчивости латентного рассуждения. В то время как Coconut заложил основу для обучения с формированием учебного плана, SIM-CoT решает проблему нестабильности, возникающую в процессе латентного вывода. Улучшая стабильность процесса, SIM-CoT демонстрирует повышенную надежность при решении сложных задач, требующих многоступенчатого логического вывода. Это достигается за счет оптимизации процесса обучения и улучшения способности модели к обобщению, что позволяет ей более эффективно справляться с незнакомыми данными и уменьшает вероятность ошибок, связанных с непредсказуемым поведением латентных переменных.
Исследования показали, что модель ATP-Latent демонстрирует значительное превосходство над повторно реализованной системой SIM-CoT. В ходе экспериментов зафиксировано увеличение точности на 4,1%, что свидетельствует о более эффективной обработке и анализе информации. При этом, модель ATP-Latent потребляет на 3,3% меньше токенов, что указывает на оптимизацию вычислительных ресурсов и повышение общей эффективности системы. Данное улучшение не только повышает надежность и стабильность работы модели, но и открывает возможности для ее применения в условиях ограниченных ресурсов и больших объемов данных.

Представленная работа демонстрирует стремление к созданию систем, в которых простота и ясность структуры определяют эффективность функционирования. Исследование ATP-Latent, направленное на оптимизацию скрытого рассуждения в больших языковых моделях, подчёркивает важность планирования в непрерывном латентном пространстве. Это соответствует принципу, сформулированному Анри Пуанкаре: «Наука не состоит из ряда накопленных истин, а из методов, открытий». Подобно тому, как метод позволяет структурировать научное исследование, так и разработанный подход к латентному планированию предлагает метод улучшения точности и эффективности языковых моделей, делая акцент на когерентности и масштабируемости, а не на сложности.
Куда Ведет Дорога?
Представленная работа, стремясь к оптимизации скрытого рассуждения в больших языковых моделях посредством активного планирования в латентном пространстве, обнажает фундаментальную проблему: как оценить истинную согласованность и эффективность этого самого скрытого процесса. Успех ATP-Latent, безусловно, интересен, но он лишь подчеркивает, что «хорошая архитектура незаметна, пока не ломается, и только тогда видна настоящая цена решений». Улучшение точности и эффективности — это лишь симптомы, а не лечение самой болезни — зависимости от непрозрачных, «черных ящиков».
Будущие исследования, вероятно, будут направлены на разработку более измеримых метрик согласованности, не полагающихся исключительно на корреляцию с человеческими оценками. Необходимо углубиться в понимание того, как различные структуры латентного пространства влияют на способность модели к обобщению и адаптации к новым задачам. Интересно будет изучить, возможно ли создание саморегулирующихся систем, способных самостоятельно обнаруживать и исправлять несогласованности в своем скрытом рассуждении.
В конечном итоге, вопрос заключается не в том, чтобы просто улучшить существующие модели, а в том, чтобы переосмыслить саму парадигму машинного обучения. Необходимо перейти от поверхностной оптимизации к глубокому пониманию принципов, лежащих в основе разумного поведения. Иначе, все эти сложные алгоритмы и впечатляющие результаты останутся лишь иллюзией интеллекта, красивой, но хрупкой.
Оригинал статьи: https://arxiv.org/pdf/2601.21598.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Отражения культуры: Как языковые модели рассказывают истории
- Квантовые Заметки: Прогресс и Парадоксы
- Звуковая фабрика: искусственный интеллект, создающий музыку и речь
- Гармония в коде: Распознавание аккордов с помощью глубокого обучения
- Визуальный след: Сжатие рассуждений для мощных языковых моделей
- Кванты в Финансах: Не Шутка!
- Взлом языковых моделей: эволюция атак, а не подсказок
- Квантовый оптимизатор: Новый подход к сложным задачам
- Оптимизация Комбинаторных Задач: Новый Взгляд с Помощью Автокодировщиков
- Волны спинов для нейроморфных вычислений: новый подход к скорости и эффективности
2026-01-31 07:05